- 文章主题:顺序表和链表详解🌱
- 所属专栏:深入理解数据结构📘
- 作者简介:更新有关深入理解数据结构知识的博主一枚,记录分享自己对数据结构的深入解读。😄
- 个人主页:[₽]的个人主页🔥🔥
栈和队列详解
- 前言
- 栈
- 栈的概念及结构
- 栈的实现
- 队列
- 队列的概念及结构
- 队列的实现
- 结语
前言
上文我们已经讲完了线性表中最基本的、最常用的顺序表和链表,这一次博主为大家带来基于顺序表和链表实现的线性表中也是十分常用的数据结构栈和队列的详解,希望能够让你对数据结构有一个更加深入的理解。
栈
栈的概念及结构
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈/弹栈。出数据也在栈顶。

栈的实现
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插入数据的代价比较小,最简单。

静态数组栈
下面是定长的静态栈的结构,实际中一般不实用,所以我们主要实现下面的支持动态增长的栈
// 下面是定长的静态栈的结构,实际中一般不实用,所以我们主要实现下面的支持动态增长的栈
typedef int STDataType;
#define N 10
typedef struct Stack
{
STDataType _a[N];
int _top; // 栈顶
}Stack;
动态数组栈
Stack.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{
STDataType* _a;
int _top; // 栈顶
int _capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps);
// 入栈
void StackPush(Stack* ps, STDataType data);
// 出栈
void StackPop(Stack* ps);
// 获取栈顶元素
STDataType StackTop(Stack* ps);
// 获取栈中有效元素个数
int StackSize(Stack* ps);
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int StackEmpty(Stack* ps);
// 销毁栈
void StackDestroy(Stack* ps);
Stack.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "Stack.h"
void StackInit(Stack* ps)
{
assert(ps);
// 栈区数组未创建,赋成NULL
ps->_a = NULL;
ps->_capacity = 0;
// 表示top指向栈顶元素
ps->_top = -1;
// 表示top指向栈顶元素的下一个
//ps->_top = 0
}
void StackPush(Stack* ps, STDataType data)
{
assert(ps);
// 栈区数据已满,扩容
if (ps->_top + 1 == ps->_capacity)
{
// 确定扩容后的新容量,如果是 0 就扩容为 4 ,如果已经扩过容了就将容量在增加一个原来这么多,即扩大为原来的两倍
int newcapacity = ps->_capacity == 0 ? 4 : ps->_capacity * 2;
// 扩容
STDataType* tmp = (STDataType*)realloc(ps->_a, newcapacity * sizeof(STDataType));
// 扩容失败打印失败原因后返回
if (tmp == NULL)
{
perror("realloc fail");
return;
}
// 未失败将容量更新成新容量,数据指针更新成新指针
ps->_capacity = newcapacity;
ps->_a = tmp;
}
// 插入数据
ps->_top++;
ps->_a[ps->_top] = data;
}
void StackPop(Stack* ps)
{
assert(ps);
// 栈不为空时才能删除数据
assert(ps->_top + 1 > 0);
// 栈顶元素坐标下移,删除数据
ps->_top--;
}
STDataType StackTop(Stack* ps)
