前言
关系代数的一项重要操作是连接运算,多个表连接是建立在两表之间连接的基础上的。研究两表连接的方式,对连接效率的提高有着直接的影响。
连接方式是一个什么样的概念,或者说我们为何要有而且有好几种,对于不太了解数据库的人来讲可能这些是开头的疑惑。简单来讲,我们将数据存在不同的表中,而不同的表有着它们自身的表结构,不同表之间可以是有关联的,大部分实际使用中,不会仅仅只需要一张表的信息,比如需要从一个班级表中找出杭州地区的学生,再用这个信息去检索成绩表中他们的数学成绩,如果没有多表连接,那只能手动将第一个表的信息查询出来作为第二个表的检索信息去查询最终的结果,可想而知这将会是多么繁琐。
对于几个常见的数据库,像 oracle,postgresql 它们都是支持 Hash-Join 的,MySQL 8.0.18 之前的版本并不支持,之后版本也开始支持 Hash-Join。Hash-Join 本身的实现并不是很复杂,但是它需要优化器的实现配合才能最大的发挥本身的优势,我觉得这才是最难的地方。
多表连接的查询方式又分为以下几种:内连接,外连接和交叉连接。外连接又分为:左外连接,右外连接和全外连接。对于不同的查询方式,使用相同的 join 算法也会有不同的代价产生,这个是跟实现方式紧密相关的,需要考虑不同的查询方式如何实现,对于具体使用哪一种连接方式是由优化器通过代价的衡量来决定的,后面会简单介绍一下几种连接方式代价的计算。 Hash-Join 其实还有很多需要考虑和实现的地方,比如数据倾斜严重如何处理、内存放不下怎木办,hash如何处理冲突等。
各种内、外连接的查询方式和语法请参考:MySQL学习笔记 ------ 连接查询_查询有奖金的员工名,部门名-CSDN博客
通常实现连接查询的算法有三种:嵌套循环连接(Nested Loop Join)、Hash 连接(Hash Join)以及归并连接(Sort Merge Join)。不同数据库:MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite 对三种连接算法的支持情况如下:
| Join 实现算法 | MySQL | Oracle | SQL Server | PostgreSQL | SQLite |
| Nested Loop Join | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| Hash Join | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| Sort Merge Join | ❌ | ✔️ | ✔️ | ✔️ | ❌ |
嵌套循环连接算法
嵌套循环连接,是比较通用的连接方式,分为内外表,每扫描外表的一行数据都要在内表中查找与之相匹配的行,没有索引的复杂度是 O(N*M),这样的复杂度对于大数据集是非常劣势的,一般来讲会通过块、索引来提升性能。
简单嵌套循环连接算法(Simple Nested-Loop Join)
两表做连接,采用的最基本算法是嵌套循环连接算法。算法的描述如下:
// 每次都从存储系统读入,消耗 IO
for each row r1 in t1 { // r1 表示记录
for each row r2 in t2 {
if r1, r2 satisfies join conditions
join r1, r2
}
}数据库引擎在实现该算法的时候,以元组为单位进行连接。元组是从一个内存页面获取来的,而内存页面是从存储系统通过 IO 操作获取的。当以元组为单位读取数据时,存储引擎会将该元组所在页加载到内存中,然后根据偏移量获取该元组;然而,由于 MySQL 的庞大与复杂,可能导致当前页中的记录在遍历了几条后,当前页就被刷盘(LRU 刷盘),等到遍历当前页的其余数据时,仍需要通过 IO 操作从存储系统获取,所以简单嵌套循环连接算法效率较低。
扩展:简单的 LRU 刷盘策略是什么?
简单点来说就是,有维持一条链表,每访问一个数据页就将其移动到表头,这样在链表尾的就一直是当前时刻的最近最少使用的页面。
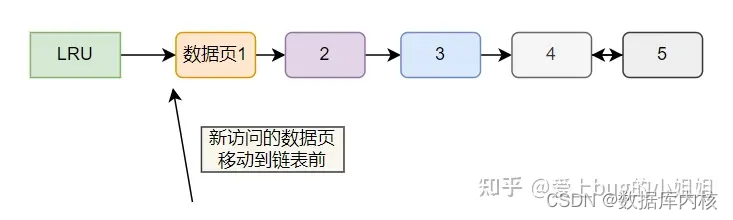
而 LRU 刷盘策略就是当缓存页不够的时候,挑最近最少使用的数据页进行刷盘以释放该缓存页。
参考:MySQL基于冷热数据分离优化的LRU刷盘策略 - 知乎 (zhihu.com)
基于块的嵌套循环连接算法(Block Nested-Loop Join)
基于块的嵌套循环连接其优化思路是减少磁盘 IO 次数;建立一个缓存,然后一次从磁盘读取多个数据页并存放到缓存中,这样可以在很大程度上减少 IO 次数,从而达到提升性能的目的。算法描述如下:
for each chunk c1 of t1 { // c1 表示 “块”
if c1 not in memory // 系统一次读入多个页面,所以不需要每次都从存储系统读入,消耗 IO
read chunk c1 into memory
for each row r1 in chunk c1 { // 从页面中分析出元组,消耗 CPU
for each chunk c2 of t2 {
if c2 not in memory
read chunk c2 into memory
for each row r2 in c2 { // 从页面中分析处元组,消耗 CPU
if r1, r2 satisfies join conditions
join r1, r2
}
}
}
}无论是嵌套循环连接还是基于块的嵌套循环连接,其本质都是在一个两层的循环中拿出各自的元组,逐一匹配是否满足连接条件。其他一些两表连接算法,多是在此基础上进行的改进。
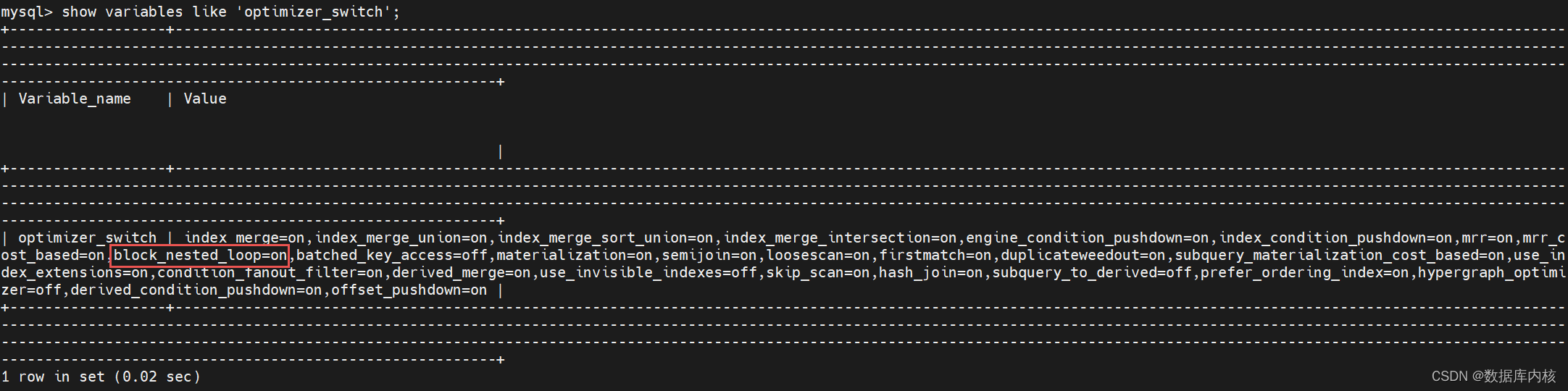
注:如果无法使用 Index Nested-Loop Join,数据库默认使用的是 Block Nested-Loop Join 算法。但使用 Block Nested-Loop Join 算法需要开启优化器管理配置的 optimizer_switch,即将 block_nested_loop 设置为 on(默认开启),如果关闭,则使用 Simple Nested-Loop Join 算法。
1)查看配置
mysql> show variables like 'optimizer_switch';
+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------- ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ ---------------------------------------------------------+
| Variable_name | Value |
+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------+
| optimizer_switch | index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_c ost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_in dex_extensions=on,condition_fanout_filter=on,derived_merge=on,use_invisible_indexes=off,skip_scan=on,hash_join=on,subquery_to_derived=off,prefer_ordering_index=on,hypergraph_optimizer=off,derived_condition_pushdown=on,offset_pushdown=on |
+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ---------------------------------------------------------+
1 row in set (0.02 sec)
2)设置 join buffer 的大小
-- 查看 join_buffer_size 的大小
mysql> show variables like 'join_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.01 sec)
-- 设置 join_buffer_size 的大小(会话级)
set session join_buffer_size = 2 * 1024 * 1024;
-- 设置 join_buffer_size 的大小(全局级)
set global join_buffer_size = 2 * 1024 * 1024;
-- 在配置文件中设置
[mysqld]
join_buffer_size = 2M基于索引的嵌套循环连接算法(Index Nested-Loop Join)
基于索引的嵌套循环连接其优化思路是利用索引减少内层匹配次数(使用外表的记录与内表的索引进行匹配),避免和内表的每条记录去比较, 这样极大地减少了和内表的匹配次数,从原来的匹配次数:外表行数 * 内表行数,变成了:外表行数 * 内表索引高度,提升了 join 的性能。算法描述如下:
for each row r1 in t1 { // r1 表示记录
find r2 by index t2 with value r1
if r1, r2 satisfies join conditions
join r1, r2
}
}注:使用基于索引的嵌套循环连接算法的前提是匹配字段必须建立了索引;
其他的优化:如果内层循环的最后一个块使用后作为下次循环的第一个块,则可以节约一次 IO。如果外层元组较少,内层的元组驻留内存多一些(如一些查询优化器采用物化技术固化内层的元组),则能有效提高连接的效率。
适用场景:嵌套循环连接算法和基于块的嵌套循环连接算法适用于内连接、左外连接、半连接、反半连接等语义的处理。
Hash 连接算法
Hash Join 基础知识
MySQL 开发组于 2019 年 10 月 14 日 正式发布了 MySQL 8.0.18 GA 版本,带来了一些新特性和增强功能。其中最引人注目的莫过于多表连接查询支持 hash join 方式了。
什么是 Hash Join
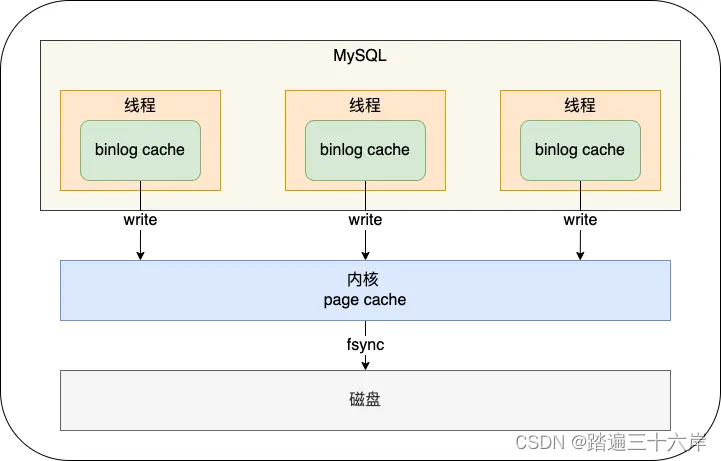
