一、前置知识
1 爬虫简介
网络爬虫(又被称作网络蜘蛛、网络机器人,在某些社区中也经常被称为网页追逐者)可以按照指定的规则(网络爬虫的算法)自动浏览或抓取网络中的信息。
1.1 Web网页存在方式
- 表层网页指的是不需要提交表单,使用静态的超链接就可以直接访问的静态页面。
- 深层网页指的是需要用户提交一些关键词才能获得的Wb页面。深层页面需要访问的信息数量是表层页面信息数量的几百倍,所以深层页面是主要的爬取对象。
1.2 网络爬虫的分类
1.2.1通用网络爬虫/全网爬虫
- 通用网络爬虫的爬行范围和数量巨大,对爬行速度和存储空间要求较高,通常采用并行工作方式,需要较长时间才可以刷新一次页面,所以存在着一定的缺陷。
- 主要应用于大型搜索引擎中,有非常高的应用价值。通用网络爬虫主要由初始URL(统一资源定位符)集合、UL队列、页面爬行模块,页面分析模块、页面数据库、链接过滤模块等构成。
1.2.2 聚焦网络爬虫/主题网络爬虫
- 主要指按照预先定义好的主题,有选择地进行相关网页爬取的一种网络爬虫,将爬取的目标网页定位在与主题相关的页面中,极大地节省了硬件和网络资源,保存的页面也由于数量少而更快了。
- 主要应用在对特定信息的爬取,为某一类特定的人群提供服务。
1.2.3 深层网络爬虫
深层网络爬虫主要通过六个基本功能的模块(爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表、LVS表)等部分构成。其中,LVS表示标签、数值集合,用来表示填充表单的数据源。
1.3 爬虫的原理
①获取初始的网络地址,该地址是用户自己制定的初始爬取的网页。
②通过爬虫代码向网页服务器发送网络请求。
③实现网页中数据的解析,确认数据在网页代码中的位置。
④在服务器响应数据中,提取数据内容。
⑤实现数据的清洗,将无用数据筛选。
⑥将清洗后的数据保存至本地或数据库当中。

2 HTTP原理
2.1 URL
使用浏览器访问网页时,需要在浏览器地址栏处填写目标网页的URL地址,统一资源定位符。
2.2 HTTP协议
HTTP(hypertext transfer protocol),即超文本传输协议,是互联网上应用最为厂厂泛的一种网络),主要利用TCP(传输控制协议)在web服务器和客户端之间传输信息的协议。客户端使用器发起HTTP请求给Web服务器,Web服务器发送被请求的信息给客户端。
2.2.1 HTTP与Web服务器
当在浏览器输人URL地址后,浏览器会先请求DNS域名系统服务器,获得请求站点的P地址(根据URL地址www.aliyun.com获取其对应的P地址,如101.201.120.85),然后发送一个HTTP请求(request)给拥有该IP的主机(阿里云服务器),接着就会接收到服务器返回的HTTP响应(response),浏览器经过渲染后,以一种较好的效果呈现给用户。
2.2.2 Web服务器工作原理
①建立连接:客户端通过TCP/IP(传输控制协议、网际协议)协议建立到服务器的TCP连接。
②请求过程:客户端向服务器发送HTTP协议请求包,请求服务器里的资源文档。
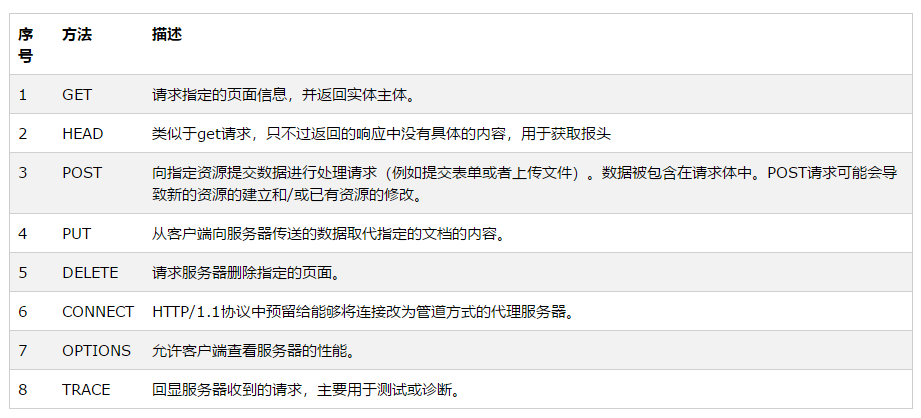
③应答过程:服务器向客户端发送HTTP协议应答包,如果请求的资源包含动态语言的内容,那么服务器会调用动态语言的解释引擎处理动态语言部分,并将处理后得到的数据返回给客户端。由客户端HTML(超文本标记语言)文档,并在客户端屏幕上渲染图形结果。服务器返回给客户端的状态码可分为5种类型,由它们的第一位数字表示。

④关闭连接:客户端与服务器断开连接。
2.2.3 浏览器中的请求与响应

3 urllib模块
3.1 urllib模块简介
Python3中将urib与urllib2模块的功能组合,并且命名为urllib。Python3中的urllib模块中包含多个功能的子模块,具体内容如下。
