文章目录
- 监控系统的分类
- 日志类(logs)
- 调用链类(tracing)
- 度量类(metrics)
- 监控系统的分层
- 监控系统典型架构
- 采集器
- Telegraf
- Exporters
- Grafana-Agent
- 时序库
- OpenTSDB
- InfluxDB
- TDEngine
- M3DB
- VictoriaMetrics
- TimescaleDB
- Prometheus
- 告警引擎
- 数据展示
监控系统的分类
针对不同场景把监控系统分为三类,分别是:
- 日志类
- 调用链类
- 度量类
日志类(logs)
通常我们在系统和业务级别上加入一些日志代码,记录一些日志信息,方便我们在发现问题的时候查找。
这些信息会与事件做相关,例如:用户登录,下订单,用户浏览某件商品,一小时以内的网关流量,用户平均响应时间等等。
这类以日志的记录和查询的解决方案比较多。比如 ELK 方案(Elasticsearch+Logstash+Kibana),使用ELK(Elasticsearch、Logstash、Kibana)+ Kafka/Redis/RabbitMQ 来搭建一个日志系统。

ELK 结合 Redis/Kafka/RabbitMQ 实现日志类监控
程序内部通过 Spring AOP 记录日志,Beats 收集日志文件,然后用 Kafka/Redis/RabbitMQ 将其发送给 Logstash,Logstash 再将日志写入 Elasticsearch。
最后,使用 Kibana 将存放在 Elasticsearch 中的日志数据显示出来,形式可以是实时数据图表。
调用链类(tracing)
对于服务较多的系统,特别是微服务系统。一次服务的调用有可能涉及到多个服务。A 调用 B,B 又要调用 C,好像一个链条一样,形成了服务调用链。
调用链就是记录一个请求经过所有服务的过程。请求从开始进入服务,经过不同的服务节点后,再返回给客户端,通过调用链参数来追踪全链路行为。从而知道请求在哪个环节出了故障,系统的瓶颈在哪儿。
这个可以了解下OpenTracing,不展开了。
业界也有比较成熟的方案,可以参考文章:
网易云音乐全链路跟踪系统实践
全链路监控Jaeger
主流微服务全链路监控系统实战
度量类(metrics)
说白了,就是描述某个被测主体在一段时间内的测量值变化(度量)。比如CPU、内存、网络情况等等。
这里一般依赖时序数据库(TimeSeriesData,TSD)。
监控系统的分层
用户请求到数据返回,经历系统中的层层关卡。

一般我们将监控系统分为五层来考虑,当然也有人分成三层,大致的意思都差不多,仅供参考:
- 客户端监控,用户行为信息,业务返回码,客户端性能,运营商,版本,操作系统等。
- 业务层监控,核心业务的监控,例如:登录,注册,下单,支付等等。
- 应用层监控,相关的技术参数,例如:URL 请求次数,Service 请求数量,SQL 执行的结果,Cache 的利用率,QPS 等等。
- 系统层监控,物理主机,虚拟主机以及操作系统的参数。例如:CPU 利用率,内存利用率,磁盘空间情况。
- 网络层监控,网络情况参数。例如:网关流量情况,丢包率,错包率,连接数等等。
监控系统典型架构

从上图来看,从左往右,监控数据的采集,采集到的数据一般是写入时序库,然后就是对时序库中的数据进行分析和可视化,分析部分最经典做法就是告警规则判断(复杂一些的做会引入统计算法和机器学习的能力做预判),也就是上图中的告警引擎,告警引擎产生告警事件之后交给告警发送模块做不同媒介的通知。可视化就比较好理解,即图上的数据展示,通过各种图表来合理地渲染各类监控数据,便于用户查看比较、日常巡检。
采集器
