目录
- Scala 01 —— Scala基础
- 一、搭建Scala开发环境
- 安装Scala编译器
- 在IDEA中进行scala编码
- 二、Scala简介与概述
- Scala简介
- Scala概述
- Scala代码规范
- 三、理解Scala变量与数据类型
- Scala的变量与常量
- Scala和Java变量的区别
- Scala的数据类型
- 四、Scala的程序逻辑
- 1.表达式
- 2.运算符
- 3.顺序控制
- 4.分支控制
- 5. 循环
- 6.迭代器
- 五、集合
- 导包
- 泛型
- 链表
- 集合
- 映射
- 数组
- 字符串插值
- 下划线:表示任意字符
- 模式匹配
- 六、方法与函数
- 七、数组方法
- 1.创建定长|变长数组
- 创建定长数组
- 创建变长数组
- 2.基本操作
- 获取长度、检查空状态
- 全部元素检查、存在性、包含行检查
- 起始/结束匹配、逆向
- 定位元素
- 数据迁移
- 添加元素
- 删除元素
- 修改和提取
- 其他算法
- 其他算法
Scala 01 —— Scala基础
Scala是Spark的基础,我们需要研究将大数据引入到Spark的特定架构。
Scala集合很重要
- 作为数据结构,解决存储问题
- 包含了大量算子、解决问题的库
由于Scala集合很多,我们在学习的时候,需要先学一个作为共性
然后在掌握差异化的部分(其实高级程序语言不是很依赖差异化的数据结构)
一、搭建Scala开发环境
安装Scala编译器
-
安装
scala-2.12.10.msi(资源位于E:\BigData\software\snd_download) -
检查scala安装情况
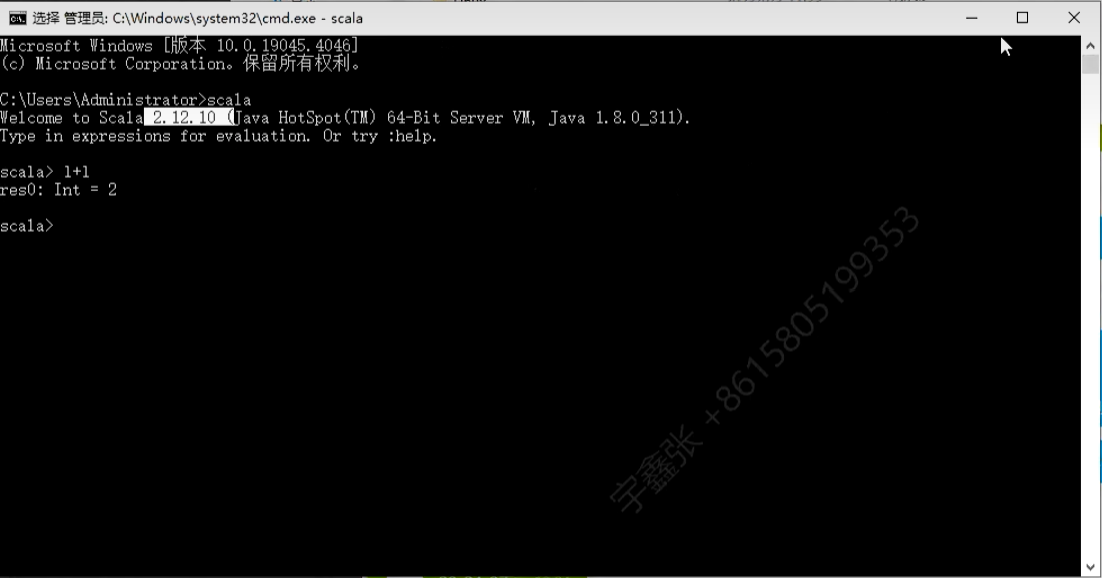
- 在dos窗口输入scala,检查是否能够进入编译器。
- 进行简单的scala命令计算
在IDEA中进行scala编码
- File - Settings - Plugins - MarketPlace中搜索scala插件

- 安装后记得重启
-
新建一个空的Maven工程,删除main包和test包,新建一个包名为Scala,将该包mark directory as source root设置成源码包,在该包下新建一个 Scala Class中的Object类
-
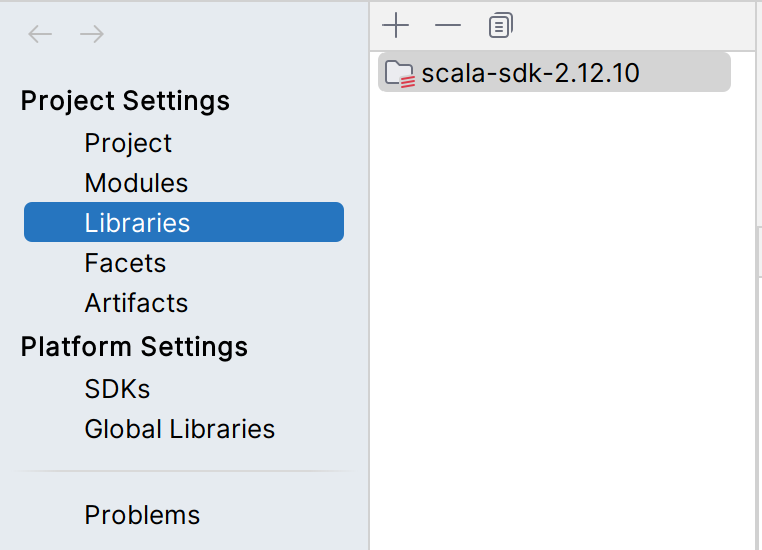
在 Project Structure中,在Libraries 和 Global Libraries中添加 Scala SDK(每新建一个工程都要重新配置一次)
-
检查基本配置
- pom.xml中的maven.compiler.source和maven.compiler.target都是8
- Project Structure中的Modules的Language Level为8-Lambdas,type annotations etc.
