前言
之前一直鸽了yolov3-tiny的onnx模型修复,今天终于把最后一个bug解决了,如果想直接享受成果的,直接点我的github仓库下载,使用说明都写了,这篇文章呢主要是给大家分享一下思路和过程,希望能够启发更多的人。
必要说明
本文采用darknet权重直接转换onnx模型的方法。
1.没有用ultralytics的pytorch模型,因为那个采用了和yolov5一样的风格,中间涉及五维向量不适合部署。
2.没有直接下载onnx官方维护的model zoo里的yolov3 tiny模型,因为那个是动态尺寸,不是静态。
3.本文的模型修改了conv层和maxpool层的pad方式,因为部署过程中不支持auto_pad选项,需要固定pad。
4.网上能直接下载到的yolov3tiny的onnx有问题,无法推理出来,太老了,且需要caffee框架,详见需要修复的onnx。
5.本文的转换代码修改自tensorrt_demos里提供的yolo转onnx,如果没有像我一样的特殊需求,你只要把它下载替换掉我仓库里的yolo_to_onnx.py即可。因为模型精度会有所损失,详细对比见下图:
我修改后:

修改前:

修改代码
1.最开始我修改了maxpool的实现方式,原先是auto_pad=‘SAME_UPPER’,这里我引入一个count全局变量判断修改到第几个节点,因为不同节点的pads是不同的,需要if判断,这里是最后一个节点需要单独处理。
def _make_maxpool_node(self, layer_name, layer_dict):
"""Create an ONNX Maxpool node with the properties from
the DarkNet-based graph.
Keyword arguments:
layer_name -- the layer's name (also the corresponding key in layer_configs)
layer_dict -- a layer parameter dictionary (one element of layer_configs)
"""
global count #modify
count +=1 #modify
stride = layer_dict['stride']
kernel_size = layer_dict['size']
previous_node_specs = self._get_previous_node_specs()
inputs = [previous_node_specs.name]
channels = previous_node_specs.channels
kernel_shape = [kernel_size, kernel_size]
strides = [stride, stride]
assert channels > 0
#modify
if count !=6:
maxpool_node = helper.make_node(
'MaxPool',
inputs=inputs,
outputs=[layer_name],
ceil_mode = 0,
kernel_shape=kernel_shape,
strides=strides,
pads =[0,0,0,0],
name=layer_name,
)
else:
maxpool_node = helper.make_node(
'MaxPool',
inputs=inputs,
outputs=[layer_name],
ceil_mode = 0,
kernel_shape=[3,3],
strides=strides,
pads =[1,1,1,1],
name=layer_name,
)
#modify
self._nodes.append(maxpool_node)
return layer_name, channels
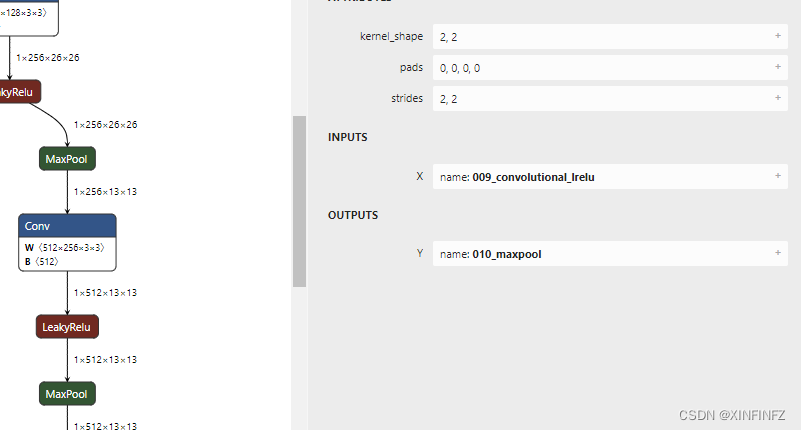
前五个节点,都是kernel_shape为2,2,pads是4个0,strides为2,2,这里可能有人想能不能用别的尺寸,事实上用别的组合也能对应上,但效果会差不少,并且可能延长推理时间。
第六个节点,即右边最后一个maxpool节点,是以下这样:

坦白的说,我自己也是靠试试出来的,首先strides不能大于kernel_shape,其次pads1,1,1,1和0,0,0,0比会多增加四行输出,具体加加减减得试过,我也尝试了前五个节点是3,3的kernel,最后是1,1,虽然能对应上但效果非常差,我猜应该是感受核的体积太小了。
2.修改conv层。其实修改1已经完成了修复的目的,但我不满足,因为我发现用厂家工具生成模型时尺寸突然缩水,怎么也对应不上,在排除了maxpool, leakyrelu的嫌疑后,还剩resize和conv层了,查阅手册,虽然厂家说支持auto_pad=SAME_LOWER,但我凭直觉觉得就是它有问题,于是修改了以下代码就可以运行了:
def _make_conv_node(self, layer_name, layer_dict):
"""Create an ONNX Conv node with optional batch normalization and
activation nodes.
Keyword arguments:
layer_name -- the layer's name (also the corresponding key in layer_configs)
layer_dict -- a layer parameter dictionary (one element of layer_configs)
"""
previous_node_specs = self._get_previous_node_specs()
inputs = [previous_node_specs.name]
previous_channels = previous_node_specs.channels
kernel_size = layer_dict['size']
stride = layer_dict['stride']
filters = layer_dict['filters']
batch_normalize = False
if layer_dict.get('batch_normalize', 0) > 0:
batch_normalize = True
kernel_shape = [kernel_size, kernel_size]
weights_shape = [filters, previous_channels] + kernel_shape
conv_params = ConvParams(layer_name, batch_normalize, weights_shape)
strides = [stride, stride]
dilations = [1, 1]
weights_name = conv_params.generate_param_name('conv', 'weights')
inputs.append(weights_name)
if not batch_normalize:
bias_name = conv_params.generate_param_name('conv', 'bias')
inputs.append(bias_name)
#modify
if kernel_shape == [3,3]:
pads = [1,1,1,1]
else:
pads = [0,0,0,0]
#modify
conv_node = helper.make_node(
'Conv',
inputs=inputs,
outputs=[layer_name],
kernel_shape=kernel_shape,
strides=strides,
pads=pads, #modify
dilations=dilations,
name=layer_name
)
self._nodes.append(conv_node)
inputs = [layer_name]
layer_name_output = layer_name
后面太长不复制了,还是一样改了pads的方式,只不过这次做了一个非常短的判断语句,因为我发现在我之前转换好的yolov4tiny中有和yolov3tiny一样的右侧结构,其中kernel_shape为3,3时pads总为1111,而2,2时总为0000。
总结
之前在yolov4tiny的转换中,使用onnxsim简化了模型,从而避开了无法转换的算子,但这次onnxsim却没法生效,只把BN层简化掉了,在这种情况下,了解算子的具体运行情况就非常必要,需要自己重新导出调试,不能指望在别人生成好的onnx模型上进行修改。