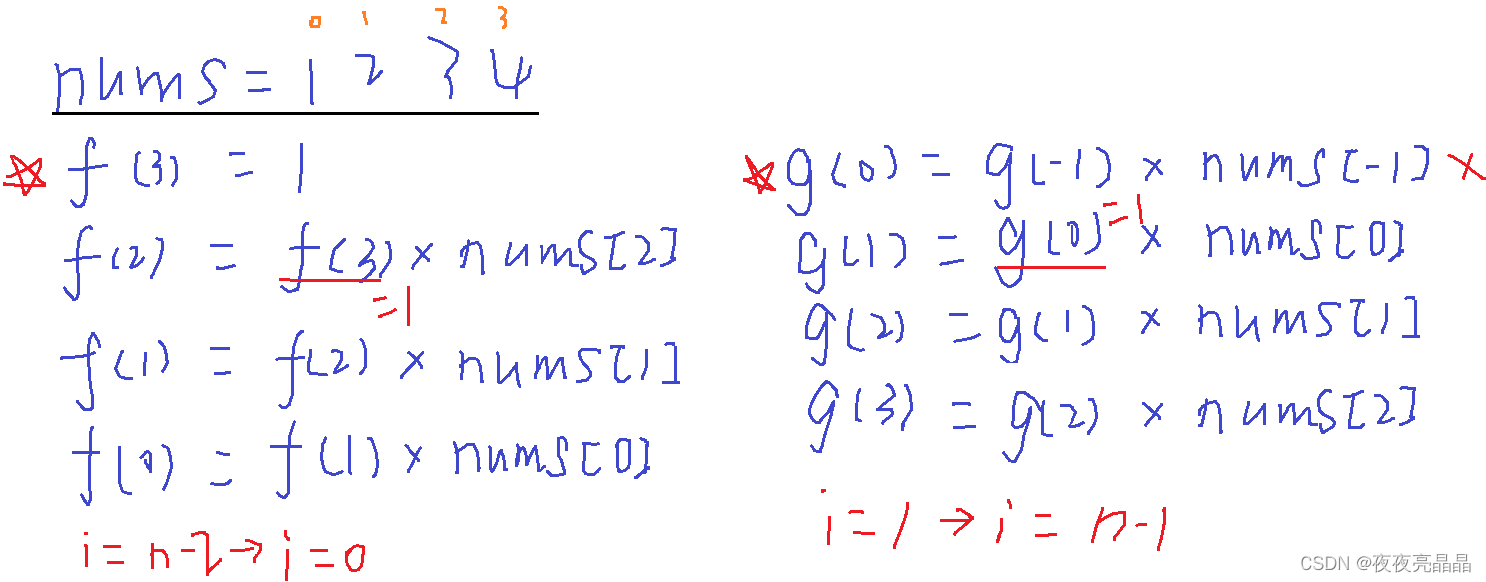参考:
Attention Is All You Need
论文解读:Attention is All you need
Transformer模型中的attention结构作用是什么?
如何最简单、通俗地理解Transformer?
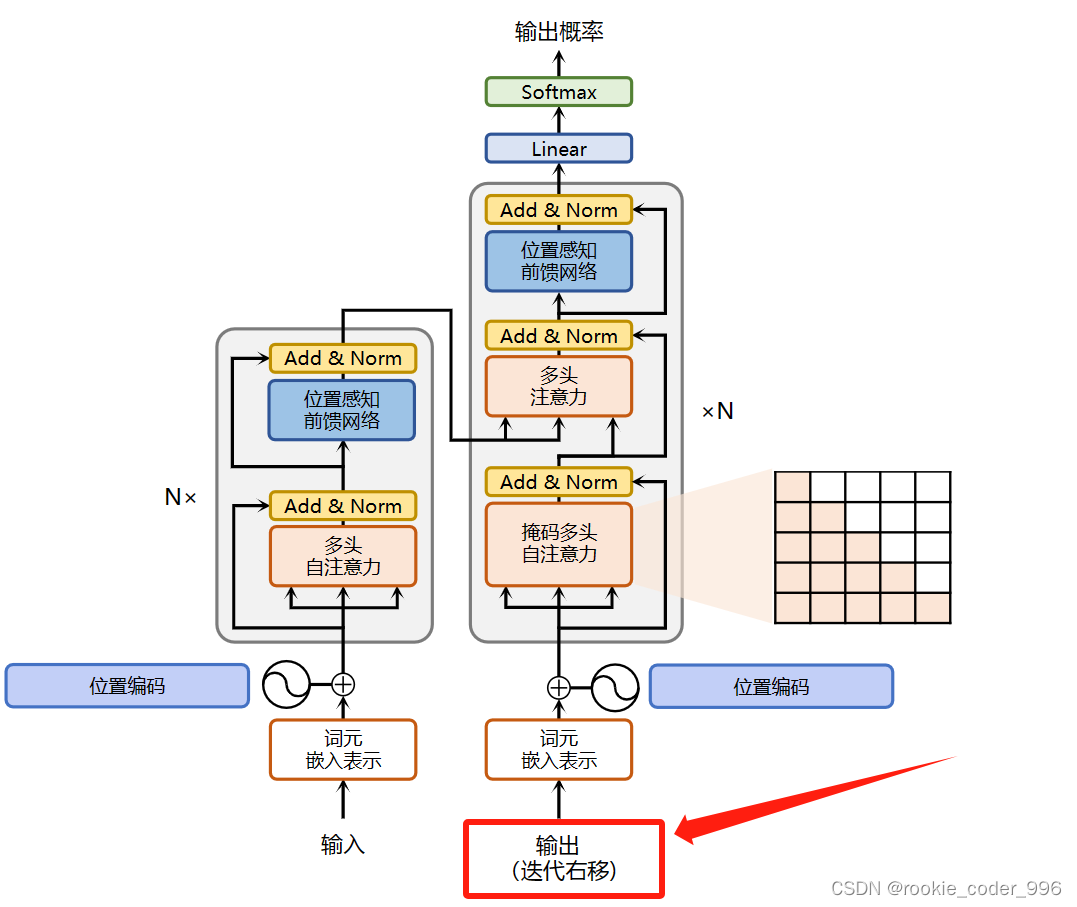
Transformer 新型神经网络,基于注意力机制 的 编码器-解码器 的序列处理模型架构;
核心是:Self - Attention 模块和 Multi-Head Attention 模块

