监控平台对主流数据库的监控,能够及时发现异常,快速响应,保障业务系统的稳定。平台通过对SQL Server数据库监控,帮助用户在数据库出现异常时事件处理。
SQL Server数据库监控内容如下
1 、数据库服务器基本性能监控。包括:服务器的CPU数量,内存大小,服务器在线时间,在线数据实例个数,离线数据实例个数和挂起的数据实例个数。
2、监控数据库基本统计信息。比如实时用户连接数,实时的活动临时数据表个数,平均每秒登录的用户数和平均每秒登出的用户数等。
3、对数据库锁的监控。每秒超值锁的个数和死锁的个数。
4、对数据库内存使用情况监控。包括数据库运行需要的理想的内存和实际使用的内存量,以及成功获取内存授权的进程数和正在等待内存授权的进程数量。
5、数据库资源池分配,默认包括default资源和内部资源,内部资源是保证数据库正常运行所需消耗的CPU和内存资源。
6、对数据库内存缓冲区管理监控, 包括数据库命中率,页预期寿命,和每秒物理读页数和每秒物理写页数,以及每秒物理惰性写次数。
数据命中率值不能低于 90%,页预期寿命是数据页在缓存中停留的时间,当数据页在缓存中低于300S就被置换出去时,需要检查分配给数据库使用的内存,是否存在内存不足问题。
7、监控数据库实例。在这里我们可以看到SQL server中的所有数据库实例,以及每个数据实例的数据文件和日志文件大小,并可以根据时序图,对文件大小进行趋势预测。
8、数据库的IO监控。包括每秒从数据库读取的字节数和每秒从数据库写入的字节数,这两个参数可以反映反映了数据库缓存和磁盘之间的IO交换的性能。
9、对SQL Server中的错误监控。例如DB离线错误,信息错误和用户错误等。
10、对数据库中等待进程的统计监控。列出线程所遇到的所有等待的相关信息。比如等待CPU资源的进程数,平均等待时间。等待内存资源的进程数,平均等待时间。以及等待锁的进程数和等待网络IO的进程数等等。对数据库每秒错误数监控和等待时间监控,可以帮助我们来诊断 SQL Server 以及特定查询和批处理的性能问题。
SQL server数据库监控
事件排查
10月13日,某三甲医院新接入4台服务器系统、4个SQL server数据库,系统对HIS数据库进行重点监控。
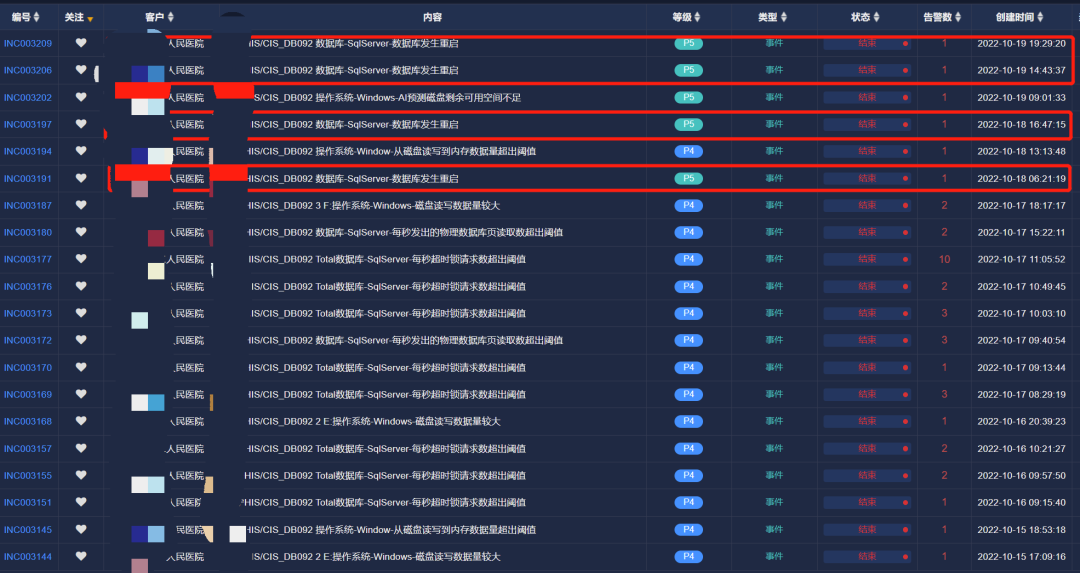
