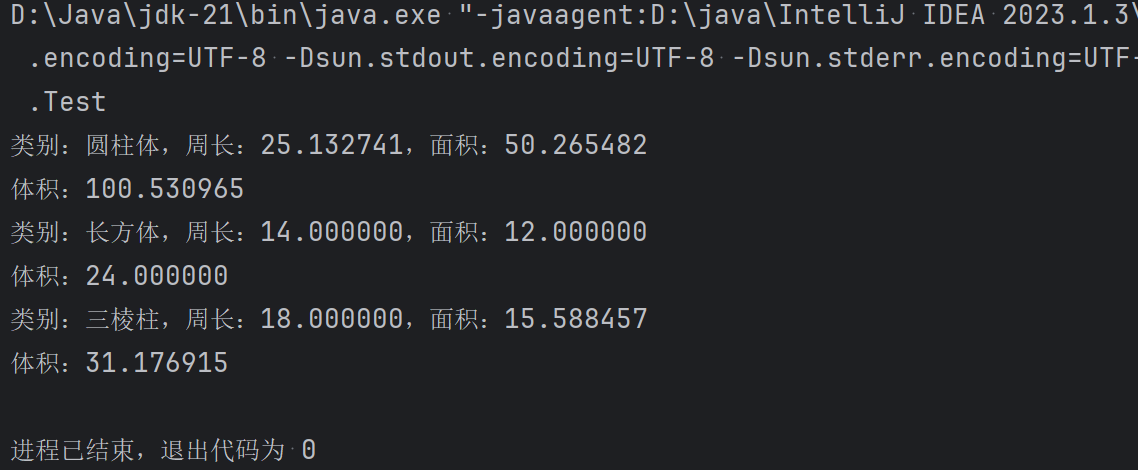
数据集及基本操作
1)数据集的组成
数据集由特征(feature)与标签(label)构成。
特征是输入数据。 什么是特征(Features): 机器学习中输入数据,被称为特征。通常特征不止1个,可以用 n 维向量表示n个特征。
Features 数据通常表示为大写 X,数据格式为 Numpy array 或者 Pandas 的 dataFrame
X的数据类型必须是float32,或 float64.
标签是输出数据,在sklearn 中有时也称为target, response.
通常标记为小写 y, 只能是1维向量,数据格式为 Numpy array 或者 Pandas 的 Series
2)常用测试集:
- iris
- digits for classification
- Boston house prices for regression
注意 Boston House Price数据集从1.2中被移除。有很多教程中还有, 手工加载方法:
import pandas as pd
import numpy as np
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
或者下载后,从本地加载
raw_df = pd.read_csv("./boston", sep="\s+", skiprows=22, header=None)
也可用California housing datase替代
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing() #可能下载不了。
切分数据集
通常,需要将数据集切分为两部分: training set and testing set.
如:
from sklearn.datasets import load_iris
iris = load_iris()
data_X = iris.data
data_y = iris.target
from sklearn.model_selection import train_test_split
#划分为训练集和测试集数据
X_train, X_test, y_train, y_test = train_test_split(
data_X,
data_y,
test_size=0.3,
random_state=111
)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
Output
(105, 4)
(45, 4)
(105,)
(45,)
数据集预处理技术
sklearn的数据预处理操作分类
(1) Feature Extract
① Load features from dict
② 文件特征化
(2) Preprocessing Data
① Standalizaiton , scaling
② Normalization
③ Encoding categorical features
④ Discretization
⑤ Custom transformers
(3) Imputation of missing values
① Univariate feature imputation, Multivariate feature imputation
② Nearest neighbors imputation
③ 用常量填充
④ NaN空值填充
(4) Dimension Reduction
① PCA: principal component analysis
② Random projections
③ Feature agglomeration
(5) 快速降维技术 Random Projection
① The Johnson-Lindenstrauss lemma
② Gaussian random projection
③ Sparse random projection
(1)Binarisation 二值 化
二值化主要用于将数值特征向量转换为(0,1), 或(true, false)
原始数据
import numpy as np
from sklearn import preprocessing
data = np.array([[3, -1.5, 2, -5.4],
[0, 4, -0.3, 2.1],
[1, 3.3, -1.9, -4.3]]) # 原始数据矩阵 shape=(3,4
二值化处理:
binarized=preprocessing.Binarizer(threshold=1.4).transform(data)
#小于等于1.4的为0,其余为1
print(“原始:\n”,data)
print(“二值化:\n”,binarized)
[
[ 1. 0. 1, 0.]