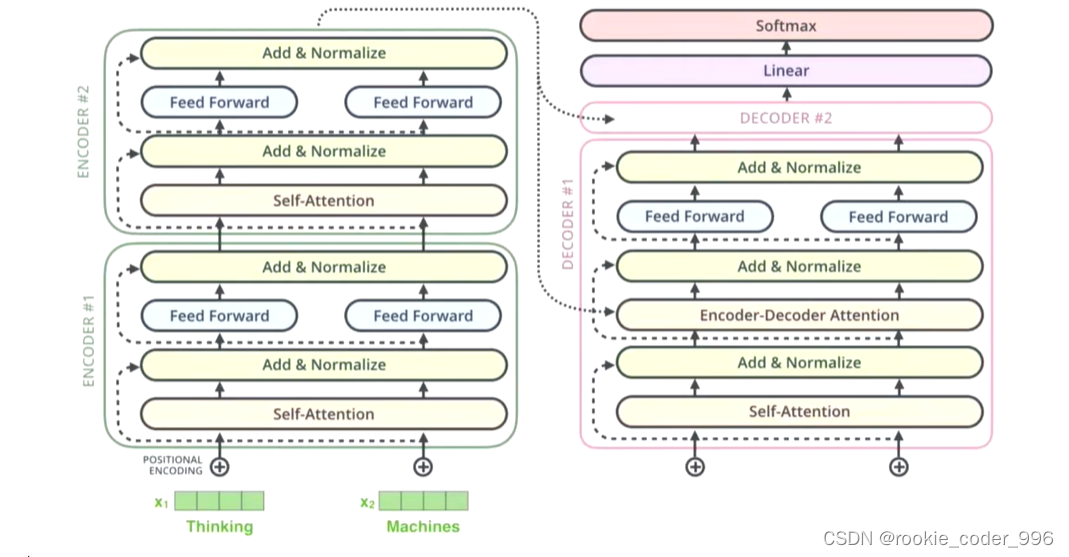
1 Encoder - Decoder 架构
一种深度模型结构,处理的是 sequence-to-sequence 任务
输入 和 输出 都是序列数据;
输入通过编码器得到词向量
词向量输入到解码器,得到翻译出来的单词
如同 变形金刚跑车形态 到 说明书,到 拼接大黄蜂人形形态的过程;
 说明书
说明书
2 RNN 的缺点
无法处理长序列(长序列依赖问题) 无法并行
- 参考窗口短 无法处理长序列
对于一个输入序列,一个句子中可能存在同义词的,例如 “ I saw a saw ”,前一个saw是动词,后一个是名词
由于同义词的存在,我们需要引入上下文机制
但是 RNN 的参考窗口短,如果输入的文本很长很长的时候,RNN 无法访问序列中较早生成的单词,获取不到之前的信息,就是说 RNN只有短时记忆
而且输入的序列长度是不一 的,扩大参考窗口的方法会导致计算量过大,还可能导致过拟合的问题。其他的记忆门机制没有深入研究
- 无法并行
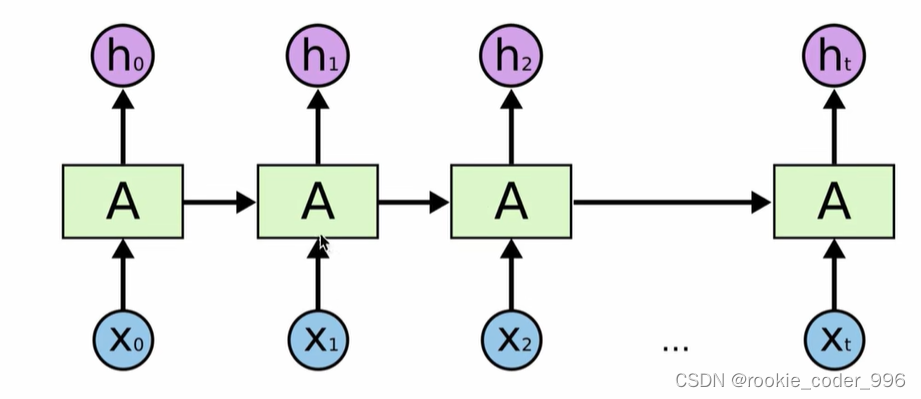
RNN是 顺序处理 的,每个时间步的计算必须等待前一个时间步的计算完成。
每一个时刻的隐藏状态 St ,不仅取决于本次的输入 Xt,还取决于上一个隐藏状态 St-1
也就是说,当前时间步的隐藏状态 St ,是由当前输入 Xt 和上一个时间步的隐藏状态 St-1 组合而成的
这导致了并行性受限,无法充分利用现代硬件的并行计算能力。这在训练大规模模型时可能会导致效率问题。
3 Attention 机制
一种模仿人类认知系统的方法,人类的视觉系统就是一种 Attention 机制。
通俗的理解 Attention 就是 权重
区分出来哪些东西是关键的信息,哪些是不那么重要的信息

那么如何去衡量权重呢?
使用相似度去衡量权重,
相似度越大权重越高,相似度越低权重越小;
相似度使用点积运算 q * k 实现的,这是计算相似度的方法之一,还有其他方法
(后续q k v 介绍)
为什么不使用 attention + RNN ?
使用两个 RNN 网络组合,形成一个 Encoder - Decoder 架构 模型

α 是权重;后续通过神经网络训练,可以得到最好的 attention 权重矩阵
引入多个 c 可以使得模型,在不同的时间都可以看到全局的信息,就可以实现在不同的上下文环境下,专注于不同的信息。
从上图我们可以看出,RNN 的顺序结构依然存在,也就是说,大模型训练的时候无法并行的问题依旧存在;
但是这个顺序结构根本不需要啊,因为我们使用的是attention,知道了各自的权重
因此 引出自注意力机制 不使用顺序结构
4 Self - Attetion 自注意力机制

自注意力模型可以实现 将输入中的每一个单词和输入中的其他单词联系起来

如何理解 self ?
q ≈ k ≈ v 是同源的
从同一个地方变换而来的,中间存在着某些关系,是有联系的
所以叫 self
如何理解 q k v ?
q k v 这个概念来自检索系统
比如搜索的时候,我们的查询词 q 被搜索引擎映射到一组键 k,
然后键 K 和数据库当中的值 v 去进行关联和匹配,
q 是查询
k v 是类似于键值对
q k v 怎么来的?
x1 乘以不同的的矩阵得到的