- urllib.request:用于实现基本HTTP请求的模块。
- urlb.error:异常处理模块,如果在发送网络请求时出现了错误,可以捕获的有效处理。
- urllib.parse:用于解析URL的模块。
- urllib.robotparser:用于解析robots.txt文件,判断网站是否可以爬取信息。
3.2 发送网络请求urllib.request.urlopen()
3.2.1 urllib.request.urlopen()函数简介
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)- url:需要访问网站的URL完整地址
- data:该参数默认为None,通过该参数确认请求方式,如果是None,表示请求方式为GET,否则请求方式为POST。在发送POST请求时,参数daa需要以字典形式的数据作为参数值,并且需要将字典类型的参数值转换为字节类型的数据才可以实现POST请求。
- timeout:设置网站访问超时时间,以秒为单位。
- cafile:指定包含CA证书的单个文件,
- capah:指定证书文件的目录。
- cadefault:CA证书默认值
- context:描述SSL选项的实例。
3.2.2 发送GET请求
import urllib.request
response = urllib.request.urlopen("https://www.baidu.com/")
print("response:",response)
# 输出: response: <http.client.HTTPResponse object at 0x000001AD2793C850>3.2.3 获取状态码、响应头、获取HTMl代码
import urllib.request
url = "https://www.baidu.com/"
response = urllib.request.urlopen(url=url)
print("响应状态码:",response.status)
# 输出: 响应状态码: 200
print("响应头信息:",response.getheaders())
# 响应头信息: [('Accept-Ranges', 'bytes'), ('Cache-Control', 'no-cache'), ('Content-Length', '227'), ('Content-Type', 'text/html'), ('Date', 'Wed, 09 Mar 2022 10:45:04 GMT'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('P3p', 'CP=" OTI DSP COR IVA OUR IND COM "'), ('Pragma', 'no-cache'), ('Server', 'BWS/1.1'), ('Set-Cookie', 'BD_NOT_HTTPS=1; path=/; Max-Age=300'), ('Set-Cookie', 'BIDUPSID=5C4759402F5A8C38E347A1E6FB8788EF; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'PSTM=1646822704; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com'), ('Set-Cookie', 'BAIDUID=5C4759402F5A8C384F12C0C34D5D3B36:FG=1; max-age=31536000; expires=Thu, 