- Settings中的Build,Execution,Deployment中的Compiler的Java Compiler的Project bytecode version为8,Target bytecode version为1.8
- 进行代码测试
package cha01
object Test01 {
def main(args: Array[String]): Unit = {
println("hello scala")
}
}
二、Scala简介与概述
Scala简介
- Scala源自Java
- Scala构建在JVM之上
- Scala与Java兼容、互通(❗ 不要混合编码)
- Scala的优势
- 多范式编程:支持面向对象编程、面向过程编程、函数式编程等多种编程范式(函数式编程是Spark的重中之重)
- 表达能力强,代码精简
- 大数据与Scala
- Spark采用Scala语言设计
- 提供的API更加优雅
- 基于JVM的语言更融入Hadoop生态圈
- Spark采用Scala语言设计
Scala概述
-
面向对象特性
- 每个值都是对象
- 在Scala中,包括基本类型都是对象。每个值都是某个类的实例,每个操作都是方法调用。
- 对象的数据类型和行为由类(Class)和特征(Trait,类似于interface)描述
- Trait不仅具有Java中接口的功能,还引入了混入式多重继承的概念,同时可以包含方法的实现和变量定义。
- 混入式多重继承:允许在实例化时或之后,将多个Trait混入一个类中
- 动态混入:直接面向对象编写代码。允许在对象实例化时或对象使用过程中,动态地将一个或多个Trait添加到类的实例中(方便开发者根据需要在运行时为对象添加新的行为或状态)
- 混入式多重继承:允许在实例化时或之后,将多个Trait混入一个类中
- Trait不仅具有Java中接口的功能,还引入了混入式多重继承的概念,同时可以包含方法的实现和变量定义。
- 每个值都是对象
-
函数式编程
-
每个函数都是一个值
- 在Scala中,每个函数都必须返回一个值。
- 在Scala中,函数不需要写return,最后一个表达式的类型就是函数的返回类型。
-
支持高阶函数,柯里化(currying),样例类(case class)及模式匹配…
-
高阶函数:Scala中提供了大量的函数,90%的算法都无需我们自己去写,我们只需要"拼图"即可。
-
柯里化:多参数列表
-
样例类:Java类的简化版
-
模式匹配:将数据延伸、变形、转化的过程语法简化
-
-
-
Scala是静态类型语言
-
扩展性:隐式类、字符串插值
-
隐式:Scala包括隐式类、隐式变量、隐式函数(Scala中的高阶函数中包含了大量的隐式函数)
可用于将多个函数的共性逻辑声明为一个隐式函数,并将其自动传进去,可实现隐式转换
-
Scala代码规范
- 通常一行一条命令,末尾无需添加分号。
- 若一行包含多条命令,两两之间用分号隔开。(【建议】非特殊语法不允许主动用分号隔开命令)
- 可以实现过程中导包,过程中定义函数
三、理解Scala变量与数据类型
Scala的变量与常量
- 创建变量
- 创建变量必须赋初值
- 可以不指定变量的具体类型,如:var a = 12。则变量的类型由首次赋值的值类型确定且锁定。(通常不指定)
- 若声明时已指定变量类型,如:var a:String = “”,则类型不可更改。
var variableName[:Type] = V
- 创建常量
- 创建常量且初始化后,常量的类型和值都将锁定。