[ 0. 1. 0, 1]
[ 0. 1. 0. 0]
]
(2)标准化与归一化处理
数据集的标准化(Standardization)是一种特征缩放技术。其主要目的是调整特征的尺度,使得所有特征都具有相同的尺度或范围。
具体来说,标准化通常是通过将每个特征值减去其均值,然后除以其标准差来实现的。这样处理后,每个特征的均值为0,标准差为1,符合标准正态分布。标准化对于那些依赖于距离和权重的算法(如KNN、Logistic Regression等)来说尤其重要,因为这些算法不应受到不均匀缩放数据集的影响。
Normalizatioin,也称归一化。 但与标准化有区别的。归一化主要目的是将数据映射到特定的范围,通常是[0,1]或[-1,1]。标准化更适用于那些特征值分布接近正态分布的情况。而归一化则更适用于那些数据范围有限或需要限制输出范围的情况。
但很多文档中,也将Normalizaiton 归为标准化的方法中。
标准化方式:
Z-score标准化(标准差标准化):这是最常用的标准化方法之一。这种方法对于大多数基于梯度的优化算法(如神经网络和逻辑回归)非常有效,因为它可以确保每个特征在模型中具有相同的权重。
Scaling 缩放技术
Min-max标准化(最小-最大标准化):它通过缩放特征值,使其落在[0,1]的范围内。具体实现是将每个特征值减去其最小值,然后除以其最大值与最小值之差。这种方法适用于那些需要限制数据范围或输出范围的情况,例如某些图像处理和信号处理的任务。
MaxAbsScaler:原理:将每个特征值缩放到[-1, 1]区间,通过除以每个特征的最大绝对值实现。如果数据集中有很大的异常值,使用MaxAbsScaler可能是一个好选择,因为它不会受到异常值的影响。
A)StandardScaler 基本标准化方法
计算z score, 分布转为标准正态分布
示例:
import numpy as np
from sklearn.preprocessing import StandardScaler
# 假设的数据集
data = np.array([[170, 60], [180, 70], [165, 55], [175, 65]])
# 创建StandardScaler对象
scaler = StandardScaler()
# 对数据进行标准化处理
standardized_data = scaler.fit_transform(data)
print(standardized_data)
# 查看标准化之后的数据,均值为0, 标准差为1
>>> standardized_data.mean(axis=0)
array([0., 0., 0.,0.])
>>> standardized_data.std(axis=0)
array([1., 1., 1.])
B)Min-Max 缩放
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1], 或[-1,1]之间。
其使用方法与standardScalar()相似
scaler = MinMaxScaler()
# 假设的数据集
data = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
# 对数据进行归一化处理
normalized_data = scaler.fit_transform(data)
输出数据的每个特征值都位于[0,1]区间内
如果你想要将数据缩放到不同的范围,例如[-1, 1],你可以在创建MinMaxScaler对象时指定feature_range参数:
scaler = MinMaxScaler(feature_range=(-1, 1))
normalized_data = scaler.fit_transform(data)
C)MaxAbsScaler缩放
原理:将每个特征值缩放到[-1, 1]区间,通过除以每个特征的最大绝对值实现。
示例:如果数据集中有很大的异常值,使用MaxAbsScaler可能是一个好选择,因为它不会受到异常值的影响。
from sklearn.preprocessing import MaxAbsScaler
scaler = MaxAbsScaler()
scaled_data = scaler.fit_transform(data)
D)Mean Removal均值移除
data_standardized=preprocessing.scale(data)
均值移除之后的矩阵每一列的均值约为0,而std为1。这样做的目的是确保每一个特征列的数值都在类似的数据范围之间,防止某一个特征列数据天然的数值太大而一家独大。
E)归一化
就是归一化是将单个样本缩放到具有单位范数的过程
normalize函数提供了一个快速简便的方法,用于在单个类似数组的数据集上执行此操作, 范数可以使用l1, l2, max,
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> X_normalized = preprocessing.normalize(X, norm='l2')
>>> X_normalized
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
L2 Normalisation
L2 normalization(也称为欧氏距离归一化)是一种常用的技术,它通过对特征向量进行缩放,使得每个样本的L2范数(即欧几里得范数)等于一个特定的值,通常是1。这有助于确保模型不会偏向于具有较大范数的特征,从而改进模型的表现。
在sklearn库中,Normalizer类提供了一个norm参数,可以设置为’l2’来执行L2 normalization。
Sklearn 也提供了1个Normlizer 类,可通过Normlizer.transform()方法进行归一化操作
Normalizer类提供了一个norm参数,可以设置为’l2’来执行L2 normalization。
normalizer = Normalizer(norm='l2')
normalized_data = normalizer.transform(X)
(3)缺失值处理–插值:
imp=SimpleImputer(missing_values=np.nan, strategy=’mean’)
