作者:CSDN @ _养乐多_
在神经网络领域,梯度下降是一种核心的优化算法,本文将介绍神经网络中梯度下降法更新参数的公式,并通过实例演示其在模型训练中的应用。通过本博客,读者将能够更好地理解深度学习中的优化算法和损失函数,为学习和应用深度学习打下坚实的基础。
文章目录
- 一、概念
- 1.1 交叉熵损失函数
- 1.2 梯度下降
- 二、梯度下降更新模型参数
- 2.1 定义模型
- 2.2 损失函数的定义
- 2.3 对于权重 w i w_i wi的更新
- 2.4 对于偏置 b b b的更新
- 三、举例推导
- 3.1 样本数据
- 3.2 初始化模型
- 3.3 第1次迭代
- 3.4 第2次迭代
- 3.5 第n次迭代
- 四、其他
一、概念
1.1 交叉熵损失函数
了解梯度下降方法更新参数之前,需要先了解交叉熵损失函数,可以参考《损失函数|交叉熵损失函数》,讲的很详细。交叉熵可以理解为模型输出值和真实值之间的差异,交叉熵损失越小,表示模型预测结果与真实情况越接近,模型的精度也就越高。
梯度下降更新参数的过程其实就是在反向求导减小梯度的过程中找到差异最小时的模型参数。
1.2 梯度下降
在机器学习和深度学习中,经常需要通过调整模型的参数来使其在训练数据上表现得更好,而梯度下降是一种常用的方法。
梯度下降的基本思想是沿着目标函数的负梯度方向进行迭代,以找到函数的局部最小值。具体而言,对于一个多维函数,梯度下降通过计算目标函数在当前参数位置的梯度(即偏导数),然后按照梯度的反方向更新参数,使得函数值不断减小。这个过程重复进行,直到达到某个停止条件,比如达到了指定的迭代次数或者目标函数的变化小于某个阈值。
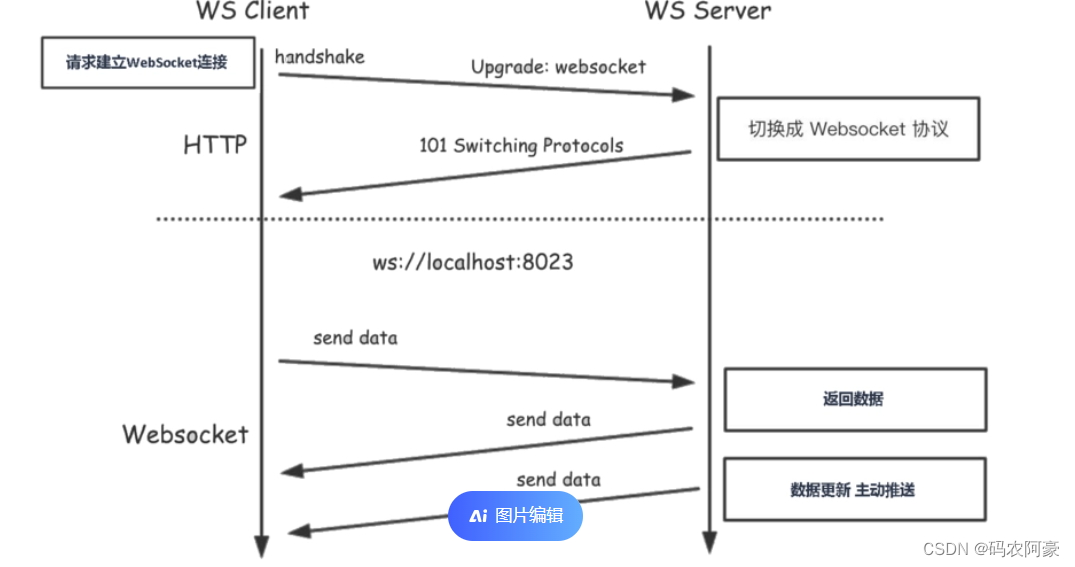
梯度下降的核心公式:
θ n e w = θ − η ∂ L O S S ∂ θ (1) θ^{new}=θ-η \frac {∂LOSS}{∂θ}\tag{1} θnew=θ−η∂θ∂LOSS(1)
其中, θ n e w θ^{new} θnew表示新的权重, θ θ θ表示旧的(初始/上一次迭代)权重, η η η 是学习率(learning rate)。
图片来自“Gradient Descent Algorithm: How does it Work in Machine Learning?”
