前言
大家好,我是jiantaoyab,这是我作为学习笔记原理篇的最后一章,一台计算机在数据中心里是不够的。因为如果只有一台计算机,我们会遇到三个核心问题。第一个核心问题,叫作垂直扩展和水平扩展的选择问题,第二问题叫作如何保持高可用性(High Availability),第三个问题叫作一致性问题(Consistency)。
垂直扩展和水平扩展
在云服务器上面租一个最低配置的1 个 CPU 核心、3.75G 内存以及一块 10G 的 SSD 系统盘,当这个服务器性能不够用的时候,可以选择升级现在这台服务器的硬件,变成 2 个 CPU 核心、7.5G 内存。这样的选择我们称之为垂直扩展。
第二个选择则是我们再租用一台和之前一样的服务器。于是,我们有了 2 台 1 个 CPU 核心、3.75G 内存的服务器。这样的选择我们称之为水平扩展。
不过,垂直扩展和水平扩展看似是两个不同的选择,但是随着流量不断增长。到最后,只会变成一个选择。那就是既会垂直扩展,又会水平扩展,并且最终依靠水平扩展,来支撑 Google、Facebook、阿里、腾讯这样体量的互联网服务。
一旦开始采用水平扩展,我们就会面临在软件层面改造的问题了。也就是我们需要开始进行分布式计算了。
我们需要引入负载均衡(Load Balancer)这样的组件,来进行流量分配。我们需要拆分应用服务器和数据库服务器,来进行垂直功能的切分。我们也需要不同的应用之间通过消息队列,来进行异步任务的执行
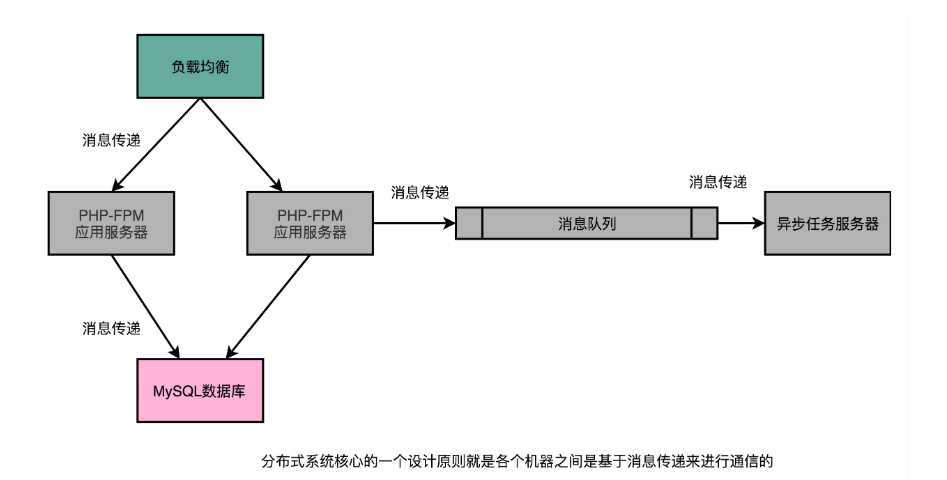
所有这些软件层面的改造,其实都是在做分布式计算的一个核心工作,就是通过消息传递(Message Passing)而不是共享内存(Shared Memory)的方式,让多台不同的计算机协作起来共同完成任务。
而因为最终必然要进行水平扩展,我们需要在系统设计的早期就基于消息传递而非共享内存来设计系统。即使这些消息只是在同一台服务器上进行传递。
理解高可用性和单点故障
上面的 1 核变 2 核的垂直扩展的方式,扩展完之后,我们还是只有 1 台服务器。如果这台服务器出现了一点硬件故障,比如,CPU 坏了,那我们的整个系统就坏了,就不可用了。