09-Mar-23 10:45:04 GMT; domain=.baidu.com; path=/; version=1; comment=bd'), ('Strict-Transport-Security', 'max-age=0'), ('Traceid', '1646822704264784359414774964437731406767'), ('X-Frame-Options', 'sameorigin'), ('X-Ua-Compatible', 'IE=Edge,chrome=1'), ('Connection', 'close')]
print("响应头指定信息:",response.getheader('Accept-Ranges'))
# 响应头指定信息: bytes
print("目标页面的Html代码 \n ",response.read().decode('utf-8'))
# 即为Html文件的内容3.2.4 发送POST请求
urlopen()方法在默认的情况下发送的是GET请求,如果需要发送POST请求,可以为其设置data参数、该参数是byte类型,需要使用bytes()方法将参数值进行数据类型转换
import urllib.request
import urllib.parse
url = "https://www.baidu.com/"
data = bytes(urllib.parse.urlencode({'hello':'python'}),encoding='utf-8') # 将表单转化为bytes类型,并且设置编码
response = urllib.request.urlopen(url=url,data=data,timeout=0.1) # 发送网络请求 设置超时时间0.1s
print(response.read().decode('utf-8')) # 读取Html代码进行编码3.2.5 处理网络超市异常
如果遇到了超时异常,爬虫程序将在此处停止。所以在实际开发中开发者可以将超时异常捕获,然后处理下面的爬虫任务。以上述发送网络请求为例,将超时参数imeout设置为0.1s,然后使用try...excpt 捕获异常并判断如果是超时异常就模拟自动执行下一个任务。
import urllib.request
import urllib.error
import socket
url = "https://www.baidu.com/"
try:
response = urllib.request.urlopen(url=url,timeout=0.1)
print(response.read().decode('utf-8'))
except urllib.error.URLError as error :
if isinstance(error.reason,socket.timeout):
print("当前任务已经超时,即将执行下一任务")4 设置请求头
4.1 urllib.request.Request()
urlopen()方法可以实现最基本的请求的发起,但如果要加入Headers等信息,就可以利用Request类来构造请求。
4.1.1 函数原型
使用方法为:
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)4.1.2 参数解析
- url:要请求的URL地址
- data :必须是bytes(字节流)类型,如果是字典,可以用urllib.parse模块里的urlencode()编码
