目录
人脸68关键点检测
检测闭眼睁眼
双眼关键点检测
计算眼睛的闭合程度:
原理:
设置阈值进行判断
实时监测和更新
拓展:通过判断上下眼皮重合程度去判断是否闭眼
检测嘴巴是否闭合
提取嘴唇上下轮廓的关键点
计算嘴唇上下轮廓关键点之间的距离
计算嘴角到上嘴唇中心的距离
计算嘴角到下嘴唇中心的距离
将两个距离相加作为嘴唇的闭合程度指标
判断嘴巴是否闭合
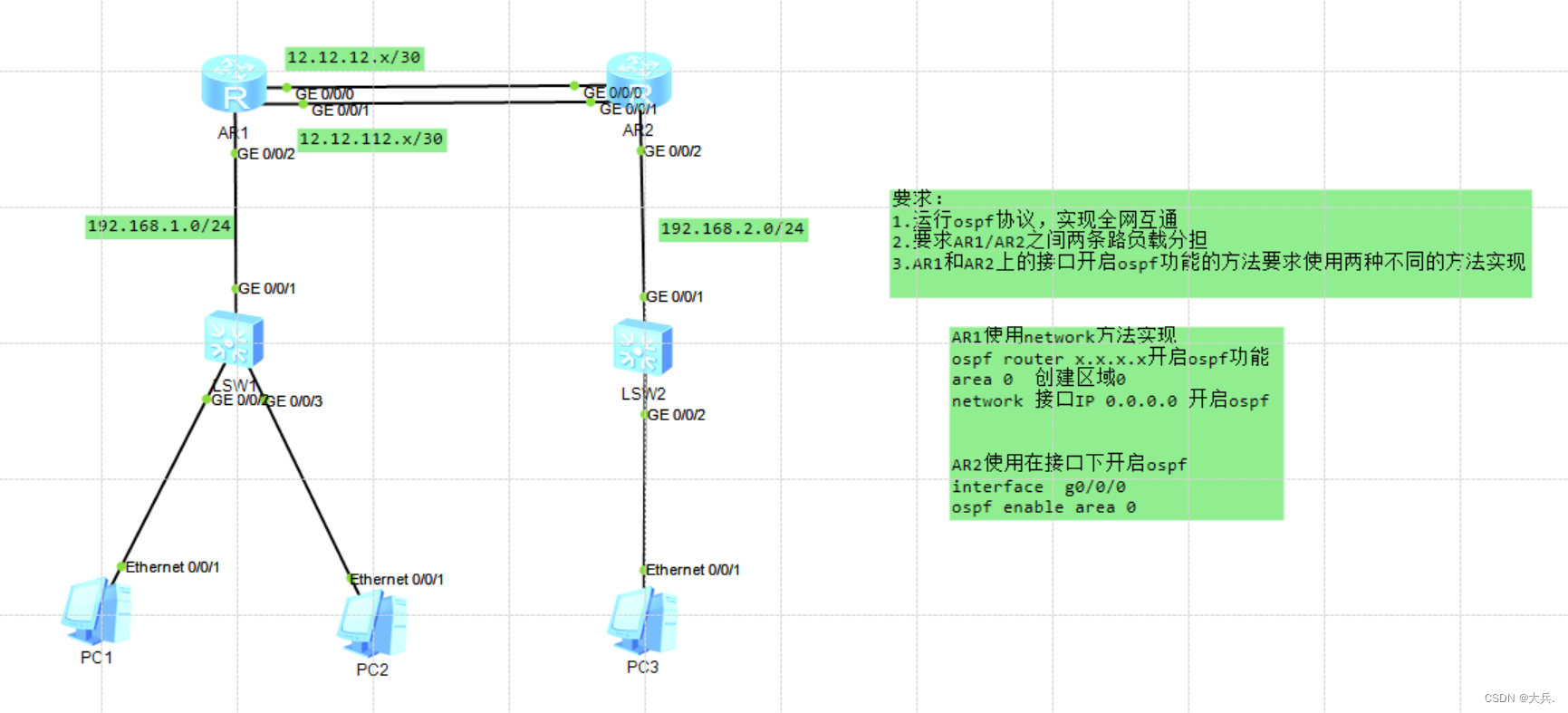
K210疲劳检测
前两天在做项目的时候,想通过偷懒的方式去试试,不用目标检测去检测疲劳,而是通过人脸检测的68关键点去通过检测睁眼闭眼和张嘴闭嘴去检测闭眼和打瞌睡。那让我们来试试吧。
人脸68关键点检测
人脸68关键点检测是一种计算机视觉技术,旨在识别和定位人脸图像中的关键点。这些关键点通常包括眼睛、鼻子、嘴巴等面部特征的位置。通过检测这些关键点,可以实现人脸识别、表情识别、姿势估计等
主要的步骤:
- 检测人脸:首先需要使用人脸检测算法确定图像中人脸的位置。
- 提取关键点:在检测到的人脸区域内,使用特定的算法来识别和标记关键点的位置。
- 分类关键点:将检测到的关键点分为不同的类别,如眼睛、鼻子、嘴巴等。

检测闭眼睁眼
双眼关键点检测
在68个关键点中,一般左眼和右眼的位置会分别由多个关键点表示。这些关键点的坐标通常以 (x, y) 形式给出,其中 x 表示水平方向的位置,y 表示垂直方向的位置。
import cv2
# 加载人脸关键点检测器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 读取图像
img = cv2.imread('face_image.jpg')
# 转换为灰度图
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = detector(gray)
for face in faces:
# 获取关键点
landmarks = predictor(gray, face)
for n in range(37, 48): # 提取左眼和右眼的关键点
x = landmarks.part(n).x
y = landmarks.part(n).y
cv2.circle(img, (x, y), 2, (0, 255, 0), -1) # 在关键点处画圆
计算眼睛的闭合程度:
原理:
通过计算眼睛关键点的纵向位置(Y 坐标)的差值,并加权求和来反映眼睛的状态。
对于每只眼睛,首先计算关键点的纵向位置(Y 坐标)的差值。可以选择一些具有代表性的关键点来进行计算,比如眼睛的上下眼睑或者眼角等位置点。 对这些差值进行加权求和,可以根据不同的应用场景进行加权,比如可以将靠近眼睛中心的关键点的差值赋予更高的权重,因为这些部位更能反映眼睛的状态。
眼睛闭合程度计算公式:
- 首先,选择上眼睑和下眼睑的关键点,分别计算它们的平均纵向位置(Y 坐标)。
- 然后,通过上眼睑平均位置减去下眼睑平均位置,得到一个值表示眼睛的闭合程度。这个值越小,表示眼睛越闭合\
[ \text{闭合程度} = \text{上眼睑平均位置} - \text{下眼睑平均位置} ]
其中,上眼睑平均位置和下眼睑平均位置分别表示对应关键点的纵向位置的平均值。
# 计算眼睛的闭合程度
def eye_closure_ratio(eye_landmarks):
# 假设我们选取了上眼睑关键点的索引为[1, 2, 3],下眼睑关键点的索引为[4, 5, 6]
upper_lid_points = eye_landmarks[1:4]
lower_lid_points = eye_landmarks[4:7]
# 计算上下眼睑的平均纵向位置
upper_lid_y_mean = sum([point[1] for point in upper_lid_points]) / len(upper_lid_points)
lower_lid_y_mean = sum([point[1] for point in lower_lid_points]) / len(lower_lid_points)
