语音识别技术简述
语音识别的概念
语音识别技术都是让智能设备能够听懂人类语言,其实一门涉及数学信号处理、人工智能、语言学、数理统计学、声学、情感学及心理学等多学科交叉的学科。这项技术可以提供比如自动客服、自动语音翻译、命令控制,语音验证码等多项应用。近年来,随着人工智能的兴起,语音识别技术在理论和应用方面都取得大突破,开始从实验室走向市场,已逐渐走进我们的日常生活。现在语音识别己用于许多领域,主要包括语音识别听写器、语音寻呼和答疑平台、自主广告平台,智能客服等。
语音识别原理
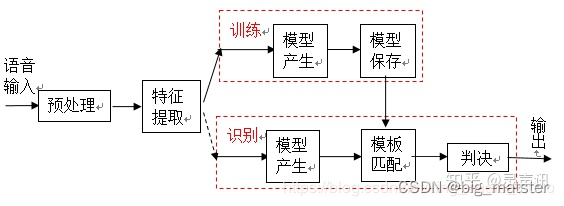
语音识别的本质是一种基于语音特征参数的模式识别,即通过学习,系统能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。目前,模式匹配原理已经被应用于大多数语音识别系统中。如图1是基于模式匹配原理的语音识别系统框图。
一般的模式识别包括预处理,特征提取,模式匹配等基本模块。如图所示首先对输入语音进行预处理,其中预处理包括分帧,加窗,预加重等。其次是特征提取,因此选择合适的特征参数尤为重要。常用的特征参数包括**:基音周期,共振峰,短时平均能量或幅度,线性预测系数(LPC),感知加权预测系数(PLP),短时平均过零率,线性预测倒谱系数(LPCC),自相关函数,梅尔倒谱系数(MFCC),小波变换系数,经验模态分解系数(EMD),伽马通滤波器系数(GFCC**)等。在进行实际识别时,要对测试语音按训练过程产生模板,最后根据失真判决准则进行识别。常用的失真判决准则有欧式距离,协方差矩阵与贝叶斯距离等。
语音识别技术简介
从语音识别算法的发展来看,语音识别技术主要分为三大类,第一类是模型匹配法,包括矢量量化(VQ) 、动态时间规整(DTW)等;第二类是概率统计方法,包括高斯混合模型(GMM) 、隐马尔科夫模型(HMM)等;第三类是辨别器分类方法,如支持向量机(SVM) 、人工神经网络(ANN)和深度神经网络(DNN)等以及多种组合方法。下面对主流的识别技术做简单介绍:
动态时间规整(DTW)
语音识别中,由于语音信号的随机性,即使同一个人发的同一个音,只要说话环境和情绪不同,时间长度也不尽相同,因此时间规整是必不可少的。DTW是一种将时间规整与距离测度有机结合的非线性规整技术,在语音识别时,需要把测试模板与参考模板进行实际比对和非线性伸缩,并依照某种距离测度选取距离最小的模板作为识别结果输出。动态时间规整技术的引入,将测试语音映射到标准语音时间轴上,使长短不等的两个信号最后通过时间轴弯折达到一样的时间长度,进而使得匹配差别最小,结合距离测度,得到测试语音与标准语音之间的距离。
支持向量机(SVM)
支持向量机是建立在VC维理论和结构风险最小理论基础上的分类方法,它是根据有限样本信息在模型复杂度与学习能力之间寻求最佳折中。从理论上说**,SVM就是一个简单的寻优过程**,它解决了神经网络算法中局部极值的问题,得到的是全局最优解。SVM已经成功地应用到语音识别中,并表现出良好的识别性能。
矢量量化(VQ)
矢量量化是一种广泛应用于语音和图像压缩编码等领域的重要信号压缩技术,思想来自香农的率-失真理论。其基本原理是把每帧特征矢量参数在多维空间中进行整体量化,在信息量损失较小的情况下对数据进行压缩。因此,它不仅可以减小数据存储,而且还能提高系统运行速度**,保证语音编码质量和压缩效率**,一般应用于小词汇量的孤立词语音识别系统。
隐马尔可夫模型(HMM)
隐马尔科夫模型是一种统计模型,目前多应用于语音信号处理领域。在该模型中,马尔科夫(Markov)链中的一个状态是否转移到另一个状态取决于状态转移概率,而某一状态产生的观察值取决于状态生成概率。在进行语音识别时,HMM首先为每个识别单元建立发声模型,通过长时间训练得到状态转移概率矩阵和输出概率矩阵,在识别时根据状态转移过程中的最大概率进行判决。
高斯混合模型GMM