- headers:是一个字典类型,是请求头。①在构造请求时通过headers参数直接构造,也可以通过调用请求实例的add_header()方法添加。②通过请求头伪装浏览器,默认User-Agent是Python-urllib。要伪装火狐浏览器,可以设置User-Agent为Mozilla/5.0 (x11; U; Linux i686) Gecko/20071127 Firefox/2.0.0.11
- origin_req_host:指定请求方的host名称或者ip地址
- unverifiable:设置网页是否需要验证,默认是False,这个参数一般也不用设置。
- method :字符串,用来指定请求使用的方法,比如GET,POST和PUT等。
4.1.3 设置请求头的作用
请求头参数是为了模拟浏览器向网页后台发送网络请求,这样可以避免服务器的反爬措施。使用urlopen()方法发送网络请求时,其本身并没有设置请求头参数,所以向测试地址发送请求时,返回的信息中headers将显示默认值。
所以在设置请求头信息前,需要在浏览器中找到一个有效的请求头信息。以谷歌浏览器为例2
4.1.4 手动寻找请求头
F12打开开发工具,选择 Network 选项,接着任意打开一个网页,在请求列表中找到Headers选项中找到请求头。

4.2 设置请求头
import urllib.request
import urllib.parse
url = "https://www.baidu.com/" # 设置请求地址
#设置请求头信息
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}
# data转化为bytes类型,并设置编码方式
data = bytes(urllib.parse.urlencode({'hello':'python'}),encoding='utf-8')
# 创建Request类型对象
url_post = urllib.request.Request(url=url,data=data,headers=headers,method='POST')
# 发送网络请求
response = urllib.request.urlopen(url_post)
# 读取HTMl代码并进行UTF-8编码
print(response.read().decode('utf-8'))5 Cookie
Cookie是服务器向客户端返回响应数据时所留下的标记,当客户端再次访问服务器时将携带这个标记。一般在实现登录一个页面时,登录成功后,会在浏览器的Cookie中保留一些信息,当浏览器再次访问时会携带Cook中的信息,经过服务器核对后便可以确认当前用户已经登录过,此时可以直接将登录后的数据返回。
在使用网络爬虫获取网页登录后的数据时,除了使用模拟登录以外,还可以获取登录后的Cookie,然后利用这个Cookie再次发送请求时,就能以登录用户的身份获取数据。
5.1 模拟登陆
5.1.1 登陆前准备
目标地址:site2.rjkflm.com:666
账号:test01test
密码:123456
5.1.2 查看登陆目标地址
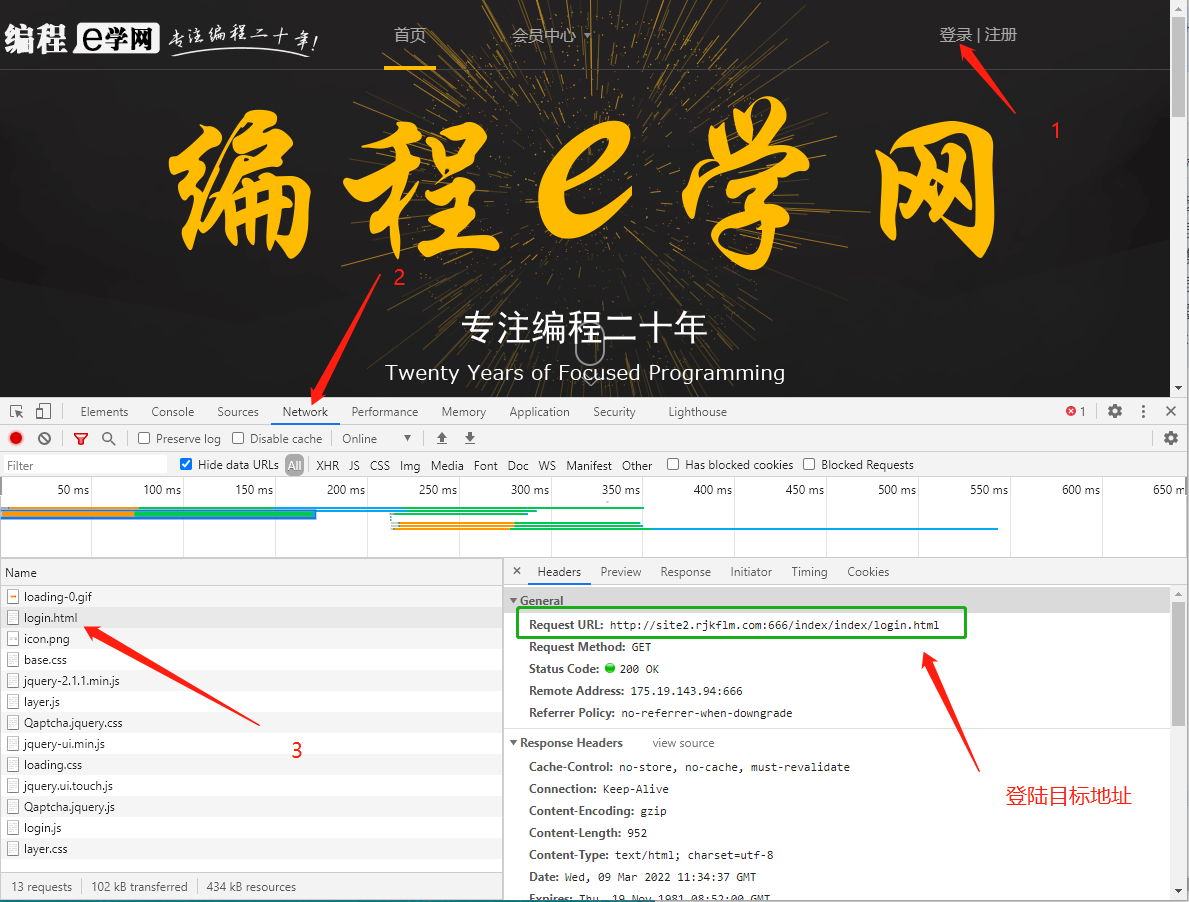
得到以下信息
Request URL:http://site2.rjkflm.com:666/index/index/login.html
5.1.2 实现模拟登陆
import urllib.request
import urllib.parse
url = "http://site2.rjkflm.com:666/index/index/chklogin.html"
# 设置表单
data = bytes(urllib.parse.urlencode({'username':'test01test','password':'123456'}),encoding='utf-8')