梯度下降算法有多种变种,如批量梯度下降(Batch Gradient Descent)、随机梯度下降(Stochastic Gradient Descent)和小批量梯度下降(Mini-batch Gradient Descent)等,它们在计算梯度的方式和参数更新的规则上略有不同,但核心思想相似。
二、梯度下降更新模型参数
了解了交叉熵损失函数的概念之后,我们来看看梯度下降如何利用这个损失函数来更新模型参数。
这个过程是神经网络的核心,能看懂这个过程,也就基本懂深度神经网络了。
2.1 定义模型
首先,假设模型为下式,其中,
T
r
u
e
True
True为模型的真实输出值,
ω
ω
ω和
b
b
b是模型需要更新的参数,分别为权重和偏置。
T
r
u
e
=
Σ
ω
i
⋅
x
i
+
b
(2)
True=Σω_i⋅x_i+b\tag{2}
True=Σωi⋅xi+b(2)
2.2 损失函数的定义
接下来,我们定义一个损失函数。在这个例子中,我们假设损失函数是交叉熵损失,因为这个函数简单且容易推导,但是 L O S S LOSS LOSS函数使用均方差MSE(Mean Squared Error)的形式,这可能有些混淆。不管混淆不混淆吧,我们就用该函数来描述梯度下降更新参数的过程。
损失函数的定义:
L
O
S
S
=
(
真实输出值
−
期望输出值
)
2
(3)
LOSS=(真实输出值−期望输出值)^2\tag{3}
LOSS=(真实输出值−期望输出值)2(3)
L
O
S
S
=
(
T
r
u
e
−
P
r
e
d
)
2
(4)
LOSS=(True−Pred)^2\tag{4}
LOSS=(True−Pred)2(4)
其中, T r u e True True 是真实输出, P r e d Pred Pred 是模型预期输出。
L O S S LOSS LOSS对 T r u e True True求偏导,得
∂ L O S S ∂ T r u e = 2 ( T r u e − P r e d ) (5) \frac {∂LOSS}{∂True }=2(True-Pred)\tag{5} ∂True∂LOSS=2(True−Pred)(5)
2.3 对于权重 w i w_i wi的更新
先对
w
i
w_i
wi求偏导,这里公式(6)是梯度下降方法的定式,得
w
i
n
e
w
=
w
i
−
η
∂
L
O
S
S
∂
w
i
(6)
w_i^{new}=w_i-η \frac {∂LOSS}{∂w_i }\tag{6}
winew=wi−η∂wi∂LOSS(6)
其中,
w
i
n
e
w
w_i^{new}
winew表示新的权重,
w
i
w_i
wi表示旧的(初始/上一次迭代)权重,
η
η
η 是学习率(learning rate)。
通过链式法则,
∂
L
O
S
S
∂
w
i
\frac {∂LOSS}{∂w_i }
∂wi∂LOSS可以表示为:
∂
L
O
S
S
∂
w
i
=
∂
L
O
S
S
∂
T
r
u
e
∂
T
r
u
e
∂
w
i
(7)
\frac {∂LOSS}{∂w_i }=\frac {∂LOSS}{∂True} \frac {∂True}{∂w_i }\tag{7}
∂wi∂LOSS=∂True∂LOSS∂wi∂True(7)