val valName[:Type] = V
- 类型别名
type Alias = Type
type S = String
var str:S = "henry"
Scala和Java变量的区别
- 是否指定类型:Java在声明变量的时候必须指定变量的类型,Scala在声明变量的时候可以不指定类型
- 是否必须赋初值:Java在声明变量的时候可以不赋初值,Scala在声明变量的时候必须赋初值
Scala的数据类型
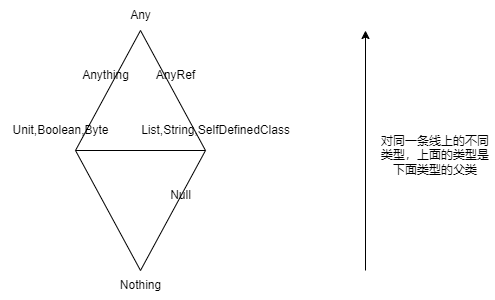
在Scala中所有的数据类型都是引用类型
- Any
- Anything(引用类型下的
基本类型,并非单独的模块)- Unit (≈void)
- Boolean
- Byte
- Short
- Int
- Long
- Float
- Double
- BigInt
- BigDecimal
- AnyRef(引用类型)
- String
- List
- SelfDefinedClass
- Anything(引用类型下的
- Null是所有引用类型的子类,Nothing是所有类的子类
-
Tuple 元组
-
定义
可以存放不同类型的元素
一旦创建,就不能修改其中的元素
元组长度范围从1~22
-
表示方法
- 使用小括号
()来表示一个元组。 - 特别注意,
()在Scala中有多重含义,可能表示:- 数组下标提取,如
array(int)。 - 方法的参数列表,如
method(p1, p2, ...)。
- 数组下标提取,如
- 使用小括号
-
声明和初始化方法
// 简单声明和初始化 val tp2 = ("java", 88) // syntatic sugar:指那些可读性强的语法 // 明确指定元组类型 val tp2: (String, Int) = ("java", 88) // 使用Tuple类显式声明 val tp2: Tuple2[String, Int] = Tuple2("java", 88) -
元组操作
- 在Scala中,通过
._n来访问元组中的元素。元组的索引是从1开始的。 - tp.productIterator()的返回值Iterator[Any]是为了方便遍历元组中的所有元素
// 获取元组中的元素 println(s"${tp2._1} ${tp2._2}") // 对元组进行迭代 val it:Iterator[Any] = tp2.productIterator tp2.productIterator.foreach(println) // 遍历输出元组中的所有元素 - 在Scala中,通过
-
四、Scala的程序逻辑
1.表达式
-
一切皆是表达式(val expr = {}):所有的构造都有值,并且可以产生结果,不需要写return
- 条件判断
val result = if(a>b) "greater" else "lesser"- 循环
val squares = for(i <- 1 to 5) yield i*i- 代码块
val result = { val temp = a * b temp + 10 }- 赋值:Scala的赋值表达式不是为了返回一个值
-
惰性表达式:使用时执行(lazy val expr = {})
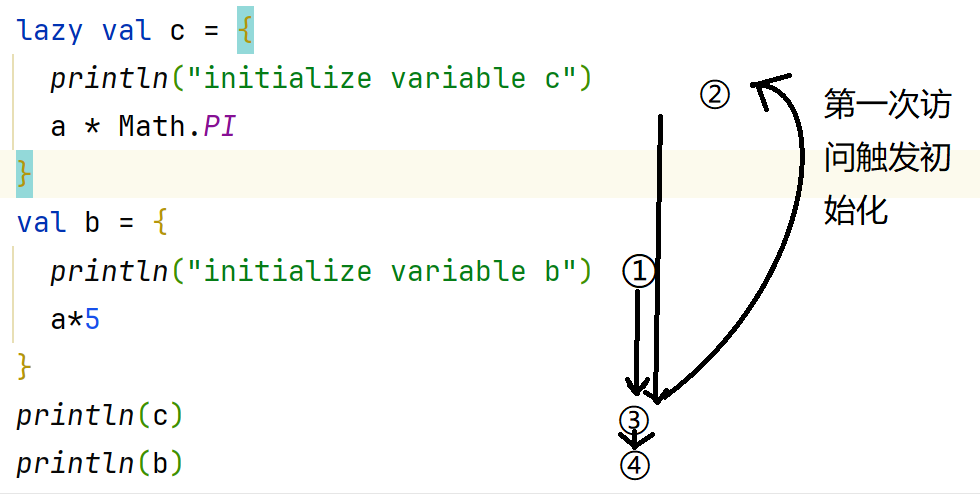
2.运算符
- 赋值
= += -= *= /= %=
- 算术
+= - * / %(没有++和–)
- 关系
> >= < <= == !=
- 逻辑
&& || !