如果采用了水平扩展,即便有一台服务器的 CPU 坏了,我们还有另外一台服务器仍然能够提供服务。负载均衡能够通过健康检测(Health Check)发现坏掉的服务器没有响应了,就可以自动把所有的流量切换到第 2 台服务器上,这个操作就叫作故障转移(Failover),我们的系统仍然是可用的。
系统的可用性(Avaiability)指的就是,我们的系统可以正常服务的时间占比。无论是因为软硬件故障,还是需要对系统进行停机升级,都会让我们损失系统的可用性。可用性通常是用一个百分比的数字来表示,比如 99.99%。我们说,系统每个月的可用性要保障在 99.99%,也就是意味着一个月里,你的服务宕机的时间不能超过 4.32 分钟。
有些系统可用性的损失,是在我们计划内的。比如上面说的停机升级,这个就是所谓的计划内停机时间(Scheduled Downtime)。有些系统可用性的损失,是在我们计划外的,比如一台服务器的硬盘忽然坏了,这个就是所谓的计划外停机时间(Unscheduled Downtime)。
那我们先来看一看硬件服务器的可用性。
现在的服务器的可用性都已经很不错了,通常都能保障 99.99% 的可用性了。如果我们有一个小小的三台服务器组成的小系统,一台部署了 Nginx 来作为负载均衡和反向代理,一台跑了 PHP-FPM 作为 Web 应用服务器,一台用来作为 MySQL 数据库服务器。每台服务器的可用性都是 99.99%。那么我们整个系统的可用性是多少呢?你可以先想一想。
答案是 99.99% × 99.99% × 99.99% =99.97%。在这个系统当中,这个数字看起来似乎没有那么大区别。不过反过来看,我们是从损失了 0.01% 的可用性,变成了损失 0.03% 的可用性,不可用的时间变成了原来的 3 倍。
如果我们有 1000 台服务器,那么整个的可用性,就会变成 99.99% ^ 1000 = 90.5%。也就是说,我们的服务一年里有超过一个月是不可用的。这可怎么办呀?