高斯混合模型是单一高斯概率密度函数的延伸,GMM能够平滑地近似任意形状的密度分布。高斯混合模型种类有单高斯模型(Single Gaussian Model, SGM)和高斯混合模型(Gaussian Mixture Model, GMM)两类。类似于聚类,根据高斯概率密度函数(Probability Density Function, PDF)参数不同,每一个高斯模型可以看作一种类别,输入一个样本x,即可通过PDF计算其值,然后通过一个阈值来判断该样本是否属于高斯模型。很明显,SGM适合于仅有两类别问题的划分,而GMM由于具有多个模型,划分更为精细,适用于多类别的划分,可以应用于复杂对象建模。目前在语音识别领域,GMM需要和HMM一起构建完整的语音识别系统。
人工神经网络(ANN/BP)
人工神经网络由20世纪80年代末提出,其本质是一个基于生物神经系统的自适应非线性动力学系统,它旨在充分模拟神经系统执行任务的方式。如同人的大脑一样,神经网络是由相互联系、相互影响各自行为的神经元构成,这些神经元也称为节点或处理单元。神经网络通过大量节点来模仿人类神经元活动,并将所有节点连接成信息处理系统,以此来反映人脑功能的基本特性。尽管ANN模拟和抽象人脑功能很精准,但它毕竟是人工神经网络**,只是一种模拟生物感知特性的分布式并行处理模型**。ANN的独特优点及其强大的分类能力和输入输出映射能力促成在许多领域被广泛应用,特别在语音识别、图像处理、指纹识别、计算机智能控制及专家系统等领域。但从当前语音识别系统来看,由于ANN对语音信号的时间动态特性描述不够充分,大部分采用ANN与传统识别算法相结合的系统。
深度神经网络
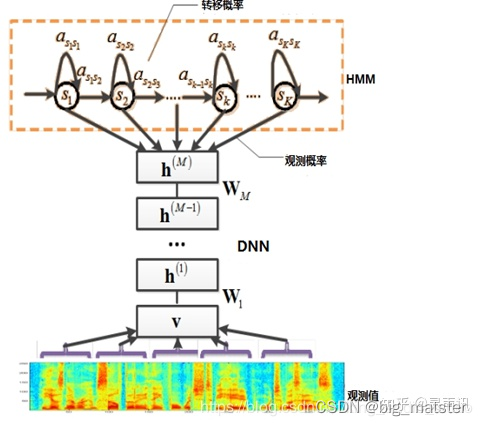
当前诸如ANN,BP等多数分类的学习方法都是浅层结构算法,与深层算法相比存在局限。尤其当样本数据有限时,它们表征复杂函数的能力明显不足。深度学习可通过学习深层非线性网络结构,实现复杂函数逼近,表征输入数据分布式,并展现从少数样本集中学习本质特征的强大能力。在深度结构非凸目标代价函数中普遍存在的局部最小问题是训练效果不理想的主要根源。为了解决以上问题,提出基于深度神经网络(DNN) 的非监督贪心逐层训练算法,它利用空间相对关系减少参数数目以提高神经网络的训练性能。相比传统的基于GMM-HMM的语音识别系统,其最大的改变是采用深度神经网络替换GMM模型对语音的观察概率进行建模。最初主流的深度神经网络是最简单的前馈型深度神经网络(Feedforward Deep Neural Network,FDNN)。DNN相比GMM的优势在于:1. 使用DNN估计HMM的状态的后验概率分布不需要对语音数据分布进行假设;2. DNN的输入特征可以是多种特征的融合,包括离散或者连续的;3. DNN可以利用相邻的语音帧所包含的结构信息。基于DNN-HMM识别系统的模型如图2所示。
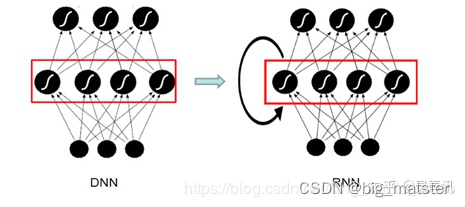
循环神经网络(RNN)
长短期记忆模块

卷积神经网络CNN

识别技术的发展方向
- 更有效的序列到序列直接转换的模型。序列到序列直接转换的模型目前来讲主要有两个方向,一是CTC模型;二是Attention 模型。
鸡尾酒会问题(远场识别)。这个问题在近场麦克风并不明显,这是因为人声的能量对比噪声非常大,而在远场识别系统上,信噪比下降得很厉害,所以这个问题就变得非常突出,成为了一个非常关键、比较难解决的问题。鸡尾酒会问题的主要困难在于标签置换(Label Permutation),目前较好的解决方案有二,一是深度聚类(Deep Clustering);二是置换不变训练(Permutation invariant Training)。 - 持续预测与自适应模型。能否建造一个持续做预测并自适应的系统。它需要的特点一个是能够非常快地做自适应并优化接下来的期望识别率。另一个是能发现频度高的规律并把这些变成模型默认的一部分,不需要再做训练。
前后端联合优化。前端注重音频质量提升,后端注重识别性能和效率提升。
总结
- 慢慢道降各种模型全部都研究透彻,研究彻底。都行啦的理由与带伞。争取将其全部都搞定。研究彻底都行啦的胡回事与打算。