引言
前文曾说过,Clickhouse是一个强大的数据库Clickhouse-一个潜力无限的大数据分析数据库系统
其中一个强大的点就在于支持各类表引擎以用于不同的业务场景。
MergeTree
MergeTree系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
其主要特点:
- 存储的数据按主键排序。
- 这使得您能够创建一个小型的稀疏索引来加快数据检索。
- 如果指定了分区键的话,可以使用分区。
- 在相同数据集和相同结果集的情况下 ClickHouse 中某些带分区的操作会比普通操作更快。查询中指定了分区键时 ClickHouse 会自动截取分区数据。这也有效增加了查询性能。
- 支持数据副本。
- 支持数据采样。
MergeTree表引擎的基础建表语句如下
CREATE TABLE table_name
(
`column_1` String,
`column_2` Int32,
`column_3` String
)
ENGINE = MergeTree
PARTITION BY column
ORDER BY column
- ORDER BY:排序键,可以是单列或多列。通常没有显示指定主键的情况下,我们会指定一个排序键,Clickhouse也会自动使用排序键作为主键
- PARTITION BY:分区键。通常使用Clickhouse都会存储“大数据”,既然是大数据,用分区来隔离数据会大大提升后续查询效率。多半用月分区的情况下, 可使用表达式toYYYYMM(date_column)来实现。
还有更多参数可选配,请参考
Clickhouse-MergeTree
ReplacingMergeTree
ReplacingMergeTree与MergeTree的不同在于它会删除排序键值相同的重复数据。
数据的去重只会在数据合并期间进行。但是合并会在后台一个不确定的时间进行,所以数据并不是有规律的进行删除\合并。
当然Clickhouse支持使用OPTIMIZE进行手动合并数据,不过会引起对数据的大量读写(建议在业务低峰期执行)。
ReplacingMergeTree的建表语句通常为
CREATE TABLE table_name
(
`column_time` DateTime,
`column_order` Int32,
`vd` String
)
ENGINE = ReplacingMergeTree(column_time)
PARTITION BY vd
ORDER BY column_order
数据合并(去重)策略为,当order by 字段重复时,保留ReplacingMergeTree字段最大的一条
测试看下效果
1、建表
CREATE TABLE t1
(
`column_time` DateTime,
`column_order` Int32,
`vd` String
)
ENGINE = ReplacingMergeTree(column_time)
PARTITION BY vd
ORDER BY column_order
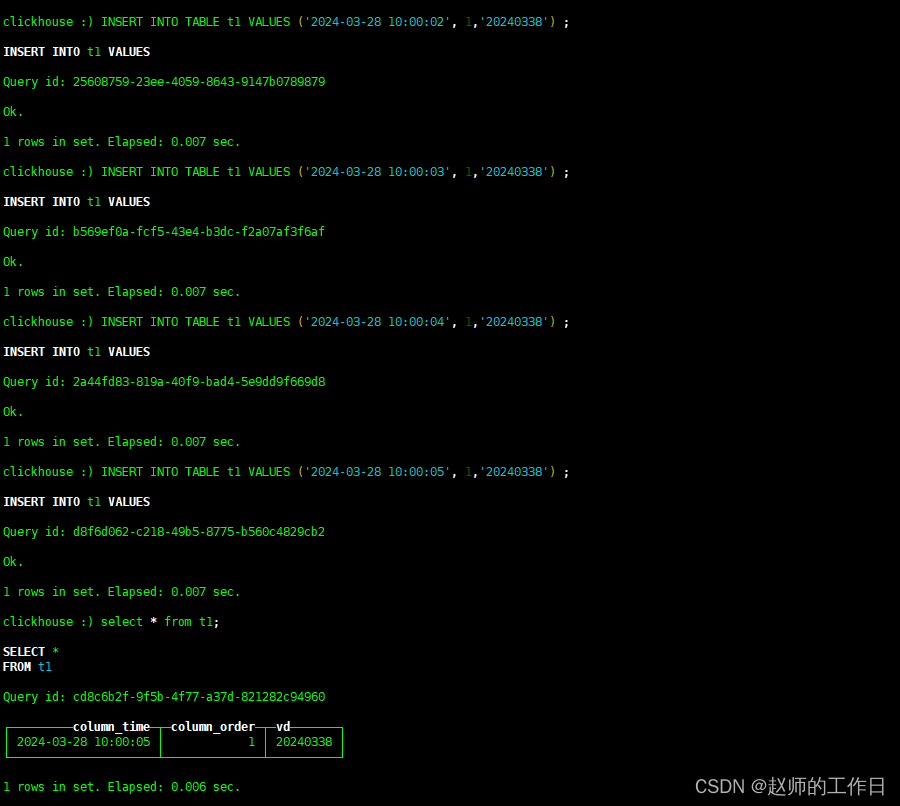
2、插入数据
INSERT INTO TABLE t1 VALUES ('2024-03-28 10:00:01', 1,'20240338') ;
INSERT INTO TABLE t1 VALUES ('2024-03-28 10:00:02', 1,'20240338') ;
INSERT INTO TABLE t1 VALUES ('2024-03-28 10:00:03', 1,'20240338') ;
INSERT INTO TABLE t1 VALUES ('2024-03-28 10:00:04', 1,'20240338') ;
INSERT INTO TABLE t1 VALUES ('2024-03-28 10:00:05', 1,'20240338') ;
3、验证
可以看到表中最终只有(‘2024-03-28 10:00:05’, 1,‘20240338’)这条数据
彩蛋
在文章开头,MergeTree之所谓被称为系列,是因为在Clickhouse由MergeTree衍生出了很多相关类型的引擎
- MergeTree
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- GraphiteMergeTree
其他引擎后续有机会在生产验证后再与大家分享。









![[flink 实时流基础]源算子和转换算子](https://img-blog.csdnimg.cn/img_convert/b6b3026c6ba5c3c64079df5c81888e22.png)