Hash Join 是一种执行连接的方法,如下图所示:
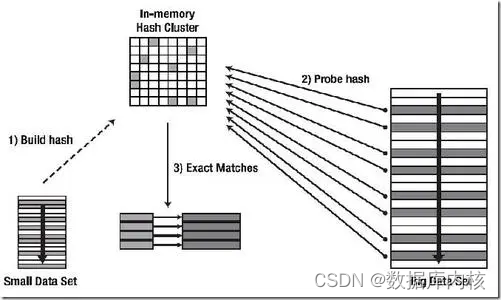
要完成一个 Hash Join 算法实现需要以下三个步骤:
- 选择合适的连接参与表作为内表(build table),构建hash表;
- 然后使用另外一个表(probe table)的每一条记录去探测第一步已经构建完成的哈希表寻找符合连接条件的记录;
- 输出匹配后符合需求的记录;
经典 Hash Join 实现
经典哈希连接的主要特征是内存可以存放哈希连接创建的 hash 表。 经典哈希连接主要包括两部分:
- 选择参加连接的一个表作为哈希表候选表,扫描该表并创建哈希表;
- 选择另外一个表作为探测表,扫描每一行,在哈希表中找寻对应的满足条件的记录;
Hash Join 特点:
- 所有两个参加连接的表只需要被扫描一次;
- 需要整个哈希表都能够被存放在内存里面; 如果内存不能存放完整的哈希表,那么情况会变的比较复杂,一种解决方案如下:
- 读取最大内存可以容纳的记录创建哈希表;
- 另外一张表对于本部分哈希表进行一次全量探测;
- 清理掉哈希表;
- 返回第一步重新执行,知道用于创建哈希表的表记录全部都被处理了一遍; 这种方案会导致用于探测的表会被扫描多次;
需要落盘 Hash Join 实现
因为经典哈希连接对于创建内存不能容纳的哈希表不友好,产生了另外一种算法就是可落盘的哈希算法。算法具体步骤如下:
- 首先现使用哈希方法将参与连接的 build table 和 probe table 按照连接条件进行哈希,将它们的数据划分到不同的磁盘小文件中去。这里小文件是经过计算的这些小的 build table 可以全部读入并创建哈希表。
- 当所有的数据划分完毕之后,按顺序加载每一组对应的 build table 和 probe table 的片段,进行一次经典哈希连接算法执行。因为每一个小片段都可以创建一个能够完全被存放在内存中的哈希表。因此每一个片段的数据都只会被扫描一次。 ** 注意:** 这里需要注意第一步划分数据的时候要防止数据倾斜。因为如果第一步划分分片数据不能划分好数据,可能会导致有的分区没用完用于创建哈希表的内存配额,而另外一些分区又放不下的尴尬情况。
Hash Join 实现原理
上面的部分都是用来普及一下哈希连接的基础知识,从现在开始我们将带大家去看看 MySQL 的 hash join 会是一个怎样的实现?
未超过内存限制的 Hash Join
Join 操作可以看作有两个输入,一个属 build input,另一个是 probe input;从名字也可以看出 build input 是用来构建哈希表的,而 probe input 是用来一行一行读取并和哈希表进行匹配的。
迭代器首先在内存中执行所有操作。如果所有内容未超过内存限制,则 Hash Join 工作流程如下:
1)指定一个输入作为 build input,另一个输入作为 probe input;理想情况下,应该将总大小(而不是行数)较小的输入指定为 build input;
2)将 build input 中的所有行记录读入内存中以构建哈希表。哈希表中使用的哈希键是从连接条件中计算得来的;假设,我们有 SQL 语句:
select * from t1 inner join t2 on t1.c1 = t2.c1;其中 t2 作为 build input,那么哈希键值就是根据 t2.c1 来建立,当然优化器也会识别 join 中的隐式条件,如下:
select * from t1, t2 where t1.c1 = t2.c1; 此时,t2.c1 也会被识别为哈希键;
3)然后,从 probe input 中依次读取行记录,对于每一行,使用连接属性(例如上面示例中的 t1.c1)和与步骤 2 中相同的哈希函数来计算哈希键,使用计算出的哈希键在哈希表中进行查找,如果在哈希表中找到了匹配行,那么会生成一个输出行;(注意,probe input 中的行记录在读取时会被存储在 “表的记录缓冲区”,当从哈希表中检测到匹配的构建行时,该构建行会被恢复到它原来的记录缓冲区,这是因为构建行的原始数据可能在之间的某个阶段被移动或修改了,但为了生成输出行,需要使用原始数据。)关于行记录是如何存储与恢复的细节,请参考 pack_rows::StoreFromTableBuffers 函数。
注意:内存中哈希表的大小由系统变量 join_buffer_size 控制,如果在上述第 2 步中内存耗尽,则降级为混合 Hash Join;内存中已经存在的记录仍然使用常规 Hash Join 处理,其余记录使用磁盘上的 Hash Join 进行处理。
超过内存限制的 Hash Join
迭代器首先在内存中执行所有操作。如果所有内容超过内存限制,则内存中已经存在的记录仍使用常规 Hash Join 处理,其余记录使用磁盘上的 Hash Join 进行处理。磁盘上的 Hash Join 工作流程如下:
1)build input 中没有被构建成哈希表的其余行,会被划分到给定数量的文件中,由 HashJoinChunks 表示;对于 build input 和 probe input 分别创建相同数量的 chunk 文件;像上面的第 2 步一样,根据连接属性计算一个哈希值,然后决定该行记录(是指 build input 中的记录)放入哪个文件,但和上述步骤(未超过内存限制的 Hash Join)使用的哈希函数不同;(将行数据划分为 chunk 文件,在 Hash Join 时可以更为有效的利用磁盘 IO 和内存)
2)然后,从 probe input 中一行一行地读取行记录,先和内存中的哈希表进行匹配,也就是走一遍上面的第 3 步;然后使用哈希函数来计算哈希值,确定该行记录要存到哪个 chunk 文件中(该行记录也会被写入到磁盘的 chunk 文件),因为该记录可能与写入磁盘的 build input 中的一行匹配(换句话说就是该记录仍需与磁盘中的 build input 记录进行匹配);
3)在处理完整个 probe input 后,对每一对 build input 和 probe input 的块文件,都会执行 Hash Join;由于对 probe input 和 build input 使用相同的哈希函数进行分区处理,因此 probe input 和 build input 匹配的行肯定在同一对 chunk 文件中;
4)最后,清除内存中的哈希表,并把每一对 chunk 文件加载到内存中进行 Hash Join。
注意:
- “未超过内存限制的 Hash Join” 处理流程中使用的哈希函数相同,“超过内存限制的 Hash Join” 处理流程中使用的哈希函数相同,但 “未超过内存限制的 Hash Join” 和 “超过内存限制的 Hash Join” 处理流程中使用的哈希函数不同;
- Hash Join 过程中,如果 build input 超出内存限制,则超出内存的其余行在落盘后,才会开始读取 probe input,并进行 Hash Join;
半连接的 Hash Join
半连接的 Hash Join 算法与上述非常相似,具体流程如下:
1)指定内部表(即半连接的 in 侧)作为 build input。由于半连接只需要内部表的第一个匹配行,因此我们不将重复键存储在哈希表中;
2)然后,从 probe input 中依次读取行记录,只要哈希表中有一个匹配行即可;如果表记录超过内存限制,即已经降级为磁盘上的 Hash Join,则只有在哈希表中没有找到匹配的行时,才会将 probe input 中的行记录写入 chunk 文件;
优化器可能会设置带有非纯连接条件的半连接,但它必须附加到 Hash Join 迭代器,示例如下:
mysql> explain analyze select t1.c1 from t1 where 1 IN (select t1.c1 = t2.c1 from t2);
+-----------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+-----------------------------------------------------------------------------------------------------------------------------------------+
| -> Hash semijoin (no condition), extra conditions: (1 = (t1.c1 = t2.c1)) (cost=0.70 rows=1) (actual time=0.159..0.159 rows=0 loops=1)
-> Table scan on t1 (cost=0.35 rows=1) (never executed)
-> Hash
-> Table scan on t2 (cost=0.35 rows=1) (actual time=0.110..0.110 rows=0 loops=1)
|
+-----------------------------------------------------------------------------------------------------------------------------------------+
1 row in set, 1 warning (0.00 sec)在上述查询中,优化器把条件 (1 = (t1.c1 = t2.c1)) 作为半连接条件;但不能将其作为连接条件,因为 Hash Join 只支持等值连接条件。此外,也不能将 (1 = (t1.c1 = t2.c1)) 附加在连接之后的过滤器上,因为这将导致错误的结果;但需要将 (1 = (t1.c1 = t2.c1)) 附加到 Hash Join 迭代器上,且同时需要注意以下几点:
- 如果 SQL 语句中有额外条件,则在创建哈希表时不能拒绝重复键(即重复键也需要存储到哈希表中),因为连接条件的第一个匹配行可能无法满足额外的条件;
- 只有当行记录满足所有额外条件时,才能输出行记录;如果有任何条件匹配失败,必须转到哈希表中的下一个匹配行;
- 只有当哈希表中没有行记录符合所有额外条件时,才会进行磁盘上的 Hash Join;
Hash Join 注意事项
1)如果能够在内存中执行 Hash Join(没有溢出到磁盘),则输出将与左(probe input)输入排序相同;如果开始溢出到磁盘,则将失去任何合理的排序属性;
