🔥个人主页:Quitecoder
🔥专栏:Leetcode刷题

本节内容我们来讲解常见的几道单链表的题型,文末会赋上单链表增删查,初始化等代码
目录
- 1.移除链表元素
- 2.链表的中间节点
- 3.返回倒数第K个节点:
- 4.环形链表(判断)
- 5.环形链表(判断加返回)
- 5.1环的起始节点推导过程
- 6.相交链表
- 7.随机链表的复制
- 8.反转链表
- 方法一:迭代法
- 方法二:递归法
- 9.合并两个有序链表
1.移除链表元素
题目链接: 203.移除链表元素
题目描述:
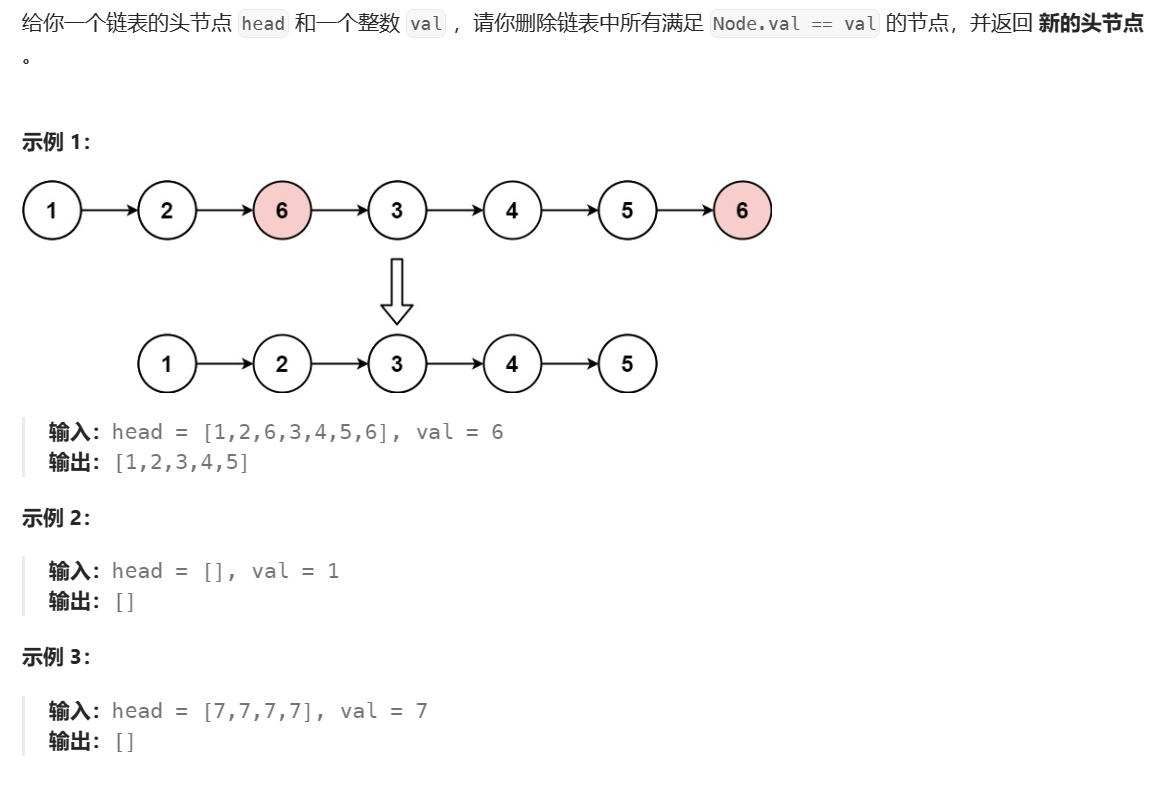
首先,这道题需要删除元素,我可以初始化一个结构体指针cur进行遍历链表,对于每个节点,检查它的值是否等于val,如果cur指向的节点值等于val,则需要删除这个节点,这里一个结构体指针是不够的,是因为单链表的单向性,我们则需要再定义另一个指针prev来实现
首先,定义并初始化两个结构体指针:
struct ListNode* cur = head;
struct ListNode* prev = NULL;
定义两个指针cur(当前节点指针)和prev(前一个节点指针)。cur初始化为指向头节点head,而prev初始化为NULL
在这个删除链表中指定值节点的函数中,prev指针被初始化为NULL是出于以下几个原因:
-
表示头节点之前:链表的头节点之前没有节点,所以在遍历开始之前,
prev指向“虚拟的”头节点之前的位置,这在逻辑上用NULL表示 -
处理头节点可能被删除的情况:如果链表的头节点(第一个节点)就是需要删除的节点,那么在删除头节点后,新的头节点将是原头节点的下一个节点。因为头节点没有前一个节点,所以使用
NULL作为prev的初始值可以帮助我们处理这种情况。在代码中,如果发现头节点需要被删除(cur->val == val且prev == NULL),就将头节点更新为下一个节点 -
简化边界条件的处理:通过将
prev初始化为NULL,我们可以用统一的方式处理需要删除的节点是头节点的情况和位于链表中间或尾部的情况。这样,当prev不是NULL时,就意味着我们不在头节点,可以安全地修改prev->next来跳过需要删除的cur节点
紧接着进行遍历过程:
while (cur != NULL) {
if (cur->val == val) {
struct ListNode* next = cur->next;