# 计算纵向位置的差值,这里可以根据具体情况加权求和
diff = upper_lid_y_mean - lower_lid_y_mean
return diff
设置阈值进行判断
根据实际情况,可以设置一个阈值来判断眼睛是否闭合。当加权求和的结果小于阈值时,可以认为眼睛是闭合的;反之则是睁开的。
# 判断眼睛是否闭合
def is_eye_closed(eye_landmarks, threshold):
closure_ratio = eye_closure_ratio(eye_landmarks)
if closure_ratio < threshold:
return True # 眼睛闭合
else:
return False # 眼睛睁开实时监测和更新
在实时监测过程中,不断更新眼睛关键点的位置信息,并重新计算眼睛的闭合程度,以实现对眼睛状态的准确监测。
# 循环实时监测
while True:
ret, frame = cap.read() # 从摄像头读取画面
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = detector(gray)
for face in faces:
landmarks = predictor(gray, face)
left_eye_landmarks = [(landmarks.part(n).x, landmarks.part(n).y) for n in range(36, 42)] # 左眼关键点
right_eye_landmarks = [(landmarks.part(n).x, landmarks.part(n).y) for n in range(42, 48)] # 右眼关键点
# 计算左眼闭合程度并判断
left_eye_closed = is_eye_closed(left_eye_landmarks, 5) # 假设阈值设为5
# 计算右眼闭合程度并判断
right_eye_closed = is_eye_closed(right_eye_landmarks, 5) # 假设阈值设为5
# 综合判断眼睛状态
if left_eye_closed and right_eye_closed:
print("Both eyes closed")
elif left_eye_closed:
print("Left eye closed")
elif right_eye_closed:
print("Right eye closed")
else:
print("Eyes open")
拓展:通过判断上下眼皮重合程度去判断是否闭眼
通过判断上下眼皮的重合程度来间接判断眼睛是否闭合。当眼睛闭合时,上下眼皮会有一定程度的重合,而睁开时则不会存在明显的重合。
具体实现方法可以是计算上下眼睑之间的垂直距离,并将其与总眼睛高度的比值作为闭合程度的度量指标。当这个比值超过一定阈值时,可以判断为闭眼状态
# 计算上下眼皮重合程度
def eyelid_overlap_ratio(eye_landmarks):
# 假设我们选取了上眼睑关键点的索引为[1, 2, 3],下眼睑关键点的索引为[4, 5, 6]
upper_lid_points = eye_landmarks[1:4]
lower_lid_points = eye_landmarks[4:7]
# 计算上下眼睑之间的垂直距离
vertical_distance = lower_lid_points[0][1] - upper_lid_points[-1][1]
# 计算垂直距离与总眼睛高度的比值
eye_height = max(eye_landmarks, key=lambda x: x[1])[1] - min(eye_landmarks, key=lambda x: x[1])[1]
overlap_ratio = vertical_distance / eye_height
return overlap_ratio
检测嘴巴是否闭合
提取嘴唇上下轮廓的关键点
根据人脸关键点的位置信息,提取出嘴唇上下轮廓的关键点。一般而言,嘴唇上下轮廓的关键点包括嘴角、上嘴唇中心、下嘴唇中心等关键点。