在Scala对象上使用运算符时,实际上是在调用一个方法。因此Scala支持运算符的重载,例如下面的例子对+进行重载实现了复数的加法:
case class Complex(re: Double, im: Double) {
def +(that: Complex): Complex = Complex(this.re + that.re, this.im + that.im)
}
val a = Complex(1.0, 2.0)
val b = Complex(3.0, 4.0)
val c = a + b // 调用a的+方法,传入b作为参数
3.顺序控制
注意懒加载的情况
4.分支控制
var result = if (fig) 1 else 0 // 类似三元运算符
5. 循环
// by 可以指定步长
val range1 = 1 to 10 by 2 // to 前闭后闭
val range2 = 1 until 10 by 3 // until 前闭后开
for(i <- 1 to 3){
print(i+" ")
}
for(i <- 1 until 3){
print(i+" ")
}
// 循环守卫 该写法不可以写成常量的形式
for(i <- 1 to 3 if i != 2){
print(i+" ")
}
// 引入变量
for(i <- 1 to 3; j=4-i){
print(j+" ")
}
// 正向遍历
for(i <- 0 until arr.length){
val item = arr(i)
}
// 反向遍历
for(i<-(0 until arr.length).reverse){
val item = arr(i)
}
- 在Scala中,为了更好地适应函数化编程,特定去掉了break和continue。
// 如何实现continue的效果?-> 循环守卫
for(i <- 1 to 10 if (i != 2 && i != 3)){
print(i+" ")
}
- yield关键字将原始的数组进行转换会产生一个新的数组,原始的数组不变
val arr = Array(1,2,3,4,5)
//arr:Array[Int] = Array(1,2,3,4,5)
val res = for(e <- arr) yield e*2
//res:Array[Int] = Array(2,4,6,8,10)
val res1 = arr.map(_*2)
//res1:Array[Int] = Array(2,4,6,8,10)
val arr = Array(1,2,3,4,5)
val r = arr.filter(_ % 2 == 0).map(_ * 10)
println(r.toBuffer)
- filter是过滤,接收一个返回值为boolean的函数
- map相当于是将数组中的每一个元素取出来,应用传进去的函数
6.迭代器
- 迭代器的三种遍历方法(123为优先级排序)
val it:Iterator[Any] = tp2.productIterator
it.foreach(println) // 使用了Scala的已有函数println(返回类型恰好是Unit) 1
it.foreach(e=>println(e)) // 调用自定义函数(一次性) 2
def show(e:List[Int])=println(e) // 调用自定义函数(可重用) 3
it.foreach(show)
五、集合
-
一般集合的创建都写成常量形式
-
在大数据中默认使用的是不可变类型
-
.var
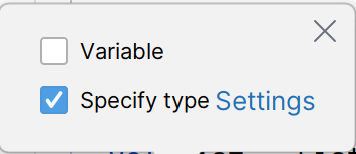
- Variable 更改为变量
- Specify type显示返回类型(适合初学者用)。为了方便设置为自动勾选,点击Settings,在Type Annotations选项卡里,勾选Local Definition选项。
导包
import scala.collection.immutable.Set // 导入具体类
import scala.collection.mutable._ // 导入包内所有类
import scala.collection.mutable.{ListBuffer,ArrayBuffer} // 导入包内部分类
-
默认导入不可变集合包
-
使用可变集合前需要先
import scala.collection.mutable,再通过mutable.T使用import scala.collection.mutable.Set val set = mutable.Set() -