free(cur);
if (prev != NULL) {
prev->next = next;
}
else
{
head = next;
}
cur = next;
}
else {
prev = cur;
cur = cur->next;
}
}
- 如果
cur指向的节点值等于val,则需要删除这个节点。首先,保存cur的下一个节点到临时变量next中。如果prev不是NULL(即当前节点不是头节点),则将prev->next设置为next,跳过当前节点,从而将其从链表中删除。如果prev是NULL(即当前节点是头节点),则需要更新头节点head为next - 释放(删除)当前节点
cur所占用的内存。 - 将
cur更新为next,继续遍历链表
节点值不等于val:如果当前节点值不等于val,则cur和prev都前进到下一个节点
2.链表的中间节点
题目链接: 876.链表的中间节点
题目描述:
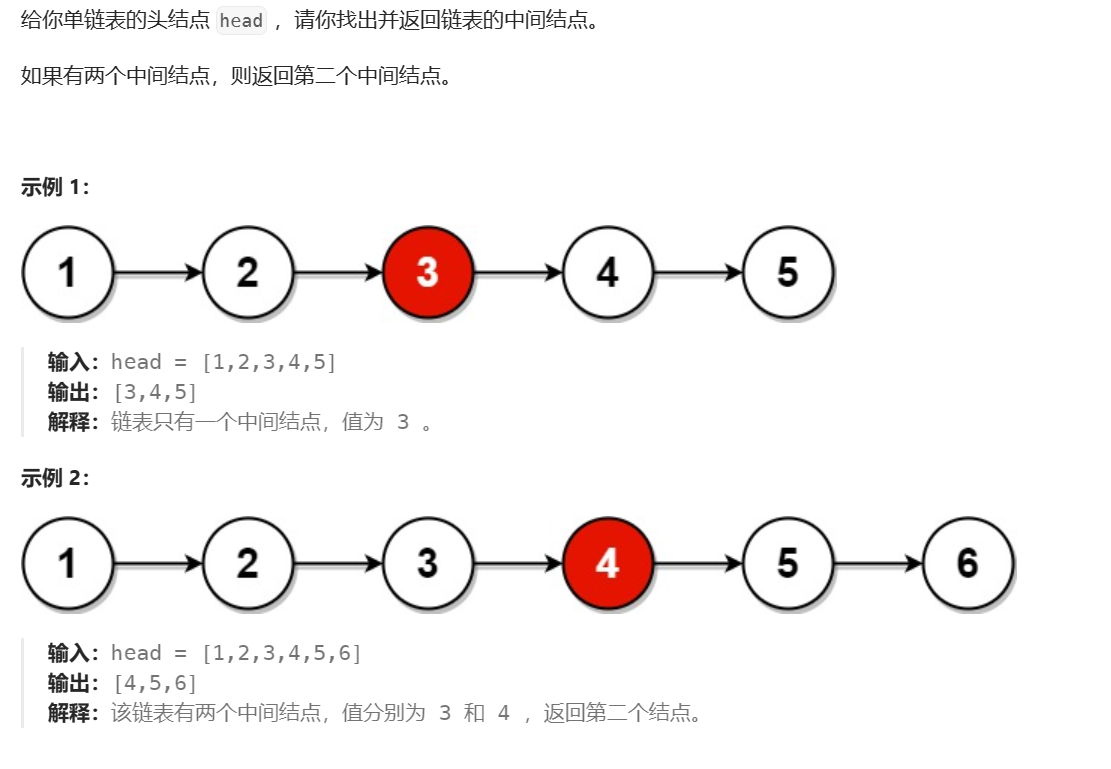
我们这道题用到了快慢指针的思路:
设置一个快指针,一次走两步,慢指针一次走一步,当节点个数为奇数时,意味着我的快指针指向尾节点,慢指针指向中间节点,此时的判断条件为快指针节点的next指针指向空
当节点个数为偶数时,意味着当我快指针刚好为空时,慢指针走到中间第二个节点,所以代码如下:
struct ListNode* middleNode(struct ListNode* head) {
struct ListNode* slow = head;
struct ListNode* fast = head;
while (fast != NULL && fast->next != NULL) {
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
注意
来看这个判断条件:
while (fast != NULL && fast->next != NULL)
这里能不能交换呢?:
while (fast->next != NULL && fast != NULL)
上面的代码片段错误之处在于 while 循环中条件判断的顺序。特别是在判断 fast 不为 NULL 以及 fast->next 不为 NULL 的时候