单词送入不同的全连接层
生成 q k v

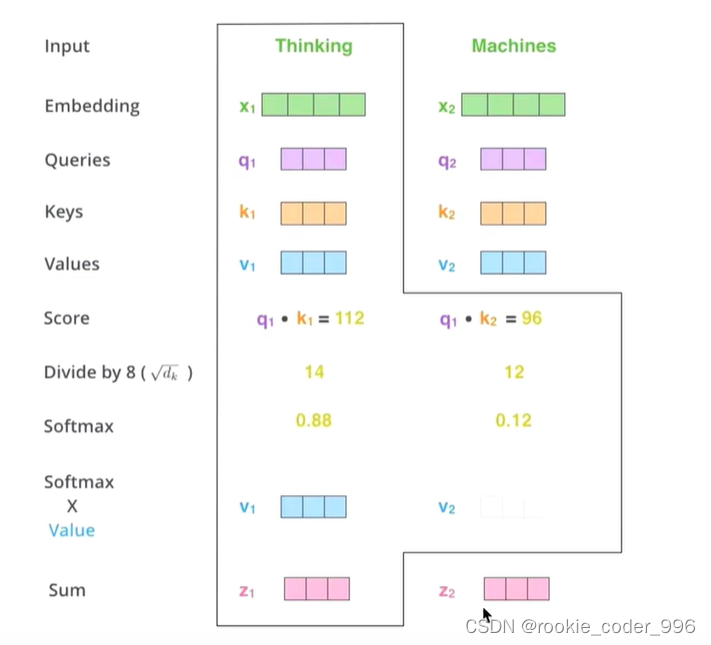
Self - Attetion 的 计算过程
q k 通过 点积矩阵乘法产生一个分数矩阵(相似度) 得到相似度
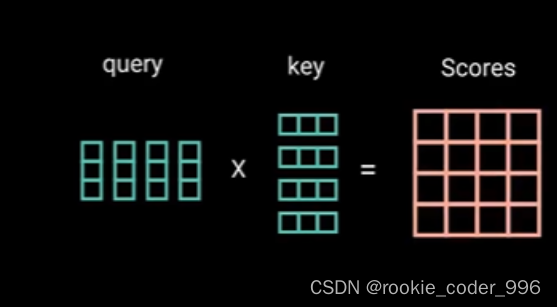

分数矩阵(相似度) 确定了一个单词应该如何关注其他单词(哪些自己应该重点关注!)

因此,每个单词都会有一个与其他单词相对应的分数,分数越高,相似度越高,权重越高
随后进行 缩放 Scale ,除以一个


然后 Softmax 得到注意力权重,从而获得0到1之间的概率值。
得到相似度
相似度乘以 v 得到注意力值
为什么要进行 缩放点积注意力模型? 也就是为什么除以
因为 q k 乘之后值很大,可能会导致梯度爆炸问题
Softmax 会将几乎全部的概率分布分配给最大值对应的标签,后续会出现梯度下降甚至消失的问题
为了缓解这个问题,我们需要除以一个特征维度,也就是
对缩放后的得分进行softmax计算,
进行softmax计算后,较高的得分会得到增强,而较低的得分会被抑制
接着,将注意力权重与 v 相乘,得到输出向量。
较高的 softma x得分会保留模型认为更重要的词的值。
分高 好 保留
分低 不关注
然后注意力得分和 v 相乘,得到输出向量

Self - Attetion 是如何解决长序列依赖问题的?
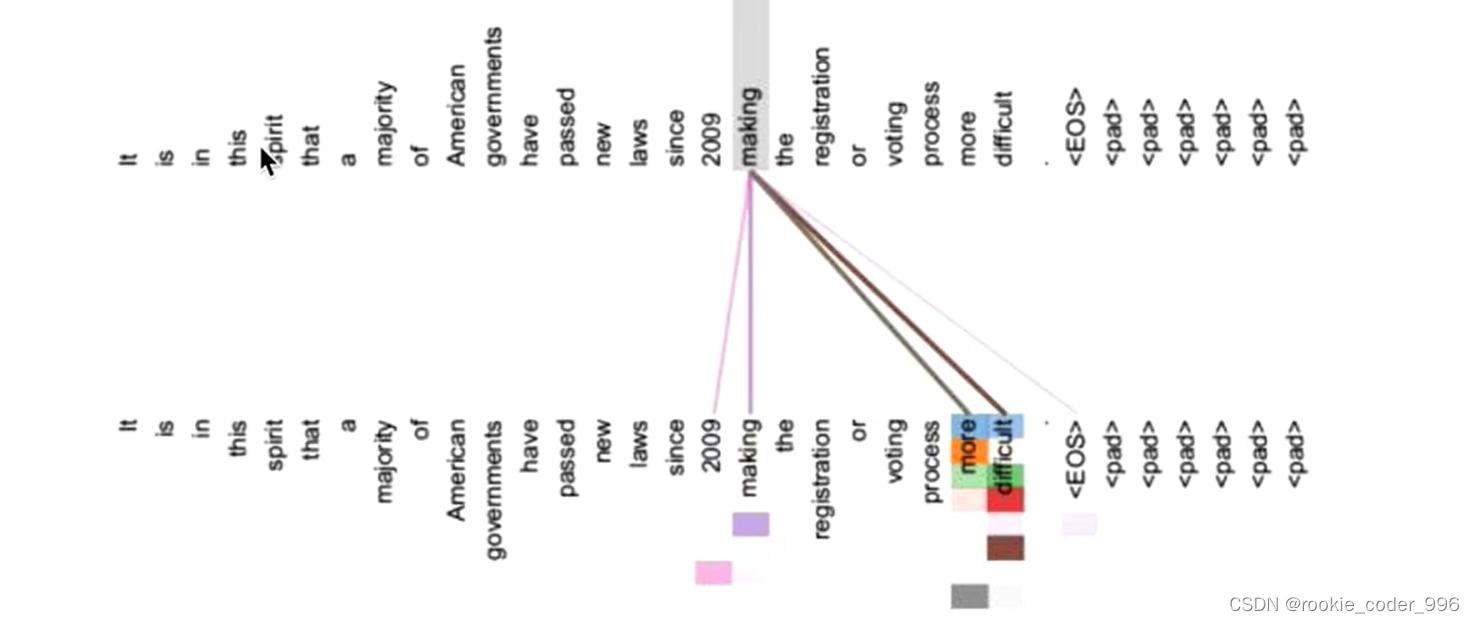
自注意力机制通过在每个位置上分配不同的权重来考虑序列中的全局信息
更容易捕获句子中长距离的相互依赖的特征
在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来
因此,模型可以同时关注所有其他位置的内容,而不仅仅是前面或后面的位置。
RNN的长序列依赖问题得到解决。
Self - Attention怎么做到并行计算的?
Self-Attention 对于一句话中的每个单词都可以单独的进行 Attention 值的计算
从图中也可以看出,每个单词都可以单独的进行计算
Self-Attention得到的新的词向量具有句法特征和语义特征
因为 模型在处理输入序列时同时考虑到全局信息、不同权重分配,
无论句子序列多长,都可以充分捕获近距离上往下问中的任何依赖关系,进而可以很好的提取句法特征还可以提取语义特征
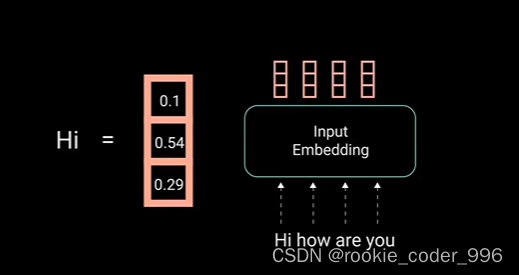
5 输入和位置编码
input embedding
获取每个单词的学习向量表示,
每个单词映射到一个连续的向量,以表示该单词
positional encoding 位置信息
位置信息注入到嵌入中

