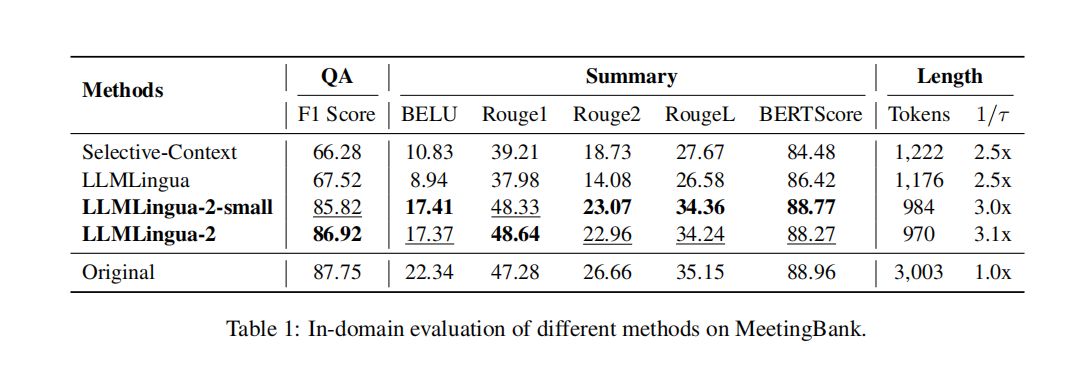
📸背景
因长期在大模型相关的部门工作,每天接收到很多和AI相关的信息,但小编意识到目前理解到的一些AI知识还有些片面。
恰逢稀土掘金开发者大会有谈到大模型相关的知识,于是借此机会,对大模型相关的一些知识再了解一波~
以下文章是对 大模型与AIGC分论坛 第一部分的整理与归纳。
一、💡大语言模型及PaLM2介绍
1、大语言模型可以做什么
下面先来说说,我们在用大语言模型可以干些什么。
(1)常见使用场景
- 娱乐 —— 游戏公司用大语言模型做
NPC的输出,让NPC能够跟我们自然地对话。(NPC指的是非玩家对话) - 工作助理 —— 帮我们执行任务,通过不同的方式去搜索、去计算,去执行一些业务的交易。
- 知识库 —— 可以作为一些自有的知识库,或者结合企业内部的知识库,去海量的知识中帮助我们检索有用的信息,帮助我们去更好地完成工作。

(2)LLM → LDM
我们说大语言模型是LLM,但实际上也可以说它是LDM,也就是让语言驱使大模型去完成我们一些实际上的任务。
比如: ①类似siri,用语言控制AI做事;②描述画图场景,让AI帮我们画出想要的图形。③……

(3)加快原型设计
除此之外,大语言模型可以极大得加快我们的工作速度,让我们的工作更集中于创意和想法,而不是琐碎的重复工作。比如说:我们在写一篇文章,里面有一块内容需要用到一张柱状图。