问题在于,当循环检查条件 fast->next != NULL && fast != NULL 时,它首先检查 fast->next 是否不为 NULL。如果 fast 本身是 NULL,那么尝试访问 fast->next 将会导致未定义行为(通常是一个访问违规错误,导致程序崩溃)。这是因为你试图访问一个 NULL 指针的成员,这在 C 和 C++ 中是不合法的。
正确的方式是首先检查 fast 是否为 NULL,然后再检查 fast->next 是否不为 NULL。这确保了代码不会试图在 NULL 指针上进行成员访问
3.返回倒数第K个节点:
题目链接: 面试题02.02.返回倒数第K个节点
题目描述:

简单思路:
设置两个指针,一个先走k步,再两个指针同时前移直到前一个指向空
int kthToLast(struct ListNode* head, int k)
{
struct ListNode*p1=head;
struct ListNode*p2=head;
while(k--)
{
p1=p1->next;
}
while(p1!=NULL)
{
p1=p1->next;
p2=p2->next;
}
return p2->val;
}
4.环形链表(判断)
题目链接: 141.环形链表
题目描述:
龟兔赛跑算法:
设置快指针一次前行两步,慢指针一次一步,若有环,则两个指针一定相遇:
bool hasCycle(struct ListNode *head) {
struct ListNode* fast = head;
struct ListNode* slow = head;
while (fast != NULL && fast->next != NULL) {
fast = fast->next->next; // 快指针每次前进两步
slow = slow->next; // 慢指针每次前进一步
if (fast == slow) { // 如果快慢指针相遇,表示链表有环
return true;
}
}
// 遍历完成没有找到环,返回 false
return false;
}
简单证明:当两个指针都入环时,快指针开始追赶慢指针,速度相差一,相对移动的距离为1,则一定能追上
5.环形链表(判断加返回)
题目链接: 142.环形链表II
题目描述:
环形链表中寻找环的起始节点的算法是基于“快慢指针”策略。这个算法分为两个主要阶段:
-
确定链表中是否存在环:
使用两个指针,slow和fast,它们初始时都指向链表的头节点head。然后,slow每次向前移动一个节点,而fast每次向前移动两个节点。如果链表中存在环,那么fast指针最终会再次与slow指针相遇(因为fast指针会从后面追上slow指针)。如果在任何时候fast指针遇到NULL(表示链表尾部),则链表中不存在环。 -
找到环的起始节点:
当slow和fast指针相遇时,我们可以确定链表中存在环。但要找到环的起始节点,我们可以使用下面的方法:- 在
slow和fast首次相遇后,将一个指针(比如slow2)放置在链表的起始处head,而将slow保留在相遇点。 - 然后同时将
slow2和slow每次向前移动一个节点,直到它们相遇。它们相遇的节点就是环的起始节点。
- 在
5.1环的起始节点推导过程
假设环外的长度(从头节点到环起始节点的长度)是L,从环起始节点到slow和fast首次相遇点的长度是S,环的剩余长度是R。因此,环的总长度C = S + R。
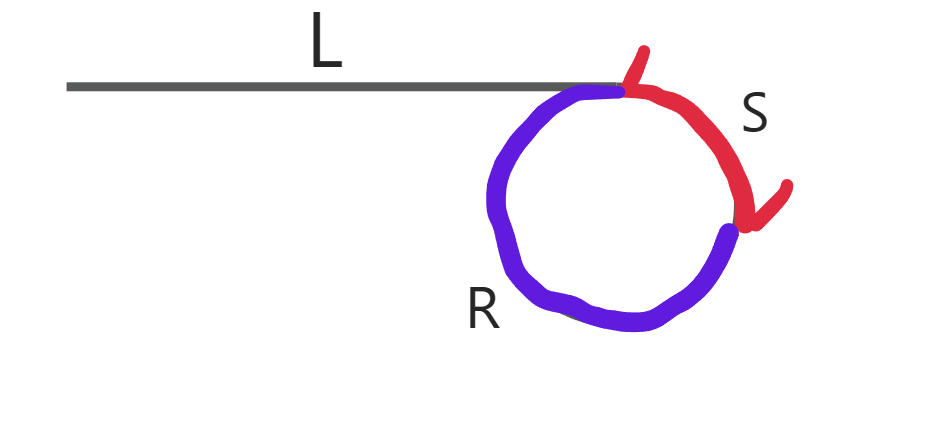
当slow和fast首次相遇时:
slow指针走过的长度是L + S。fast指针走过的长度是L + S + nC,其中n是fast指针在环中绕行的次数。
因为fast指针走的距离是slow指针的两倍,所以我们有:
[2(L + S) = L + S + nC]
通过简化这个方程,我们得到:
[L + S = nC]
或者
[L = nC - S]
这个方程告诉我们从头节点到环的起始节点的距离L,等同于从首次相遇点继续前进直到再次回到环起始节点的距离(即n圈环长度减去首次相遇点到环起始节点的距离S)。这就是为什么当我们将一个指针放在链表头部,另一个保留在首次相遇点,它们以相同的速度移动时,它们相遇的点就是环的起始节点
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode *slow = head, *fast = head;
while (fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
if (slow == fast) {
struct ListNode *slow2 = head;
while (slow2 != slow) {
slow = slow->next;
slow2 = slow2->next;
}
return slow;
}
}
return NULL;
}
6.相交链表
题目链接: 160.相交链表
题目描述:
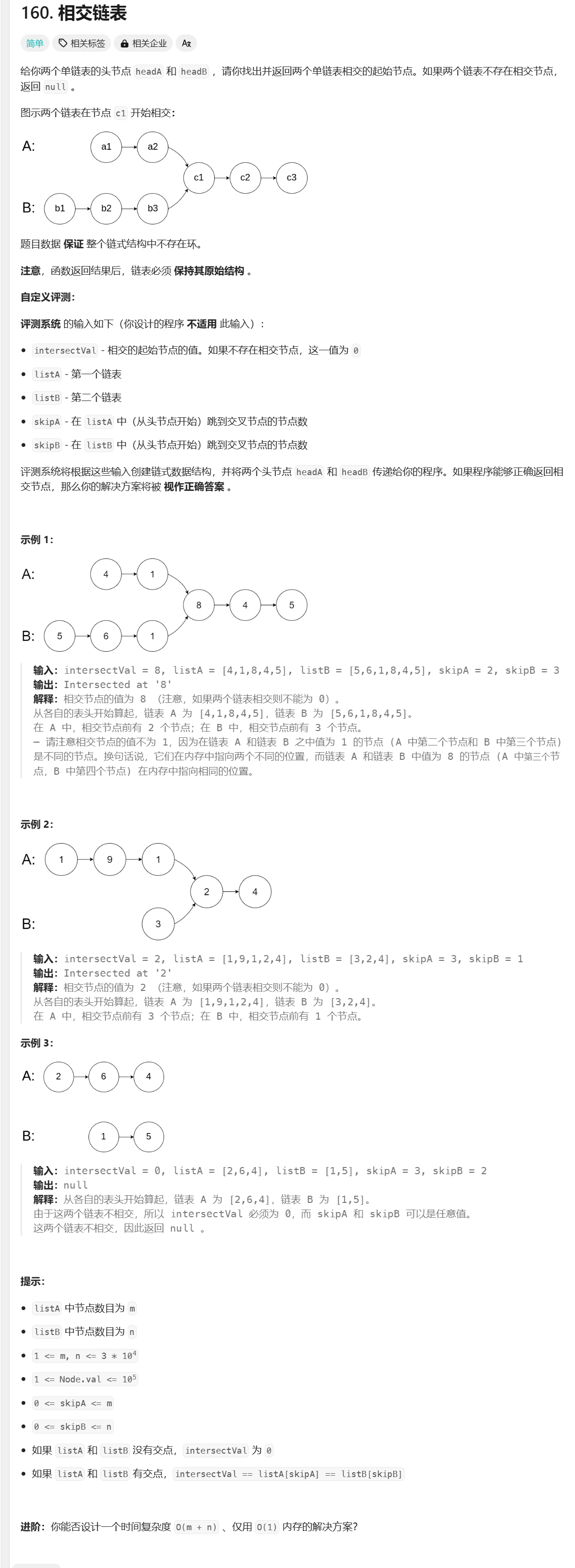
思路:
相交链表指的是两个链表在某一点开始合并成一个链表。这意味着从相交点到链表的末尾,这两个链表都具有相同的节点
解决相交链表问题的一个有效方法是使用两个指针遍历两个链表。以下是实现这一思路的步骤:
- 创建两个指针
创建两个指针,p1和p2,分别指向两个链表的头节点
- 同步遍历链表
同时移动两个指针,每步向前移动一次。如果一个指针到达链表末尾,则将其移动到另一个链表的头节点继续遍历。这样,两个指针会分别遍历两个链表的节点
- 相遇点或结束
- 如果两个链表相交,
p1和p2会在相交点相遇。这是因为p1和p2会遍历整个结构(两个链表的总长度),这样调整确保它们最终会有相同的遍历长度。当它们移动到相交点时,由于它们步调一致,因此会同时到达相交点。 - 如果链表不相交,
p1和p2最终都会到达各自链表的末尾并同时为NULL,这意味着它们没有相交点
- 如果两个链表相交,
假设链表A的非共享部分长度为
a,链表B的非共享部分长度为b,两个链表的共享部分长度为c。当p1和p2遍历完各自的链表后,它们会分别遍历对方的链表,所以它们各自遍历的总长度是a + c + b。这意味着无论a和b的长度差异如何,它们最终会同时到达相交点或链表的末尾。这个方法的优点是,它不需要知道两个链表的长度,也不需要额外的存储空间,只需要两个指针即可解决问题
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB)
{
if (headA == NULL || headB == NULL) {
return NULL;
}
struct ListNode *pA = headA, *pB = headB;
while (pA != pB) {
pA = pA == NULL ? headB : pA->next;
pB = pB == NULL ? headA : pB->next;
}
return pA;
}
7.随机链表的复制
题目链接: 138.随机链表的复制
题目描述:
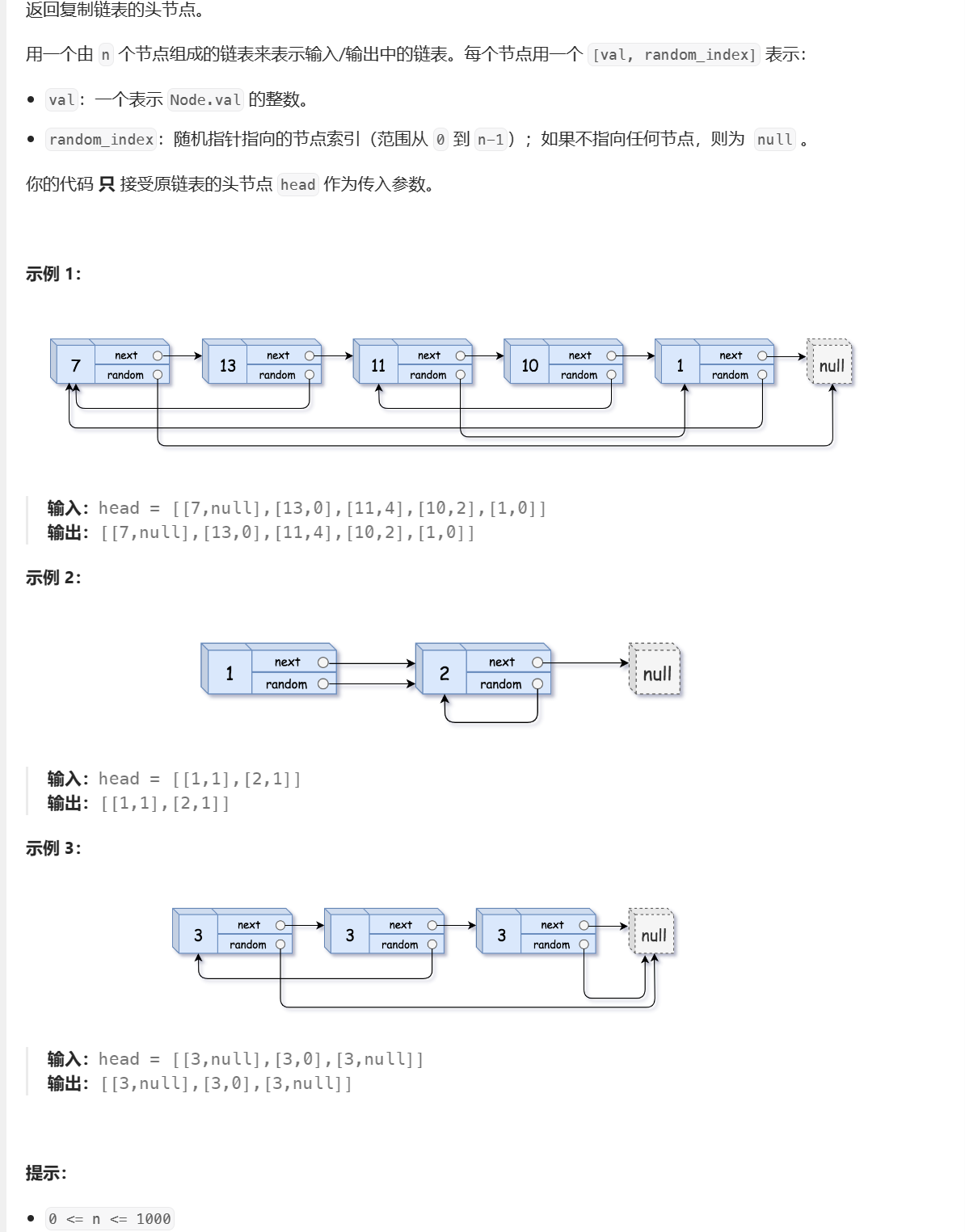
思路:
- 遍历原链表,为每个原节点创建一个新节点:这个新节点有相同的值,并将其插入到原节点和下一个原节点之间。
if (!head) return NULL;
struct Node* curr = head;
while (curr) {