基本原理:使用正弦函数和余弦函数,使用这样的函数是因为具有线性特性,模型可以很容易学会
分奇数时间步和偶数时间步,为网络提供了每个向量的位置信息

为什么需要位置编码?
首先,位置信息是全局的有关信息,是重要的信息
对于一句话 例如 “我喜欢可乐”
RNN 是一个字一个字去处理的,由于顺序性,单词和单词的 位置信息是自然隐含其中的
但是Transformer 不一样,没有顺序性,Transformer 是一起处理的,一起处理速度会很快,但是失去了原来输入的序列信息、先后关系
自我理解():
如果没有顺序关系,那我们输入
“ 我 喜 欢 可 乐”
“ 我 喜 欢 乐 可”
得到的结果岂不是一样的?
' 可 ' 和 '乐 ' 相关性很会高,' 可乐' 是一个品牌,但是如果 实际生活当中 ' 乐可 ' 也是一个牌子呢?
岂不是翻译错误。
这个情况当然不是我们希望出现的。因此,我们需要引入位置编码
我们引入了位置编码,知道 ' 可 ' 的位置在 '乐 ' 的前面,得到的品牌是 ' 可乐'
位置编码对于句意应该也有很重要的作用
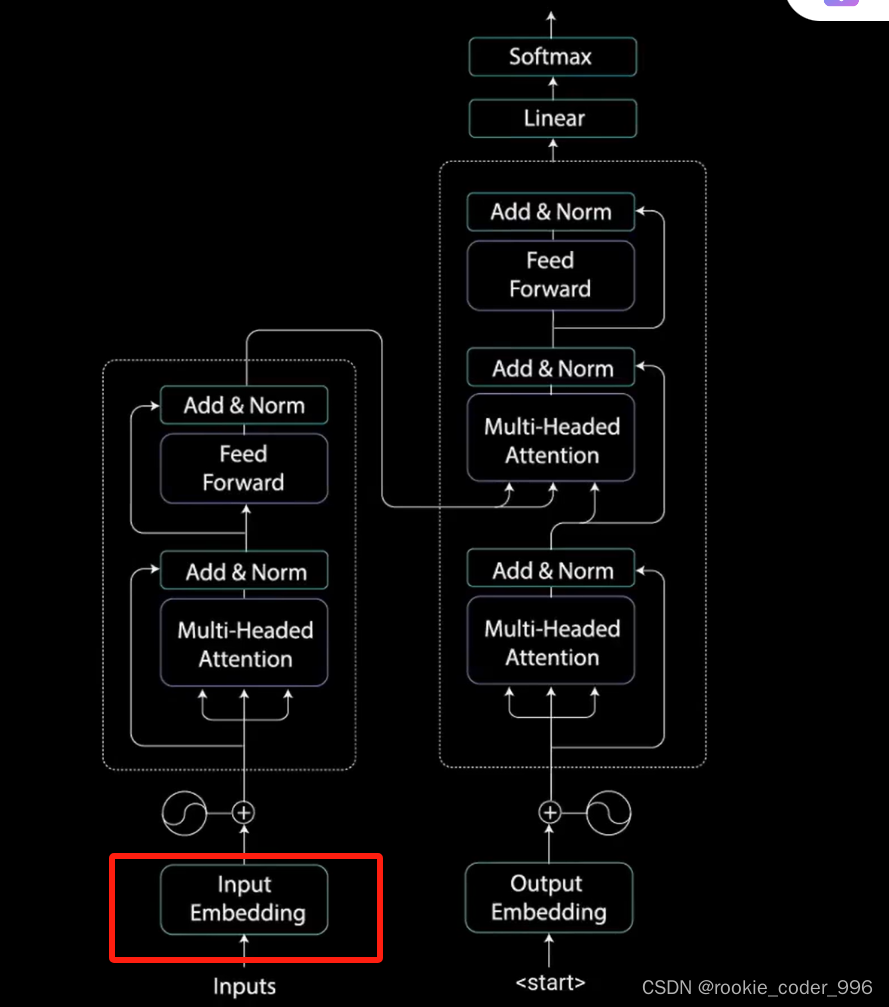
6 编码器层 encoder layer 框架
目的,输入的词向量 ------》 更好的词向量
结果就像一个变形金刚的拼接说明书,永远 各个部位之间的连接关系(相似度) 等信息
就是 车拆解成各个零部件,进行多次学习,找到各个零部件之间的关系
最后,得到一个说明书
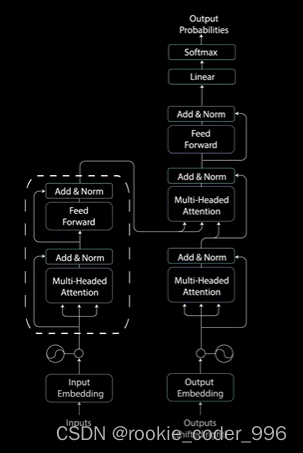
编码器层将所有的输入序列映射成一个抽象的连续表示,其中包含了整个序列的学习信息

