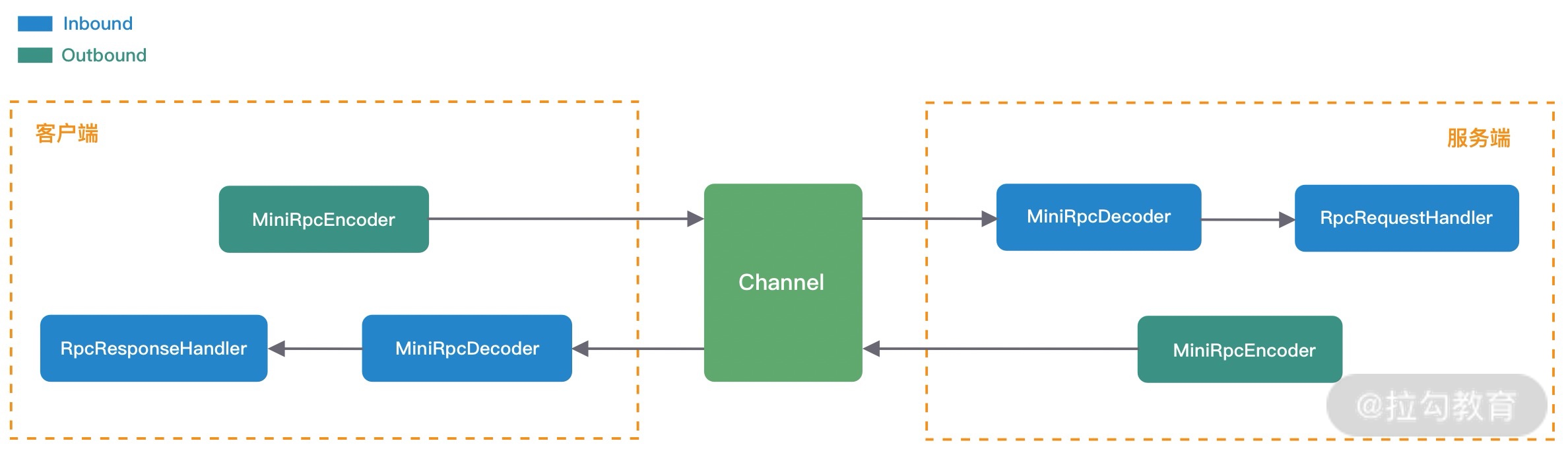
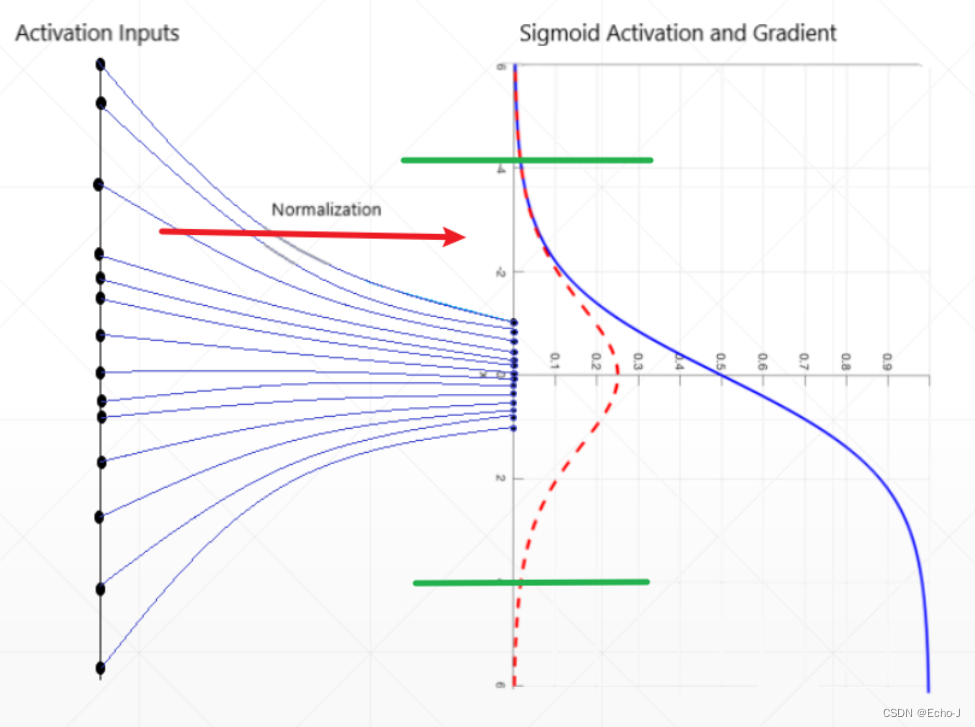
由于Sigmoid函数在两边存在梯度趋于零的特性,这种特性会使梯度长久得不到更新,造成梯度离散的现象,如何处理这一种现象?压缩数据使数据位于Sigmoid梯度不趋于0区间,即批量正则化(Batch Norm )(图-1)。
图像正则化(image normalization)
在均值为0时最有利于搜索最优解。深度学习中,图像的像素值位于[0, 1]区间,如何将像素值均值为0?pytorch提供了transforms.normalization()方法,将像素值正则化为正态分布N(0,1),代码演示如下:
normalize = transformers.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])在这个代码中的均值mean和方差std都是经过统计而来,transforms.normalization()方法内部原理是什么?首先,将均值的三个值分别看成R G B通道,然后,将每个通道的输入值减去本通道均值,除于本通道方差,即可得到(公式-1)。