struct Node* newNode = (struct Node*)malloc(sizeof(struct Node));
newNode->val = curr->val;
newNode->next = curr->next;
newNode->random=NULL;
curr->next = newNode;
curr = newNode->next;
}
- 更新新节点的random指针:由于每个新节点都紧跟在其对应的原节点后面,可以通过原节点的random指针找到新节点的random指针应该指向的节点
curr = head;
while (curr) {
if (curr->random) {
curr->next->random = curr->random->next;
}
curr = curr->next->next;
}
- 将混合链表拆分为原链表和复制链表:恢复原链表,并提取出复制链表
struct Node* pseudoHead = (struct Node*)malloc(sizeof(struct Node));
pseudoHead->next = head->next;
struct Node* copyCurr = pseudoHead->next;
curr = head;
while (curr) {
curr->next = curr->next->next;
if (copyCurr->next) {
copyCurr->next = copyCurr->next->next;
}
curr = curr->next;
copyCurr = copyCurr->next;
}
struct Node* copiedHead = pseudoHead->next;
free(pseudoHead);
return copiedHead;
解释
-
第一步:遍历原链表,对于每个节点创建一个新节点,将新节点插入原节点和原节点的下一个节点之间。
-
第二步:再次遍历链表,这次是为了设置新节点的random指针。因为每个新节点都位于其对应的原节点之后,可以通过原节点的random指针直接找到对应新节点的random目标节点。
-
第三步:将原链表和复制的链表分离。在这一步中,恢复原始链表的next指针,并将复制链表的next指针指向正确的节点
所以这道题只是逻辑复杂一点,并没有很难理解
8.反转链表
题目链接: 206.反转链表
题目描述:
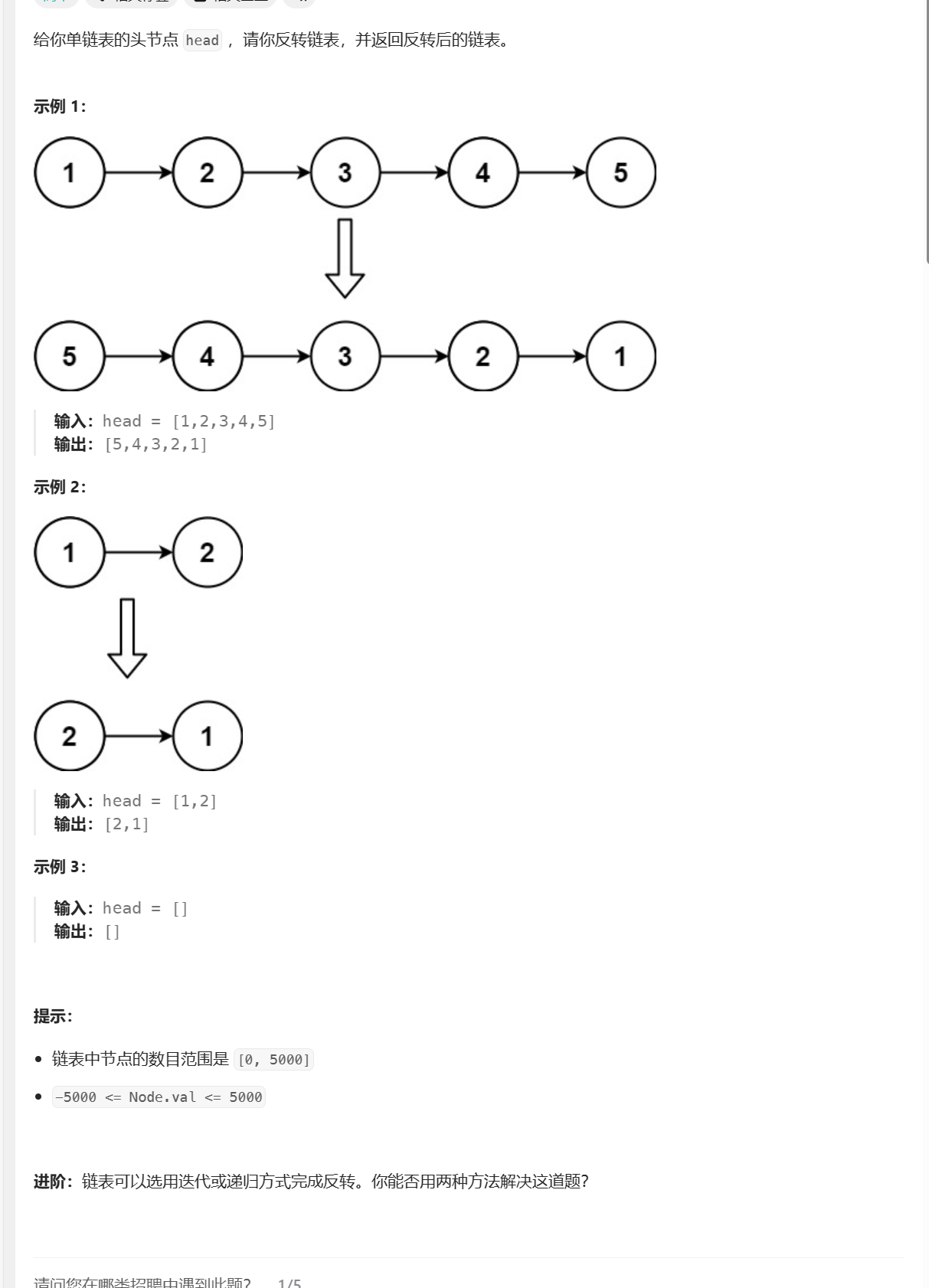
方法一:迭代法
迭代法通过遍历链表,逐个改变节点的指向来实现链表的反转。其基本思路如下:
-
初始化三个指针:
prev(指向当前节点的前一个节点,初始为NULL),curr(指向当前节点,初始为链表的头节点head),next(临时保存curr的下一个节点) -
遍历链表:在遍历过程中,逐个节点地改变指向,直到
curr为NULL -
更新指针:在每次迭代中,首先保存
curr的下一个节点(next = curr->next),然后改变curr的指向(curr->next = prev)。之后,移动prev和curr指针前进一步(prev = curr,curr = next) -
更新头节点:当遍历完成,
curr为NULL时,prev指向的是新的头节点
struct ListNode* reverseList(struct ListNode* head)
{
if(head==NULL)
return NULL;
struct ListNode*prev,*cur,*_next;
prev=NULL;
cur=head;
_next=head->next;
while(cur)
{
cur->next=prev;
prev=cur;
cur=_next;
if(_next)
_next=_next->next;
}
return prev;
}
方法二:递归法
递归法利用递归回溯的过程实现链表的反转。其基本思路如下:
-
递归基:如果链表为空或只有一个节点,直接返回当前节点作为新的头节点。
-
递归步骤:对于链表
head->...->n1->n2->...->null,假设从n1开始的链表已经被成功反转,即head->n1<-n2<-...<-newHead。我们的目标是将head节点放到最后,即n1->head->null并将n1的next设置为null。 -
执行反转:递归调用自身,传入
head->next作为新的链表头,直到链表末尾。然后设置head->next->next = head(这实现了反转),再将head->next设置为null(断开原来的连接) -
返回新的头节点:递归的最深处将返回新的头节点,每层递归都返回这个头节点,最终实现整个链表的反转
struct ListNode* reverseListRecursive(struct ListNode* head) {