自10月15日起,LinkSLA智能运维平台监测到新接入的HIS/CIS数据库多次发生重启,MOC工程师通知用户进行查看重启原因;
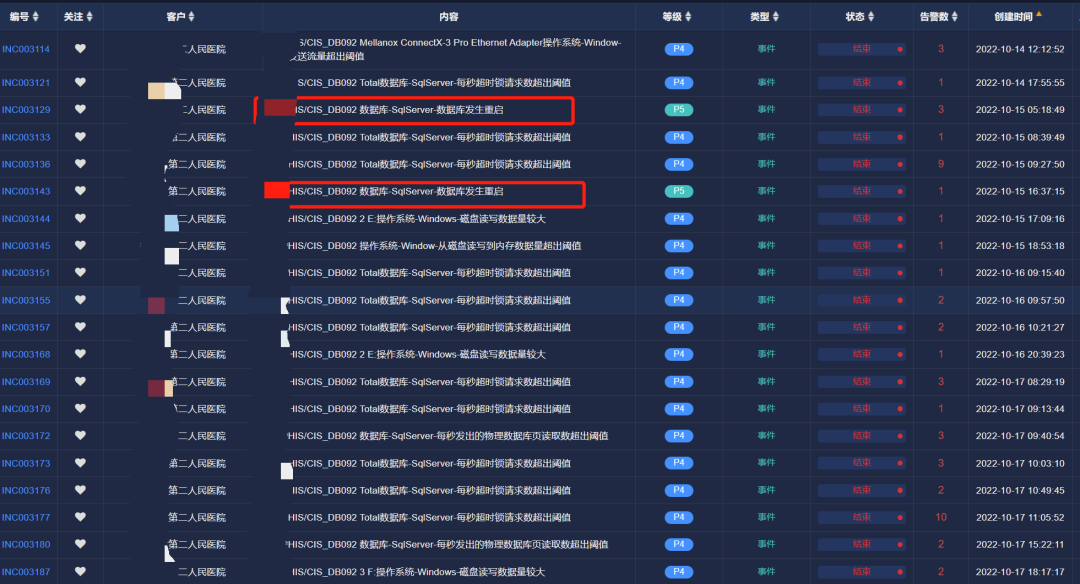
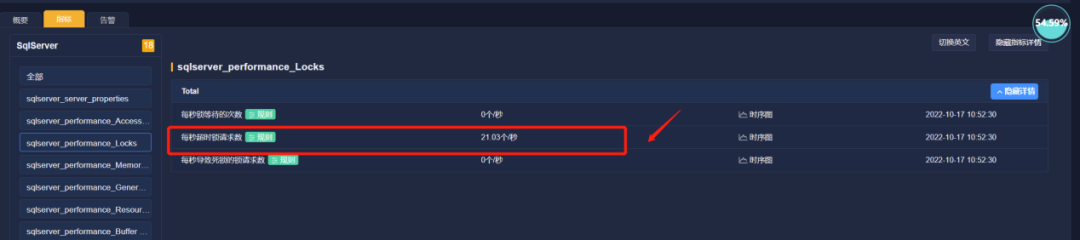
报告数据库有超时锁超出阈值告警。锁等待时间是一个进程花费在等待另一个进程释放锁的时间。
MOC工程师及时与应用厂商的数据工程师反馈,对方未发现有重启事件。
MOC工程师将数据库运行时间展示给应用厂商的工程师查看:HIS/CIS DB092172.20.64.xx数据库运行时间是212分钟,在6点21分时重启,这个参数值是数据库的运行指标值。请检查数据库重启的原因。
通过数据库运行时间,确认数据库发生重启,提高问题关注度。
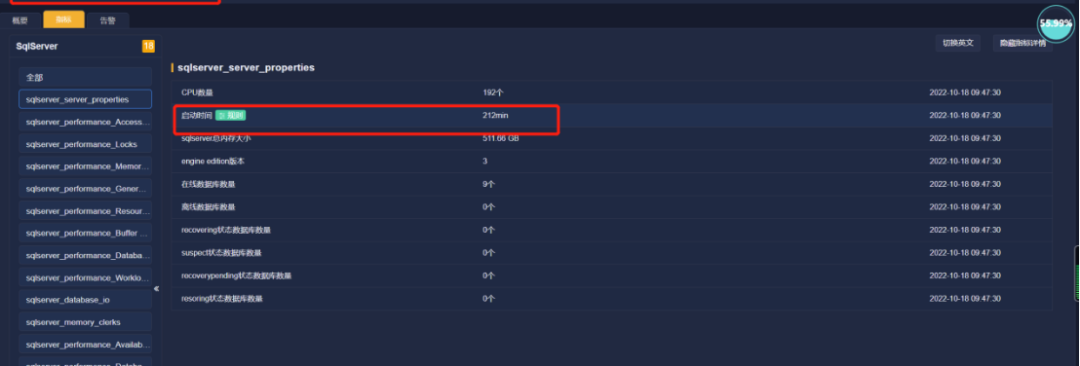
应用厂商的工程师通过登录数据库确认,确认数据库反复重启现象。
接下来的一周,数据库仍然时常发生重启,每秒超时锁数量超出阈值。由于系统集群没有异常报错,应用厂商数据工程师并未重视。
事件处理
经过MOC工程师反复通报数据库重启问题,引起用户重视。应用厂商的数据库工程师经过排查,发现是SQL Server数据库bug导致反复重启,对数据库进行打补丁升级。
打补丁升级后,MOC工程师持续监测SQL server数据库问题。后期未发生SQL Server数据库反复重启问题,告警得以解除。
事件复盘
从HIS数据库安装后,发生反复自动重启,应用厂商的数据工程师未发现重启故障。接到MOC工程师告警后,应用厂商的数据工程师认为集群没有异常报错,并未着急处理。但是HIS系统是医院的核心系统,数据库反复自动重启,存在很大的安全隐患。平台多次告警,锁定SQL Server数据库bug导致,并进行打补丁升级,数据库反复重启问题解决。
通过这个案例可以了解到,业务系统由应用厂商安装和维护,出现故障隐患时,用户并不能及时感知,更无法及时解决。LinkSLA智能运维管家帮助用户一站式监控所有业务系统,及时发现故障MOC工程师并持续跟踪,直至问题解决,形成服务闭环。为用户提供省心、放心的IT运维服务,保障用户系统健康稳定运行。