2)如果单个构建 chunk 文件无法完全加载到内存(即发生数据集倾斜),解决办法为,将尽可能多的数据加载到哈希表,然后将整个探测 chunk 文件(多次读取相应的探测 chunk 文件)读入内存,并与哈希表中的数据进行匹配(即分批次处理构建 chunk 文件,每次处理一部分,直至整个构建 chunk 文件处理完毕);
3)当开始溢出到磁盘时,在磁盘上为两个输入分配最大的 “kMaxChunks” chunk 文件(即为 chunk 文件数量设置上限);设置上限的原因是为了避免耗尽文件描述符;
4)可以通过设置一个 flag 来避免落盘操作(不管输入的表是多大都不会写磁盘);如果设置了该 flag,Hash Join 处理流程如下:
- 从 build input 中尽可能读取多的行记录,构建哈希表并将读取的行记录存储到哈希表中;
- 当哈希表满时(达到系统变量 join_buffer_size 设置的限制),从 probe input 中依次读取行记录,检测哈希表中的匹配项,且为找到的每一个匹配项输出一行;
- 当 probe input 为空时(读取完毕),查看 build input 中是否有剩余行;如果有剩余行,则清除内存中的哈希表并跳转到步骤 1,从上次停止的 build input 继续;如果没有剩余行,则 Hash Join 完成;
注意:在某些情况下,在内存中执行所有 Hash Jon 操作可以带来性能上的优势。
- 特别是当查询中没有排序或分组操作,并且带有 Limit 子句时,这种做法特别有效。因为这样可以更早地开始生成输出行,而不需要等到所有数据都写入磁盘后再进行处理。(假设有一个查询,它从一个非常大的表中选取前 10 行数据,并且没有排序或分组操作。如果我们将所有数据都加载到内存中,一旦找到前 10 行,我们就可以立即开始返回结果,而不需要等待所有其他行都写入磁盘。)
- 当构建输入(build input)的大小几乎可以完全装入内存时,将所有数据都保持在内存中可能也是有益的。这是因为如果我们将构建输入和探测输入(probe input)都写入磁盘,然后再从磁盘读取它们进行比较,这将涉及更多的磁盘 I/O 操作,这通常比内存操作要慢得多。在这种情况下,即使需要读取探测输入两次,也可能比将数据写入磁盘然后再读取更高效。
然而,当前的系统并不总是基于上述成本效益分析来做出决策。系统可能会根据其他因素,如内存可用性、磁盘I/O负载、预计的磁盘使用量等,来决定是将数据保持在内存中还是写入磁盘。这种决策可能需要复杂的成本估算和算法来确定最优策略。
5)在迭代器中有一个叫做 “探测行保存”(probe row saving) 的概念(诣在避免多次输入同一探测行),这种技术通常应用于两种场景:当 Hash Join 的构建 chunk 不能完全装入内存时、当 Hash Join 不允许溢出到磁盘时;这两种场景的共同点是探测行(probe input)将被多次读取。对于某些连接类型(如半连接、外连接、反半连接等),必须注意确保相同的探测行不会被多次发送给客户端,“探测行保存” 通过以下操作来解决这个问题:
- 当系统检测到将多次读取相同的探测行时(如在半连接中,我们只关心未匹配的探测行),就会启用 “探测行保存” 功能;
- 当读取一个探测行时,如果它满足某些条件(对于半连接……,这些条件通常是该行未与 build input 中的任何行匹配),那么该行就会被写入到“探测行保存写文件”(probe row saving write file)中;这个写文件用于临时存储这些探测行,以便后续读取;
- 当所有的 probe input 都被处理完后,系统会交换 “探测行保存写文件” 和 “探测行保存读文件”(probe row saving read file)的角色;这样,原本的写文件就变为读文件,可以被重新用于写入新的探测行,而原本的读文件则变为写文件的备用;
- 当需要再次读取 probe input 时,系统会从 “探测行保存读文件” 中读取探测行;这样,就不需要重新从原始 probe input 读取这些行,从而提高了效率;对于半连接来说,这种机制确保了同一个探测行不会被输出两次;
6)启用 “探测行保存” 时,读取和写入行记录到文件的方式与磁盘上 Hash Join 读写文件的方式相同;需要注意的是对于内连接,不会启用探测行保存功能,因为如果同一探测行与 build input 中的多行匹配,确实希望多次输入同一探测行;关于何时启用 “探测行保存“,不同的 Hash Join 类型(参见 enum HashJoin Type)存在着一定的差异,具体如下:
- IN_MEMORY:“探测行保存” 永远不会被激活,因为内存中的 Hash Join,probe input 只被读取一次;
- SPILL_TO_DISK:如果单个构建 chunk 文件无法完全加载到内存(即发生数据集倾斜),此时不得不多次读取探测 chunk;在这种情况下,一旦发现构建 chunk 无法完全加载到内存,就会启用 “探测行保存”,并保持活跃状态,直到整个构建 chunk 处理完毕;在读取一次探测 chunk 之后,需要交换 “探测行保存写文件” 和 “探测行保存 读文件” 的角色,这样,原本的写文件就变为读文件,可以被重新用于写入新的探测行,而原本的读文件则变为写文件的备用;一旦移动到下一对 chunk 文件,“探测行保存” 将被禁用;
- IN_MEMORY_WITH_HASH_TABLE_REFILL:当 build input 太大而无法完全加载到内存时,将激活 “探测行保存” ;一旦探测迭代器被使用一次,需要交换 “探测行保存写文件” 和 “探测行保存 读文件” 的角色,这样,原本的写文件就变为读文件,可以被重新用于写入新的探测行,而原本的读文件则变为写文件的备用;只要 build input 没有被构建完,就继续将读文件中的探测行写入新的写文件,并在每次重新构建哈希表时交换这些文件;在这种 Hash Join 连接类型中永远不会禁用 “探测行保存”;
注意:
- 如果需要多次读取探测输入,除内连接外都会启用 “探测行保存”,MySQL 8.0 源码部分如下图所示;
- 探测表是主表,即输出的是探测表数据(除内连接外);
- 关于是否能使用 “探测行保存” 功能的案例分析,见附录:MySQL 不同连接方式对比;

在数据库查询执行中,“探测行保存” 这种管理内存使用的策略是很重要的。通过启用和禁用 “探测行保存” 功能,系统可以在内存压力和查询性能之间找到一个平衡。当内存充足时,系统可以尽量避免将数据溢出到磁盘,从而提高查询性能。而当内存不足时,系统可以通过保存未匹配的探测行到磁盘来释放内存,虽然这可能会降低查询性能,但可以避免因内存耗尽而导致的查询失败。
enum class HashJoinType {
IN_MEMORY, // 未超过内存限制的 Hash Join
SPILL_TO_DISK, // 超过内存限制且超出部分选择落盘 Hash Join
IN_MEMORY_WITH_HASH_TABLE_REFILL // 超过内存限制且超出部分选择不落盘 Hash Join
};Hash join 源码分析
MySQL 8.0 中关于 Hash Join 的文件有以下几个,下面一个个来分析。
hash_join_buffer
HashJoinRowBuffer 是用来存储一批行记录的。
行记录会存储在哈希表中,HashJoinRowBuffer 会维护自己的 MEM_ROOT,所有数据都会分配在这里。
下面以:select t1.c2 from t1 join t2 on t1.c1 = t2.c1; 为例进行分析;
假设 t2 存储在 HashJoinRowBuffer 中,这种情况下,t2.c1 就将作为哈希表键值,如果 on 条件中有多个等式,那么这些等式讲一起组合为哈希表的键值,如下所示:
mysql> explain analyze select t1.c2 from t1 join t2 on t1.c1 = t2.c1 and t1.c2 = t2.c2;
+-------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+-------------------------------------------------------------------------------------------------------------------+
| -> Inner hash join (t2.c2 = t1.c2), (t2.c1 = t1.c1) (cost=0.70 rows=1) (actual time=0.180..0.180 rows=0 loops=1)
-> Table scan on t2 (cost=0.35 rows=1) (never executed)
-> Hash
-> Table scan on t1 (cost=0.35 rows=1) (actual time=0.106..0.106 rows=0 loops=1)
|
+-------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)然后,使用 StoreFromTableBuffers 函数来存储行记录;HashJoinRowBuffer 能存储的数据量由参数 join_buffer_size 来限制;当然,为了检查数据量是不是超过 join_buffer_size,可能会需要一些更多的内存空间。
哈希键值是由 join 的 on 条件来决定的,如:t1.c1 = t2.c1 and t1.c2 = t2.c2,那么哈希键值就是(t1.c1,t2.c1),实际上转成什么类型也是由 join 条件决定的,比如有字符串和整数,那么整数就会被转为字符串存储。所以应该使用共有的结构来比较,这里就直接一个个哈希字符(byte-by-byte)来哈希比较,存储的时候也是如此。
注意:对于类似 upper(t1.c1) = upper(t2.c1) 这种 on 条件,此时会把 upper(t1.c1) 作为哈希键值;
HashJoinRowBuffer 类主要内容如下:
class HashJoinRowBuffer {
public:
// Construct the buffer. Note that Init() must be called before the buffer can
// be used.