{
assert(ps);
// 不为空,为空弹不出数据来进行访问,并且访问会导致数组越界
assert(ps->_top + 1 > 0);
// 返回栈顶元素值
return ps->_a[ps->_top];
}
int StackSize(Stack* ps)
{
assert(ps);
// 返回栈中有效元素个数(栈顶元素 +1 即为栈中有效元素个数)
return ps->_top + 1;
}
int StackEmpty(Stack* ps)
{
assert(ps);
// 为空则返回非 0 的真
return ps->_top + 1 == 0;
}
void StackDestroy(Stack* ps)
{
assert(ps);
// 数据内存释放,再将记录数据的各值清空
free(ps->_a);
ps->_a = NULL;
ps->_capacity = 0;
ps->_top = -1;
}
Test.c
#include "Stack.h"
void StackTest1()
{
// 初始化栈
Stack S1;
StackInit(&S1);
// 数据入栈
StackPush(&S1, 1);
StackPush(&S1, 2);
StackPush(&S1, 3);
StackPush(&S1, 4);
StackPush(&S1, 5);
// 销毁栈
StackDestroy(&S1);
// 检测是否销毁成功
if (S1._a == NULL && S1._capacity == 0 && S1._top == -1)
printf("销毁成功!\n");
else
printf("销毁失败。\n");
}
void StackTest2()
{
// 初始化栈
Stack S1;
StackInit(&S1);
// 数据入栈
StackPush(&S1, 1);
StackPush(&S1, 2);
StackPush(&S1, 3);
StackPush(&S1, 4);
StackPush(&S1, 5);
// 从栈顶读取数据后弹出栈中数据
while (!StackEmpty(&S1))
{
printf("%d ", StackTop(&S1));
StackPop(&S1);
}
printf("\n");
// 销毁栈
StackDestroy(&S1);
}
void StackTest3()
{
// 初始化栈
Stack S1;
StackInit(&S1);
// 栈为空时也弹出数据
StackPop(&S1);
// 销毁栈
StackDestroy(&S1);
}
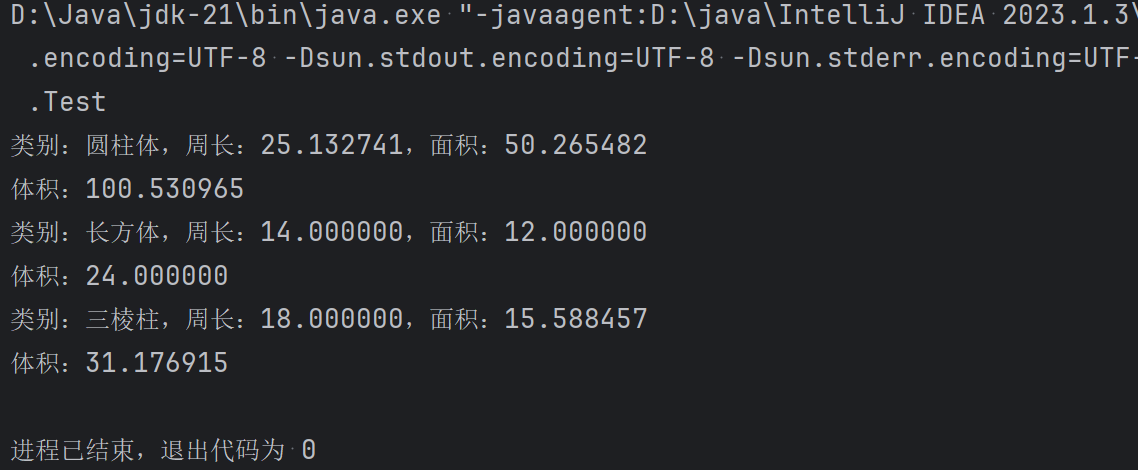
int main()
{
StackTest3();
return 0;
}
队列
队列的概念及结构
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out) 入队列:进行插入操作的一端称为队尾 出队列:进行删除操作的一端称为队头
入队:队列的插入操作叫做入队,入数据在队尾。
出队:队列的删除操作叫做出队。出数据在队头。
(栈和对列都是将出数据的地方叫作顶/头)

队列的实现
队列也可以数组和链表的结构实现,使用链表(带头的单链表)的结构实现更优一些(时间复杂度O(1),比数组来说在队头删除数据更加简洁),因为如果使用数组的结构,出队列在数组头上出数据,效率会比较低(时间复杂度为O(N))。

队列
Queue.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int QDataType;
// 链式结构:表示队列
typedef struct QListNode
{
struct QListNode* _next;
QDataType _data;
}QNode;
// 队列的结构
typedef struct Queue
{
QNode* _front;
QNode* _rear;
int _size;
}Queue;
// 初始化队列
void QueueInit(Queue* q);
// 销毁队列
void QueueDestroy(Queue* q);
// 队尾入队列
void QueuePush(Queue* q, QDataType data);
// 队头出队列
void QueuePop(Queue* q);
