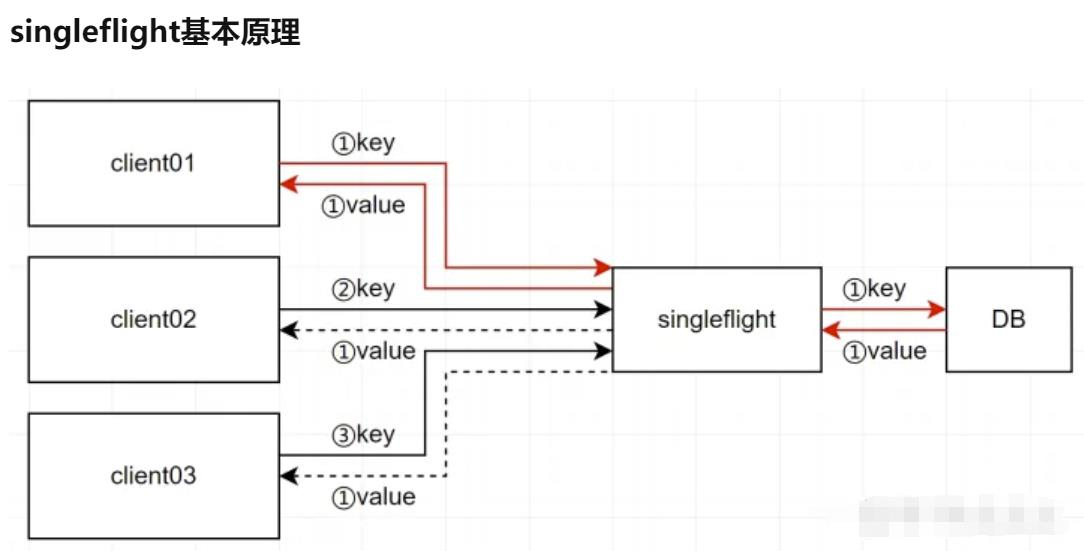
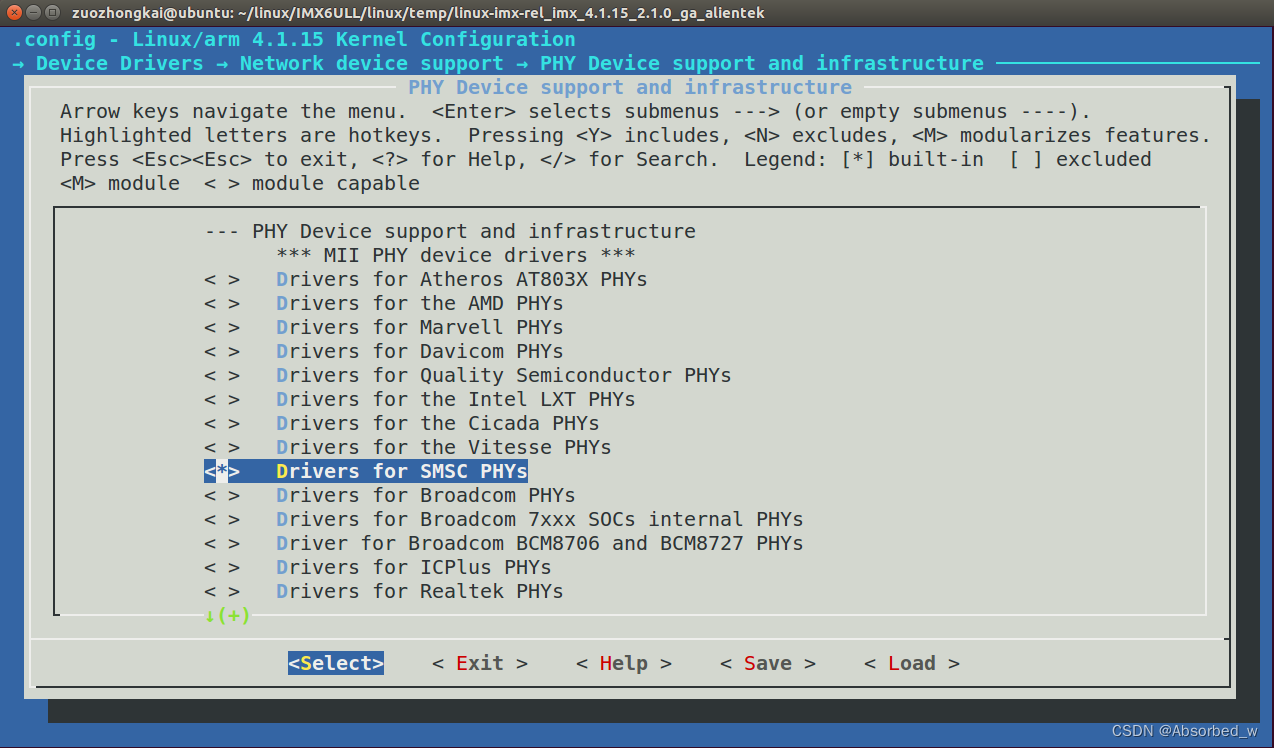
chatglm2部署在本地时,需要从huggingface上下载模型的权重文件(需要科学上网)。下载后权重文件会自动保存在本地用户的文件夹上。但这样不利于分享,下面介绍如何将chatglm2模型打包部署。
一、克隆chatglm2部署
这个项目是chatglm2的部署和实现方式,将模型以网页demo的形式呈现,其并不包含模型的结构。
git clone https://github.com/THUDM/ChatGLM2-6B二、克隆chatglm2模型
这个项目包含了模型的结构。GIT_LFS_SKIP_SMUDGE=1的意思是把大文件的大小都压缩为1KB。所以pytorch_model-00001到pytorch_model-00007这个七个文件和tokennizer.model下载后大小均为1KB。
假设该项目的路径是D:\\model。
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm2-6b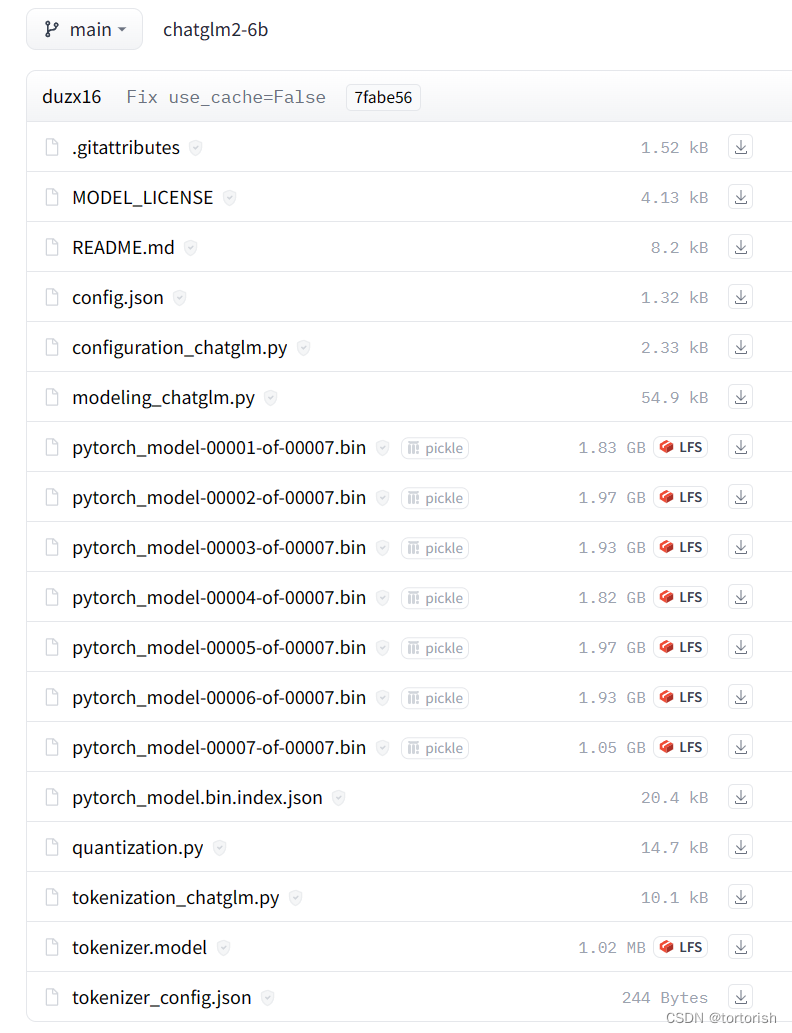
三、下载权重文件和语料库
从官方云盘里下载权重文件和tokennizer并对上述文件进行替换。官方模型权重

四、路径替换
更改下述代码中的路径"THUDM/chatglm2-6b"
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).cuda()在第二节中假设路径为D:\\model,那么在这里就将其改成:
tokenizer = AutoTokenizer.from_pretrained("D:\model", trust_remote_code=True)
model = AutoModel.from_pretrained("D:\model", trust_remote_code=True).cuda()部署成功!
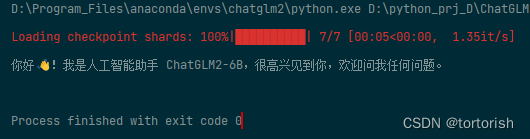
五、其它问题
部署的过程中会出现各种各样的问题。这里建议新建一个conda环境,然后再pip install -r requirements.txt安装依赖,将代码置于该环境下执行。此外,安装时务必注意cuda cudunn和python的对应关系。 这样就可以尽量避免报错。
有关cuda的安装可以看这篇:
Windows10下ChatGLM2-6B模型本地化安装部署教程图解_chatglm本地部署-CSDN博客