采集器负责采集监控数据,有两种典型部署方式,一种是跟随监控对象部署,常见做法是所有机器都部署一个采集器采集机器的 CPU、内存、硬盘、IO、网络相关的指标;另一种是远程探针式,比如选取一个中心机器做探针,同时探测很多个机器的 PING 连通性,或者连到很多 MySQL 实例上去,执行命令采集数据。
下面我们就介绍几个典型的开源采集器:
Telegraf
Telegraf 是 InfluxData 公司的产品,开源协议是 MIT,非常开放,有很多外部贡献者,主要配合 InfluxDB 使用。当然,Telegraf 也可以把监控数据推给 Prometheus、Graphite、Datadog、OpenTSDB 等很多其他存储,但和 InfluxDB 的对接是最丝滑的。
InfluxDB 支持存储字符串,而 Telegraf 采集的很多数据都是字符串类型,但如果把这类数据推给 Prometheus 生态的时序库,比如 VictoriaMetrics、M3DB、Thanos 等,它就会报错。因为这些时序库只能存储数值型时序数据。另外,Telegraf 采集的很多数据在成功和失败的时候会打上不同的标签,比如成功的时候会打上 result=success 标签,失败的时候打上 result=failed 标签。
在 InfluxDB 中这种情况是可以的,但是在 Prometheus 生态里,标签变化就表示不同的指标,这种情况我叫它标签非稳态结构,使用 Prometheus 生态的时序库与 Telegraf 对接时需要把这类标签丢弃掉。
Telegraf 是指标领域的 All-In-One 采集器,支持各种采集插件,只需要使用 Telegraf 这一个采集器,就能解决绝大部分采集需求
Exporters
Exporter 是专门用于 Prometheus 生态的组件,Prometheus 生态的采集器比较零散,每个采集目标都有对应的 Exporter 组件,比如 MySQL 有 mysqld_exporter,Redis 有 redis_exporter,交换机有 snmp_exporter,JVM 有 jmx_exporter。
这些 Exporter 的核心逻辑,就是去这些监控对象里采集数据,然后暴露为 Prometheus 协议的监控数据。比如 mysqld_exporter,就是连上 MySQL,执行一些类似于 show global status 、show global variables 、show slave status 这样的命令,拿到输出,再转换为 Prometheus 协议的数据;还有 redis_exporter,它是连上 Redis,执行一些类似于 info 的命令,拿到输出,转换为 Prometheus 协议的数据。
随着 Prometheus 的影响越来越大,很多中间件都内置支持了 Prometheus,直接通过自身的 /metrics 接口暴露监控数据,不用再单独伴生 Exporter,简化了架构。比如 Kubernetes 中的各类组件:kube-apiserver、kube-proxy、kube-scheduler 等等,比如 etcd,还有新版本的 ZooKeeper、 RabbitMQ、HAProxy,都可以直接暴露 Prometheus 协议的监控数据,无需 Exporter。
不管是 Exporter 还是直接内置支持 Prometheus 协议的各类组件,都提供 HTTP 接口(通常是 /metrics )来暴露监控数据,让监控系统来拉,这叫做 PULL 模型。而像 Telegraf 那种则是 PUSH 模型,采集了数据之后调用服务端的接口来推送数据。
Grafana-Agent