HashJoinRowBuffer(pack_rows::TableCollection tables,
std::vector<HashJoinCondition> join_conditions,
size_t max_mem_available_bytes);
// 初始化一个 HashJoinRowBuffer,代表已经准备好存储行记录(这个函数可以调用很多次,每次调用都会清除现有数据)
bool Init();
// 存储当前位于表记录缓冲区的行
// 哈希表的键是从行缓冲区保存的连接条件中获取的
// @param thd 处理线程
// @param reject_duplicate_keys 如果为 true,则聚拒绝具有重复键的行,别拒绝后仍将返回 ROW_STORED
// @param store_rows_with_null_in_condition 是否存储 null 行
//
// @retval ROW_STORED 行已经被存储
// @retval BUFFER_FULL 行被存储了,但是缓冲区已满
// @retval FATAL_ERROR 错误
StoreRowResult StoreRow(THD *thd, bool reject_duplicate_keys,
bool store_rows_with_null_in_condition);
// 返回哈希表的状态
size_t size() const { return m_hash_map->size(); }
bool empty() const { return m_hash_map->empty(); }
bool inited() const { return m_hash_map != nullptr; }
using hash_map_type = robin_hood::unordered_flat_map<
ImmutableStringWithLength, LinkedImmutableString, KeyHasher, KeyEquals>;
using hash_map_iterator = hash_map_type::const_iterator;
// 返回查找哈希键值 key 的迭代器
hash_map_iterator find(const Key &key) const { return m_hash_map->find(key); }
hash_map_iterator begin() const { return m_hash_map->begin(); }
hash_map_iterator end() const { return m_hash_map->end(); }
// 获取最后一行插入到哈希表中的行记录
LinkedImmutableString LastRowStored() const {
assert(Initialized());
return m_last_row_stored;
}
bool Initialized() const { return m_hash_map.get() != nullptr; }
bool contains(const Key &key) const { return find(key) != end(); }
private:
// 存储 join 连接条件
const std::vector<HashJoinCondition> m_join_conditions;
// 一行记录可以由来自不同表的部分组成,这个结构告诉我们该行记录涉及哪些表
const pack_rows::TableCollection m_tables;
// 所有的哈希键值(包括键和值)都会存储在 m_mem_root 中,并分配在堆上
MEM_ROOT m_mem_root;
// 存储哈希表的最后一行记录(包括键和值),用于确保当发生溢出时能将溢出部分的数据写入磁盘
MEM_ROOT m_overflow_mem_root;
// 存储行记录
std::unique_ptr<hash_map_type> m_hash_map;
// 通过 join 连接条件构建 key 时使用的缓冲区(为了避免重新分配内存,缓冲区永远不会缩小)
String m_buffer;
size_t m_row_size_upper_bound;
// 缓冲区的最大大小,以字节表示
const size_t m_max_mem_available;
// The last row that was stored in the hash table, or nullptr if the hash
// table is empty. We may have to put this row back into the tables' record
// buffers if we have a child iterator that expects the record buffers to
// contain the last row returned by the storage engine (the probe phase of
// hash join may put any row in the hash table in the tables' record buffer).
// See HashJoinIterator::BuildHashTable() for an example of this.
// 存储哈希表的最后一行,如果哈希表为空,则为 nullptr
LinkedImmutableString m_last_row_stored{nullptr};
// 获取相关列,组成一行记录后,作为 LinkedImmutableString 类型存储到哈希表中
LinkedImmutableString StoreLinkedImmutableStringFromTableBuffers(
LinkedImmutableString next_ptr, bool *full);
};hash_join_chunk
HashJoinChunk 是位于磁盘上的一个文件,可用于存储行。它用于磁盘上的哈希连接,当一个表被划分为几个较小的文件时,也称为 HashJoinChunks。
当将列写入 HashJoinChunk 时,我们使用 StoreFromTableBuffers 将必要的列转换为适合存储在磁盘上的格式。方便的是,StoreFromTableBuffers 创建了一个连续的字节范围和相应的长度,可以轻松有效地写入文件。当从文件中读取行时,LoadIntoTableBuffers() 用于将行放回表记录缓冲区。
HashJoinChunk 类主要内容如下:
class HashJoinChunk {
public:
HashJoinChunk() = default; // Constructible.
HashJoinChunk(HashJoinChunk &&other); // Movable.
HashJoinChunk(const HashJoinChunk &obj) = delete;
HashJoinChunk &operator=(HashJoinChunk &&other);
~HashJoinChunk();
// 初始化 HashJoinChunk.
// @param tables 要存储行记录的表,在 chunk 文件中存储哪一列由表的 read set 决定
// @param uses_match_flags 是否在每行前加一个匹配标志,表示该行是否有匹配的行
// @returns true if the initialization failed.
bool Init(const pack_rows::TableCollection &tables, bool uses_match_flags);
// 返回 HashJoinChunk 中存储的行记录数量
ha_rows num_rows() const { return m_num_rows; }
// 把行记录写入 chunk
// 读取位于给定表的记录缓冲区(record[0])中的行,并将其写入底层文件;
// 如果 QEP_TAB 发出应该保留行 ID 信号,它也会被写出来;
// 注意,TABLE::read_set 用于指示应该将哪些列写入 chunk;
// @param buffer 将数据从表复制到 chunk 文件时使用的缓冲区; 注意,“buffer”中的任何现有数据都将被覆盖;
// @param matched 这一行是否看到了来自其他输入的匹配行; 只有当设置了'm_uses_match_flags',并且该行来自探测输入时,才会写入标志;
// @retval true on error.
bool WriteRowToChunk(String *buffer, bool matched);
// 从 HashJoinChunk 中读取一行,并将其放入记录缓冲区
// 该函数将从磁盘上的文件中读取一行,并将其放入所提供表中的记录缓冲区(table->record[0]); 磁盘上的文件应该已经指向一行的开头;
// @param buffer 将数据从表复制到 chunk 文件时使用的缓冲区; 注意,“buffer”中的任何现有数据都将被覆盖;
// @param[out] matched 这一行是否看到了来自其他输入的匹配行; 只有当设置了'm_uses_match_flags',并且该行来自探测输入时,才会写入标志;
// @retval true on error.
bool LoadRowFromChunk(String *buffer, bool *matched);
// 刷新文件缓冲区,并准备文件以供读取
// @retval true on error
bool Rewind();
private:
// chunk 文件保存数据的表的集合; 用于确定从何处读取数据以及将数据放回何处
pack_rows::TableCollection m_tables;
// chunk 文件中行记录的数量
ha_rows m_num_rows{0};
// 从磁盘读数据时使用的底层文件
IO_CACHE m_file;
// 每行是否以匹配前缀作为标志
bool m_uses_match_flags{false};
};hash_join_iterator(Hash Join 实现原理)
该文件主要介绍 MySQL Hash Join 的实现原理。
HashJoinIterator 类主要内容如下:
class HashJoinIterator final : public RowIterator {
public:
HashJoinIterator(THD *thd, unique_ptr_destroy_only<RowIterator> build_input, // 构建输入
const Prealloced_array<TABLE *, 4> &build_input_tables,
double estimated_build_rows,
unique_ptr_destroy_only<RowIterator> probe_input,
const Prealloced_array<TABLE *, 4> &probe_input_tables,
bool store_rowids, table_map tables_to_get_rowid_for,
size_t max_memory_available,
const std::vector<HashJoinCondition> &join_conditions,
bool allow_spill_to_disk, JoinType join_type,
const Mem_root_array<Item *> &extra_conditions,
bool probe_input_batch_mode,
uint64_t *hash_table_generation);
bool Init() override;
int Read() override;
void SetNullRowFlag(bool is_null_row) override {
m_build_input->SetNullRowFlag(is_null_row);
m_probe_input->SetNullRowFlag(is_null_row);
}
void EndPSIBatchModeIfStarted() override {
m_build_input->EndPSIBatchModeIfStarted();
m_probe_input->EndPSIBatchModeIfStarted();
}
void UnlockRow() override {
// Since both inputs may have been materialized to disk, we cannot unlock
// them.