我们先来分析一下原因。之所以会出现这个问题,是因为在这个场景下,任何一台服务器出错了,整个系统就没法用了。这个问题就叫作单点故障问题(Single Point of Failure,SPOF)。我们这里的这个假设特别糟糕。我们假设这 1000 台服务器,每一个都存在单点故障问题。所以,我们的服务也就特别脆弱,随便哪台出现点风吹草动,整个服务就挂了。
要解决单点故障问题,第一点就是要移除单点。其实移除单点最典型的场景,在我们水平扩展应用服务器的时候就已经看到了,那就是让两台服务器提供相同的功能,然后通过负载均衡把流量分发到两台不同的服务器去。即使一台服务器挂了,还有一台服务器可以正常提供服务。
不过光用两台服务器是不够的,单点故障其实在数据中心里面无处不在。我们现在用的是云上的两台虚拟机。如果这两台虚拟机是托管在同一台物理机上的,那这台物理机本身又成为了一个单点。那我们就需要把这两台虚拟机分到两台不同的物理机上。
不过这个还是不够。如果这两台物理机在同一个机架(Rack)上,那机架上的交换机(Switch)就成了一个单点。即使放到不同的机架上,还是有可能出现整个数据中心遭遇意外故障的情况。
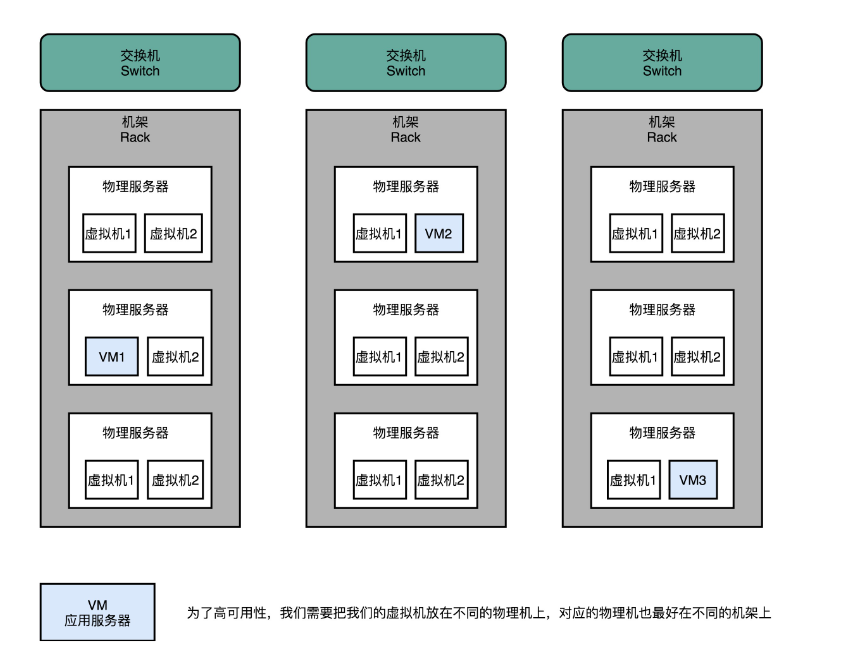
只是能够去除单点,其实我们的可用性问题还没有解决。比如,上面我们用负载均衡把流量均匀地分发到 2 台服务器上,当一台应用服务器挂掉的时候,我们的确还有一台服务器在提供服务。但是负载均衡会把一半的流量发到已经挂掉的服务器上,所以这个时候只能算作一半可用。
想要让整个服务完全可用,我们就需要有一套故障转移(Failover)机制。想要进行故障转移,就首先要能发现故障。
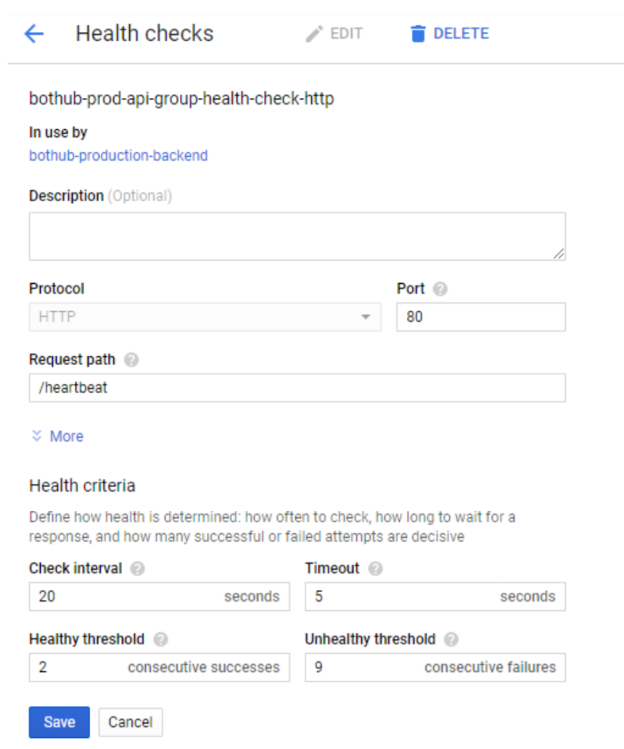
以我们这里的 PHP-FPM 的 Web 应用为例,负载均衡通常会定时去请求一个 Web 应用提供的健康检测(Health Check)的地址。这个时间间隔可能是 5 秒钟,如果连续 2~3 次发现健康检测失败,负载均衡就会自动将这台服务器的流量切换到其他服务器上。
于是,我们就自动地产生了一次故障转移。故障转移的自动化在大型系统里是很重要的,因为服务器越多,出现故障基本就是个必然发生的事情。而自动化的故障转移既能够减少运维的人手需求,也能够缩短从故障发现到问题解决的时间周期,提高可用性。