批量正则化(batch normalization)
将数据定义为[N, C, H, W]
Batch Norm :在每个通道求均值,求方差(图-2)

第一部分是进行标准的正态分布计算(公式-2) ,第二部分是得到正态分布(公式-3)。



代码实现:
import torch
x = torch.randn(100,16)+0.5
layer = torch.nn.BatchNorm1d(16) # 创建一个包含16个特征的批归一化层
print(layer.running_mean,layer.running_var)
out = layer(x) # 将输入张量x传入批归一化层,得到输出张量out
print(layer.running_mean,layer.running_var) # 显示批归一化层的running_mean和running_var的更新值不断迭代更新:
import torch
x = torch.randn(100,16)+0.5
layer = torch.nn.BatchNorm1d(16)
for i in range(100):
out=layer(x)
print(layer.running_mean,layer.running_var)torch.nn.BatchNorm2d:
import torch
x = torch.randn(1,16,7,7)
print(x.shape)
layer = torch.nn.BatchNorm2d(16)
out=layer(x)
print(out.shape)
print(layer.weight)
print(layer.weight.shape)
print(layer.bias.shape)torch.nn.BatchNorm2d和torch.nn.BatchNorm1d是PyTorch中用于对输入进行批标准化的模块,它们的主要区别在于处理的输入数据的维度不同。
torch.nn.BatchNorm1d用于对输入数据的第二个维度(通常是特征维度)进行批标准化,适用于输入数据为一维的情况,比如全连接层的输入。
torch.nn.BatchNorm2d用于对输入数据的后两个维度(通常是高度和宽度)进行批标准化,适用于输入数据为二维的情况,比如卷积层的输出。
因此,如果输入数据是二维的,比如图像数据,应该使用torch.nn.BatchNorm2d来对其进行批标准化;如果输入数据是一维的,比如文本数据,应该使用torch.nn.BatchNorm1d来对其进行批标准化。
vars(layer):
可用其查看当前操作情况
vars(layer)
总结:

在训练时使用正则化,但是为了在测试中得到更好的测试效果,需要终止这种行为。
使用eval()方法,代码示例:
layer.eval()其它
Layer Norm :对每个实例求均值,求方差(图-5)

Instance Norm:对一个实例的一个通道求均值,求方差 (图-6)

Group Norm:对一个实例的几个通道求均值,求方差(图-7)

优点
1、收敛速度快(不处于sigmoid饱和区)
2、更好的性能(图-8)
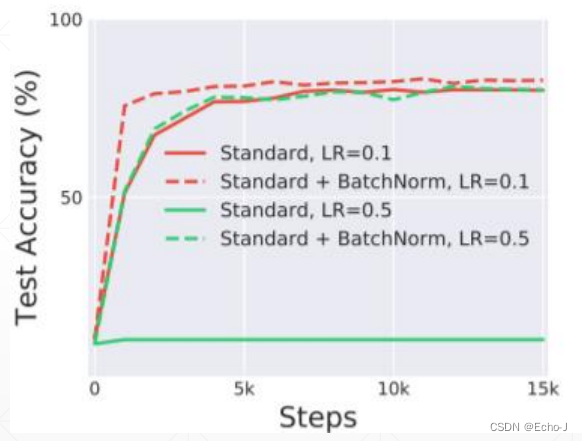
3、得到的模型更加健壮,可以设置更大的学习率
参考:课时88 RNN Layer使用-1_哔哩哔哩_bilibili





![[flink 实时流基础]源算子和转换算子](https://img-blog.csdnimg.cn/img_convert/b6b3026c6ba5c3c64079df5c81888e22.png)