// 获取队列头部元素
QDataType QueueFront(Queue* q);
// 获取队列队尾元素
QDataType QueueBack(Queue* q);
// 获取队列中有效元素个数
int QueueSize(Queue* q);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q);
Queue.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "Queue.h"
void QueueInit(Queue* q)
{
assert(q);
// 首尾指针都赋成NULL,元素个数赋0
q->_front = q->_rear = NULL;
q->_size = 0;
}
void QueueDestroy(Queue* q)
{
assert(q);
// 释放队列数据内存
QNode* cur = q->_front;
while (cur)
{
QNode* tmp = cur;
cur = cur->_next;
free(tmp);
}
// 将队列中的首尾指针数据赋成NULL,队列元素个数也置为0
q->_front = q->_rear = NULL;
q->_size = 0;
}
void QueuePush(Queue* q, QDataType data)
{
assert(q);
// 创建新节点
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("maloc fail");
return;
}
newnode->_data = data;
newnode->_next = NULL;
// 无节点
if (q->_front == NULL)
{
q->_front = q->_rear = newnode;
}
// 有节点
else
{
q->_rear->_next = newnode;
q->_rear = newnode;
}
// 队尾入数据时总元素个数加一
q->_size++;
}
void QueuePop(Queue* q)
{
assert(q);
// 无节点
assert(q->_front);
// 有节点
QNode* tmp = q->_front;
q->_front = q->_front->_next;
free(tmp);
// 一个节点时,尾指针因为释放节点变成野指针,需要置空
if (q->_front == NULL)
q->_rear = NULL;
// 队头出数据时总元素个数减一
q->_size--;
}
QDataType QueueFront(Queue* q)
{
assert(q);
// 无节点
assert(q->_front);
// 有节点
return q->_front->_data;
}
QDataType QueueBack(Queue* q)
{
assert(q);
// 无节点
assert(q->_front);
// 有节点
return q->_rear->_data;
}
int QueueSize(Queue* q)
{
assert(q);
// 直接将储存队列主要数据的结构体中的元素个数拿出来返回
return q->_size;
}
int QueueEmpty(Queue* q)
{
assert(q);
return q->_size == 0;
}
Test.c
#define _CRT_SECURE_NO_WARNINGS 1
#include "Queue.h"
void QueueTest1()
{
// 队列初始化
Queue Q1;
QueueInit(&Q1);
// 队尾入数据
QueuePush(&Q1, 1);
QueuePush(&Q1, 2);
QueuePush(&Q1, 3);
QueuePush(&Q1, 4);
QueuePush(&Q1, 5);
// 销毁队列
QueueDestroy(&Q1);
if (Q1._front == NULL && Q1._rear == NULL && Q1._size == 0)
printf("销毁成功!\n");
else
printf("销毁失败。\n");
}
void QueueTest2()
{
// 队列初始化
Queue Q1;
QueueInit(&Q1);