# 将bytes转化,并且设置编码
r = urllib.request.Request(url=url,data=data,method='POST')
response = urllib.request.urlopen(r) # 发送请求
print(response.read().decode('utf-8'))
# 返回:{"status":true,"msg":"登录成功!"}5.1.3 获取Cookies
import urllib.request
import urllib.parse
import http.cookiejar
import json
url = "http://site2.rjkflm.com:666/index/index/chklogin.html"
# 设置表单
data = bytes(urllib.parse.urlencode({'username':'test01test','password':'123456'}),encoding='utf-8')
cookie_file = 'cookie.txt'
cookie = http.cookiejar.LWPCookieJar(cookie_file) # 创建LWPCookieJar对象
# 生成 Cookie处理器
cookie_processor = urllib.request.HTTPCookieProcessor(cookie)
# 创建opener对象
opener = urllib.request.build_opener(cookie_processor)
response = opener.open(url,data=data) # 发送网络请求
response = json.loads(response.read().decode('utf-8'))['msg']
if response == '登陆成功':
cookie.save(ignore_discard=True,ignore_expires=True) # 保存Cookie文件5.1.4 载入Cookies
import urllib.request
import http.cookies
import urllib.request # 导入urllib.request模块
import http.cookiejar # 导入http.cookiejar子模块
# 登录后页面的请求地址
url = 'http://site2.rjkflm.com:666/index/index/index.html'
cookie_file = 'cookie.txt' # cookie文件
cookie = http.cookiejar.LWPCookieJar() # 创建LWPCookieJar对象
# 读取cookie文件内容
cookie.load(cookie_file,ignore_expires=True,ignore_discard=True)
# 生成cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
# 创建opener对象
opener = urllib.request.build_opener(handler)
response = opener.open(url) # 发送网络请求
print(response.read().decode('utf-8')) # 打印登录后页面的html代码二、项目简介
必应是微软推出的搜索引擎,相比于百度具有广告少的显著优点,比较良心。以下为必应的网址:必应
经常使用必应应该可以发现,其主页每天都会更新一张图片,博主发现这些图片非常符合博主的审美,希望每天能够下载收藏每张图片。幸运的是已经有人完成了这项工作,具体请看这个网站:必应每日高清壁纸(必应每日高清壁纸 - 精彩,从这里开始)。