impute.SimpleImputer进行缺失值处理,其中参数miss_values是告诉SimpleImputer,数据中缺失值长什么样,默认是np.nan;参数strategy是缺失值插补策略,有mean,median,most_frequent,constant插补,其中前两个均值和中位数只能在数值型中插补,后两个众数和特定值可以在数值型和字符型中都可以插补,特定值是在参数fill_value中输入的值,参数copy是否创建副本,默认True是创建,如果为False则会覆盖原数据
(4)处理异常数据 Outlier data
Outlier data, far bigger or less than rest data in dataset. 有几种方式可以处理
方式1: 用pandas处理
删除异常行
df = pd.DataFrame({
'feature1': [1, 2, 3, 4, 500], # 假设500是异常值
'feature2': [10, 20, 30, 40, 50],
'target': [0, 0, 1, 1, 1]
})
# 删除包含异常值的行
df = df[df['feature1'] < 100] # 删除'feature1'大于100的行
# 划分数据集
X = df[['feature1', 'feature2']]
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 用均值替代
import pandas as pd
import numpy as np
# 创建一个示例DataFrame
data = {'A': [1, 2, 3, 4, 500], 'B': [5, 6, 7, 8, 9], 'C': [10, 11, 12, 1000, 14]}
df = pd.DataFrame(data)
# 计算每列的均值
mean_values = df.mean()
# 定义一个函数来替换异常值
def replace_outliers_with_mean(series, threshold=1.5):
# 计算标准差
std_dev = series.std()
# 计算异常值的上下限
lower_limit = series.mean() - (threshold * std_dev)
upper_limit = series.mean() + (threshold * std_dev)
# 替换异常值为均值
series[series < lower_limit] = mean_values[series.name]
series[series > upper_limit] = mean_values[series.name]
return series
# 应用函数到DataFrame的每一列
df_replaced = df.apply(replace_outliers_with_mean)
print(df_replaced)
方式2: 使用IQR(四分位距)识别并处理异常值
import numpy as np
# 计算IQR并定义异常值范围
Q1 = df['feature1'].quantile(0.25)
Q3 = df['feature1'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
替换或删除异常值
df['feature1'] = np.where((df['feature1'] < lower_bound) | (df['feature1'] > upper_bound), np.nan, df['feature1']) # 替换为NaN
df = df.dropna() # 删除包含NaN的行
方式3: 使用sklearn的IsolationForest识别异常值:
IsolationForest是一种基于随机森林的异常值检测算法。
from sklearn.ensemble import IsolationForest
# 训练异常值检测器
clf = IsolationForest(contamination=0.1) # 假设数据集中10%是异常值
y_pred = clf.fit_predict(X)
# -1表示异常值,1表示正常值
outliers = X[y_pred == -1]
inliers = X[y_pred == 1]
# 处理异常值,例如删除它们
X = inliers
方式4: 使用中位数和IQR缩放或替换异常值:
对于数值特征,可以使用中位数和IQR的缩放因子来替换异常值。
def replace_outliers_with_iqr(df, column, factor=1.5):
Q1 = df[column].quantile(0.25)
Q3 = df[column].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - factor * IQR
upper_bound = Q3 + factor * IQR
df.loc[df[column] < lower_bound, column] = Q1 - factor * IQR
df.loc[df[column] > upper_bound, column] = Q3 + factor * IQR
return df
df = replace_outliers_with_iqr(df, 'feature1')
(5)分类特征数据的编码处理
很多场景中,特征数据不是数字值 ,而是离散的文本,如人的特征: [“male”, “female”], [“from Europe”, “from US”, “from Asia”], [“uses Firefox”, “uses Chrome”, “uses Safari”, “uses Internet Explorer”]. 可以用1个数字来代表某个文本,将其编码为. 如
[“male”, “from US”, “uses Internet Explorer”] ==》 [0, 1, 3]
[“female”, “from Asia”, “uses Chrome”] ==> [ 1, 2, 1]
OrdinalEncoder 序列编码器
enc = preprocessing.OrdinalEncoder()
X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
enc.fit(X)
enc.transform([['female', 'from US', 'uses Safari']])
输出:
array([[0., 1., 1.]])