Grafana-Agent 是 Grafana 公司推出的一款 All-In-One 采集器,不但可以采集指标数据,也可以采集日志数据和链路数据。开源协议是 Apache 2.0,比较开放。
Grafana-Agent 作为后来者,是如何快速集成各类采集能力的呢?Grafana-Agent 写了个框架,方便导入各类 Exporter,把各个 Exporter 当做 Lib 使用,常见的 Node-Exporter、Kafka-Exporter、Elasticsearch-Exporter、Mysqld-Exporter 等,都已经完成了集成。这样我们就不用到处去找各类 Exporter,只使用 Grafana-Agent 这一个二进制就可以搞定众多采集能力了。
Grafana-Agent 这种集成 Exporter 的方式,完全兼容 Exporter 的指标体系,比如 Node-Exporter。如果我们的场景不方便使用 PULL 的方式来抓取数据,就可以换成 Grafana-Agent,采用 PUSH 的方式推送监控数据,完全兼容 Node-Exporter 的指标。当然,Exporter 种类繁多,Grafana-Agent 不可能全部集成,对于默认没有集成进去的 Exporter,Grafana-Agent 也支持用 PULL 的方式去抓取其他 Exporter 的数据,然后再通过 Remote Write 的方式,将采集到的数据转发给服务端。
对于日志采集,Grafana-Agent 集成了 Loki 生态的日志采集器 Promtail。对于链路数据,Grafana-Agent 集成了 OpenTelemetry Collector。相当于把可观测性三大支柱的采集能力都建全了。一个 Agent 搞定所有采集能力有个显而易见的好处,就是便于附加一些通用标签,比如某个机器的所有可观测性数据,都统一打上机器名的标签,后面就可以使用这种统一的标签做关联查询,这个关联能力是这类 All-In-One 采集器带来的最大好处。
| 采集器 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
| telegraf | 指标方面全家桶方案 | 不太适合prometgeus生态,资深高手通过配置可规避这些问题 | 与influxDB一起作为机器的统一的agent使用 |
| Exporters | 生态庞大,所有指标场景计划全部都exporters | 不同的exporter水平参差不齐kubernetes生态,或sidecar部署模式的场合 | kubernetes生态,或sidecar部署模式的场合 |
| garfana-agent | 指标、日志、链路全部支持大一统方案 | 集成的采集器不全,和监控目标之间仍然是一对一的,同时采集多个监控目标的时候,不太方便。 | kubernetes生态,或sidecar部署模式的场合 |
时序库
监控系统的架构中,最核心的就是时序库。老一些的监控系统直接复用关系型数据库,比如 Zabbix 直接使用 MySQL 存储时序数据,MySQL 擅长处理事务场景,没有针对时序场景做优化,容量上有明显的瓶颈。Open-Falcon 是用 RRDtool 攒了一个分布式存储组件 Falcon-Graph,但是 RRDTool 本身的设计就有问题,散文件很多,对硬盘的 IO 要求太高,性能较差。Falcon-Graph 是分布式的,可以通过堆机器来解决大规模的问题,但显然不是最优解。
后来,各种专门解决时序存储问题的数据库横空出世,比较有代表性的有:OpenTSDB、InfluxDB、TDEngine、M3DB、VictoriaMetrics、TimescaleDB 等。下面我们逐一介绍一下。
OpenTSDB