// 递归基:如果链表为空或只有一个节点,没有反转的必要
if (head == NULL || head->next == NULL) {
return head;
}
// 递归步骤:假设head->next之后的链表已经被成功反转了
struct ListNode* newHead = reverseListRecursive(head->next);
// head->next此时指向反转后的链表的最后一个节点
// 将其next指针指回head,完成对head节点的反转
head->next->next = head;
// 断开原来head指向head->next的指针,防止形成环
head->next = NULL;
// 每一层递归返回新的头节点
return newHead;
}
9.合并两个有序链表
题目链接: 21.合并两个有序链表
题目描述:
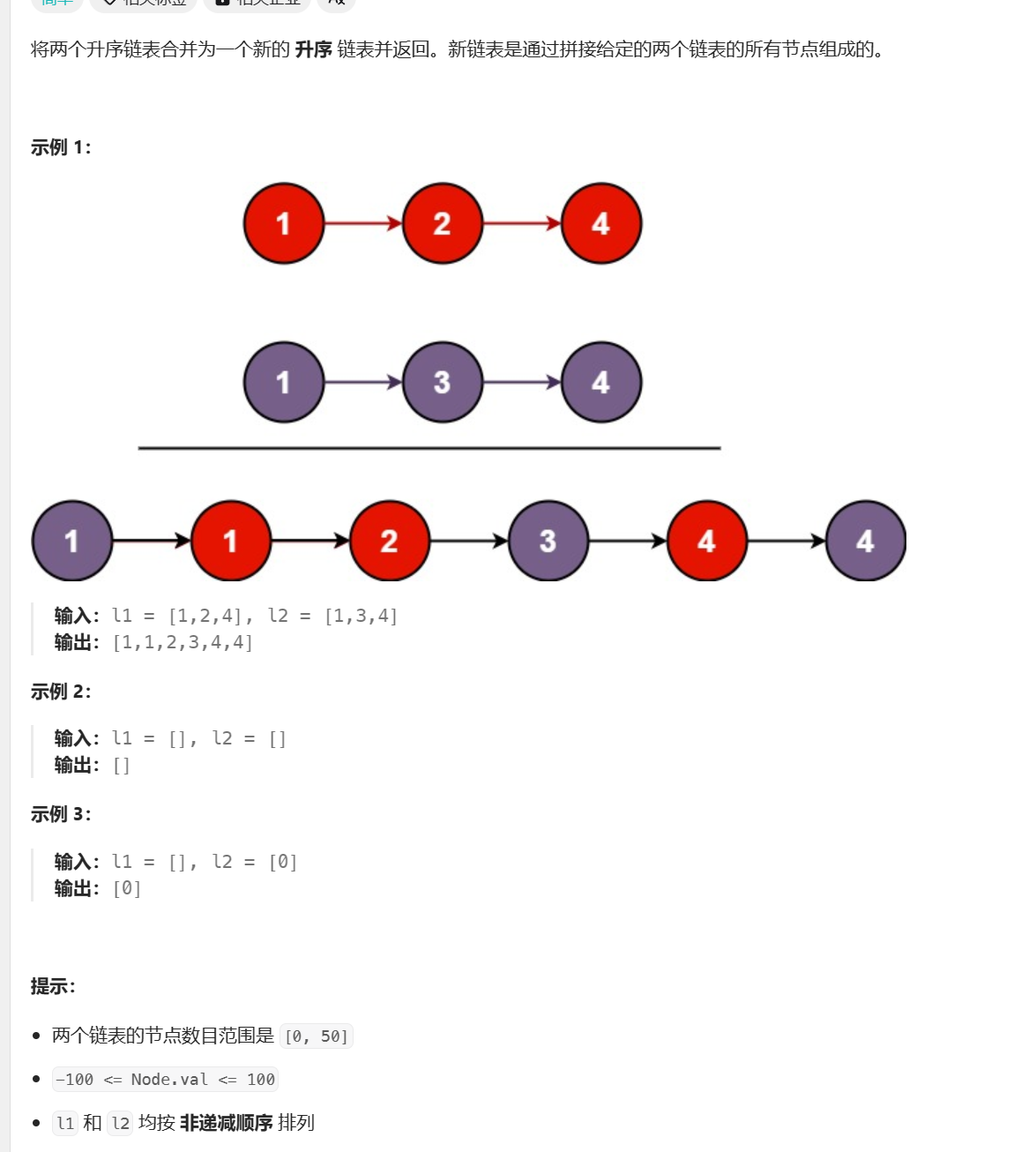
这里与我们归并排序的思路相似,设置两个指针分别遍历两个链表,取元素插入到新链表中,直到某个链表遍历完成
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2) {
struct ListNode *new ;
new->val = 0;
new->next = NULL;
struct ListNode *p3 = new;
struct ListNode *p1 = list1, *p2 = list2;
while (p1 && p2) {
if (p1->val < p2->val) {
p3->next = p1;
p1 = p1->next;
} else {
p3->next = p2;
p2 = p2->next;
}
p3 = p3->next;
}
p3->next = p1 ? p1 : p2;
struct ListNode *result = new->next; // 保存合并后链表的头节点
free(new); // 释放new节点占用的内存
return result; // 返回合并后的链表头节点
}
p3->next = p1 ? p1 : p2;这一步也是后面的关键,我不知道哪个链表遍历完,剩余一个链表还剩元素,我就需要将剩下的元素整体接入新链表中,这里就用三目运算符,如果p1不为空,则指向p1剩余元素,如果p1为空,则指向p2
本节内容到此结束,感谢大家阅读!!!