文章目录
- Python爬虫实战—探索某网站电影排名
- 准备工作
- 编写爬虫代码
- 代码解析
- 运行情况截图
- 进一步优化和说明
- 完整代码
- 总结
说明:本案例以XXX网站为例,已隐去具体网站名称与地址。
Python爬虫实战—探索某网站电影排名
网络爬虫是一种自动化程序,用于获取互联网上的信息。它们被广泛用于数据收集、搜索引擎和各种其他应用中。Python语言具有强大的网络爬虫库和工具,使得编写爬虫变得相对简单。在本文中,我们将介绍如何使用Python编写一个简单的网络爬虫,并以某网电影网站为例进行说明。
准备工作
首先,我们需要安装Python以及以下几个库:
- requests:用于发送HTTP请求和获取响应。
- lxml:用于解析HTML文档。
- csv:用于将数据保存到CSV文件中。
你可以使用pip命令来安装这些库:
pip install requests lxml
编写爬虫代码
以下是一个简单的某网电影网站爬虫示例代码:
import requests
from lxml import etree
import csv
import time
class DoubanSpider(object):
def __init__(self):
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
# 发请求 获响应
def get_source(self, com_url):
res = requests.get(com_url, headers=self.header)
html = res.content.decode('utf-8')
return html
# 解析数据
def parsed_source(self, html):
tree = etree.HTML(html)
divs = tree.xpath('//div[@class="info"]')
lis_data = []
for div in divs:
d = {}
title = div.xpath('./div[@class="hd"]/a/span/text()')[0].strip()
score = div.xpath('./div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0].strip()
evaluate = div.xpath('./div[@class="bd"]/div[@class="star"]/span[last()]/text()')[0].strip()
quote = div.xpath('./div[@class="bd"]/p[@class="quote"]/span/text()')
quote = quote[0] if quote else ''
link_url = div.xpath('./div[@class="hd"]/a/@href')[0].strip()
d['title'] = title
d['score'] = score
d['evaluate'] = evaluate
d['quote'] = quote
d['link_url'] = link_url
lis_data.append(d)
return lis_data
# 保存数据
def save_source(self, move_data, header):
with open('movie_data.csv', 'a', encoding='utf-8-sig', newline='') as f:
w = csv.DictWriter(f, header)
w.writerows(move_data)
# 主函数
def main(self):
start = int(input('输入要爬取的起始页:'))
end = int(input('输入要爬取的末尾页:'))
for i in range(start, end+1):
time.sleep(2)
page = (i-1) * 25
com_url = 'https://xxx/top250?start=' + str(page)
h = self.get_source(com_url)
print('爬虫机器人正在爬取第%d页' % i)
move_data = self.parsed_source(h)
header = ['title', 'score', 'evaluate', 'quote', 'link_url']
self.save_source(move_data, header)
if __name__ == '__main__':
Spider = DoubanSpider()
Spider.main()
代码解析
- 类
DoubanSpider
这是一个名为 DoubanSpider 的类,用于执行某网电影网站的爬取任务。
- 初始化方法
__init__()
在初始化方法中,我们设置了请求头,模拟了浏览器发送请求的行为。
get_source()方法
这个方法发送HTTP请求并获取响应内容。
parsed_source()方法
这个方法用于解析HTML内容,提取电影的相关信息,如标题、评分、评价人数、引用和链接URL。
save_source()方法
该方法用于将解析后的数据保存到CSV文件中。
main()方法
这是爬虫的主要逻辑。它接受用户输入的起始页和结束页,然后遍历每一页,调用其他方法执行爬取和保存数据的操作。
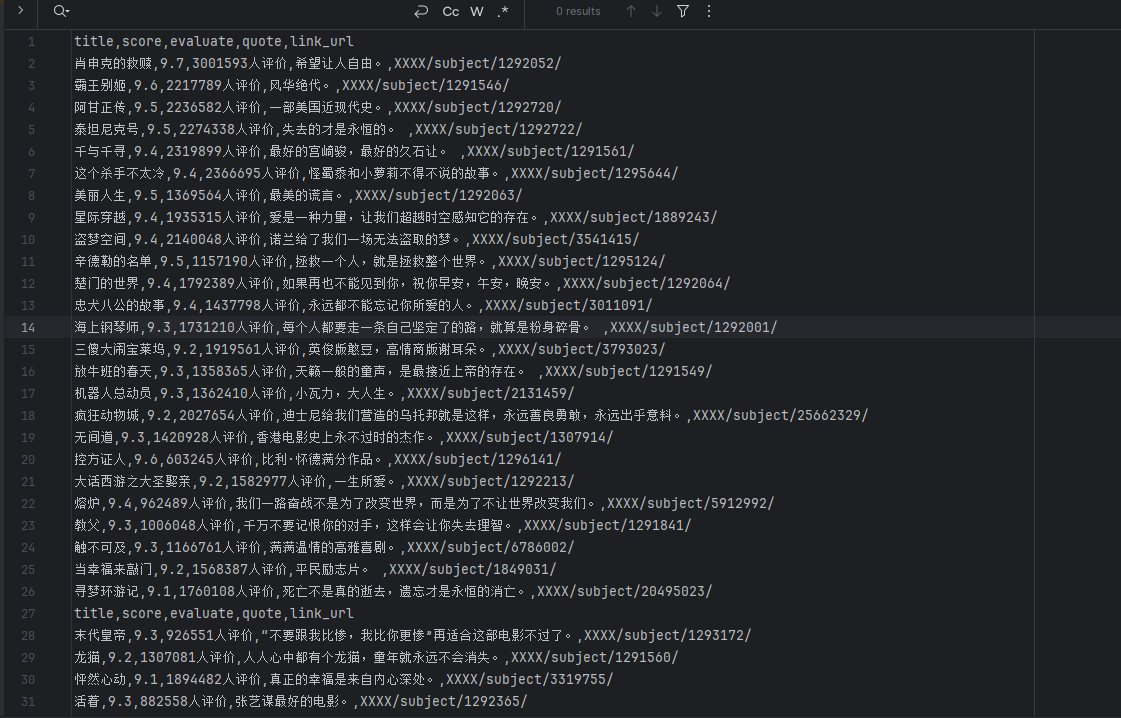
运行情况截图

进一步优化和说明
虽然以上代码可以完成基本的爬取任务,但还有一些优化和说明可以帮助提高代码的质量和可读性。
- 异常处理
在网络请求中,经常会出现各种异常情况,比如连接超时、请求失败等。为了增加代码的健壮性,可以添加异常处理机制。