OpenTSDB 出现得较早,2010 年左右就有了,OpenTSDB 的指标模型有别于老一代监控系统死板的模型设计,它非常灵活,给业界带来了非常好的引导。
OpenTSDB 是基于 HBase 封装的,后来持续发展,也有了基于 Cassandra 封装的版本。你可以看一下它的架构图。由于底层存储是基于 HBase 的,一般小公司都玩不转,在国内的受众相对较少,当下再选型时序数据库时,就已经很少有人会选择 OpenTSDB 了。
InfluxDB
InfluxDB 来自 InfluxData,是一个创业公司做的项目,2019 年 D 轮融资 6000 万美金,所以开发人员不担心养家糊口的问题,做的产品还是非常不错的。
InfluxDB 针对时序存储场景专门设计了存储引擎、数据结构、存取接口,国内使用范围比较广泛,而且 InfluxDB 可以和 Grafana、Telegraf 等良好整合,生态是非常完备的。不过 InfluxDB 开源版本是单机的,没有开源集群版本。毕竟是商业公司,需要赚钱实现良性发展,这个点是需要我们斟酌的。
TDEngine
TDEngine 姑且可以看做是国产版 InfluxDB,GitHub 的 Star 数上万,针对物联网设备的场景做了优化,性能很好,也可以和 Grafana、Telegraf 整合,对于偏设备监控的场景,TDEngine 是个不错的选择。
TDEngine 的集群版是开源的,相比 InfluxDB,TDEngine 这点很有吸引力。TDEngine 不止是做时序数据存储,还内置支持了流式计算,可以让用户少部署一些组件。
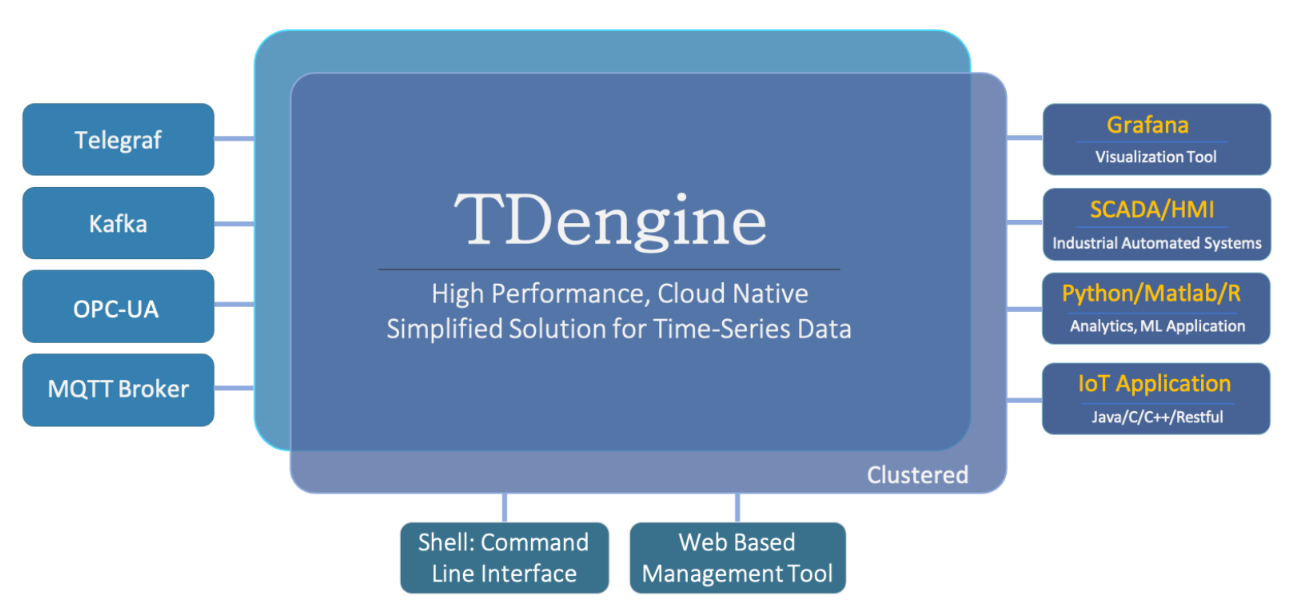
你可能比较关注 TDEngine 是否可以和 Prometheus 生态良好打通。通过 TDEngine 的官网可以得知,TDEngine 是支持 Prometheus 的 remote_read 和 remote_write 接口的。不过不支持 Prometheus 的 Query 类接口,这点需要注意。
M3DB
M3DB 是来自 Uber 的时序数据库,M3 声称在 Uber 抗住了 66 亿监控指标,这个量非常庞大。而且 M3DB 是全开源的,包括集群版,不过架构原理比较复杂,CPU 和内存占用较高,在国内没有大规模推广起来。M3DB 的架构代码中包含很多分布式系统设计的知识,是个可以拿来学习的好项目。
VictoriaMetrics
VictoriaMetrics,简称 VM,架构非常简单清晰,采用 merge read 方式,避免了数据迁移问题,搞一批云上虚拟机,挂上云硬盘,部署 VM 集群,使用单副本,是非常轻量可靠的集群方式。
VM 实现了 Prometheus 的 Query 类接口,即 /api/v1/query、/api/v1/query_range、/api/v1/label//values 相关的接口,是 Prometheus 一个非常好的 Backend,甚至可以说是 Prometheus 的一个替代品。其实 VM 的初衷就是想要替换掉 Prometheus 的。
TimescaleDB
TimescaleDB 是 timescale.inc 开发的一款时序数据库,作为一个 PostgreSQL 的扩展提供服务。
它是基于 PostgreSQL 设计而成的,而 PostgreSQL 生态四十年的积累,就是巨人的肩膀,很多底层的工作 PostgreSQL 其实已经完成了。就拿保障数据安全来说吧,因为程序可能随时会崩溃,服务器可能会遇到电源问题或硬件故障,磁盘可能损坏或者夯住,这些极端场景都需要完善的解决方案来处理。PostgreSQL 社区已经有了现成的高可用特性,包括完善的流复制和只读副本、数据库快照功能、增量备份和任意时间点恢复、wal 支持、快速导入导出工具等。而其他时序库,这些问题都要从头解决。