如果是传统的方法,我们需要去打开画图软件,一线一点的画出来。而如果把这个“画柱状图”的事情,交给大语言模型来处理,只需简单几句话,就让LLM帮我们把图画出来。这样,就能让我们把精力都专注于创意和想法,减少很大一部份的机械性工作和重复工作。

2、PaLM2的纸短情长
那么用什么工具来加快原型设计呢,这里就谈到了PaLM2。
(1)PaLM 2
- LLM ——
PaLM 2是google最新的通用大语言模型,全称为Pathways Language Model。 - 540-billion —— 这意味着
PaLM2模型是一个非常大的模型,具有5400亿的参数。参数的数量通常与模型的复杂性和能力成正比。更多的参数意味着模型可以学习和存储更多的信息,但同时也需要更多的数据和计算资源来训练。 - 稠密的纯解码器Transformer结构 ——
Transformer是一种深度学习模型架构,广泛用于自然语言处理任务。"稠密的解码器"意味着Transformer架构中,解码器部分是稠密连接的,这有助于模型更好地处理和生成文本。 - 基于
Pathways系统来训练 —— Pathways系统是Google用于训练其大型模型的新系统或框架,而PaLM2,就基于这个系统来进行训练。
(2)PaLM2对外商务场景
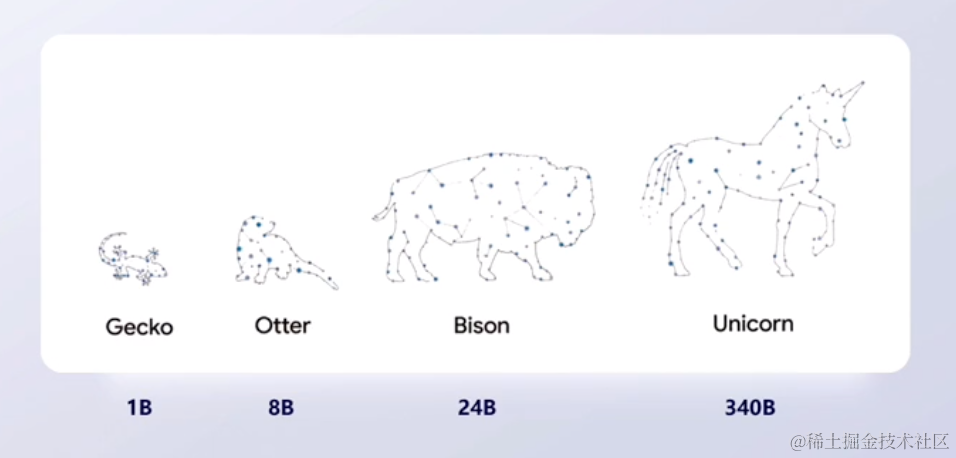
对外提供商务场景有4种不同的版本:
- Gecko —— 壁虎模型,只有
1B的参数,它更多的是在移动设备上进行应用,比如在手机上做文本的生成。 - Otter —— 水獭模型,具有