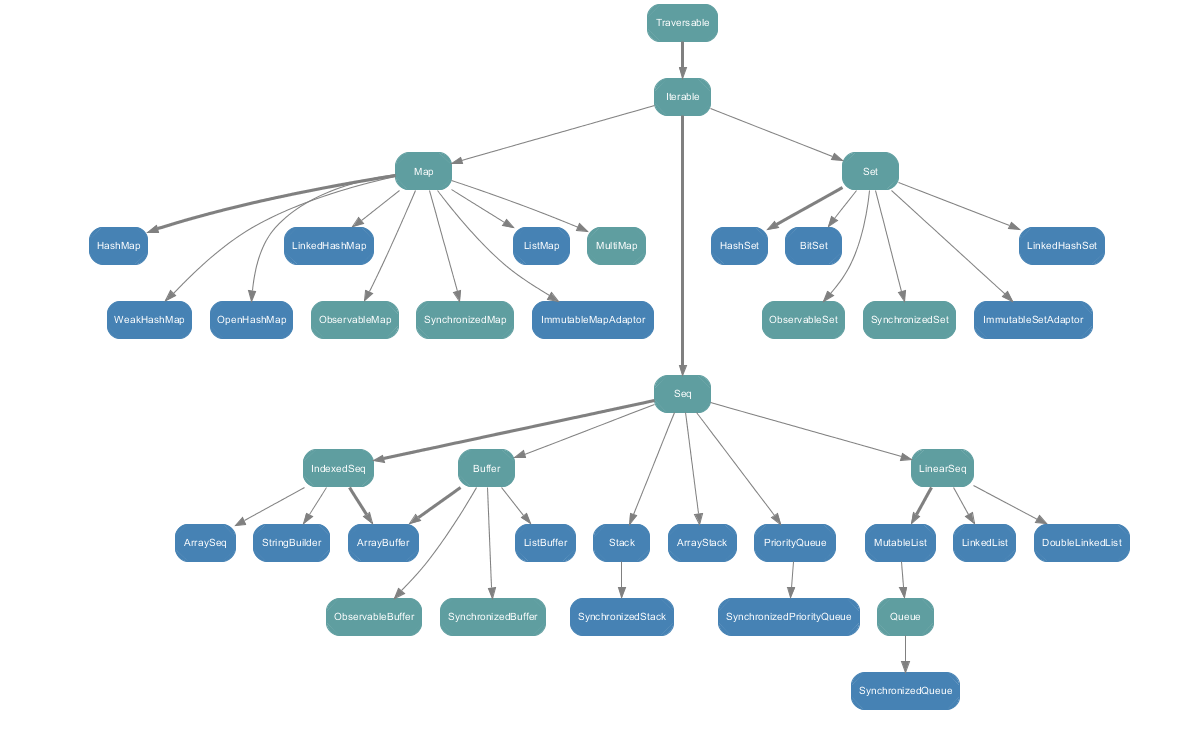
scala.collection.mutable和scala.collection.immutable的目录结构scala.collection.mutable
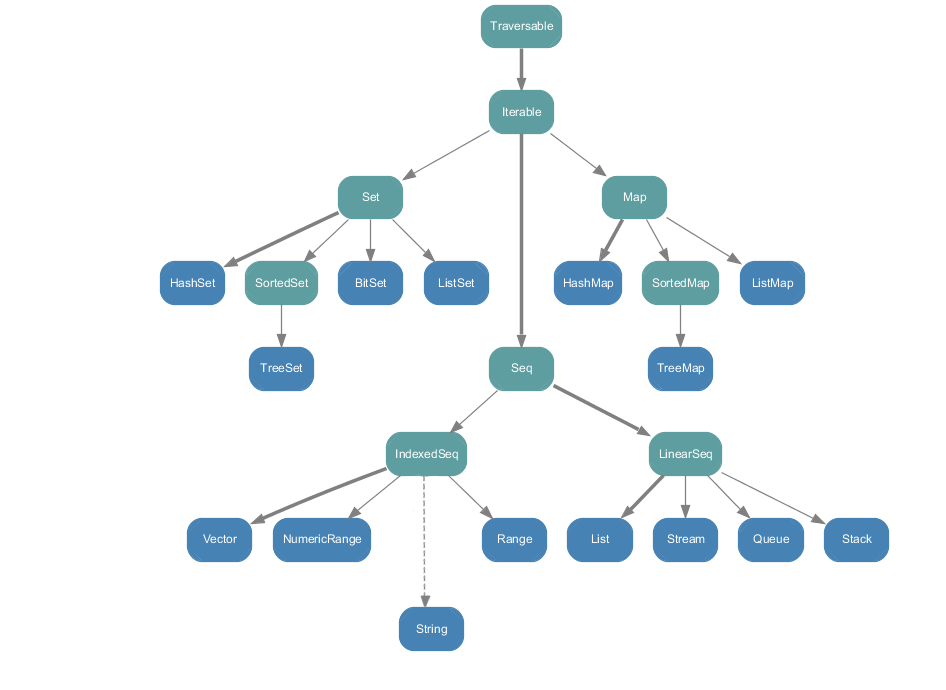
scala.collection.immutable
泛型
泛型用中括号表示:[T1,…,TN]
链表
import scala.collection.immutable.List
import scala.collection.mutable.ListBuffer //可以代替链表高效插删
-
分组
list.grouped(N)表示每N个元素为一组,若非N的整数倍,则最后一组含少于N个元素
val list = List(1, 2, 3, 4, 5, 6)
list.grouped(3).foreach(println)
//(1,2,3)
//(4,5,6)
val it: Iterator[List[Int]] = list.sliding(3,1)// 滑动窗口 list.sliding(3,3) <=> list.grouped(3)
// list.sliding(窗口长度,窗口每次移动距离)
集合
import scala.collection.immutable.Set
import scala.collection.mutable.Set
-
差
差集 set1和set2的顺序会影响正负 当两个不同类型的集合进行交并差的时候 是左边的集合类型决定了结果类型
val diff: mutable.Set[Int] = set2.diff(set1)
val diff2: mutable.Set[Int] = set2 &~ set1
- 交
val union: mutable.Set[Int] = set1.union(set2) // 交集
val union2: mutable.Set[Int] = set1 | set2 // 交集
- 并
val intersect: mutable.Set[Int] = set1.intersect(set2) // 并集
val intersect2: mutable.Set[Int] = set1 & set2
映射
import scala.collection.immutable.Map
import scala.collection.mutable.Map
val map = mutable.Map.empty;
- 映射之间
var map = Map[String,String]("name" -> "jason","age" -> "50","test_100" -> "test_100","test_101" -> "test_101")
val map2 = Map[String,String]("brand"->"apple","sex"->"男")
map += ("city" -> "北京")
map += ("city" -> "南京")// 更新键的值
var combineMap: Map[String, String] = map ++ map2// 合并两个map
val newMap: Map[String, String] = combineMap -- map.keys// 从一个map重删去另一个map的键
combineMap -= ("city","name") // 删除指定的key
println(combineMap.get("age").get) // 获取指定key的值
println(combineMap.get("age").getOrElse("不存在"))
- 映射与元组
val map:mutable.Map[String,Int] = mutable.Map.empty
map += (("java",88)) // 外层括号表示方法的参数列表,内层括号表示是一个二元组
map ++= Array(("scala",76),("hadoop",79)) // 一次性放入
数组
import scala.Array
import scala.collection.mutable.ArrayBuffer
- += ++=
val array = mutable.ArrayBuffer(
(5,100),
(3,88),
(2,60),
(4,74),
(2,52),
(5,80),