try:
res = requests.get(com_url, headers=self.header)
res.raise_for_status() # 检查请求是否成功
except requests.RequestException as e:
print("请求异常:", e)
return None
- 数据去重
在爬取数据时,可能会出现重复的电影信息。为了避免重复,可以在保存数据之前进行去重操作。
def save_source(self, move_data, header):
# 去重
move_data = self.remove_duplicates(move_data)
with open('movie_data.csv', 'a', encoding='utf-8-sig', newline='') as f:
w = csv.DictWriter(f, header)
w.writerows(move_data)
def remove_duplicates(self, move_data):
unique_data = []
titles = set()
for item in move_data:
if item['title'] not in titles:
unique_data.append(item)
titles.add(item['title'])
return unique_data
- 使用生成器优化内存占用
在爬取大量数据时,可能会占用大量内存。可以使用生成器来优化内存占用。
def parsed_source(self, html):
tree = etree.HTML(html)
divs = tree.xpath('//div[@class="info"]')
for div in divs:
d = {}
title = div.xpath('./div[@class="hd"]/a/span/text()')[0].strip()
score = div.xpath('./div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0].strip()
evaluate = div.xpath('./div[@class="bd"]/div[@class="star"]/span[last()]/text()')[0].strip()
quote = div.xpath('./div[@class="bd"]/p[@class="quote"]/span/text()')
quote = quote[0] if quote else ''
link_url = div.xpath('./div[@class="hd"]/a/@href')[0].strip()
d['title'] = title
d['score'] = score
d['evaluate'] = evaluate
d['quote'] = quote
d['link_url'] = link_url
yield d
- 添加用户代理池
为了避免被网站识别为爬虫程序而被封禁IP,可以使用代理池来切换IP地址。
- 日志记录
添加日志记录功能可以方便调试和追踪爬取过程中的问题。
- 数据存储方式
除了CSV文件,还可以考虑使用数据库(如SQLite、MySQL等)来存储爬取的数据,以支持更复杂的数据操作和查询。
- 用户交互改进
在用户与爬虫交互方面,可以考虑添加输入参数的方式来控制爬虫的行为,而不是每次都手动输入起始页和结束页。
import argparse
def parse_arguments():
parser = argparse.ArgumentParser(description="某网电影Top250爬虫")
parser.add_argument("--start", type=int, default=1, help="起始页码")
parser.add_argument("--end", type=int, default=10, help="结束页码")
return parser.parse_args()
def main(self):
args = parse_arguments()
start = args.start
end = args.end
for i in range(start, end+1):
# 爬取逻辑不变
通过这种方式,用户可以在命令行中指定起始页和结束页,而不需要手动输入。
- 添加定时任务
如果需要定时执行爬虫任务,可以使用Python中的定时任务库(如APScheduler)来实现。
from apscheduler.schedulers.blocking import BlockingScheduler
def scheduled_task():
Spider = DoubanSpider()
Spider.main()
if __name__ == "__main__":
scheduler = BlockingScheduler()
scheduler.add_job(scheduled_task, "interval", minutes=60) # 每隔60分钟执行一次
scheduler.start()
- 添加单元测试
为了保证爬虫代码的稳定性和正确性,可以添加单元测试,验证爬虫函数的各个部分是否按照预期工作。
import unittest
class TestDoubanSpider(unittest.TestCase):
def test_get_source(self):
# 编写测试用例
def test_parsed_source(self):
# 编写测试用例
def test_save_source(self):