包括一个多头注意力和一个全连接网络。
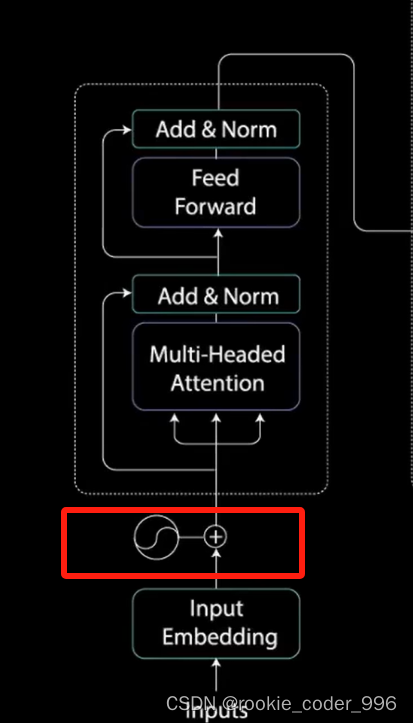
7 残差链接和归一化
每一个 注意力机制 和 前馈神经网络之间 有残差连接,后面跟着归一化

x1 是单词的词向量
x1 是加了位置信息的词向量
自注意力机制 ,那三个剪头就代表着 q k v
z1 是自注意力机制学习之后,有位置信息、语义、语法信息的词向量
Q: 残差连接的作用?
在深度神经网络中,在反向传播算法中,梯度会逐渐变小,甚至消失
导致深层网络的权重无法有效地更新,从而影响了网络的训练收敛和性能
残差连接通过允许信息在跨层传递,可以让信息传播的更深,可以避免一些梯度消失问题
残差连接就是有一个兜底,以防没有信息传播到下一层了~
为何需要归一化?
做标准化,避免数据差距太大,限制一下区间
后续 softmax 的时候不会出现相乘导致的梯度爆炸的问题
Feed Forward 作用是什么?
在此之前,所做的操作都是线性变换的叠加,
通过 Feed Forward 的 Relu 函数做 非线性变换
这对于非线性建模非常重要
ReLU函数是一个非线性的激活函数。这意味着它可以引入网络中的非线性性质,使神经网络能够更好地建模和拟合复杂的非线性关系。
这对于处理实际世界中的数据非常重要,因为很多数据都包含了非线性关系。
为何使用 n 层编码器 ?
可以将编码器堆叠n次以进一步编码信息,其中每一层都有机会学习不同的注意力表示,从而有可能提高Transformer网络的预测能力。
对于词向量进行强化,增强信息
就像照镜子,不断的美化自己
论文当中使用的是 n = 6 层,更多的层会很吃性能

8 多头注意力机制
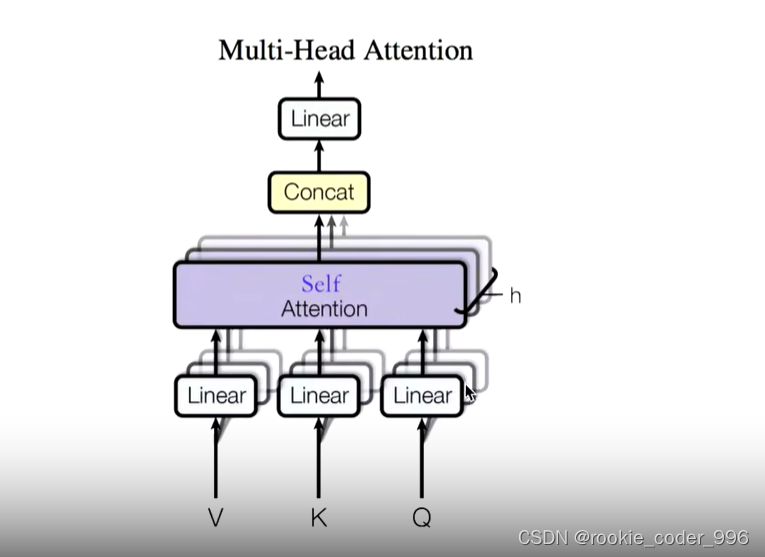
为什么使用多头?有什么好处?
多头注意力机制则引入了多个注意力头,每个头都可以关注不同的部分并进行独立的计算。每个头都会学到不同的东西,从而为编码器模型提供更多的表达能力
不同的头可以分别关注输入序列的不同部分,捕捉更多的语义信息
通过并行计算多个头,可以提高模型的表示能力和泛化能力,从而提升模型的性能。
总之,多头注意力机制是一种能够更好地捕捉输入序列中不同部分关联性的机制,它通过并行计算多个注意力头,提高了模型的表达能力和性能。
其次,使用8个不同的权重矩阵,还可以消除 q k v 初始值的影响
通俗的理解,一件事找人做,一个人的话不靠谱怎么办?
8个人做(多头),能力不同(关注不同的信息),
比如,一个人处理 距离很远的单词之间的信息,一个人处理中距离的,一个人出来很近很近的
一件事情,分成8个部分,给8个人做,对最后的结果加权平均。
怎么实现多头?