// 队尾入数据
QueuePush(&Q1, 1);
QueuePush(&Q1, 2);
QueuePush(&Q1, 3);
QueuePush(&Q1, 4);
QueuePush(&Q1, 5);
// 打印队列中的数据
printf("Queue: \n");
while (!QueueEmpty(&Q1))
{
printf("%d ", QueueFront(&Q1));
QueuePop(&Q1);
}
printf("\n");
// 销毁队列
QueueDestroy(&Q1);
}
void QueueTest3()
{
// 队列初始化
Queue Q1;
QueueInit(&Q1);
// 队尾入数据
QueuePush(&Q1, 1);
QueuePush(&Q1, 2);
QueuePush(&Q1, 3);
QueuePush(&Q1, 4);
QueuePush(&Q1, 5);
// 打印队列中的数据
printf("Queue: \n");
while (!QueueEmpty(&Q1))
{
printf("%d ", QueueFront(&Q1));
QueuePop(&Q1);
}
printf("\n");
// 无节点从队列中弹出数据
QueuePop(&Q1);
// 销毁队列
QueueDestroy(&Q1);
}
void QueueTest4()
{
// 队列初始化
Queue Q1;
QueueInit(&Q1);
// 队尾入数据
QueuePush(&Q1, 1);
QueuePush(&Q1, 2);
QueuePush(&Q1, 3);
QueuePush(&Q1, 4);
QueuePush(&Q1, 5);
// 打印队尾中的数据
printf("BackNum: \n%d\n", QueueBack(&Q1));
// 打印队列中的数据
printf("Queue: \n");
while (!QueueEmpty(&Q1))
{
printf("%d ", QueueFront(&Q1));
QueuePop(&Q1);
}
printf("\n");
// 销毁队列
QueueDestroy(&Q1);
}
void QueueTest5()
{
// 队列初始化
Queue Q1;
QueueInit(&Q1);
// 队尾入数据
QueuePush(&Q1, 1);
QueuePush(&Q1, 2);
QueuePush(&Q1, 3);
QueuePush(&Q1, 4);
QueuePush(&Q1, 5);
// 打印队列中的数据个数
printf("QueueSize: \n%d\n", QueueSize(&Q1));
// 打印队列中的数据
printf("Queue: \n");
while (!QueueEmpty(&Q1))
{
printf("%d ", QueueFront(&Q1));
QueuePop(&Q1);
}
printf("\n");
// 销毁队列
QueueDestroy(&Q1);
}
int main()
{
QueueTest5();
return 0;
}
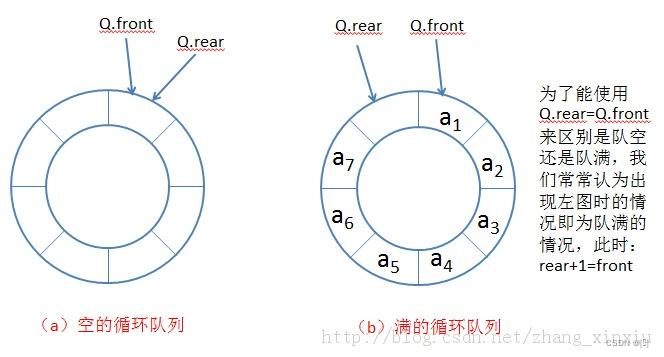
环形队列
另外扩展了解一下,实际中我们有时还会使用一种队列叫循环队列。如操作系统中的生产者消费者模型中就会使用循环队列。环形队列可以使用数组实现,也可以使用循环链表实现(差别不是很大,并且环形队列的元素个数是固定的,但也可以不是在栈区的静态数组实现的,其可用在动态区用长度不变的数组来实现内存大小不变的效果,可理解成动态数组大小不变所实现的仿静态效果,并且虽逻辑结构上两种环形队列都相接,数组型的环形队列物理结构上首尾不相接,链表物理结构上相接)。

通常为区分队头和队尾,会在数组中多加一个元素来既防止数组越界,又能够解决因空和满索引条件相同而造成无法判断的假溢出问题(此时环形队列容量为数组总元素个数减一):
结语
以上就是博主对栈和队列的详解,😄希望对你的数据结构的学习有所帮助!看都看到这了,点个小小的赞或者关注一下吧(当然三连也可以~),你的支持就是博主更新最大的动力!让我们一起成长,共同进步!


![[HNCTF 2022 WEEK2]来解个方程?](https://img-blog.csdnimg.cn/direct/b62b92076b114dde893ff82b8d194d19.png)