}
int ChunkCount() { return m_chunk_files_on_disk.size(); }
private:
// 构建哈希表
bool BuildHashTable();
// 把磁盘上 chunk 文件中的记录读取到内存中,并构建哈希表
bool ReadNextHashJoinChunk();
// 从探测迭代器读取记录,并将其加载到 “表的记录缓冲区”,这些缓冲区用于临时存储数据,以便进行后续的处理或比较
/*
从探测迭代器读取记录,并将其加载到 “表的记录缓冲区”,这些缓冲区用于临时存储数据,以便进行后续的处理或比较
结束条件:
1) 当表的记录缓冲区中准备好一行记录,且状态被设置为 READING_FIRST_ROW_FROM_HASH_TABLE 时,这意味着可以进行哈希连接操作;
2) 当没有更多的行记录需要从探测输入中处理时,迭代器状态将被设置为 LOADING_NEXT_CHUNK_PAIR,这意味着探测输入中的数据已经全部处理完毕;
*/
bool ReadRowFromProbeIterator();
// 把 chunk 中的行记录读到 “表的记录缓冲区”,结束条件和 ReadRowFromProbeIterator() 函数类似
bool ReadRowFromProbeChunkFile();
// 把探测行存储文件中的行记录读到 “表的记录缓冲区”
bool ReadRowFromProbeRowSavingFile();
// Do a lookup in the hash table for matching rows from the build input.
// The lookup is done by computing the join key from the probe input, and
// using that join key for doing a lookup in the hash table. If the join key
// contains one or more SQL NULLs, the row cannot match anything and will be
// skipped, and the iterator state will be READING_ROW_FROM_PROBE_INPUT. If
// not, the iterator state will be READING_FIRST_ROW_FROM_HASH_TABLE.
//
// After this function is called, ReadJoinedRow() will return false until
// there are no more matching rows for the computed join key.
void LookupProbeRowInHashTable();
/// Take the next matching row from the hash table, and put the row into the
/// build tables' record buffers. The function expects that
/// LookupProbeRowInHashTable() has been called up-front. The user must
/// call ReadJoinedRow() as long as it returns false, as there may be
/// multiple matching rows from the hash table. It is up to the caller to set
/// a new state in case of EOF.
///
/// @retval 0 if a match was found and the row is put in the build tables'
/// record buffers
/// @retval -1 if there are no more matching rows in the hash table
int ReadJoinedRow();
// Have we degraded into on-disk hash join?
bool on_disk_hash_join() const { return !m_chunk_files_on_disk.empty(); }
/// Write the last row read from the probe input out to chunk files on disk,
/// if applicable.
///
/// For inner joins, we must write all probe rows to chunk files, since we
/// need to match the row against rows from the build input that are written
/// out to chunk files. For semijoin, we can only write probe rows that do not
/// match any of the rows in the hash table. Writing a probe row with a
/// matching row in the hash table could cause the row to be returned multiple
/// times.
///
/// @retval true in case of errors.
bool WriteProbeRowToDiskIfApplicable();
/// @retval true if the last joined row passes all of the extra conditions.
bool JoinedRowPassesExtraConditions() const;
/// If true, reject duplicate keys in the hash table.
///
/// Semijoins/antijoins are only interested in the first matching row from the
/// hash table, so we can avoid storing duplicate keys in order to save some
/// memory. However, this cannot be applied if we have any "extra" conditions:
/// the first matching row in the hash table may fail the extra condition(s).
///
/// @retval true if we can reject duplicate keys in the hash table.
bool RejectDuplicateKeys() const {
return m_extra_condition == nullptr &&
(m_join_type == JoinType::SEMI || m_join_type == JoinType::ANTI);
}
// 初始化行缓冲区并重置所有指向它的迭代器(可能被多次调用以重新初始化行缓冲区)
bool InitRowBuffer();
// 初始化 Probe 迭代器,使其能够从数据集的开头读取,且在合适的情况下能进行批量读取
bool InitProbeIterator();
// 初始化 Probe 行保存文件以供写入
bool InitWritingToProbeRowSavingFile();
// 初始化 Probe 行保存文件以供读取
bool InitReadingFromProbeRowSavingFile();
/// Set the iterator state to the correct READING_ROW_FROM_PROBE_*-state.
/// Which state we end up in depends on which hash join type we are executing
/// (in-memory, on-disk or in-memory with hash table refill).
void SetReadingProbeRowState();
/// Read a joined row from the hash table, and see if it passes any extra
/// conditions. The last probe row read will also be written do disk if needed
/// (see WriteProbeRowToDiskIfApplicable).
///
/// @retval -1 There are no more matching rows in the hash table.
/// @retval 0 A joined row is ready.
/// @retval 1 An error occurred.
int ReadNextJoinedRowFromHashTable();
enum class State {
// We are reading a row from the probe input, where the row comes from
// the iterator.
READING_ROW_FROM_PROBE_ITERATOR,
// We are reading a row from the probe input, where the row comes from a
// chunk file.
READING_ROW_FROM_PROBE_CHUNK_FILE,
// We are reading a row from the probe input, where the row comes from a
// probe row saving file.
READING_ROW_FROM_PROBE_ROW_SAVING_FILE,
// The iterator is moving to the next pair of chunk files, where the chunk
// file from the build input will be loaded into the hash table.
LOADING_NEXT_CHUNK_PAIR,
// We are reading the first row returned from the hash table lookup that
// also passes extra conditions.
READING_FIRST_ROW_FROM_HASH_TABLE,
// We are reading the remaining rows returned from the hash table lookup.
READING_FROM_HASH_TABLE,
// No more rows, both inputs are empty.
END_OF_ROWS
};
State m_state;
uint64_t *m_hash_table_generation;
uint64_t m_last_hash_table_generation;
const unique_ptr_destroy_only<RowIterator> m_build_input;
const unique_ptr_destroy_only<RowIterator> m_probe_input;
// The last row that was read from the hash table, or nullptr if none.
// All rows under the same key are linked together (see the documentation
// for LinkedImmutableString), so this allows iterating through the rows
// until the end.
LinkedImmutableString m_current_row{nullptr};
// These structures holds the tables and columns that are needed for the hash
// join. Rows/columns that are not needed are filtered out in the constructor.
// We need to know which tables that belong to each iterator, so that we can
// compute the join key when needed.
pack_rows::TableCollection m_probe_input_tables;
pack_rows::TableCollection m_build_input_tables;
const table_map m_tables_to_get_rowid_for;
// An in-memory hash table that holds rows from the build input (directly from
// the build input iterator, or from a chunk file). See the class comment for
// details on how and when this is used.
hash_join_buffer::HashJoinRowBuffer m_row_buffer;
// 等值连接条件列表
Prealloced_array<HashJoinCondition, 4> m_join_conditions;
// Array to hold the list of chunk files on disk in case we degrade into
// on-disk hash join.
Mem_root_array<ChunkPair> m_chunk_files_on_disk;
// 当前正在读取哪一个 HashJoinChunk,HashJoinChunk 表示一组构建行和与之关联的探测行
int m_current_chunk{-1};
// The seed that is by xxHash64 when calculating the hash from a join
// key. We use xxHash64 when calculating the hash that is used for
// determining which chunk file a row should be placed in (in case of
// on-disk hash join); if we used the same hash function (and seed) for
// both operation, we would get a really bad hash table when loading
// a chunk file to the hash table. The number is chosen randomly and have
// no special meaning.
static constexpr uint32_t kChunkPartitioningHashSeed{899339};
// 构建输入和探测输入当前操作行
ha_rows m_build_chunk_current_row = 0;
ha_rows m_probe_chunk_current_row = 0;
// 估计构建输入中可能有多少行(该估计值对于决定如何在磁盘上划分数据库至关重要)
const double m_estimated_build_rows;
// 当数据溢出到磁盘时,为每个输入分配的最大 chunk 数,该限制主要是为了防止消耗过多的文件描述符
// 因为每个文件都需要一个文件描述符来管理,而文件描述符是一种有限的资源,如果消耗过多可能会导致系统无法打开更多的文件,从而影响数据库的性能
// 这个最大值的选择通常是 2 的 n 次幂,这是因为使用 2 的次幂可以在某些计算上实现优化(如:位运算)
static constexpr size_t kMaxChunks = 128;
// A buffer that is used during two phases:
// 1) when constructing a join key from join conditions.
// 2) when moving a row between tables' record buffers and the hash table.
//
// There are two functions that needs this buffer; ConstructJoinKey() and
// StoreFromTableBuffers(). After calling one of these functions, the user
// must take responsibility of the data if it is needed for a longer lifetime.
//
// If there are no BLOB/TEXT column in the join, we calculate an upper bound
// of the row size that is used to preallocate this buffer. In the case of
// BLOB/TEXT columns, we cannot calculate a reasonable upper bound, and the
// row size is calculated per row. The allocated memory is kept for the
// duration of the iterator, so that we (most likely) avoid reallocations.