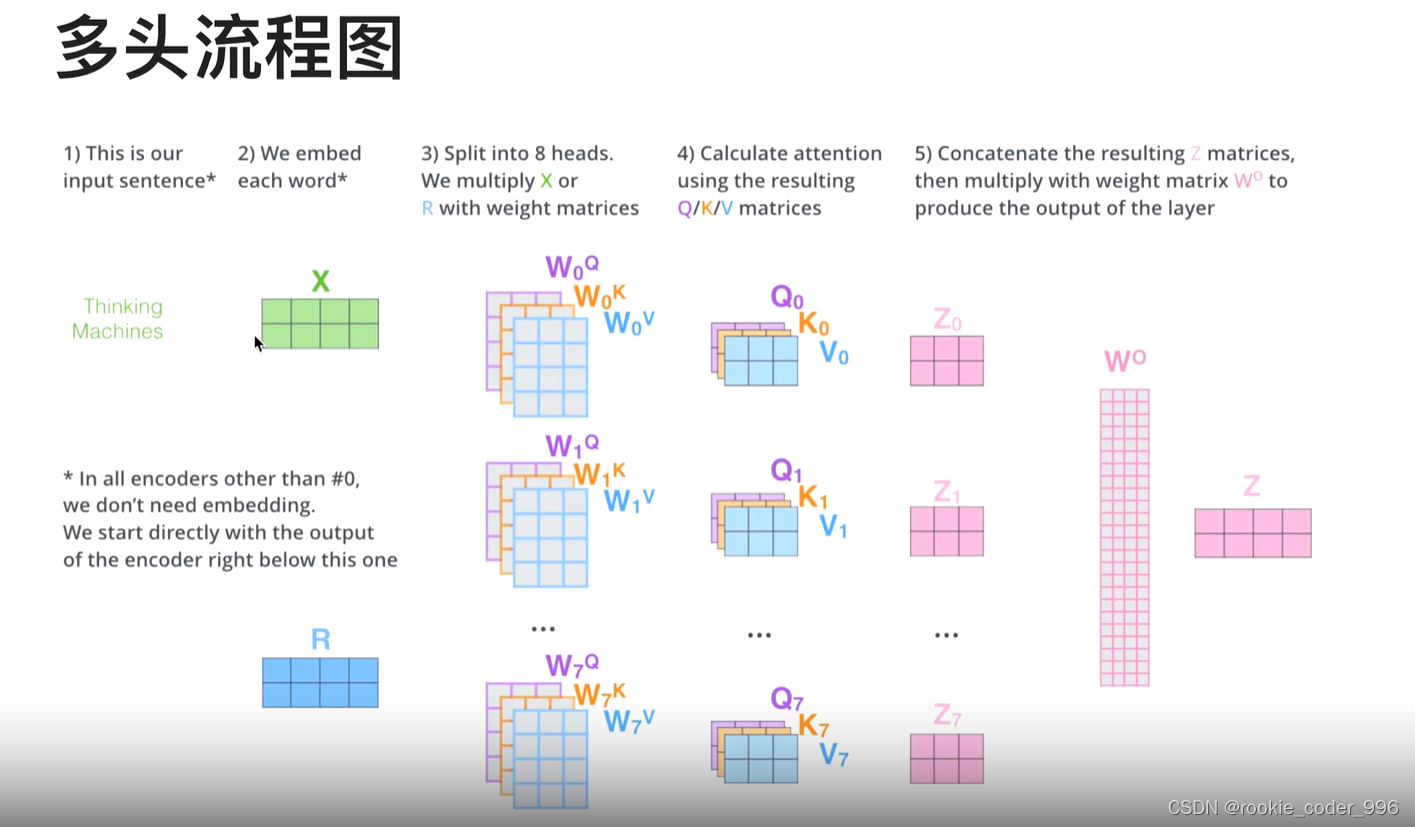

一件事情,分成8个部分,给8个人做,对最后的结果加权平均。
x 分成 8 个向量, q、 k 和 v 分成 8 个向量
然后 分别经过相同的 Self - Attetion 过程
得到的注意力向量 z0 - z7
然后 拼接 z0 -z7,整合学到的不同的信息
随后做一次线性变换,保持词向量维度的统一
9 Decoder 解码器 框架
拿着每一个部件,对比说明书 (encoder的输出结果),找到这个位置最有可能出现的部件
组装成变形金刚的过程
解码器的任务是生成文本序列,使用编码器生成的词向量,通过这个词向量去生成翻译的结果
它有两个多头注意力层、一个前馈网络层,以及在每个子层之后的残差连接和层归一化。
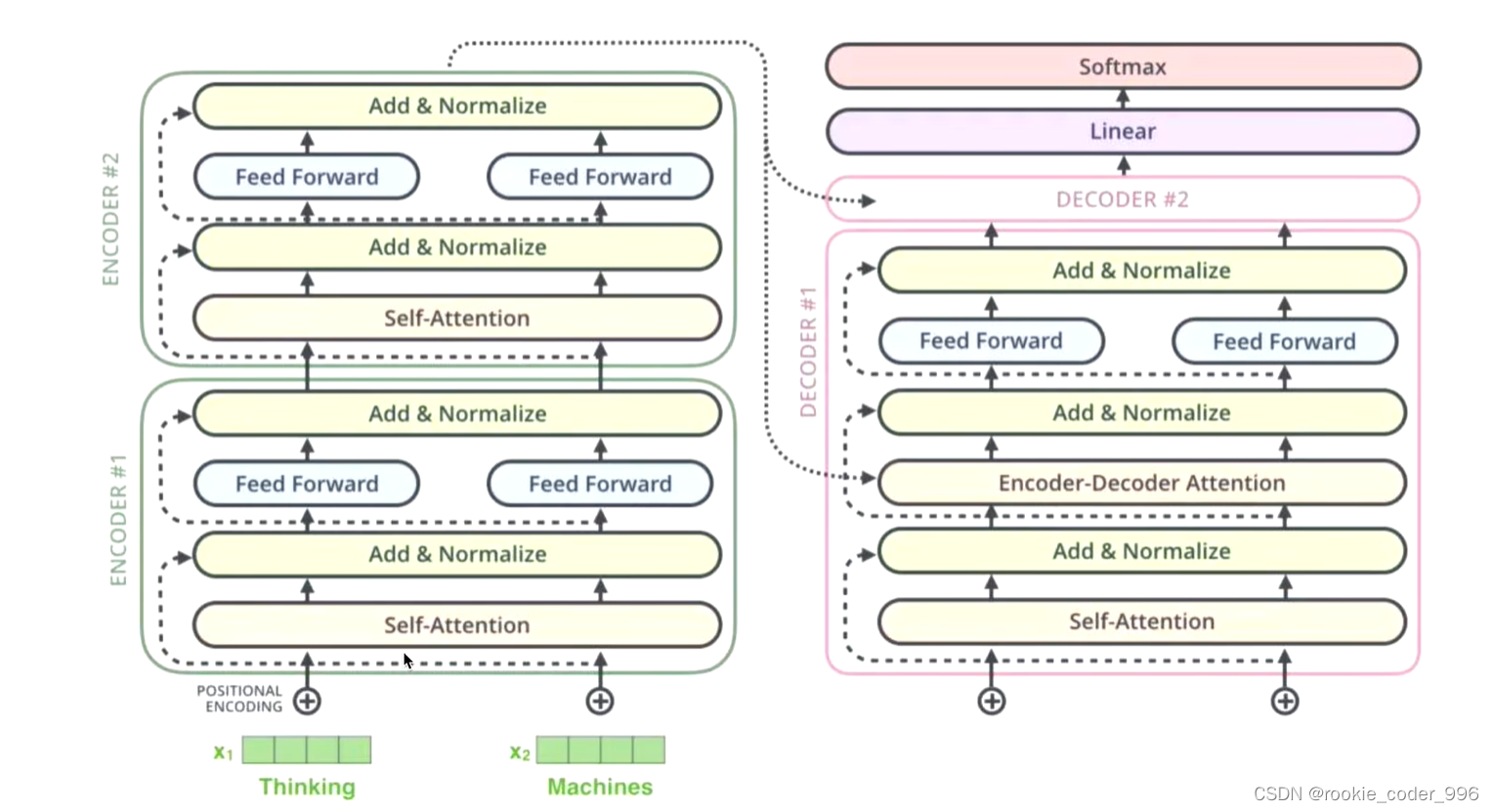
10 输入和位置编码
位置编码 和前面的类似
decoder的输入是什么?
为什么前面的 encoder 输入的 是中文,后面 decoder 输入的英文
decoder 的输入是: encoder的输出 + 前一个decoder的输出
比如 我喜欢可乐的翻译,模型的训练过程
decoder 是对于 <begin> I like cola <end> 进行训练的
刚开始 decoder输入一个 <begin> ,然后通过训练模型,模型得到一个输出 I
然后 <begin> I 作为 decoder 的输入,通过训练模型,我们期望后面的输出是 like
11 第一层 自注意力机制 MASK 掩码机制
为什么需要掩码机制?带来的好处是什么?
在编码器端,是要考虑上下文信息的,需要知道整个序列
但是!!! 在解码器decoder端 ,生成的句子是一个单词一个单词生成的
生成后续单词的时候,我们希望是模型自己训练得到的结果
如果模型能够通过已知的注意力得分,直接看到后续的单词,那么这样的训练就没有意义
而同时,这样的掩码设计带来的好处就是提高并行性
有了掩码设计,可以一次性把所有输出(应该是编码器的输出)都作为输入(作为解码器的输入),进行并行计算