(3,83),
(1,59),
(1,77),
(4,45)
)
// 尾部追加
array.append((2,36),(4,77))
array+=((2,36))
// 向一个集合中添加另一个集合
array.appendAll(Array((1,100),(2,200)))
array++=Array((1,100),(2,200))
// 前置添加
array.prepend((2,36),(4,77))
array.prependAll(Array((1,100),(2,200)))
-
数组与元组
:面向集合
val tp2s: ArrayBuffer[(Int, Int)] = array :+ Tuple2(1, 100)
val tp3s: ArrayBuffer[(Int,Int)] = Tuple2(2,100) +: array
字符串插值
s插值器
支持转义符
val age = 18
if(age>=18)
println(s"${age}岁是成年")
else
println(s"${age}岁是未成年")
f插值器
支持转义符和格式占位符
val height = 1.9d
val name = "James"
val introduction = f"$name%s is $height%2.2f meters tall"
raw插值器
不支持转义符
val rawString = raw"Newline character: \n"
println(rawString) // 输出:Newline character: \n,而不是换行
下划线:表示任意字符
-
通配符导入
在导入包时,下划线用作通配符,表示导入该包下的所有成员。
import scala.collection.mutable._ -
省略参数
val nums = List(1,2,3) val doubled = nums.map(_ * 2) -
占位符语法
def add(a:Int,b:Int):Int = a+b val addTwo = add(2,_:Int) // 创建一个新的函数,其中第一个参数固定为2 -
忽略参数
将不关心的参数忽略,起到一定程度上的减少冗余
val (_,value) = (1,"hello")
模式匹配
case _表示没有被之前的case分支匹配的值,类似于 Java 中switch-case语句中的default关键字。case List(id,"java",score:Int)用于匹配列表结构
// 字符串与条件守卫
val rst = "henry@qq.com" match {
case a if a.matches("\\w+@\\w{2,}\\.(com|cn)") => "email"
case a if a.matches("1[3-9]\\d{9}") => "handset"
case "NULL" => "nothing"
case _ => "unknown"
}
// 数值
val rst = 1 match {
case 1 => "charge"
case 2 => "find balance"
case 3 => "promotion"
case _ => "not supported"
}
// 元组
val rst = (7,101) match {
case (3,_) => (3,1)
case (5,a) => if(a%2==0) (5,0) else (5,1)
case _ => (0,0)
}
// 列表
val rst = List(1,"hive",88) match {
case List(id,"java",score:Int) => if(score>=60) ("java","pass") else ("java","fail")
case _ => ("SKIP","NONE")
}
// 类型
val rst = value match {
case a:Int => ("int",a)
case a:(Int,Int) => ("Tuple2",a)
case a:String => ("String",a)
case _ => ("Unknown",1)
}
// 嵌套
val rst = (1,("java",67)) match {
case (1,(sub:String,score:Int)) => (sub,score)
case _ => ("UnknownFormat",1)
}
六、方法与函数
-
从Java->Scala,为什么我们需要划分方法与函数的界限?