计算嘴唇上下轮廓关键点之间的距离
选择合适的距离度量方法(如欧氏距离)计算嘴唇上下轮廓关键点之间的距离。具体来说,可以计算嘴角到上嘴唇中心和嘴角到下嘴唇中心的距离,并将这两个距离相加作为嘴唇的闭合程度指标。
计算嘴角到上嘴唇中心的距离
使用欧氏距离公式计算嘴角到上嘴唇中心的距离: [ distance_top = \sqrt{(x_{top} - x_{corner})^2 + (y_{top} - y_{corner})^2} ] 其中 (x_{top}) 和 (y_{top}) 分别是上嘴唇中心的 x、y 坐标,(x_{corner}) 和 (y_{corner}) 分别是嘴角的 x、y 坐标。
计算嘴角到下嘴唇中心的距离
同样使用欧氏距离公式计算嘴角到下嘴唇中心的距离: [ distance_bottom = \sqrt{(x_{bottom} - x_{corner})^2 + (y_{bottom} - y_{corner})^2} ] 其中 (x_{bottom}) 和 (y_{bottom}) 分别是下嘴唇中心的 x、y 坐标。
将两个距离相加作为嘴唇的闭合程度指标
将嘴角到上嘴唇中心的距离 (distance_top) 和嘴角到下嘴唇中心的距离 (distance_bottom) 相加,得到嘴唇的闭合程度指标: [ distance_total = distance_top + distance_bottom ]
判断嘴巴是否闭合
设定一个阈值,根据嘴唇上下轮廓关键点之间的距禀与该阈值的比较结果来判断嘴巴是否闭合。通常情况下,当嘴唇闭合时,嘴唇上下轮廓的关键点之间的距离会比较小;而当嘴巴张开时,这个距离会增大。
import math
# 计算欧氏距离
def euclidean_distance(point1, point2):
return math.sqrt((point2[0] - point1[0])**2 + (point2[1] - point1[1])**2)
# 提取嘴唇上下轮廓的关键点索引(假设为索引0到11)
mouth_landmarks = face_landmarks[0:12] # 假设face_landmarks包含了所有68个关键点的坐标
# 计算嘴唇上下轮廓关键点之间的距离
lip_distances = []
for i in range(len(mouth_landmarks)//2):
distance = euclidean_distance(mouth_landmarks[i], mouth_landmarks[i + len(mouth_landmarks)//2])
lip_distances.append(distance)
# 计算平均距离
avg_distance = sum(lip_distances) / len(lip_distances)
# 设定阈值
threshold = 5.0
# 判断嘴巴是否闭合
if avg_distance < threshold:
print("嘴巴闭合")
else:
print("嘴巴张开")
K210疲劳检测
项目的来源:对K210人脸检测68关键点的一种拓展
如何通过人脸检测68关键点去检测疲劳情况
代码是根据K210的例程改的,也只是使用上下眼皮的距离和上下嘴唇的距离来检测疲劳状态
import sensor, image, time, lcd
from maix import KPU
import gc
lcd.init()
sensor.reset()
sensor.set_pixformat(sensor.RGB565)
sensor.set_framesize(sensor.QVGA)
sensor.set_vflip(True) # 摄像头后置
sensor.skip_frames(time=500)
clock = time.clock()
od_img = image.Image(size=(320, 256), copy_to_fb=False)