mask 掩码,过滤一下,让单词看不到和自己后面单词的权重

mask是一个与注意力得分大小相同的矩阵,填充零和负无穷大 -inf 的值。

将 Mask 添加到缩放后的注意力得分后,会得到一个带有右上角三角形负无穷大值的得分矩阵
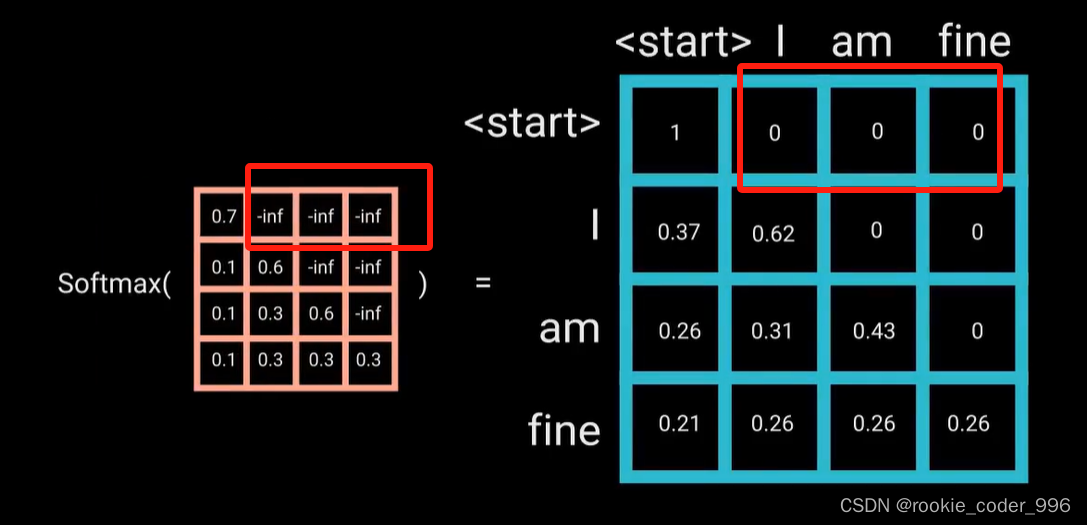
对Mask得分进行softmax计算,负无穷大值就会变为零,
后面的 attention得分就是 0

这一层仍然有多个头,
Mask在被拼接并通过线性层进行进一步处理之前被应用到每个头上
第一个多头注意力层的输出是一个带有掩码的输出向量,其中包含有关模型如何关注解码器输入的信息
位置信息 一直存在 不受 mask 的影响
位置信息是一直嵌入在向量当中的
位置编码不会受到 mask 的影响,因为它是在输入嵌入中添加的,并且与注意力机制的计算无关。
那么,mask 过滤的是权重,过滤不了位置编码
那么 位置信息怎么处理?????
不就不能掩盖后续的文本信息了?????
位置编码确实在训练期间一直存在,但它们并不包含未来的文本信息。
它们的目的是帮助模型在生成过程中正确考虑目标序列中的位置信息,以确保生成的序列是合理的。
关键在于如何生成和使用这些位置编码。
12 第二层 注意力机制