8B的参数。 - Bison —— 野牛模型,
Bison是目前google对外商用的主流模型,具有24B的参数。目前Google Cloud以及developer,都是通过Bison,来提供文本生成、对话交流等任务。 - Unicom —— 独角兽模型,具有
340B参数。像是一些专有领域的模型,比如下方第二张图:Med-PaLM2。它是医疗领域的一个知识问答库。像这样的专有领域的场景,就会使用最大的独角兽模型,来提供支持
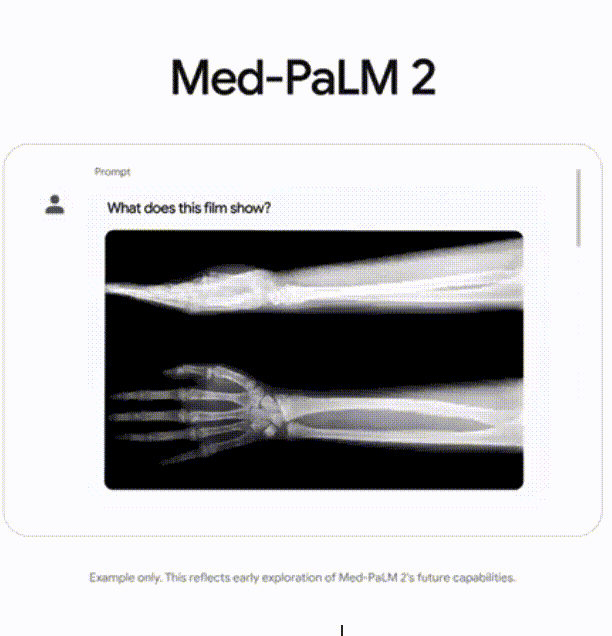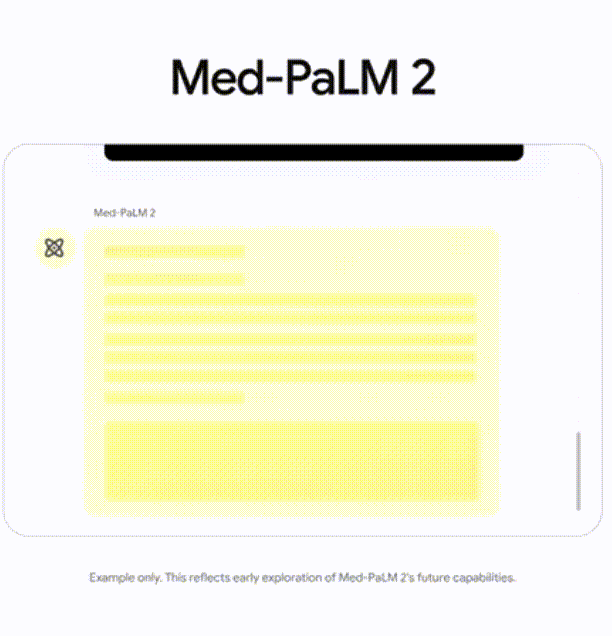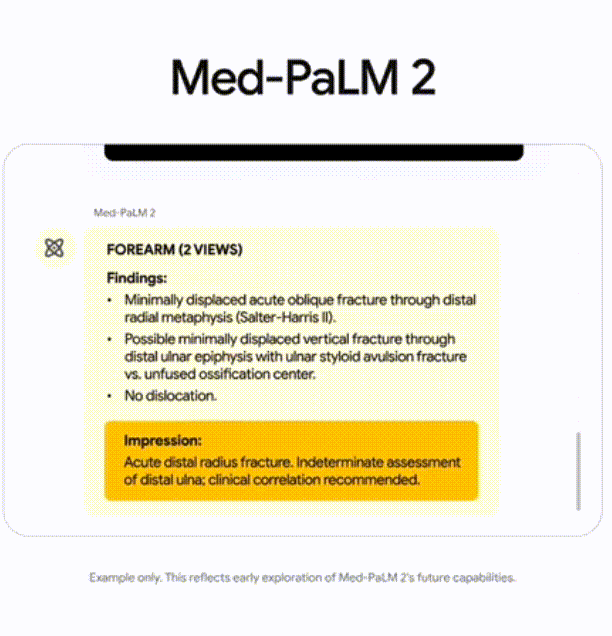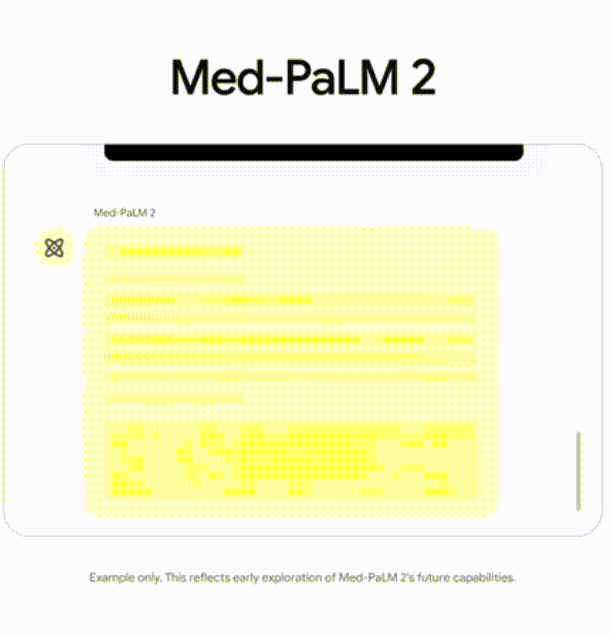
(2)Google Cloud 大语言模型应用平台
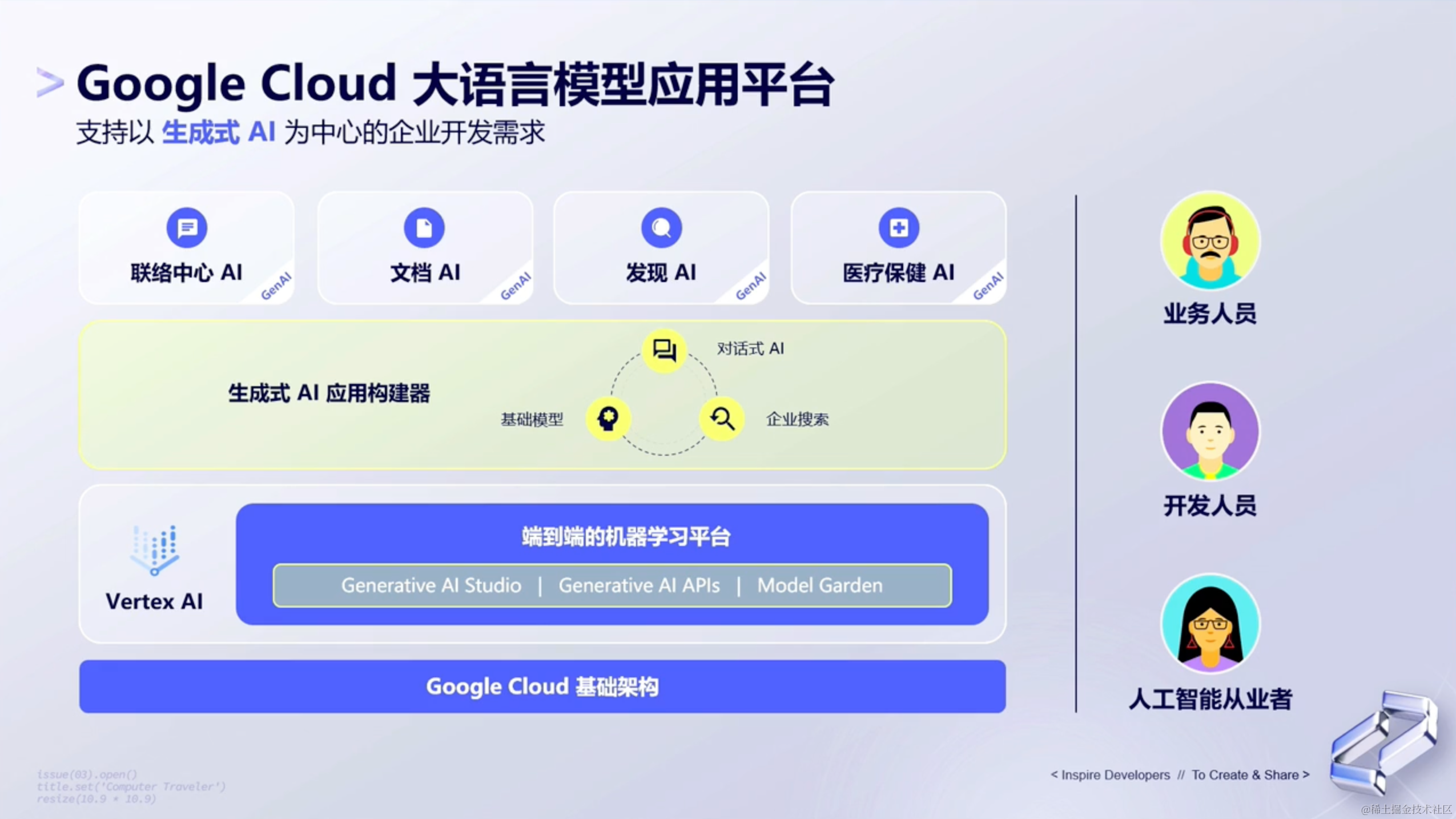
对于大语言模型来说,Google通过Google Cloud这样的一个平台,来提供大语言模型的对外商务能力。
这个平台支持从最底层的基础架构(为人工智能从业者服务)到顶层的模型应用(为业务人员服务),针对不同的人群,提供不同的服务。
(3)Generative AI Studio
而对于PaLM2来说,通过Google Cloud中的Generative AI Studio工具,来提供一些PaLM2对外的商业能力。那PaLM2都提供了哪些对外的商业能力呢?如下图所示:

二、📟提示词工程
1、模型类别
模型类别分为三种,如下图所示:

对于上面这三种模型来说,通用语言模型、指令微调模型和对话微调模型是基于相似的基础模型,但它们在微调和使用方式上有所不同,那它们之间的主要区别是什么区别呢?如下所示:
通用语言模型 (GPT):
- 这是一个预训练的模型,它可以生成连贯的文本。
- 它没有经过特定任务的微调。
- 用户可以直接输入文本,模型会返回生成的文本。
指令微调模型:
- 这个模型是在通用语言模型的基础上,经过特定任务的微调得到的。
- 用户需要给模型一个明确的指令,例如“翻译以下文本到法语”。
- 模型会根据给定的指令执行特定的任务。
对话微调模型:
- 这也是一个经过特定任务微调的模型,但它是为对话设计的。
- 用户可以与模型进行交互式对话。
- 模型会记住对话的上下文,从而更好地回应用户。
总的来说,这三种模型都是基于相同的基础模型,但它们在微调和交互方式上有所不同。指令微调模型和对话微调模型都是为了更好地完成特定任务而进行的微调,而通用语言模型则更加通用。
2、PaLM2在文本和对话上的应用
(1)PaLM模型 - 文本和对话
PaLM2具有强大的文本能力,具体应用表现在:
- 文本生成:
PaLM 2可以根据给定的提示生成连贯且与上下文相关的文本。这可以用于内容创建、故事写作等。 - 文本摘要:给定一个冗长的文章或文档,