# 构建KPU对象
# 需要导入2个模型,分别是人脸检测模型和68关键点检测模型
anchor = (0.893, 1.463, 0.245, 0.389, 1.55, 2.58, 0.375, 0.594, 3.099, 5.038, 0.057, 0.090, 0.567, 0.904, 0.101, 0.160, 0.159, 0.255)
kpu_face_detect = KPU()
print("Loading face detection model")
kpu_face_detect.load_kmodel("/sd/face_detect.kmodel")
kpu_face_detect.init_yolo2(anchor, anchor_num=9, img_w=320, img_h=240, net_w=320, net_h=256, layer_w=10, layer_h=8, threshold=0.7, nms_value=0.2, classes=1)
kpu_lm68 = KPU()
print("Loading landmark 68 model")
kpu_lm68.load_kmodel("/sd/landmark68.kmodel")
RATIO = 0.08
while True:
gc.collect()
clock.tick() # Update the FPS clock.
img = sensor.snapshot()
od_img.draw_image(img, 0, 0)
od_img.pix_to_ai()
kpu_face_detect.run_with_output(od_img)
detections = kpu_face_detect.regionlayer_yolo2()
fps = clock.fps()
if len(detections) > 0:
for det in detections:
x1_t = max(int(det[0] - RATIO * det[2]), 0)
x2_t = min(int(det[0] + det[2] + RATIO * det[2]), 319)
y1_t = max(int(det[1] - RATIO * det[3]), 0)
y2_t = min(int(det[1] + det[3] + RATIO * det[3]), 255)
cut_img_w = x2_t - x1_t + 1
cut_img_h = y2_t - y1_t + 1
face_cut = img.cut(x1_t, y1_t, cut_img_w, cut_img_h)
face_cut_128 = face_cut.resize(128, 128)
face_cut_128.pix_to_ai()
out = kpu_lm68.run_with_output(face_cut_128, getlist=True)
if out is not None:
left_eye_height = out[41][1] - out[37][1]
right_eye_height = out[47][1] - out[43][1]
eye_height_avg = (left_eye_height + right_eye_height) / 2
mouth_height = out[66][1] - out[62][1]
if eye_height_avg < 10 and mouth_height > 15:
print("Tired: Eyes closed, Mouth open")
elif eye_height_avg < 10:
print("Tired: Eyes closed")
elif mouth_height > 15:
print("Tired: Mouth open")
del face_cut_128
del face_cut
img.draw_string(0, 0, "%2.1f fps" % fps, color=(0, 60, 255), scale=2.0)
lcd.display(img)
gc.collect()
kpu_face_detect.deinit()
kpu_lm68.deinit()