文章目录
- 🚀🚀🚀前言
- 一、1️⃣ 修改loss.py文件
- 1.1 🎓 修改1
- 1.2 ✨ 修改2
- 1.3 ⭐️相关代码的解释
- 二、2️⃣NWD实验
- 2.1 🎓 实验一:基准模型
- 2.2 ✨实验二:NWD权重设置0.5
- 2.3 ⭐️实验三:NWD权重设置1.0
- 2.4 🎯实验总结

👀🎉📜系列文章目录
【论文精读】NWD:一种用于微小目标检测的归一化高斯Wasserstein距离(A Normalized Gaussian Wasserstein Distance for Tiny Object ) !!!必读
【YOLOv5改进系列(1)】高效涨点----使用EIoU、Alpha-IoU、SIoU、Focal-EIOU替换CIou
【YOLOv5改进系列(2)】高效涨点----Wise-IoU详细解读及使用Wise-IoU(WIOU)替换CIOU
【YOLOv5改进系列(3)】高效涨点----Optimal Transport Assignment:OTA最优传输方法
【YOLOv5改进系列(4)】高效涨点----添加可变形卷积DCNv2
🚀🚀🚀前言
🚀检测微小物体是一个非常具有挑战性的问题,因为微小物体仅包含几个像素大小。由于缺乏外观信息,最先进的探测器在微小物体上无法产生令人满意的结果。在此之前也有不少研究者发现了IOU度量对于微小物体的偏差非常敏感,也提出了不少改进,像DIOU、GIOU、CIOU、等等,但是都是基于位置去判断两个框的距离和相似度,依旧无法解决小物体的位置敏感问题。为此武汉大学的一些研究人员将边界框建模为 2D 高斯分布,然后提出一种称为归一化 Wasserstein 距离(NWD)的新度量,以通过相应的高斯分布计算它们之间的相似性。
在原论文中作者将NWD方法替换掉Faster r-cnn中的标签分配、NMS极大值抑制、Iou损失,本篇文章介绍了如何将yolov5中的IOU损失替换成NWD的计算方法。本次使用的数据集是热轧钢带的六种典型表面缺陷数据集,只有小部分疵点是小目标,在相较于基准模型来说,map@0.5从0.78提升到了0.814。
一、1️⃣ 修改loss.py文件
1.1 🎓 修改1
📌首先找到utils文件夹下的loss.py文件,在该文件中找到ComputeLoss类函数,大概是在第90行左右。

📌在ComputeLoss类函数上面添加如下代码,该代码是用来计算归一化 Wasserstein 距离的:
def wasserstein_loss(pred, target, eps=1e-7, constant=12.8):
r"""`Implementation of paper `Enhancing Geometric Factors into
Model Learning and Inference for Object Detection and Instance
Segmentation <https://arxiv.org/abs/2005.03572>`_.
Code is modified from https://github.com/Zzh-tju/CIoU.
Args:
pred (Tensor): Predicted bboxes of format (x_center, y_center, w, h),
shape (n, 4).
target (Tensor): Corresponding gt bboxes, shape (n, 4).
eps (float): Eps to avoid log(0).
Return:
Tensor: Loss tensor.
"""
center1 = pred[:, :2]
center2 = target[:, :2]
whs = center1[:, :2] - center2[:, :2]
center_distance = whs[:, 0] * whs[:, 0] + whs[:, 1] * whs[:, 1] + eps #
w1 = pred[:, 2] + eps
h1 = pred[:, 3] + eps
w2 = target[:, 2] + eps
h2 = target[:, 3] + eps
wh_distance = ((w1 - w2) ** 2 + (h1 - h2) ** 2) / 4
wasserstein_2 = center_distance + wh_distance
return torch.exp(-torch.sqrt(wasserstein_2) / constant)
1.2 ✨ 修改2
还是utils文件夹下的loss.py文件,在ComputeLoss类函数找到__call__函数,在__call__函数里面找到下面两行代码,后面添加的代码需要将这两行替换掉,当然你也可以将这两行注释掉。

📌需要替换的代码如下:
nwd = wasserstein_loss(pbox, tbox[i]).squeeze()
iou_ratio = 0.5
lbox += (1 - iou_ratio) * (1.0 - nwd).mean() + iou_ratio * (1.0 - iou).mean() # iou loss
# Objectness
iou = (iou.detach() * iou_ratio + nwd.detach() * (1 - iou_ratio)).clamp(0, 1).type(tobj.dtype)
📌替换之后的代码显示如下,这个步骤执行完,所有的修改就已经完毕了,可以训练数据集了:

1.3 ⭐️相关代码的解释
🔥这里的话其实iou和nwd方法都有使用,但是使用了一个iou_ratio 来设置两者损失所占的权重,iou_ratio被设置为0.5,意味着两种损失的权重相等。如果 iou_ratio 被设置为0,那么在计算最终损失时,只会考虑到“nwd”损失,而不会考虑到“IoU”损失。
🔥同时还需要设置clamp值域的一个限定,因为我们的Iou取值(DIOU)可能是-1~1,但是后面obji = self.BCEobj(pi[..., 4], tobj)方法需要用到IOU的值,但是BCE得方法取值只能是0 ~ 1 的。所以我们需要设置clamp(0,1)将Iou的值域限制在0 ~ 1之间。