PaLM 2可以提供一个简洁的摘要,捕捉内容的主要要点和精髓。 - 翻译:
PaLM 2可以用于将文本从一种语言翻译成另一种语言,帮助打破语言障碍。 - 问答:您可以使用
PaLM 2根据提供的上下文或一般知识回答问题。 - 情感分析:分析文本背后的情感或情绪,例如确定评论是积极的、消极的还是中性的。
- 文本分类:将文本分类到预定义的类别或主题中。
- 命名实体识别:识别并分类文本中的命名实体,如人名、组织名、地点名等。
- 代码生成:给定特定的任务描述,
PaLM 2可以生成代码片段或解决方案。
除了强大的文本能力外,PaLM2还拥有超强的对话能力,具体应用表现在:
- 多轮对话:
PaLM2可以进行连续的对话,处理多轮的用户输入。 - 使用插件:
PaLM2可以与各种插件进行交互,如KAYAK、WebPilot和show_me_diagrams等,以提供更丰富的功能。 - 代码执行:
PaLM2可以执行Python等各种语言的代码,帮助用户解决编程问题或进行计算。 - 多语言支持:尽管
PaLM2主要是英文模型,但它也支持其他语言,如中文、法文、德文等。 - 任务指导:用户可以给
PaLM2提供具体的指导,指导模型如何回应。 - 系统消息:可以使用系统消息来为对话设置上下文,帮助模型更好地理解用户的需求。
当然以上这只是PaLM 2文本能力的许多应用中的一部分,该模型在各种领域和行业中都有广泛的应用。

(2)PaLM模型:Demo
下面来看下PaLM2平台的demo展示:
3、Prompt