String m_temporary_row_and_join_key_buffer;
/*
是否为 probe_input 启用批量模式,批量处理模式会在以下条件下被启用:
1) probe_input 只包含一个表;
2) 该表可以返回多行;
3) 没有关联的子查询
*/
bool m_probe_input_batch_mode{false};
// 是否允许溢出到磁盘
bool m_allow_spill_to_disk{true};
// 构建输入是否有更多行; 当我们确定整个构建输入已被构建完成时,这用于停止 Hash
// Join 迭代器请求更多行; 只有当 m_allow_spill_to_disk 为 false 时才使用该变量
// 因为当整个探测输入检索完时,必须查看构建输入中是否有更多的行
bool m_build_iterator_has_more_rows{true};
// 迭代器应该执行哪种类型的 Hash Join
const JoinType m_join_type;
// 如果该值不为空,Hash Join 迭代器应该在哈希表查找完成之后,但在返会该行之前过滤该条件(一般为非等值条件)
Item *m_extra_condition{nullptr};
// 是否应该将探测输入中的行写入保存探测行的写文件
bool m_write_to_probe_row_saving{false};
// 是否应该从保存读取文件的探测行中读取行
bool m_read_from_probe_row_saving{false};
// 未匹配的 probe 行被写入和读取的文件被称为 probe 行保存文件
HashJoinChunk m_probe_row_saving_write_file;
HashJoinChunk m_probe_row_saving_read_file;
// 当前正在读取 probe 行保存文件中读文件的哪一行,用于检测是否已经达到文件末尾
ha_rows m_probe_row_saving_read_file_current_row{0};
// Hash Join 类型
enum class HashJoinType {
IN_MEMORY,
SPILL_TO_DISK,
IN_MEMORY_WITH_HASH_TABLE_REFILL
};
HashJoinType m_hash_join_type{HashJoinType::IN_MEMORY};
// The match flag for the last probe row read from chunk file.
//
// This is needed if a outer join spills to disk; a probe row can match a row
// from the build input we haven't seen yet (it's been written out to disk
// because the hash table was full). So when reading a probe row from a chunk
// file, this variable holds the match flag. This flag must be a class member,
// since one probe row may match multiple rows from the hash table; the
// execution will go out of HashJoinIterator::Read() between each matching
// row, causing any local match flag to lose the match flag info from the last
// probe row read.
bool m_probe_row_match_flag{false};
};Hash Join 代价估算
Hash Join 的代价估算:COST = BUILD_COST + M_SCAN_COST + JOIN_CONDITION_COST + FILTER_COST
- BUILD_COST:建立 hash 表的开销;
- M_SCAN_COST:扫描另一个表的开销;
- JOIN_CONDITION_COST:join 连接条件的开销;
- FILTER_COST:filter 过滤的开销;
注意:join 的两个表都是只需要扫描一次即可,filter 过滤是指 t1.c2 > t2.c2 这样的条件过滤(需要在 server 层进行),对于 t1.c1>1 这样只涉及单表的条件会被下推到引擎层,在做连接之前就被过滤了。
Hash Join 使用
从 MySQL 8.0.18 开始,任何一个带有等值连接的查询都能使用 Hash Join,如下所示:
select * from t1 join t2 on t1.c1 = t1.c1;
-- 查询执行计划
mysql> explain analyze select a.a2, b.b3 from a join b on a.a2 = b.b2;
+-------------------------------------------------------------------------------------------------+
| EXPLAIN |
+-------------------------------------------------------------------------------------------------+
| -> Inner hash join (b.b2 = a.a2) (cost=4.70 rows=6) (actual time=0.436..0.584 rows=6 loops=1)
-> Table scan on b (cost=0.06 rows=6) (actual time=0.043..0.179 rows=6 loops=1)
-> Hash
-> Table scan on a (cost=0.85 rows=6) (actual time=0.124..0.312 rows=7 loops=1)
|
+-------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)Hash Join 不需要索引的支持。大多数情况下,hash join 比之前的 Block Nested-Loop 算法在没有索引时的等值连接更加高效。使用以下语句创建三张测试表:
create table t1 (c1 int, c2 int);
create table t2 (c1 int, c2 int);
create table t3 (c1 int, c2 int);MySQL 8.0.20 之前版本需要加 format tree 方可查看 Hash Join 的连接信息;之后版本直接使用 explain analyze 即可查看 Hash Join 的连接信息,如下所示:
mysql> explain format = tree select * from t1 join t2 on t1.c1 = t2.c1\G
*************************** 1. row ***************************
EXPLAIN: -> Inner hash join (t2.c1 = t1.c1) (cost=0.70 rows=1)
-> Table scan on t2 (cost=0.35 rows=1)
-> Hash
-> Table scan on t1 (cost=0.35 rows=1)
1 row in set (0.01 sec)
mysql> explain analyze select * from t1 join t2 on t1.c1 = t2.c1\G
*************************** 1. row ***************************
EXPLAIN: -> Inner hash join (t2.c1 = t1.c1) (cost=0.70 rows=1) (actual time=0.162..0.162 rows=0 loops=1)
-> Table scan on t2 (cost=0.35 rows=1) (never executed)
-> Hash
-> Table scan on t1 (cost=0.35 rows=1) (actual time=0.114..0.114 rows=0 loops=1)
1 row in set (0.01 sec)Hash Join 也支持多表连接,但每两张表连接条件中必须有一个等值条件,如下所示:
mysql> explain analyze select * from t1 join t2 on (t1.c1 = t2.c1 and t1.c2 < t2.c2) join t3 on (t2.c1 = t3.c1);
+--------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+--------------------------------------------------------------------------------------------------------------+
| -> Inner hash join (t3.c1 = t1.c1) (cost=1.05 rows=1) (actual time=0.184..0.184 rows=0 loops=1)
-> Table scan on t3 (cost=0.35 rows=1) (never executed)
-> Hash
-> Filter: (t1.c2 < t2.c2) (cost=0.70 rows=1) (actual time=0.137..0.137 rows=0 loops=1)
-> Inner hash join (t2.c1 = t1.c1) (cost=0.70 rows=1) (actual time=0.137..0.137 rows=0 loops=1)
-> Table scan on t2 (cost=0.35 rows=1) (never executed)
-> Hash
-> Table scan on t1 (cost=0.35 rows=1) (actual time=0.088..0.088 rows=0 loops=1)
|
+--------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)MySQL 8.0.20 之前版本,多表连接时,每两个表的连接条件中必须有一个等值条件方可使用 Hash Join,否则使用性能更差的 Block Nested-Loop Join 连接算法。
MySQL 8.0.20 之后版本,Hash Join 也适用于笛卡尔积(即没有连接条件),具体如下:
mysql> explain analyze select * from t1 join t2 whehr t1.c2 > 50\G
*************************** 1. row ***************************
EXPLAIN: -> Inner hash join (cost=0.70 rows=1))
-> Table scan on t2 (cost=0.35 rows=1)
-> Hash
-> Filter: (t1.c2 > 50) (cost=0.35 rows=1)
-> Table scan on t1 (cost=0.35 rows=1)MySQL 8.0.20 之后版本,Hash Join 的使用条件不再限制连接条件中必须有等值条件(即连接条件中没有等值条件也可以使用 Hash Join),示例如下:
1)Inner non-equi-join
mysql> explain analyze select * from t1 join t2 on t1.c1 < t2.c1\G
*************************** 1. row ***************************
EXPLAIN: -> Filter: (t1.c1 < t2.c1) (cost=4.70 rows=12))
-> Inner hash join (no condition) (cost=4.70 rows=12)
-> Table scan on t2 (cost=0.08 rows=6)
-> Hash
-> Table scan on t1 (cost=0.85 rows=6)2)semijoin
mysql> explain analyze select * from t1 where t1.c1 in (select t2.c2 from t2);
+-----------------------------------------------------------------------------------------------------+
| EXPLAIN |
+-----------------------------------------------------------------------------------------------------+
| -> Hash semijoin (t2.c2 = t1.c1) (cost=0.70 rows=1) (actual time=0.469..0.469 rows=0 loops=1)
-> Table scan on t1 (cost=0.35 rows=1) (never executed)
-> Hash
-> Table scan on t2 (cost=0.35 rows=1) (actual time=0.416..0.416 rows=0 loops=1)
|
+-----------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)3)Antijoin
mysql> explain analyze select * from t2 where not exists (select * from t1 where t1.c1 = t2.c1);
+-----------------------------------------------------------------------------------------------------+
| EXPLAIN |
+-----------------------------------------------------------------------------------------------------+
| -> Hash antijoin (t1.c1 = t2.c1) (cost=0.70 rows=1) (actual time=0.453..0.453 rows=0 loops=1)
-> Table scan on t2 (cost=0.35 rows=1) (actual time=0.032..0.032 rows=0 loops=1)
-> Hash
-> Table scan on t1 (cost=0.35 rows=1) (actual time=0.371..0.371 rows=0 loops=1)
|
+-----------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)4)Left outer join
mysql> explain analyze select * from t1 left join t2 on t1.c1 = t2.c1;
+---------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------+
| -> Left hash join (t2.c1 = t1.c1) (cost=0.70 rows=1) (actual time=0.177..0.177 rows=0 loops=1)
-> Table scan on t1 (cost=0.35 rows=1) (actual time=0.030..0.030 rows=0 loops=1)
-> Hash
-> Table scan on t2 (cost=0.35 rows=1) (actual time=0.098..0.098 rows=0 loops=1)
|
+---------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)5)Right outer join (observe that MySQL rewrites all right outer joins as left outer joins)
mysql> explain analyze select * from t1 right join t2 on t1.c1 = t2.c1;
+---------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------+
| -> Left hash join (t1.c1 = t2.c1) (cost=0.70 rows=1) (actual time=0.182..0.182 rows=0 loops=1)
-> Table scan on t2 (cost=0.35 rows=1) (actual time=0.030..0.030 rows=0 loops=1)
-> Hash
-> Table scan on t1 (cost=0.35 rows=1) (actual time=0.103..0.103 rows=0 loops=1)
|
+---------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)用户可干预的变化
默认配置时,MySQL(8.0.18 及更高版本)所有可能的情况下都会使用 hash join。同时提供了两种控制是否使用 hash join 的方法:
- 在全局或者会话级别,设置服务器系统变量 optimizer_switch 中的 hash_join = on 或者 hash_join = off 选项,默认为 hash_join = on;
- 在语句级别,为特定的连接指定优化器提示 HASH_JOIN 或者 NO_HASH_JOIN;
可以通过系统变量 join_buffer_size 控制 hash join 允许使用的内存数量;hash join 不会使用超过该变量设置的内存数量。如果 hash join 所需的内存超过该阈值,MySQL 将会在磁盘中执行操作。需要注意的是,如果 hash join 无法在内存中完成,并且打开的文件数量超过系统变量 open_files_limit 的值,连接操作可能会失败。为了解决这个问题,可以使用以下方法之一:
- 增加 join_buffer_size 的值,确保 hash join 可以在内存中完成;
- 增加 open_files_limit 的值;
参考:MySQL :: MySQL 8.0 Reference Manual :: 10.2.1.4 Hash Join Optimization
没有等值连接条件的 Hash Join 是如何工作的
问题:当没有等值连接条件时,如何进行 Hash Join 的?何时过滤数据?
