B+树(B+Tree):
-
结构:
- B+树是一种自平衡的多路查找树,每个节点可以拥有M个子节点(M通常是一个较大的常数,比如几百),每个节点最多含有M-1个键和M个指向子节点的指针。
- 叶子节点存储实际的数据,并且所有叶子节点通过指针串联成一个有序链表,便于范围查询。
-
特点:
- B+树的非叶子节点不存储数据,仅存储键和指向子节点的指针,这使得单个节点可以存储更多索引信息,减少了树的高度。
- 所有的查询都要经过内部节点直到叶子节点才能找到数据,但叶子节点集中存储数据并形成有序链表,有利于做全表扫描和范围查询。
-
应用场景:
- B+树主要应用于数据库索引、文件系统和其他需要处理大量数据并优化磁盘I/O操作的环境。
- 由于B+树的这种特性,它能够极大程度地减少磁盘I/O次数,特别是在大数据集下表现优异,因为它能在一次磁盘读取中检索到更多的相关数据。

MySQL 中的 InnoDB 存储引擎使用 B+Tree 作为索引结构,它非常适合磁盘存储和检索大量有序数据。在内存中,B+Tree 索引页的存储方式遵循以下原则:
-
页(Page)的基本概念:
- InnoDB 存储引擎的管理单元是页(Page),默认情况下每个页的大小通常是 16KB。
- 页是磁盘和内存之间交互的最小单位,数据在写入磁盘或从磁盘读取到内存时,都是按页为单位进行的。
-
B+Tree 结构:
- B+Tree 的每个节点都对应着一个页,节点内包含了多个键值对以及指向子节点的指针(非叶子节点)或记录指针(叶子节点)。
- 非叶子节点仅存储索引列(键值),不存储实际的数据行,这样可以容纳更多的索引键,减小单次 I/O 读取的数据量,提高查找效率。
- 叶子节点存储所有的索引键,并且叶子节点之间通过指针相互连接,形成了一个有序链表,方便范围扫描。
-
内存存储示例: 假设有一个简单的用户表,其中包含
id(主键)和username字段,并在id上建立了 B+Tree 索引。-
内存中加载了一个 B+Tree 的索引页,这个页包含了多个槽(slot),每个槽包括键值(如
id)和指针。 -
例如,假设一个页可以存储100个键值对,则可能的格式如下:
-
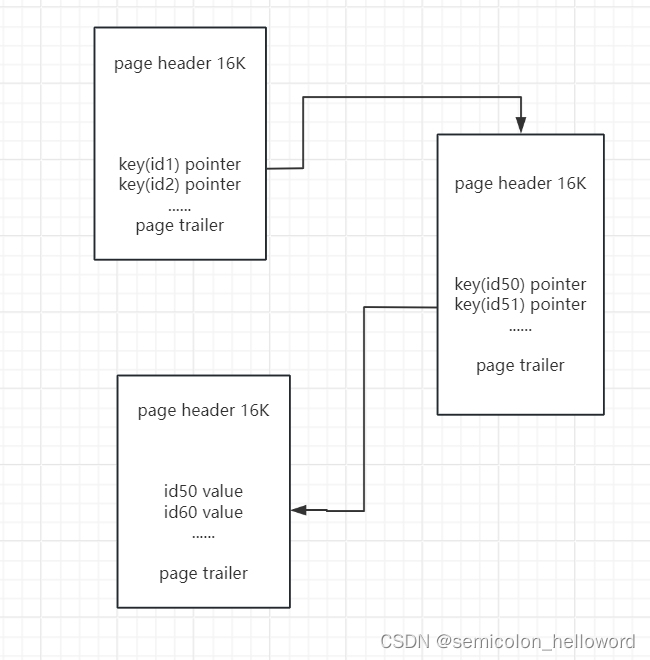
当查询 id=123 时,MySQL 会从内存缓存池(Buffer Pool)中查找对应的 B+Tree 索引页,如果不在缓存中则从磁盘读取。从根节点开始,沿着键值比较的路径向下遍历,最终到达存储该 id 的叶子节点,叶子节点中找到对应的记录指针,再通过该指针获取完整的数据行。
注意,内存中的页并不直接反映磁盘上的物理布局,而是经过了数据库系统的逻辑组织和管理,确保了即使在不同的硬件环境下,也能保持高效的读写性能。并且,MySQL 还有诸如自适应哈希索引(Adaptive Hash Index)等特性,可以在特定条件下动态地在内存中为热点索引创建哈希索引以进一步提升查询速度。