上面谈到了PaLM2的文本和对话能力,接下来,我们来说下大模型里面最重要的能力,也就是提示词。
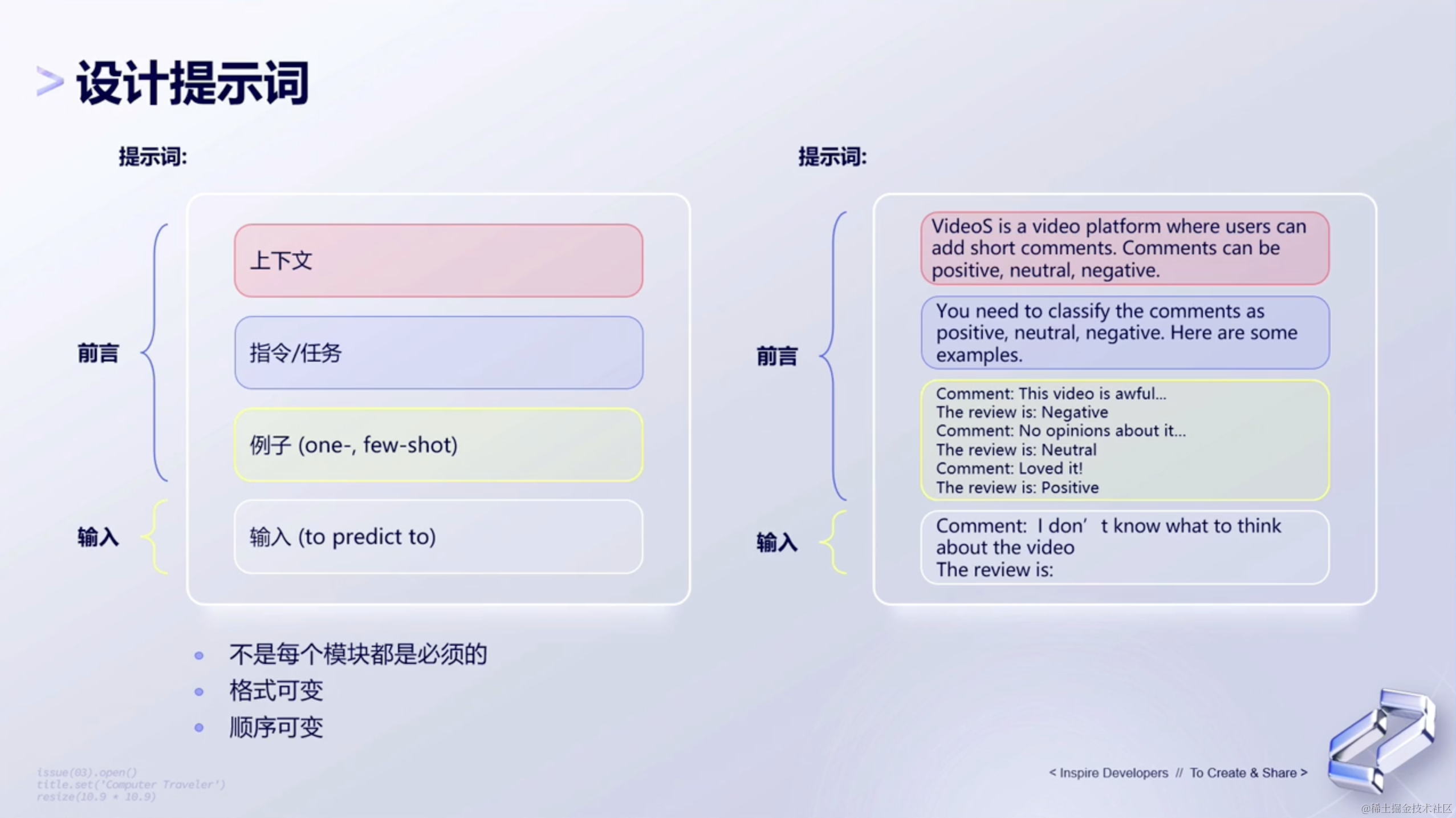
(1)设计提示词
首先是设计提示词。对于大语言模型来说,设计提示词是一个关键的步骤,因为它决定了模型的输出质量和相关性。下面列举出一些建议和方法:
- 明确目标 —— 首先,你需要明确你想从模型中获得什么样的回答。例如,如果你想要一个定义,你可以使用“什么是…?”这样的提示。
- 详细描述 —— 尽量提供详细的上下文和信息。例如,而不是简单地问“苹果的颜色是什么?”,你可以问“红富士苹果的颜色是什么?”。
- 使用多种提示 —— 尝试使用不同的提示词来获得不同的答案,这可以帮助你找到最佳的提示词。
- 指导模型的输出格式 —— 如果你想要特定格式的答案,如列表、段落或标题,可以在提示词中明确指出。
- 迭代和优化 —— 基于模型的回答,不断调整和优化你的提示词,直到获得满意的结果。
- 避免模糊或歧义 —— 确保你的提示词是清晰和具体的,避免任何可能导致模型混淆的歧义。
- 使用温和的引导 —— 如果你不确定模型是否理解你的问题,可以先给出一些背景信息或使用温和的引导词。
- 测试和验证 —— 在实际应用中,建议对不同的提示词进行测试和验证,以确保模型的输出是准确和相关的。
综上,设计提示词是一个迭代的过程,需要根据模型的反馈不断调整和优化。
(2)提示词手段