因为
T
r
u
e
True
True是
Σ
ω
⋅
x
i
+
b
Σω⋅x_i+b
Σω⋅xi+b计算得到的,所以:
∂
T
r
u
e
∂
w
i
=
x
i
(8)
\frac {∂True}{∂w_i }=x_i\tag{8}
∂wi∂True=xi(8)
因此,权重
w
i
w_i
wi的更新规则为:
w
i
n
e
w
=
w
i
−
η
⋅
2
(
T
r
u
e
−
P
r
e
d
)
⋅
x
i
(9)
w_i^{new}=w_i-η·2(True-Pred)·x_i\tag{9}
winew=wi−η⋅2(True−Pred)⋅xi(9)
2.4 对于偏置 b b b的更新
b n e w = b − η ∂ L O S S ∂ b (10) b^{new}=b-η \frac {∂LOSS}{∂b }\tag{10} bnew=b−η∂b∂LOSS(10)
其中,
b
n
e
w
b^{new}
bnew表示新的偏置,
b
b
b表示旧的(初始/上一次迭代)偏置,
η
η
η 是学习率(learning rate)。
同样的,通过链式法则,
∂
L
O
S
S
∂
b
\frac {∂LOSS}{∂b }
∂b∂LOSS可以表示为:
∂
L
O
S
S
∂
b
=
∂
L
O
S
S
∂
T
r
u
e
∂
T
r
u
e
∂
b
(11)
\frac {∂LOSS}{∂b }=\frac {∂LOSS}{∂True} \frac {∂True}{∂b}\tag{11}
∂b∂LOSS=∂True∂LOSS∂b∂True(11)
因为
T
r
u
e
True
True是
Σ
ω
⋅
x
i
+
b
Σω⋅x_i+b
Σω⋅xi+b计算得到的,所以:
∂
T
r
u
e
∂
b
=
1
(12)
\frac {∂True}{∂b }=1\tag{12}
∂b∂True=1(12)
因此,偏置
b
b
b的更新规则为:
b
n
e
w
=
b
−
η
⋅
2
(
T
r
u
e
−
P
r
e
d
)
(13)
b^{new}=b-η·2(True-Pred)\tag{13}
bnew=b−η⋅2(True−Pred)(13)
三、举例推导
3.1 样本数据
下表中, X 1 X_1 X1和 X 2 X_2 X2分别为自变量,可以理解为特征变量,期望输出就是分类或者回归时用到的目标变量,可以理解为标签数据。
| ID | X 1 X_1 X1 | X 2 X_2 X2 | 期望输出 |
|---|---|---|---|
| 1 | 0.1 | 0.8 | 0.8 |
| 2 | 0.5 | 0.3 | 0.5 |
| … | … | … | … |
3.2 初始化模型
因为模型是 T r u e = Σ ω ⋅ x i + b True=Σω⋅x_i+b True=Σω⋅xi+b ,分别设置模型的初始参数: η η η为0.1, w 1 w_1 w1为0, w 2 w_2 w2为0, b b b为0。
3.3 第1次迭代
将样本1(
x
1
x_1
x1为0.1,
x
2
x_2
x2为0.8,期望输出为0.8)代入模型,经过
w
1
⋅
x
1
+
w
2
⋅
x
2
+
b
w_1⋅x_1+w_2⋅x_2+b
w1⋅x1+w2⋅x2+b,得