这个网站收录了必应每天的主页图片,并且提供直接下载(管理猿太良心了,祝愿少掉一些头发,少写一些bug )。但是博主发现这个网站缺少一个一键全部下载功能,只能一张一张图片手动下载,如果要把所有图片都下载下来,非常麻烦,因此用python写了一个下载网站上所有图片的小爬虫,分享给大家。
三、使用的环境
- python3.8.1(较新版本都可)
- requests库(需要使用pip工具下载该库)
- re库(python自带,不用下载,直接导入就行)
- bs4库(需要使用pip工具下载该库)
1 分析页面
1.1 分析网址
https://bing.ioliu.cn/?p=11.2 元素寻找页面
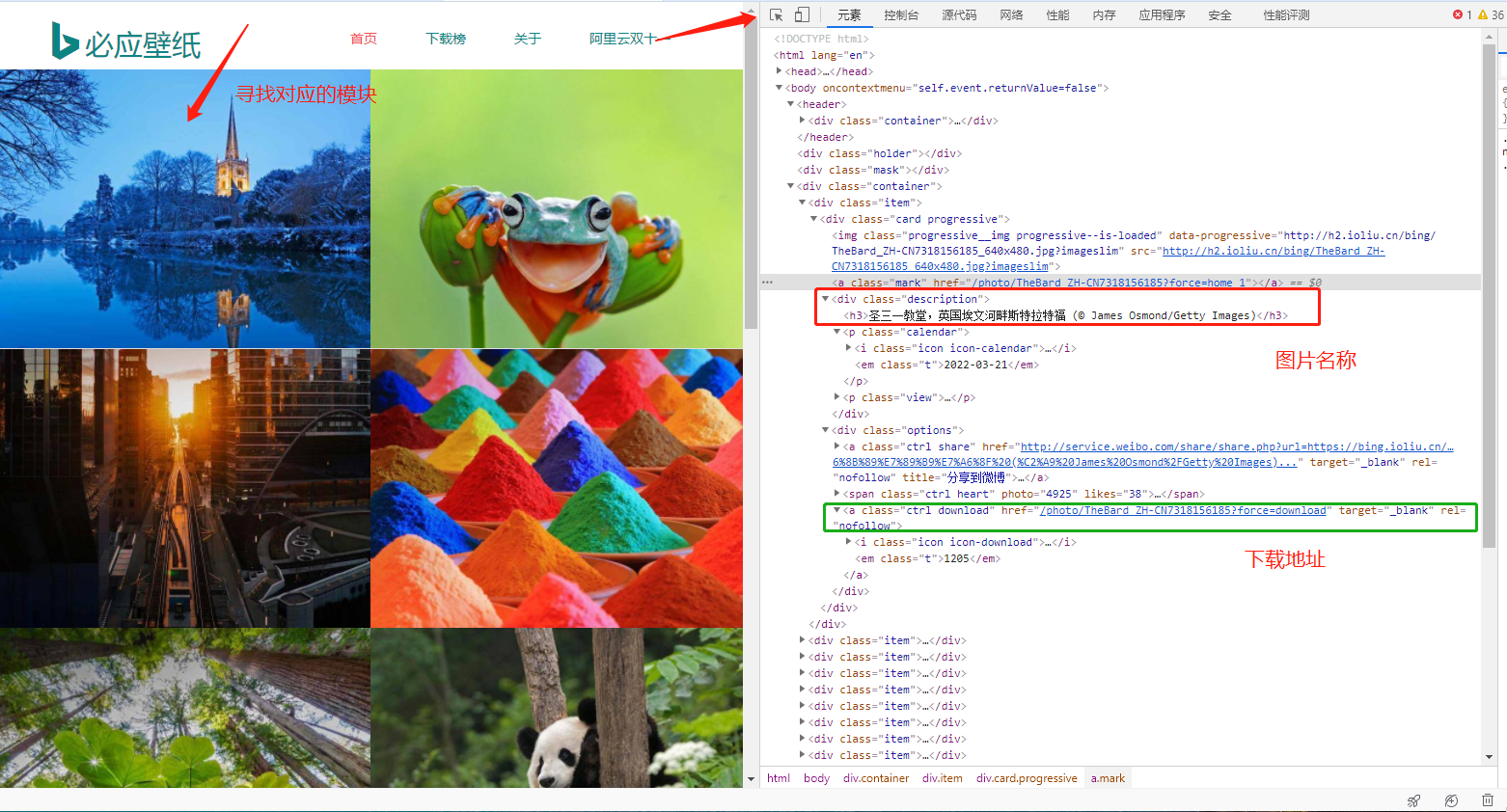
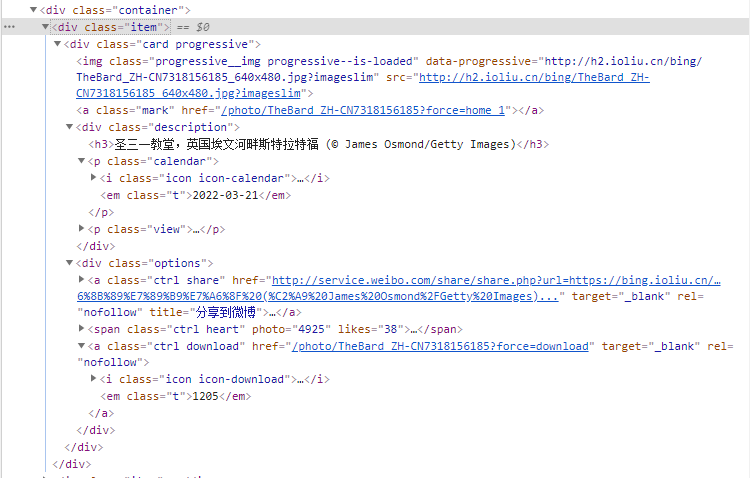
2 代码编写
import urllib3
import re
import os
http = urllib3.PoolManager() # 创建连接池管理对象
# 定义火狐浏览器请求头信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0'}
# 通过网络请求,获得该页面的信息
def send_request(url,headers):
response = http.request('GET',url,headers=headers)
if response.status == 200:
html_str = response.data.decode('utf-8')
return html_str
# 解析地址并下载壁纸
def download_pictures(html_str):
# 提取壁纸名称
pic_names = re.findall('<div class="description"><h3>(.*?)</h3>',html_str)
print("未处理的壁纸名称:",pic_names)
# 提取壁纸的下载地址
pic_urls = re.findall('<a class="ctrl download" href="(.*?)" ',html_str)
print("未处理的下载地址:", pic_urls)
for name,url in zip(pic_names,pic_urls): # 遍历壁纸的名称与地址
pic_name = name.replace('/',' ') # 把图片名称中的/换成空格
pic_url = 'https://bing.ioliu.cn'+url # 组合一个完整的url
pic_response = http.request('GET',pic_url,headers=headers) # 发送网络请求,准备下载图片
if not os.path.exists('pic'): # 判断pic文件夹是否存在
os.mkdir('pic') # 创建pic文件夹
with open('pic/'+pic_name+'.jpg','wb') as f:
f.write(pic_response.data) # 写入二进制数据,下载图片
print('图片:',pic_name,'下载完成了!')
if __name__ == '__main__':
for i in range(1, 2):
url = 'https://bing.ioliu.cn/p={}'.format(i)
print(url)
html_str = send_request(url=url, headers=headers) # 调用发送网络请求的方法
download_pictures(html_str=html_str) # 调用解析数据并下载壁纸的方法3 效果展示