SQL性能优化系列:
Hive/MaxCompute SQL性能优化(一):什么是数据倾斜
Hive/MaxCompute SQL性能优化(二):如何定位数据倾斜
前面介绍了如何定位数据倾斜,本文介绍如果遇到各种数据倾斜的情况该怎样优化代码。
Map长尾优化
一、Map读取数据量不均匀
小文件多,数据分布不均匀,使用下面的参数设置小文件合并,让每个mapper实例读取数据量大致相同。
set odps.sql.mapper.merge.limit.size=64; -- 小于阈值的文件将会合并,默认64mb
set odps.sql.mapper.split.size=256; --map最大输入数据量,默认256mb,影响mapper数量当出现文件过大,mapper很少,导致map端读取数据很慢的时候,可以适量缩小split.size的值,以达到提高map实例数量的效果,提高数据读取效果。
二、Map实例读取的块中的数据分布不均匀
出现这种情况的话,可以使用distribute by rand()打乱数据,将数据随机分发。
需要注意,此参数不可随意使用,只有出现块中数据分布不均时候才建议使用,否则会适得其反。
使用此参数后,map端不要再做复杂join、聚合,避免map端长尾,并且会带来reduce端的资源紧张,可以适度增加reducer的个数。
set odps.sql.reducer.instances=500; -- 增大reducer个数
select id,count(*) cnt
from (
select id,name
from tbl
distribute by rand()
)
group by id
;Join端长尾优化
一、关联键存在大量空值引发长尾
首先定位是哪个关联键中存在空值,然后使用rand()随机值替换join字段空值,打乱空值的分布,提高计算并行度,并且由于空值本身关联无意义,因此不会影响数据结果。
select ...
from a
left join b
on coalesce(a.id,rand()*9999) = coalesce(b.id,rand()*9999) --空值替换成随机值,不影响计算结果,可以将空值打散到多个joinner中二、大表关联小表,使用mapjoin优化避免长尾
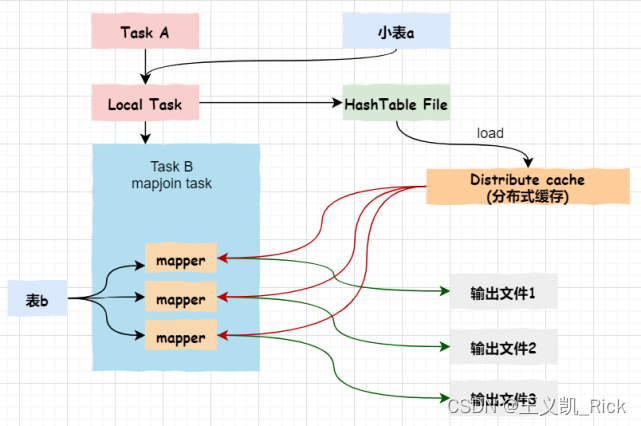
大表关联小表时,可以使用mapjoin hint,将小表广播到map端,转换成hash table加载到内存中,在mapper端和大表的分散数据做笛卡尔积,省去大表的shuffle时间,避免出现长尾。
注意,小表的定义有阈值限制,并且小表只能作为从表,不能作为主表。
且map join没有reduce任务,所以map直接输出结果,即有多少个map任务就会产生多少个结果文件
set odps.sql.mapjoin.memory.max=512; -- 最大2048MB,小表过大会影响性能
select /*+ mapjoin(b,c)*/ --mapjoin hint 定义小表,多个用逗号分隔
...
from t0 a
left join t1 b
on a.id = b.id
left join t2 c
on a.id = c.idmap join原理图:
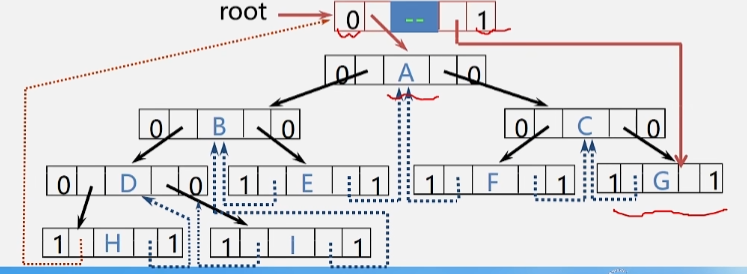
三、大表关联大表,使用skewjoin优化避免长尾
大表关联大表出现数据倾斜时,可以将大表数据拆分,对热点数据使用map join,非热点数据使用merge join,然后将结果合并。
如何拆分热点数据:引入一个aggregate,提取topK热点key拆分数据,可以通过参数调整top key个数:set odps.optimizer.skew.join.topk.num=20;
若执行计划中出现topk_agg关键字,则表示skewjoin生效。
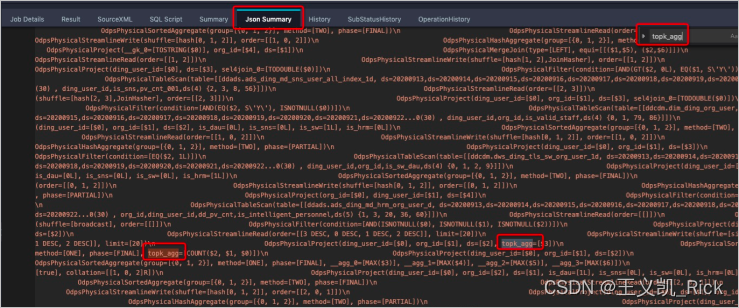
skew join原理图:

下面三个级别的hint,指定热点信息越详细,效率越高。
-- 性能效率 方法1<方法2<方法3
-- 方法1:hint表名
select /*+ skewjoin(a)*/ ... from t0 a join t1 b on a.id = b.id and a.code = b.code;
-- 方法2:hint表名和认为可能产生倾斜的列,下面认为a的id和code列存在倾斜
select /*+ skewjoin(a(id,code))*/ ... from t0 a join t1 b on a.id = b.id and a.code = b.code;
-- 方法3:hint表名和列,并提供产生倾斜的列的值,如果是string类型需要加引号
-- 下面case认为(a.id=1 and a.code='xxx')和(a.id=3 and a.code='yyy')的值出现倾斜
select /*+ skewjoin(a(id,code)((1,'xxx'),(3,'yyy')))*/ ... from t0 a join t1 b on a.id = b.id and a.code = b.code;四、大表关联中表,使用distributed mapjoin优化