在Java中,"方法"这个术语被用来描述类或对象的行为,而Java没有像"Scala"那样显式地使用"函数"这个概念。这是因为Java主要是一种面向对象的编程语言,而不直接支持函数式编程的特性。
Scala是多范式编程语言,支持面向对象和函数式编程两种范式。在Scala中,函数是一等公民,意味着它们可以像任何其它值一样被传递和操作。这种设计决定了方法(定义在类或对象中的行为)和函数(可以独立于类或对象存在的代码块)之间有明确的区别。
-
方法与函数的异同·
-
同:都可以执行代码块并返回结果。
-
异:方法不能直接作为值传递,而函数可以直接作为值传递。
方法调用依赖于对象实例或类,而函数可以独立于任何类或对象存在。
-
-
将函数作为参数传递的三种方式
def show(e:List[Int])=println(e)
it.foreach(show) // 【自定义】函数(重用) 3
it.foreach(e=>println(e)) // 【自定义】函数(一次性) 2
it.foreach(println) // 调用scala【已定义】函数 1
-
创建函数
val func:(参数类型) => (返回类型) = (参数列表) => {函数体}
// 接受一个整数列表作为参数并返回列表中所有元素之和的函数
val sum:(List[Int])=>Int=(numbers)=>{
numbers.sum
}
-
创建方法
def func(参数列表):返回类型={方法体}
// 求和方法
def add(a:Int,b:Int):Int={
a+b
}
-
可变参数:一个参数列表只能有一个可变参数,且必须在参数列表的末尾
def func(...,可变参数:可变参数类型*):返回类型={方法体}
def func(numbers:Int*):Int={
numbers.sum
}
-
函数作为参数:主流
def func(...,参数方法名:(参数列表)=>返回类型,...):返回类型={方法体}
def applyOperation(x:Int,y:Int,operation:(Int,Int)=>Int):Int = operation(x,y)
val sum = applyOperation(5,3,(a,b)=>a+b)
println(sum)
- 函数柯里化(Currying)
def func(init:Int,a:Int*) = {...} => def func(init:Int)(a:Int*) = {...}
def func1(init: Int)(a: Int*): Int = init + a.sum
def func2(init: Int, a: Int*): Int = init + a.sum
val result1 = func1(10)(1, 2, 3) // 需要两步调用,func1返回一个函数
val result2 = func2(10, 1, 2, 3) // 一步调用,直接传递所有参数
println(result1) // 输出:16
println(result2) // 输出:16
func1是一个柯里化函数,是将接收多个参数的函数转换成接受单一参数的函数的过程,这些单一参数的函数返回接收下一个参数的新函数。
柯里化的作用:1.可以固定一部分参数,便于进行函数的服用
2.有利于进行延迟计算
-
隐式参数(implicit)
implicit val f = (a:Int,b:Int) => a/bdef divide(init:Int)(a:Int*)(implicit f:(Int,Int)=>Int):Int = f(init,a)
implicit val divider: (Int, Int) => Int = (a, b) => a / b
def divide(init: Int)(a: Int*)(implicit f: (Int, Int) => Int): Int = f(init, a.sum)
val result = divide(10)(1, 2, 3) // 使用隐式参数divider
println(result) // 输出:2
隐式参数允许你省略调用函数时传递常用或可以由上下文推断的参数,简化代码。
隐式参数中需要将函数作为方法参数
七、数组方法
1.创建定长|变长数组
创建定长数组
// new 关键字让所有元素初始化为0
val arr1 = new Array[Int](8)
val arr2 = Array[Int](10)
val arr3 = Array("hadoop","storm","spark")
创建变长数组
import scala.collection.mutable.ArrayBuffer
val empty: ArrayBuffer[Int] = ArrayBuffer.empty
val ab1: ArrayBuffer[Int] = ArrayBuffer(1, 2, 3)
2.基本操作
获取长度、检查空状态
val length = buffer.length
val bool = buffer.isEmpty
val bool = buffer.nonEmpty
全部元素检查、存在性、包含行检查
val bool = buffer.forall(f: T => Boolean) // 检查是否所有元素都满足条件
println(array.forall(_ >= 10)) // 判断数组是否所有元素都>=10
val bool = buffer.exists(f: T => Boolean) // 检查是否存在满足条件的元素
println(array.exists(_ >= 10)) // 判断数组是否存在>=10的元素
val bool = buffer.contains(t: T)
val bool = buffer.containsSlice(Array(10,9,20)) // 是否包含完整的子序列(数量,顺序,内容)
array.corresponds(Array(16, 20, 14, 11, 6, 9, 8, 20))(_>_) // 判定该数组的每个元素是否与传入的数组序列的每个元素都符合传入函数的规则
array.sameElements(Array(17,21,15,12,7,10,9,20)) // 判定该数组的每个元素是否与传入的数组序列的每个元素相同
起始/结束匹配、逆向
val bool = buffer.startsWith(Array(17,21,15))// 判定数组是否是以该元素片段开头
val bool = buffer.endsWith(Array(10,9,20))// 判定数组是否是以该元素片段结尾
val reverse: ArrayBuffer[T] = buffer.reverse
定位元素
val index = buffer.indexOf(15)// 查找该元素在数组中对应的下标
val index = buffer.indexOfSlice(Array(7, 10, 9))// 查找该片段在数组中的第一个元素的下标
var index = array.indexWhere(_ < 10)// 查找第一个符合条件的元素下标
val lastIndex = buffer.lastIndexOf(15)// 从尾部开始查找,查找该元素在数组中对应的下标
val lastIndex = buffer.lastIndexOfSlice(Array(7, 10, 9))// 从尾部开始查找,查找该片段在数组中的第一个元素的下标