二、2️⃣NWD实验
2.1 🎓 实验一:基准模型
⚡️在没有修改任何网络的yolov5训练结果:F1置信度分数为0.71、map@0.5=0.78;

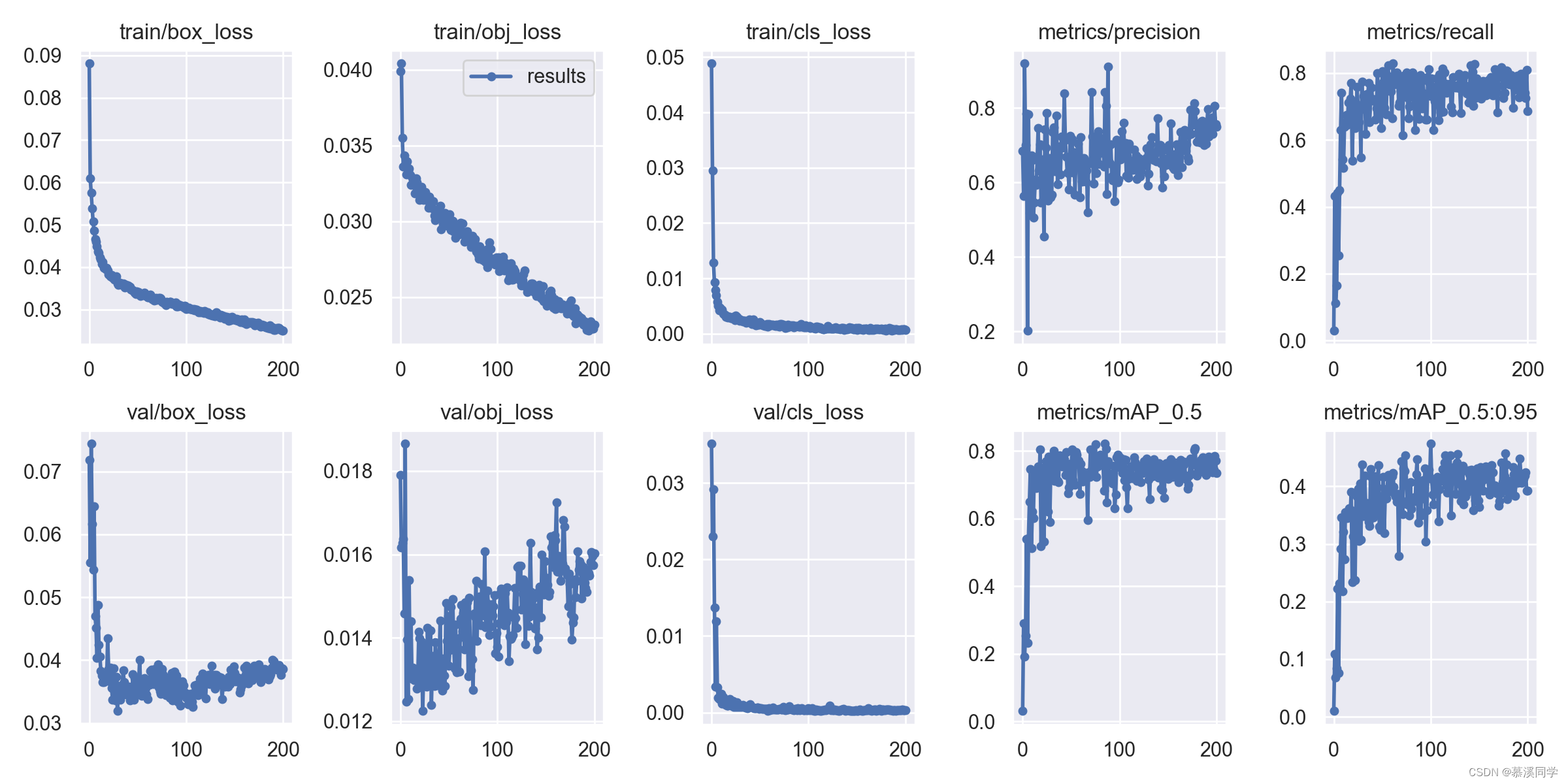
2.2 ✨实验二:NWD权重设置0.5
☀️将iou_ratio权重设置0.5,此时IOU损失和NWD损失各占一半,实验结果:F1置信度分数为0.77、map@0.5=0.814;详细训练结果图如下:


2.3 ⭐️实验三:NWD权重设置1.0
☀️将iou_ratio权重设置0.0,此时只考虑到nwd损失,而不考虑到IoU损失,实验结果:F1置信度分数为0.72,map@0.5=0.751;详细训练结果图如下:


2.4 🎯实验总结
🚀该数据集中的crazing类普遍是大目标,通过实验1和实验3进行对比crazing的map@0.5下降比较严重,但是实验2的crazing大目标的map@0.5有所增加。所以,对于某一个数据集,如果同时有大目标和小目标,建议IOU损失和NWD同时使用,如果只使用NWD进行检测,对于某些大目标的的检测效果反而不如使用IOU。