mysql> explain analyze select * from t1 join t2 on t1.c1 > t2.c1;
+------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+------------------------------------------------------------------------------------------------------+
| -> Filter: (t1.c1 > t2.c1) (cost=0.70 rows=1) (actual time=0.124..0.124 rows=0 loops=1)
-> Inner hash join (no condition) (cost=0.70 rows=1) (actual time=0.123..0.123 rows=0 loops=1)
-> Table scan on t2 (cost=0.35 rows=1) (never executed)
-> Hash
-> Table scan on t1 (cost=0.35 rows=1) (actual time=0.077..0.077 rows=0 loops=1)
|
+------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)答:当 hash join 中没有等值连接条件时,仍然会使用 build input 构建哈希表,但是哈希键无效,所以当一条一条读取 probe input 记录时,会拿着 probe 记录和哈希表中的记录进行逐条 join;相关源码如下所示:
HashJoinIterator::BuildHashTable 函数
// 构建哈希表
bool HashJoinIterator::BuildHashTable() {
// 检查迭代器是否还有更多的行需要处理
if (!m_build_iterator_has_more_rows) {
m_state = State::END_OF_ROWS;
return false;
}
// 检查行缓冲区是否被初始化且最后存储的行是否为空
if (m_row_buffer.Initialized() && m_row_buffer.LastRowStored() != nullptr) {
// 将最后存储的行加载到表的缓冲区
LoadImmutableStringIntoTableBuffers(m_build_input_tables,
m_row_buffer.LastRowStored());
}
// 初始化行缓冲区
if (InitRowBuffer()) {
return true;
}
// 是否拒绝重复的键
const bool reject_duplicate_keys = RejectDuplicateKeys();
// 根据连接类型确定是否存储包含 null 值得连接键的行
const bool store_rows_with_null_in_join_key = m_join_type == JoinType::OUTER;
// null 行标志用于指示当前处理的行记录连接条件中是否包含 null 值
// 如果 init 方法被多次调用,那么 null 标志可能被设置,因此需要清除该标志,否则可能会影响后续 hash join
m_build_input->SetNullRowFlag(/*is_null_row=*/false); // false 表示当前处理的行记录连接条件中包含 null 值
// 创建批量处理对象
PFSBatchMode batch_mode(m_build_input.get());
for (;;) { // Termination condition within loop.
int res = m_build_input->Read(); // 从构建输入中读取一行记录
if (res == 1) {
assert(thd()->is_error() ||
thd()->killed); // my_error should have been called.
return true;
}
// 读取到构建输入的末尾
if (res == -1) {
m_build_iterator_has_more_rows = false; // 构建输入中没有更多的行
// 如果是内连接或者半连接,当构建输入为空时,返回结果也为空
// 如果是反连接,当构建输入为空时,返回探测输入的所有行
if (m_row_buffer.empty() && m_join_type != JoinType::ANTI &&
m_join_type != JoinType::OUTER) {
m_state = State::END_OF_ROWS;
return false;
}
/*
在这种情况下, 如果之前因为哈希表内存不足并且不允许溢出到磁盘而启用了探测行保存(probe row saving)功能
那么现在就可以安全地禁用这个功能了, 因为我们已经读到了构建迭代器的末尾,并且知道不会再有新的匹配行需要被保存
*/
m_write_to_probe_row_saving = false;
// 设置哈希连接迭代器状态(in-memory, on-disk or in-memory with hash table refill)
SetReadingProbeRowState();
return false;
}
assert(res == 0); // 成功从构建输入中读取一行记录
// 获取当前记录的行Id
// 1) m_build_input_tables.tables():构建输入表集合
// 2) m_build_input_tables.tables():获取行Id需要的特定表
RequestRowId(m_build_input_tables.tables(), m_tables_to_get_rowid_for);
// 先把行记录保存到内存,如果内存已满,则检查是否允许落盘;如果不允许则启用 “探测行保存”
const hash_join_buffer::StoreRowResult store_row_result =
m_row_buffer.StoreRow(thd(), reject_duplicate_keys,
store_rows_with_null_in_join_key);
switch (store_row_result) {
case hash_join_buffer::StoreRowResult::ROW_STORED: // 构建行记录成功存储到内存
break;
case hash_join_buffer::StoreRowResult::BUFFER_FULL: { // 构建行已存储,但内存已满
assert(!m_row_buffer.empty());
// 如果不允许溢出到磁盘且当内存已满时,则开始从探测输入读取行,并在内存中寻找匹配项
if (!m_allow_spill_to_disk) {
if (m_join_type != JoinType::INNER) {
// 如果不是内连接,则启用 “探测行保存” 并准备 “探测行保存写文件”
InitWritingToProbeRowSavingFile();
}
SetReadingProbeRowState();
return false;
}
// 如果允许溢出到磁盘,则将溢出部分写入磁盘
if (InitializeChunkFiles( // 初始化 chunk 文件
m_estimated_build_rows, m_row_buffer.size(), kMaxChunks,
m_probe_input_tables, m_build_input_tables,
/*include_match_flag_for_probe=*/m_join_type == JoinType::OUTER,
&m_chunk_files_on_disk)) {
assert(thd()->is_error()); // my_error should have been called.
return true;
}
// 把溢出部分的行记录写入 chunk 文件
if (WriteRowsToChunks(thd(), m_build_input.get(), m_build_input_tables,
m_join_conditions, kChunkPartitioningHashSeed,
&m_chunk_files_on_disk,
true /* write_to_build_chunks */,
false /* write_rows_with_null_in_join_key */,
m_tables_to_get_rowid_for,
&m_temporary_row_and_join_key_buffer)) {
assert(thd()->is_error() ||
thd()->killed); // my_error should have been called.
return true;
}
// 刷新块文件(确保所有待处理数据已写入磁盘),并定位到块文件的起始位置
for (ChunkPair &chunk_pair : m_chunk_files_on_disk) {
if (chunk_pair.build_chunk.Rewind()) {
assert(thd()->is_error() ||
thd()->killed); // my_error should have been called.
return true;
}
}
SetReadingProbeRowState();
return false;
}
case hash_join_buffer::StoreRowResult::FATAL_ERROR: // 发生错误
my_error(ER_OUTOFMEMORY, MYF(ME_FATALERROR),
thd()->variables.join_buff_size);
return true;
}
}
}HashJoinRowBuffer::StoreRow 函数
// 把读取的构建行记录存储到内存
StoreRowResult HashJoinRowBuffer::StoreRow(
THD *thd, bool reject_duplicate_keys,
bool store_rows_with_null_in_condition) {
bool full = false; // 内存是否已满
// 从连接条件中获取哈希键
m_buffer.length(0);
for (const HashJoinCondition &hash_join_condition : m_join_conditions) { // 遍历哈希连接条件
// 哈希键是否为空
bool null_in_join_condition =
hash_join_condition.join_condition()->append_join_key_for_hash_join(
thd, m_tables.tables_bitmap(), hash_join_condition,
m_join_conditions.size() > 1, &m_buffer);
if (thd->is_error()) {
// An error was raised while evaluating the join condition.
return StoreRowResult::FATAL_ERROR;
}
// 检查哈希键是否为 null,如果为空,继续检查是否允许以 null 为键建立哈希表
if (null_in_join_condition && !store_rows_with_null_in_condition) {
// SQL NULL values will never match in an inner join or semijoin, so skip
// the row.
return StoreRowResult::ROW_STORED;
}
}
// ------------------- 存储哈希键 --------------------- //
// 计算存储哈希键所需要的字节数
const size_t required_key_bytes =
ImmutableStringWithLength::RequiredBytesForEncode(m_buffer.length());
ImmutableStringWithLength key;
// 检查当前内存块是否有足够空间来存储哈希键,如果没有,则请求一个新的内存块
std::pair<char *, char *> block = m_mem_root.Peek();
if (static_cast<size_t>(block.second - block.first) < required_key_bytes) {
// No room in this block; ask for a new one and try again.
m_mem_root.ForceNewBlock(required_key_bytes); // 分配一个新的内存块
block = m_mem_root.Peek();
}
// 初始化一个变量以跟踪存储哈希键需要的字节数
size_t bytes_to_commit = 0;
// 检查新的内存块是否足以存储哈希键
if (static_cast<size_t>(block.second - block.first) >= required_key_bytes) {
char *ptr = block.first;
key = ImmutableStringWithLength::Encode(m_buffer.ptr(), m_buffer.length(),
&ptr);
assert(ptr < block.second);
bytes_to_commit = ptr - block.first;
} else { // 如果新内存块仍不足以存储哈希键,则使用 m_overflow_mem_root 分配内存
char *ptr =
pointer_cast<char *>(m_overflow_mem_root.Alloc(required_key_bytes));
if (ptr == nullptr) {
return StoreRowResult::FATAL_ERROR;
}
key = ImmutableStringWithLength::Encode(m_buffer.ptr(), m_buffer.length(),
&ptr);
// Keep bytes_to_commit == 0; the value is already committed.