0
✖
0.1
+
0
✖
0.8
+
0
0✖0.1+0✖0.8+0
0✖0.1+0✖0.8+0,最终输出值为0,然而期望输出值为0.8,根据损失函数
L
O
S
S
=
(
T
r
u
e
−
P
r
e
d
)
2
LOSS=(True−Pred)^2
LOSS=(True−Pred)2,得
L
O
S
S
=
(
输出值
−
期望输出值
)
2
LOSS=(输出值-期望输出值)^2
LOSS=(输出值−期望输出值)2,即
(
0
−
0.8
)
2
(0-0.8)^2
(0−0.8)2,那么
L
O
S
S
LOSS
LOSS为
0.64
0.64
0.64。
根据公式(9),
w
1
n
e
w
=
w
1
−
η
⋅
2
(
T
r
u
e
−
P
r
e
d
)
⋅
x
1
w_1^{new}=w_1-η⋅2(True-Pred)⋅x_1
w1new=w1−η⋅2(True−Pred)⋅x1,先来更新
w
1
w_1
w1,得
0
−
0.1
✖
2
✖
(
0
−
0.8
)
✖
0.1
0-0.1✖2✖(0-0.8)✖0.1
0−0.1✖2✖(0−0.8)✖0.1,最终得到新的权重
w
1
w_1
w1为0.016。
同样的更新
w
2
w_2
w2,
w
2
n
e
w
=
w
2
−
η
⋅
2
(
T
r
u
e
−
P
r
e
d
)
⋅
x
2
w_2^{new}=w_2-η⋅2(True-Pred)⋅x_2
w2new=w2−η⋅2(True−Pred)⋅x2,得
0
−
0.1
✖
2
✖
(
0
−
0.8
)
✖
0.8
0-0.1✖2✖(0-0.8)✖0.8
0−0.1✖2✖(0−0.8)✖0.8,得到新的权重
w
2
w_2
w2为0.128。
接着根据公式(13),
b
n
e
w
=
b
−
η
⋅
2
(
T
r
u
e
−
P
r
e
d
)
b^{new}=b-η·2(True-Pred)
bnew=b−η⋅2(True−Pred),更新偏置
b
b
b,得
0
−
0.1
✖
2
✖
(
0
−
0.8
)
0-0.1✖2✖(0-0.8)
0−0.1✖2✖(0−0.8),得到新的偏置
b
b
b为0.16。
3.4 第2次迭代
经过3.3节第1次迭代更新的参数,现在新的参数为: η η η为0.1, w 1 w_1 w1为0.016, w 2 w_2 w2为0.128, b b b为0.16。
接着基于这一组新的参数继续训练模型。
将样本2(
x
1
x_1
x1为0.5,
x
2
x_2
x2为0.3,期望输出为0.5)代入3.3节更新的模型中,经过
w
1
⋅
x
1
+
w
2
⋅
x
2
+
b
w_1⋅x_1+w_2⋅x_2+b
w1⋅x1+w2⋅x2+b,得
0.016
✖
0.5
+
0.128
✖
0.3
+
0.16
0.016✖0.5+0.128✖0.3+0.16
0.016✖0.5+0.128✖0.3+0.16,最终输出值为0.2064,然而期望输出值为0.5,根据损失函数
L
O
S
S
=
(
T
r
u
e
−
P
r
e
d
)
2
LOSS=(True−Pred)^2
LOSS=(True−Pred)2,得
L
O
S
S
=
(
输出值
−
期望输出值
)
2
LOSS=(输出值-期望输出值)^2