var lastIndex = array.lastIndexWhere(_ < 10)// 从尾部开始查找,查找第一个符合条件的元素下标
数据迁移
val ints: Array[Int] = array.clone()// 复制数组的元素和结构
array.copyToArray(arr,0,2)// 将array数组中下标范围为[0,2)的元素拷贝到arr数组中
array.copyToBuffer
添加元素
// buffer.append(e:T*) +=
buffer.append((1,111))
// buffer.prepend(e:T*) +=:
buffer.prepend((2,112))
// buffer.appendAll(es:TraversableOnce) ++=
buffer.appendAll(Array((3,113)))
// buffer.prependAll(es:TraversableOnce) ++=:
buffer.prependAll(Array((4,114)))
buffer.insert(0,(3,112))
buffer.insertAll(0,Array((1,451)))
// 最终类型由左侧表达式的类型决定
val combine:ArrayBuffer[T] = buffer ++ seq:GenTraversableOnce[T]
val newBuffer: ArrayBuffer[T] = buffer :+ ((4,5)) // 用于在数组缓冲的末尾添加元素,buffer:+t即将元素添加到buffer的末尾
val newBuffer: ArrayBuffer[T] = ((4,5)) +: buffer// 用于在数组缓冲的开头添加元素,buffer:+t即将元素添加到buffer的末尾
-
如何理解
:+和+:?可以将
:看作是数组缓冲的象征,而+指向要添加的元素的位置,buffer :+ t可以被视为将元素t添加到buffer的末尾
删除元素
val left: ArrayBuffer[T] = buffer - (T)
val left: ArrayBuffer[T] = buffer -- (seq:TraversableOnce[T])
buffer -= (T)
buffer --= (seq:TraversableOnce[T])
T t = buffer.remove(index:Int)// 删除指定下标的元素,并返回被删除的元素
buffer.remove(index:Int, count:Int)// 从index位置开始,删除count个元素
buffer.clear()
val left1: ArrayBuffer[T] = buffer.drop(size:Int) // 左删除
val left2: ArrayBuffer[T] = buffer.dropRight(size:Int) // 右删除
// 元素已升序排序时推荐 : 从左1开始,删除连续满足条件的元素,若左1就不满足则不删除
val left3: ArrayBuffer[T] = buffer.dropWhile(f:T=>Boolean) // 左删
buffer.trimEnd(size:Int) // 右删除size个元素
buffer.trimStart(size:Int) // 左删除size个元素
buffer.reduceToSize(size:Int) // 削减容量(左保留)
val distinct: ArrayBuffer[(Int, Int)] = buffer.distinct // 去重
修改和提取
-
array.patch(from,seq,replaced)replaced=0=>插入 replaced>0&&seq.nonEmpty()=>替换 replaced>0&&seq.isEmpty()=>删除
-
Option类型用于表示一个值可能存在也可能不存在的情况。Option有两种形态:Some和None。Some包含一个值,而None表示没有值。使用Option可以避免空指针异常。
array.update(2,30)// 将下标为2的元素值改为30
val upd: Array[Int] = array.updated(2, 30) // 返回一个新数组
val upd = array.patch(2, Array(100, 200), 2) // 将从下标2开始的两个元素分别替换为100和200
val upd2 = array.patch(2, Array[Int](), 2) // 相当于删除
val item = buffer.apply(index:Int)// 用于获取 ArrayBuffer 中给定索引位置的元素
val item = buffer.applyOrElse(index:Int,f:Int->T)// 尝试获取给定索引的元素,如果索引超出范围或不存在,则调用函数 f
val opt: Option[(Int, Int)] = buffer.find(f:T=>Boolean)// 搜索第一个满足给定条件的元素,并返回一个 Option 类型的结果。如果找到符合条件的元素,则返回 Some(元素);如果没有找到,则返回 None。
其他算法
val arr = Array(2,1,3,4,5)
println("arr.sum="+arr.sum)// 求和
println("arr.max="+arr.max)// 求最大值
println("arr.sorted="+arr.sorted.toBuffer)// 排序
array.patch(from,seq,replaced)
replaced=0=>插入 replaced>0&&seq.nonEmpty()=>替换 replaced>0&&seq.isEmpty()=>删除
Option类型用于表示一个值可能存在也可能不存在的情况。Option有两种形态:Some和None。Some包含一个值,而None表示没有值。使用Option可以避免空指针异常。
array.update(2,30)// 将下标为2的元素值改为30
val upd: Array[Int] = array.updated(2, 30) // 返回一个新数组
val upd = array.patch(2, Array(100, 200), 2) // 将从下标2开始的两个元素分别替换为100和200
val upd2 = array.patch(2, Array[Int](), 2) // 相当于删除
val item = buffer.apply(index:Int)// 用于获取 ArrayBuffer 中给定索引位置的元素
val item = buffer.applyOrElse(index:Int,f:Int->T)// 尝试获取给定索引的元素,如果索引超出范围或不存在,则调用函数 f
val opt: Option[(Int, Int)] = buffer.find(f:T=>Boolean)// 搜索第一个满足给定条件的元素,并返回一个 Option 类型的结果。如果找到符合条件的元素,则返回 Some(元素);如果没有找到,则返回 None。
其他算法
val arr = Array(2,1,3,4,5)
println("arr.sum="+arr.sum)// 求和
println("arr.max="+arr.max)// 求最大值
println("arr.sorted="+arr.sorted.toBuffer)// 排序