但是传统数据库是基于 btree 做索引的,数据量到百亿或者千亿行,btree 会大到内存都存不下,产生频繁的磁盘交换,数据库性能会显著下降。另外,时序数据的写入量特别大,PostgreSQL 面对大量的插入,性能也不理想。TimescaleDB 就要解决这些问题。目前 Zabbix 社区在尝试对接到 TimescaleDB,不过国内应用案例还比较少。
Prometheus
随着这几年云环境的发展,Prometheus 被广泛地认可。它的本质是时间序列数据库。Prometheus 能够很好地支持大量数据的写入。
它采用拉的模式(Pull)从应用中拉取数据,并通过 Alert 模块实现监控预警。据说单机可以消费百万级时间序列。
告警引擎
告警引擎的核心职责是处理告警规则,生成告警事件。通常来说,用户会配置数百甚至数千条告警规则,一些超大型公司可能需要配置数万条告警规则。每个规则里含有数据过滤条件、阈值、执行频率等,有一些配置丰富的监控系统,还支持配置规则生效时段、持续时长、留观时长等。
告警引擎通常有两种架构,一种是数据触发式,一种是周期轮询式。
数据触发式,是指服务端接收到监控数据之后,除了存储到时序库,还会转发一份数据给告警引擎,告警引擎每收到一条监控数据,就要判断是否关联了告警规则,做告警判断。因为监控数据量比较大,告警规则的量也可能比较大,所以告警引擎是会做分片部署的,即部署多个实例。这样的架构,即时性很好,但是想要做指标关联计算就很麻烦,因为不同的指标哈希后可能会落到不同的告警引擎实例。
周期轮询式,架构简单,通常是一个规则一个协程,按照用户配置的执行频率,周期性查询判断即可,因为是主动查询的,做指标关联计算就会很容易。像 Prometheus、Grafana 等,都是这样的架构。
生成事件之后,通常是交给一个单独的模块来做告警发送,这个模块负责事件聚合、收敛,根据不同的条件发送给不同的接收者和不同的通知媒介。告警事件的处理,是一个非常通用的需求,而且非常零碎、复杂,每个监控系统都去实现一套,通常不会做得很完备。于是就有了专门处理这类需求的产品,最典型的比如 PagerDuty ,可以接收各类事件源的事件,用户就只需要在 PagerDuty 做 OnCall 响应即可,非常方便。
数据展示
监控数据的可视化也是一个非常通用且重要的需求,业界做得最成功的当数 Grafana。
Grafana 采用插件式架构,可以支持不同类型的数据源,图表非常丰富,基本可以看做是开源领域的事实标准。很多公司的商业化产品中,甚至直接内嵌了 Grafana,可见它是多么流行。当然,Grafana 新版本已经修改了开源协议,使用 AGPLv3,这就意味着如果某公司的产品基于 Grafana 做了二次开发,就必须公开代码,有些厂商想要 Fork Grafana,然后进行闭源商业分发,就行不通了。
监控数据可视化,通常有两类需求,一个是即时查询,一个是监控大盘(Dashboard)。即时查询是临时起意,比如线上有个问题,需要追查监控数据,还原现场排查问题,这就需要有个方便我们查看的指标浏览功能,快速找到想要的指标。监控大盘通常用于日常巡检和问题排查,由资深工程师创建,放置了一些特别值得重点关注的指标,一定程度上可以引发我们思考,具有很强的知识沉淀效果。如果想要了解某个组件的原理,这个组件的监控大盘通常可以带给你一些启发。
补充:

参考:
https://blog.csdn.net/Tiger_lin1/article/details/130712365
https://www.sohu.com/a/344073073_236714