Distributed MapJoin是MapJoin的升级版,适用于小表Join大表的场景,二者的核心目的都是为了减少大表侧的Shuffle和排序。
注意事项:
Join两侧的表数据量要求不同,大表侧数据在10 TB以上,小表侧数据在[1 GB, 100 GB]范围内。
小表侧的数据需要均匀分布,没有明显的长尾,否则单个分片会产生过多的数据,导致OOM(Out Of Memory)及RPC(Remote Procedure Call)超时问题。
SQL任务运行时间在20分钟以上,建议使用Distributed MapJoin进行优化。
由于在执行任务时,需要占用较多的资源,请避免在较小的Quota组运行。
使用方式:
在select语句中使用Hint提示
/*+distmapjoin(<table_name>(shard_count=<n>,replica_count=<m>))*/
并发数=shard_count * replica_count
参数说明:
table_name:目标表名。
shard_count=<n>:设置小表数据的分片数,小表数据分片会分布至各个计算节点处理。n即为分片数,一般按奇数设置。
说明
shard_count值建议手动指定, shard_count值可以根据小表数据量来大致估算,预估一个分片节点处理的数据量范围是[200 MB, 500 MB]。
shard_count设置过大,性能和稳定性会受影响; shard_count设置过小,会因内存使用过多而报错。
replica_count=<m>:设置小表数据的副本数。m即为副本数,默认为1。
说明 为了减少访问压力以及避免单个节点失效导致整个任务失败,同一个分片的数据,可以有多个副本。当并发过多,或者环境不稳定导致运行节点频繁重启,可以适当提高 replica_count,一般建议为2或3。
语法示例
-- 推荐,指定shard_count(replica_count默认为1)
/*+distmapjoin(a(shard_count=5))*/
-- 推荐,指定shard_count和replica_count
/*+distmapjoin(a(shard_count=5,replica_count=2))*/
-- distmapjoin多个小表
/*+distmapjoin(a(shard_count=5,replica_count=2),b(shard_count=5,replica_count=2)) */
-- distmapjoin和mapjoin混用
/*+distmapjoin(a(shard_count=5,replica_count=2)),mapjoin(b)*/五、动态过滤器 Dynamic Filter
适用于大表和中小表关联,且小表过滤性高的情况,使用动态过滤器,可减少大表shuffle数据量,以此提高性能。
如图所示,两表join,其中A为小表,B为大表,依据A表的key生成filter,推送至shuffle/join之前,提前过滤B表(大表)的数据量,可以减少B表shuffle的数据量从而提高性能。

使用hint开启动态过滤功能:
-- HINT格式为/*+dynamicfilter(Producer, Consumer1[, Consumer2,...])*/,允许一个生产者过滤多个消费者
select /*+dynamicfilter(A, B)*/ * from (table1) A join (table2) B on A.a= B.b;注意,当关连键为分区字段时,可以开启动态分区裁剪,在读取完整数据前将无用分区裁剪掉。
下面的例子,如果不使用动态分区裁剪,则会将B表中的全部分区读取后再和A表关联,即使此时开启了动态过滤器,也在前期浪费了大量的读取时间。
而打开动态分区裁剪功能后,由于A表中的a列值只有20200701,B表中的20200702和20200703分区会被裁剪掉,既节省了资源,也降低了作业运行时长。
-- 开启动态分区裁剪功能
set odps.optimizer.dynamic.filter.dpp.enable=true;
--A为非分区表,表中a列的值为20200701。
--B为分区表,表中ds列的值包含3个分区20200701、20200702、20200703。
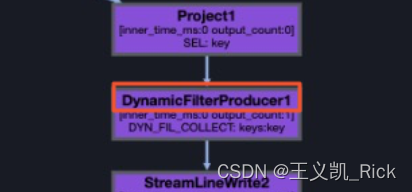
select * from (table1) A join (table2) B on A.a= B.ds;开启动态过滤器或动态分区裁剪后,若Logview中出现类似DynamicFilterConsumer1的算子,说明动态过滤器已生效。
Reduce长尾
一、Count Distinct引发长尾
count distinct使得map端不做预聚合,group by 和distinct 字段的数据全量shuffle,容易引发reduce端长尾,若一段脚本中出现多个count distinct,则数据膨胀N倍,长尾也是N倍。
优化方案:
去重字段组合到group by 字段中,打散分组聚合去重,然后统计group by 字段的数量。
select group_id
,app_id
,sum(case when 7d_cnt>0 then 1 else 0 end) AS 7d_uv, -- 7日内UV
,sum(case when 14d_cnt>0 then 1 else 0 end) AS 14d_uv --14日内UV