LOSS=(输出值−期望输出值)2,即
(
0.2065
−
0.5
)
2
(0.2065-0.5)^2
(0.2065−0.5)2,那么
L
O
S
S
LOSS
LOSS为
0.0862
0.0862
0.0862。
根据公式(9),
w
1
n
e
w
=
w
1
−
η
⋅
2
(
T
r
u
e
−
P
r
e
d
)
⋅
x
1
w_1^{new}=w_1-η⋅2(True-Pred)⋅x_1
w1new=w1−η⋅2(True−Pred)⋅x1,先来更新
w
1
w_1
w1,得
0.1
−
0.1
✖
2
✖
(
0.2064
−
0.5
)
✖
0.1
0.1-0.1✖2✖(0.2064-0.5)✖0.1
0.1−0.1✖2✖(0.2064−0.5)✖0.1,最终得到新的权重
w
1
w_1
w1为0.04536。
同样的更新
w
2
w_2
w2,
w
2
n
e
w
=
w
2
−
η
⋅
2
(
T
r
u
e
−
P
r
e
d
)
⋅
x
2
w_2^{new}=w_2-η⋅2(True-Pred)⋅x_2
w2new=w2−η⋅2(True−Pred)⋅x2,得
0.128
−
0.1
✖
2
✖
(
0.2064
−
0.5
)
✖
0.3
0.128-0.1✖2✖(0.2064-0.5)✖0.3
0.128−0.1✖2✖(0.2064−0.5)✖0.3,得到新的权重
w
2
w_2
w2为0.14562。
接着根据公式(13),
b
n
e
w
=
b
−
η
⋅
2
(
T
r
u
e
−
P
r
e
d
)
b^{new}=b-η·2(True-Pred)
bnew=b−η⋅2(True−Pred),更新偏置
b
b
b,得
0.16
−
0.1
✖
2
✖
(
0.2064
−
0.5
)
0.16-0.1✖2✖(0.2064-0.5)
0.16−0.1✖2✖(0.2064−0.5),得到新的偏置
b
b
b为0.21872。
3.5 第n次迭代
和前面的方式一样,用户设置迭代次数n,迭代n次结束以后就可以得到一组模型参数,作为本次训练的最终模型。以后只要有新的 X 1 X_1 X1, X 2 X_2 X2输入,就会计算一个 输出 Y 输出Y 输出Y,这个过程就是模型应用(推理)。当然,并不是说迭代的次数越多,模型精度就越高,有可能会过拟合。
四、其他
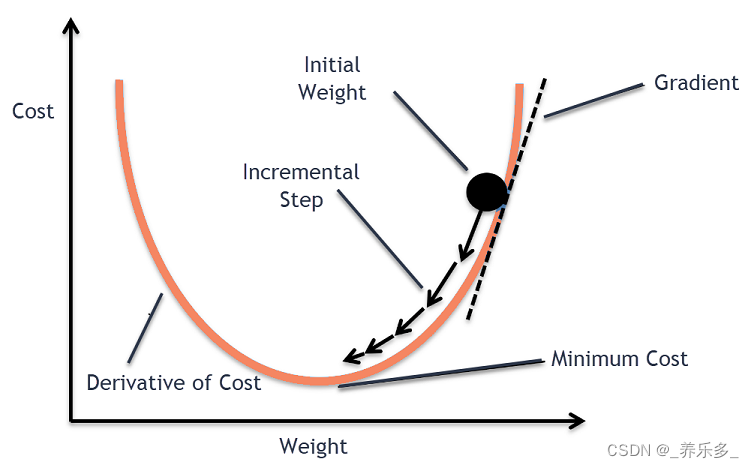
模型精度也和学习率有关,学习率影响着模型在训练过程中收敛速度以及最终的收敛状态。
下图来自https://www.kdnuggets.com/2020/05/5-concepts-gradient-descent-cost-function.html。
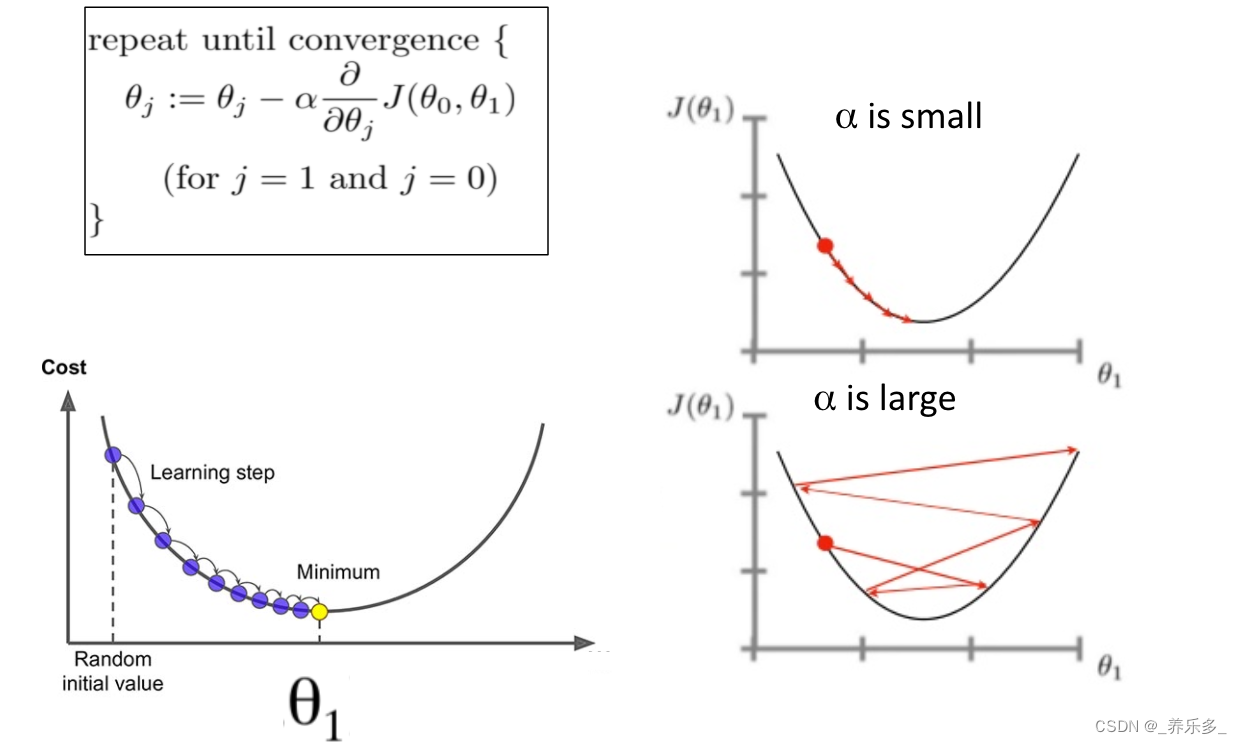
如上图右下图示所示,学习率过大可能导致参数在优化过程中发生震荡,甚至无法收敛;而学习率过小(上图右上图示)则可能导致收敛速度过慢,耗费大量的时间和计算资源。因此,需要在学习率和模型精度之间取一定的平衡。


![[flask]异常抛出和捕获异常](https://img-blog.csdnimg.cn/direct/b52f1ea9c6344737bec4786a080362be.png)