标签编码
preprocessing.LabelEncoder:标签专用,能够将分类转换为数值型数据
对数字编码

对字符串编码

OneHot独热编码
与类别编码相似,会把每一个类别特征变换成一个新的整数数字特征,并以One-Hot格式输出,常用的参数:
- categories
- ‘auto’ : 根据训练集自动确定各列特征的类别数
- list : 手动枚举每列特征,这样即使训练集中没有出现过,特能进行编
- sparse:表示编码的格式,默认为 True,即为稀疏的格式,指定 False 则就不用 toarray() 了
- handle_unknown:其值可以指定为 “error” 或者 “ignore”,即如果碰到未知的类别,是返回一个错误还是忽略它。
from sklearn.preprocessing import OneHotEncoder
# 构造数据
X_train = [['male', 'from US', 'uses Safari'],
['female', 'from Europe', 'uses Firefox'],
['female', 'from China', 'uses Safari']]
# 编码器
encoder = OneHotEncoder()
encoder = encoder.fit(X_train)
# 编码
X = [['female', 'from Europe', 'uses Safari']]
X_transform = encoder.transform(X)
X_transform.toarray() # 默认返回的是稀疏矩阵, 用toarray()方法可以转为np.array格式
>> array([[1., 0., 0., 1., 0., 0., 1.]])
如果指定categories 参数,
>>> genders = ['female', 'male']
>>> locations = ['from Africa', 'from Asia', 'from Europe', 'from US']
>>> browsers = ['uses Chrome', 'uses Firefox', 'uses IE', 'uses Safari']
>>> enc = preprocessing.OneHotEncoder(categories=[genders, locations, browsers])
>>> # Note that for there are missing categorical values for the 2nd and 3rd
>>> # feature
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X) # onehot长度:各category元素按顺序排列。
OneHotEncoder(categories=[['female', 'male'],
['from Africa', 'from Asia', 'from Europe',
'from US'],
['uses Chrome', 'uses Firefox', 'uses IE',
'uses Safari']])
>>> enc.transform([['female', 'from Asia', 'uses Chrome']]).toarray()
array([[1., 0., 0., 1., 0., 0., 1., 0., 0., 0.]])
(6)discretization离散化(分箱)
有的数据,局部是连续的,整体不是连续的。 可以将连续特征划分为离散值。
K-bins discretization
X = np.array([[ -3., 5., 15 ],
… [ 0., 6., 14 ],
… [ 6., 3., 11 ]])
est = preprocessing.KBinsDiscretizer(n_bins=[3, 2, 2], encode=‘ordinal’).fit(X)
缺少输出是采用one-hot编码的矩阵,
PCA 主成分分析
PCA(Principal Component Analysis,主成分分析)主要用于数据的降维。PCA的主要思想是将n维特征映射到k维上(k<n),这k维是全新的正交特征,是重新构造出来的k维特征,而不是简单地从n维特征中去除其余n-k维特征。这k维特征称为主成分,是原始特征的线性组合。
PCA的工作原理是,通过对原始特征空间进行线性变换,寻找一组新的正交基,这组正交基就是主成分。新的特征空间是由这些主成分构成的,并且新空间的维度(即主成分的数量)通常小于原始特征空间的维度。通过这种方式,PCA可以有效地降低数据的维度,同时保留数据中的主要变化信息。
其数学基础:
Variance and Convariance
Eigen Vectors and Eigen values
算法实现步骤:
1) 把数据集分为X, Y 两部分, X做为 train 或 study, Y做为验证数据
2) 把X数据集转换成2维数组
3) Standize datasite
4) 求协方差
5) 计算特征向量与特征值
6) 排序特征向量
7) 计算新的features,
8) 在新数据集去除不重要的feature
在sklearn实现PCA非常简单:
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加载iris数据集
iris = load_iris()
X = iris.data
y = iris.target
# 初始化PCA,设置目标维度为2
pca = PCA(n_components=2)
# 对数据进行PCA降维
X_pca = pca.fit_transform(X)
![[HNCTF 2022 WEEK2]来解个方程?](https://img-blog.csdnimg.cn/direct/b62b92076b114dde893ff82b8d194d19.png)