# 编写测试用例
if __name__ == '__main__':
unittest.main()
完整代码
import requests # 导入requests库,用于发送HTTP请求
from lxml import etree # 导入etree模块,用于解析HTML文档
import csv # 导入csv模块,用于读写CSV文件
import time # 导入time模块,用于添加延时
class DoubanSpider(object):
def __init__(self):
# 初始化函数,设置请求头,模拟浏览器发送请求
self.header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
# 发请求 获响应
def get_source(self, com_url):
# 发送HTTP请求并获取响应内容
res = requests.get(com_url, headers=self.header)
html = res.content.decode('utf-8')
return html
# 解析数据
def parsed_source(self, html):
# 解析HTML内容,提取电影相关信息
tree = etree.HTML(html)
divs = tree.xpath('//div[@class="info"]')
lis_data = []
for div in divs:
d = {}
# 提取标题
title = div.xpath('./div[@class="hd"]/a/span/text()')[0].strip()
# 提取评分
score = div.xpath('./div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0].strip()
# 提取评价人数
evaluate = div.xpath('./div[@class="bd"]/div[@class="star"]/span[last()]/text()')[0].strip()
# 提取引用
quote = div.xpath('./div[@class="bd"]/p[@class="quote"]/span/text()')
quote = quote[0] if quote else ''
# 提取电影链接url
link_url = div.xpath('./div[@class="hd"]/a/@href')[0].strip()
# 根据key值提取数据
d['title'] = title
d['score'] = score
d['evaluate'] = evaluate
d['quote'] = quote
d['link_url'] = link_url
lis_data.append(d)
return lis_data
# 保存数据
def save_source(self, move_data, header):
# 保存解析后的数据到CSV文件中
with open('movie_data.csv', 'a', encoding='utf-8-sig', newline='') as f:
w = csv.DictWriter(f, header)
# 写入表头
w.writeheader()
# 一次性写入多行数据
w.writerows(move_data)
# 主函数
def main(self):
start = int(input('输入要爬取的起始页:')) # 输入起始页码
end = int(input('输入要爬取的末尾页:')) # 输入结束页码
for i in range(start, end+1):
time.sleep(2) # 延时2秒,避免对目标服务器造成过大压力
page = (i-1) * 25
com_url = 'https://xxx/top250?start=' + str(page)
h = self.get_source(com_url)
print('爬虫机器人正在爬取第%d页' % i) # 打印爬取页面信息
move_data = self.parsed_source(h)
# 设置表头
header = ['title', 'score', 'evaluate', 'quote', 'link_url']
self.save_source(move_data, header) # 保存数据到CSV文件
if __name__ == '__main__':
# 实例化对象
Spider = DoubanSpider()
# 调用主函数
Spider.main()
总结
在本文中,我们介绍了如何使用Python编写一个简单的网络爬虫,并以某网电影网站为例进行了详细说明。通过对某网电影Top250页面的爬取,我们学习了发送HTTP请求、解析HTML文档、提取所需信息以及保存数据到CSV文件的基本操作。我们还对代码进行了进一步的优化,包括异常处理、数据去重、使用生成器优化内存占用、添加用户代理池等,以提高爬虫的稳定性、效率和可维护性。
除此之外,我们还讨论了一些提高爬虫功能和可用性的方法,如改进用户交互、添加定时任务、编写单元测试等。这些方法可以使得爬虫更加灵活和智能,满足不同场景下的需求,并提供了更多的扩展可能性。
在实际应用中,网络爬虫是一种强大的工具,可用于数据收集、信息监控、搜索引擎优化等各种领域。但是在使用爬虫时,我们必须遵守网站的使用条款和法律法规,尊重网站的隐私权和数据安全,避免对网站造成不必要的干扰和损害。
综上所述,本文介绍了从网络爬虫的基础知识到实际应用的全过程,希望能够帮助读者更好地理解和应用网络爬虫技术。在未来的工作中,我们可以进一步探索和应用更多的爬虫技巧,以满足不断变化的需求,并为数据获取和应用提供更多可能性。