使用的是 交叉注意力方法
encoder 这里输出的是 k v
decoder 里的第一个 self-attention 输入的是 q

这个过程是将 encoder 输入与 decoder 输入进行匹配,
允许解码器决定哪个encoder 输入是相关的焦点。
Decoder 的时候,不仅要看目前产生的输出 (目前翻译出来的内容) 第一层 自注意力机制
比如 BeiJing Winter Games
Decoder的时候一个一个翻译 就是 北京 冬天 竞赛
还需要看Encoder 得到的输出 (上下文信息) 第二层 注意力机制
联系上下文就是, 北京冬奥会
翻译的时候,动态的改变翻译结果应该就得益于此
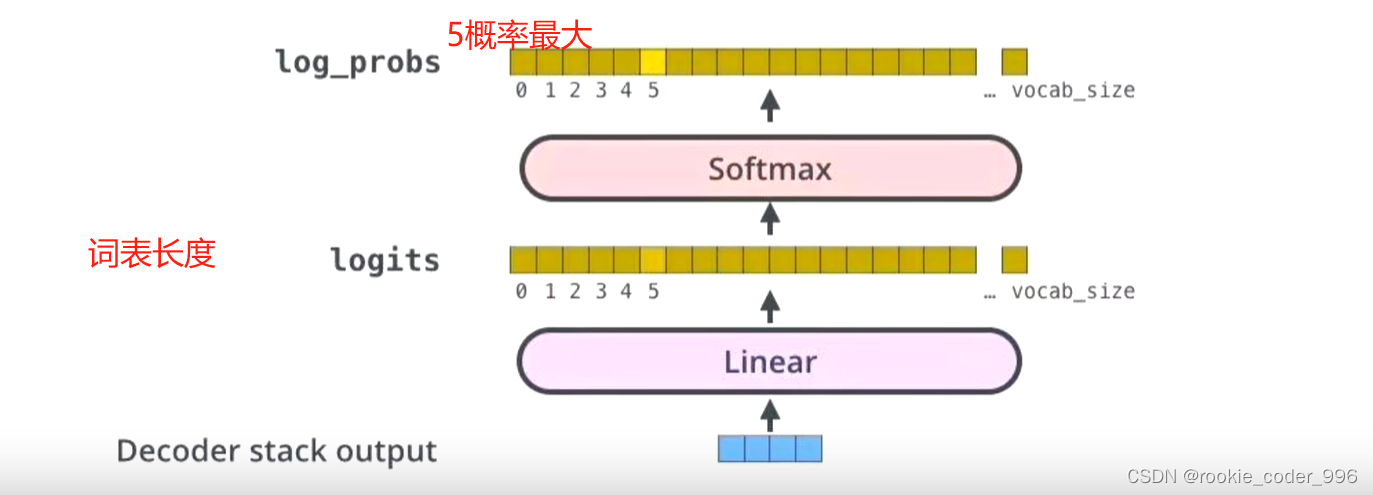
13 Linear 层
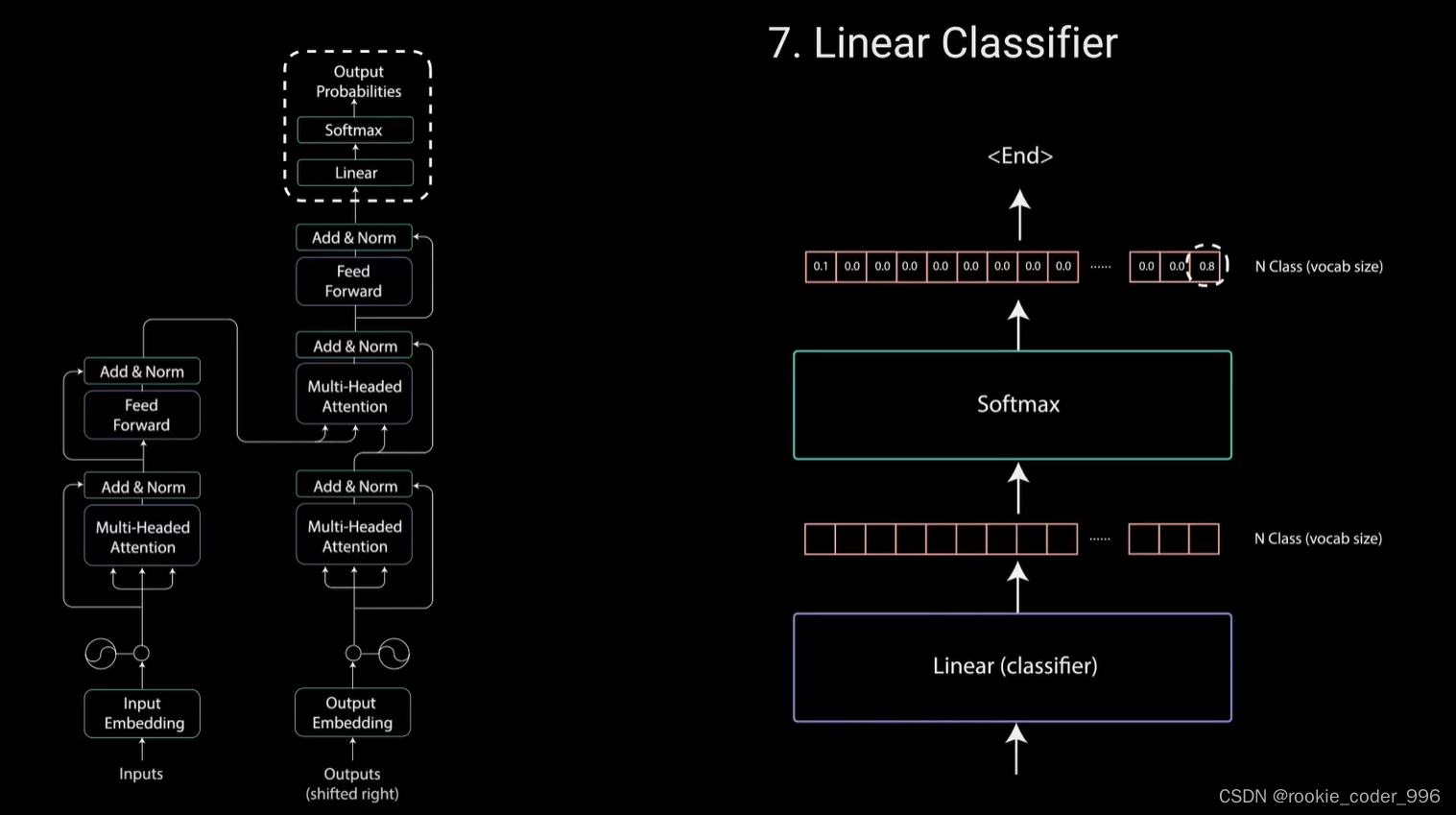
最后一个点对点前馈层的输出经过一个最后的线性层,该层充当分类器。
分类器的大小与你拥有的类别数相同
例如,如果你有10.000个类别,表示10.000个单词,那么分类器的输出大小将为10.000。分类器的输出然后被送入 softmax 层
softmax层为每个类别生成0到1之间的概率得分。我们取概率得分最高的索引,等于我们预测的单词。
然后,解码器将输出添加到解码器输入列表中,并继续解码,直到预测出结束标记。
输出的是最大的概率