from (
select
group_id,
app_id,
user_id, --按user_id去重
count(case when dt>='${7d_before}' then user_id else null end) as 7d_cnt, -- 7日内各用户的点击量
count(case when dt>='${14d_before}' then user_id else null end) as 14d_cnt --14日内各用户的点击量
from tbl
where dt>='${14d_before}'
group by
group_id,
app_id,
user_id
) a
group by group_id,
app_id前面的内容中有过详细示例:https://blog.csdn.net/wsdc0521/article/details/117885554
二、动态分区写入数据倾斜
动态分区是指在往分区表里插入数据时,可以在分区中指定分区列,但不指定具体分区值,sql执行完才确定分区值,运行时动态批量写入。
当有K个Map Instance,N个目标分区,极端情况下会产生K* N个小文件。
MaxCompute对动态分区的处理是引入额外的一级Reduce Task,将同一个分区的数据,尽可能交给一个instance来处理写入,如有热点分区则发生长尾,优点是产生小文件少,但额外引入一级Reduce操作也耗费计算资源,因此如何保持着两者的平衡,需要认真的权衡。
若目标分区少,则没有小文件的情况存在,开启此功能不仅会增加资源浪费,还会降低性能,可以选择关闭此功能,反而可以提升性能。
-- 当reduce和动态分区数少的时候可以关闭,否则会生成大量小文件
-- 关闭此功能
set odps.sql.reshuffle.dynamicpt=false;三、GroupBy数据倾斜
数据倾斜引发的GroupBy聚合长尾,可采用groupby.skewindata参数优化:
set odps.sql.groupby.skewindata=true;优化原理为引入两级reduce
第一次shuffle key是group key和一个随机数(取模),将数据打散,多个reduce并发做部分聚合;
第二次shuffle key是group key,相同的key分发到同一个reduce做最终聚合;
四、ROW_NUMBER(计算TopN)
常用于取TopN的场景中,当数据量巨大时候,可以通过两阶段聚合,增加随机列或拼接随机数,将其作为分组中一参数,提升查询性能。
示例:
为使Map阶段中各分组数据尽可能均匀,增加随机列,将其作为分组中一参数。
SELECT main_id
,type
FROM (SELECT main_id
,type
,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn
FROM (SELECT main_id
,type
FROM(SELECT main_id
,type
,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn
FROM (SELECT main_id
,type
,ceil(10 * rand()) AS src_pt
FROM data_demo2
)
) B
WHERE B.rn <= 10
)
) A
WHERE A.rn <= 10;参数调优
一、Map端
--调整cpu数量,默认100,在[50,800]之间调整,一般无需改动
set odps.sql.mapper.cpu=100;
-- 当map阶段instance有wirte dumps,可适当增加内存
set odps.sql.mapper.memory=1024;
-- 设定一个map的最大数据输入量,调小该值可以增加mapper数量
set odps.sql.mapper.split.size=256;二、Join端
-- 调整cpu数量,默认100,在[50,800]之间调整,一般无需改动
set odps.sql.joiner.cpu=100;
-- 当join阶段instance有wirte dumps,可适当增加内存
set odps.sql.joiner.memory=1024;
-- 调整instance数量,默认-1,在[0,2000]之间调整
set odps.sql.joiner.instances=-1;三、Reduce端
-- 调整cpu数量,默认100,在[50,800]之间调整,一般无需改动
set odps.sql.reducer.cpu=100;
-- 当reduce阶段instance有wirte dumps,可适当增加内存
set odps.sql.reducer.memory=1024;
-- 调整instance数量,默认-1,在[0,2000]之间调整
set odps.sql.reducer.instances=-1;当日志看到dumps关键词,则说明出现了文件dump,若比较严重,可以适当调大内存参数,但不能太大,否则集群资源不足时,任务会一直排队等待资源。
当reduce无长尾时,但耗时长,可适当增大reduce并发数。
当map无长尾,但耗时长,可适当调小mapper.split.size的值,以增加mapper数量,提高并发。
希望本文对你有帮助,请点个赞鼓励一下作者吧~ 谢谢!