}
std::pair<hash_map_type::iterator, bool> key_it_and_inserted;
// 尝试在哈希表中插入键
try {
key_it_and_inserted =
m_hash_map->emplace(key, LinkedImmutableString{nullptr});
} catch (const std::overflow_error &) {
// This can only happen if the hash function is extremely bad
// (should never happen in practice).
return StoreRowResult::FATAL_ERROR;
}
LinkedImmutableString next_ptr{nullptr};
if (key_it_and_inserted.second) { // 如果为真,则表明哈希键已经插入到哈希表中
// 哈希表插入一行新记录
size_t bytes_used = m_hash_map->calcNumBytesTotal(m_hash_map->mask() + 1);
// 检查当前使用内存是否超出最大内存,若超出则需将超出部分溢出到磁盘
if (bytes_used >= m_max_mem_available) {
// 0 means no limit, so set the minimum possible limit.
m_mem_root.set_max_capacity(1);
full = true; // 内存已满标志位
} else {
// 更新当前内存容量:最大可用内存 - 当前记录使用字节数
m_mem_root.set_max_capacity(m_max_mem_available - bytes_used);
}
// We need to keep this key.
m_mem_root.RawCommit(bytes_to_commit);
} else {
if (reject_duplicate_keys) {
return StoreRowResult::ROW_STORED;
}
// We already have another element with the same key, so our insert
// failed, Put the new value in the hash bucket, but keep track of
// what the old one was; it will be our “next” pointer.
next_ptr = key_it_and_inserted.first->second;
}
// Save the contents of all columns marked for reading.
m_last_row_stored = key_it_and_inserted.first->second =
StoreLinkedImmutableStringFromTableBuffers(next_ptr, &full);
if (m_last_row_stored == nullptr) {
return StoreRowResult::FATAL_ERROR;
} else if (full) {
return StoreRowResult::BUFFER_FULL;
} else {
return StoreRowResult::ROW_STORED;
}
}排序归并连接算法(MySQL 不支持暂不详细介绍)
排序归并连接算法又称归并排序连接算法,简称归并连接算法。归并连接算法需要首先对两个表按照关联的字段进行排序,然后分别从两个表中取出一行数据进行匹配,如果合适放入结果集;不匹配将较小的那行丢掉继续匹配另一个表的下一行,依次处理直到将两表的数据取完。merge join的很大一部分开销花在排序上,也是同等条件下差于hash join的一个主要原因。
排序归并连接算法又称归并排序连接算法,简称归并连接算法。这种算法的步骤是:为两个表创建可用内存缓冲区数为:M 的 M 个子表,将每个子表排好序;然后读入每个子表的第一个块到 M 个块中,找到其中最小的先进行两个表的元组的匹配,找出次小的匹配……以此类推,完成其他子表的两表连接。
归并连接算法要求内外表都是有序的,所以对于内外表都要排序。如果连接列是索引列,可以利用索引进行排序。
适用场景:归并连接算法适用于内连接、左外连接、右外连接、全外连接、半连接、反半连接等语义的处理。
注意:虽然这种方式执行速度很快,但大数情况下数据没有排序,因此性能不如哈希连接。
附录
查询执行计划 Extra 列的含义
Using where
如果查询未能使用索引,Using where 的作用只是提醒我们 MySQL 将用 where 子句来过滤结果集。这个一般发生在 MySQL 服务器,而不是存储引擎层。一般发生在不能走索引扫描的情况下或者走索引扫描,但是有些查询条件不在索引当中的情况下。
Using index
表示直接访问索引就能够获取到所需要的数据(覆盖索引扫描),不需要通过回表;
Using index condition
在 MySQL 5.6 版本后加入的新特性(Index Condition Pushdown);先使用下推到引擎层的条件过滤,找到所有符合索引条件的数据行,随后用 where 子句中的其他条件去过滤这些数据行(即走 ICP 下推);
Using temporary
表示 MySQL 需要使用临时表来存储结果集,常见于排序和分组查询;
Using filesort
MySQL 中无法利用索引完成的排序操作称为“文件排序”;
Select tables optimized away
SELECT操作已经优化到不能再优化了,即查询不需要访问任何表的数据就可以得到结果;
详细解释见:MySQL :: MySQL 5.7 Reference Manual :: 8.8.2 EXPLAIN Output Forma
FirstMatch()
FirstMatch 是一种优化,这也是在处理半连接子查询时可能会用到的一种优化策略。
下面展示了一个构造 FirstMatch 的小 demo 例子:
mysql> explain select b1 from b where b1 in (select a1 from a)\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: b
partitions: NULL
type: index
possible_keys: b1
key: b1
key_len: 5
ref: NULL
rows: 6
filtered: 100.00
Extra: Using where; Using index
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: a
partitions: NULL
type: ref
possible_keys: a1
key: a1
key_len: 5
ref: db1.b.b1
rows: 1
filtered: 100.00
Extra: Using index; FirstMatch(b)
2 rows in set, 1 warning (0.00 sec)
mysql> explain select b1 from b where b1 in (select a1 from a);
+----+-------------+-------+------------+-------+---------------+------+---------+----------+------+----------+----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+----------+------+----------+----------------------------+
| 1 | SIMPLE | b | NULL | index | b1 | b1 | 5 | NULL | 6 | 100.00 | Using where; Using index |
| 1 | SIMPLE | a | NULL | ref | a1 | a1 | 5 | db1.b.b1 | 1 | 100.00 | Using index; FirstMatch(b) |
+----+-------------+-------+------------+-------+---------------+------+---------+----------+------+----------+----------------------------+
2 rows in set, 1 warning (0.01 sec)我们可以看到上面查询计划中,两个 id 都为1,且 extra 中列可以看到 FirstMatch(b)。MySQL 使用了连接来处理此查询,对于 a 表的行,只要能在 b 表中找到 1 条满足即可以不必再检索 b 表。从语义角度来看,和 IN-to-EXIST 策略转换为 Exist 子句是相似的,区别就是 FirstMath 以连接形式执行查询,而不是子查询。
参考:聊聊MySQL的子查询 - 活在夢裡 - 博客园 (cnblogs.com)
MySQL 半连接(semi-join)
所谓 semi-join 是指 semi-join 子查询。 当一张表在另一张表中找到匹配的记录之后,半连接(semi-jion)返回第一张表中的记录。
半连接是指一种查询优化技术,它仅仅返回两个表中匹配的数据,而不会返回另一个表中不匹配的数据。这个技术是在查询时使用。
MySQL 的半连接通过使用 IN 和 EXISTS 操作符来实现,这两个操作符的使用旨在提高查询效率。
select * from a where a1 in (select b1 from b);上述查询语句是使用 in 实现的半连接语句,它会查询表 a 中与表 b 中 b1 列匹配的数据。
select * from a where exists (select b1 from b where a.a1 = b.b1);上述查询语句是使用 exists 实现的半连接语句,它会查询表 a 中与表 b 中 b1 列匹配的数据。
这种查询的特点是我们只关心 a 中与 semi-join 相匹配的记录。
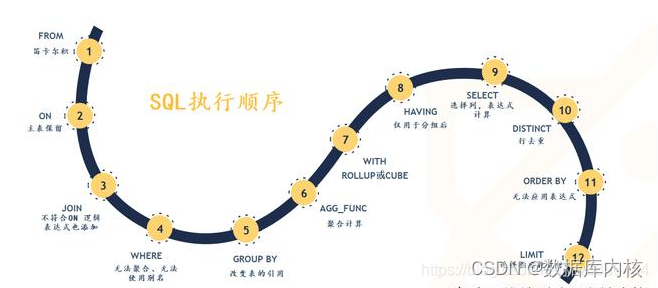
SELECT 语句各部分执行顺序
- FROM,对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
- ON,对虚表VT1进行ON筛选,只有那些符合的行才会被记录在虚表VT2中
- JOIN,如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, rug from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止
- WHERE,对虚拟表VT3进行WHERE条件过滤。只有符合的记录才会被插入到虚拟表VT4中
- GROUP BY,根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5
- WITH CUBE or WITH ROLLUP,对表VT5进行cube或者rollup操作,产生表VT6
- HAVING,对虚拟表VT6应用having过滤,只有符合的记录才会被 插入到虚拟表VT7中
- SELECT,执行select操作,选择指定的列,插入到虚拟表VT8中
- DISTINCT,对VT8中的记录进行去重。产生虚拟表VT9
- ORDER BY,将虚拟表VT9中的记录按照进行排序操作,产生虚拟表VT10
- TOP,取出指定行的记录,产生虚拟表VT11, 并将结果返回