提示词手段是指在与大型语言模型交互时,使用的一系列技巧和方法来引导模型生成期望的输出。常见的提示词手段有:指令、自洽、思想链等等。那下一环节,就列举出三种基础提示词和六种进阶提示词给大家作为参考。
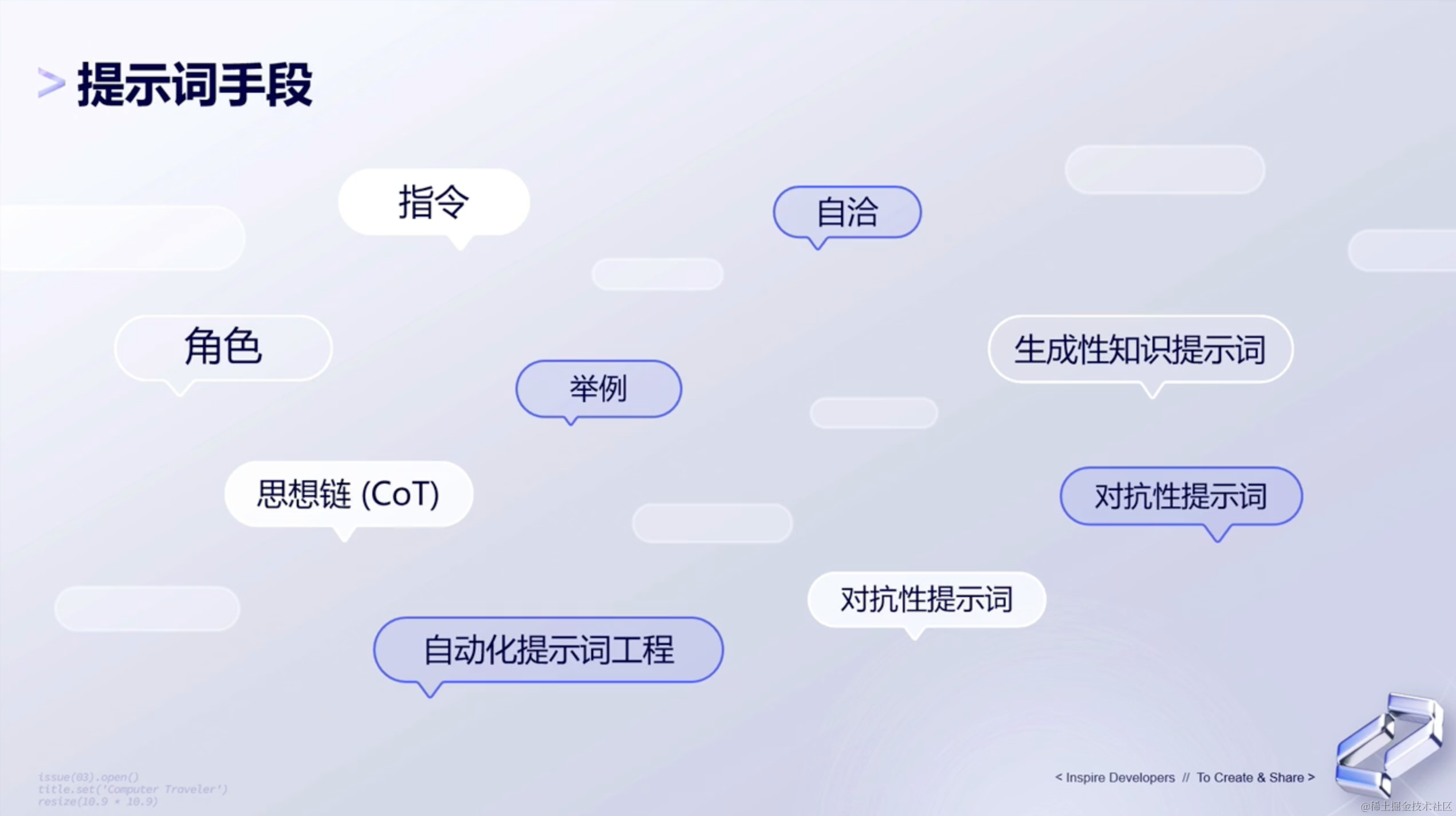
4、三种基础提示词
(1)简单的提示词
最简单的提示词有两种类型:指令形式和角色形式。具体形式如下:
- 指令形式: 指的是给模型一个输入,然后它根据自己的理解,返回一个输出。
- 角色形式: 让模型扮演一个角色,然后再给输出。

(2)举例子
第二种方式是举例子提示词。这种类型的提示词,通常我们会先给模型一个例子,然后让模型根据例子,去输出用户想要的效果。下面给出了三种举例子的方式:零样本、一个样本和少量样本。

(3)思想链
思想链提示词(Chain-of-Thought CoT),指的是通过一系列相关的词汇或概念,形成一个逻辑上连贯的链条,帮助人们回忆或联想到某个特定的信息。这是一种比较常见的提示词手段,很多用户都会用CoT这样的一种形式,让大语言模型给出一个更好的输出。
这里介绍Google Research所发表的两种思想链形式:
- Few-shot CoT(小样本) —— 通过
few-shot的方式告诉模型,应该怎么更好地去做推理; - Zero-shot CoT(零样本) —— 这种形式是
Let's think step by step,旨在告诉模型,让模型需要一步步思考,一步步地给出公式,最后推理出最终的答案。

5、进阶提示词
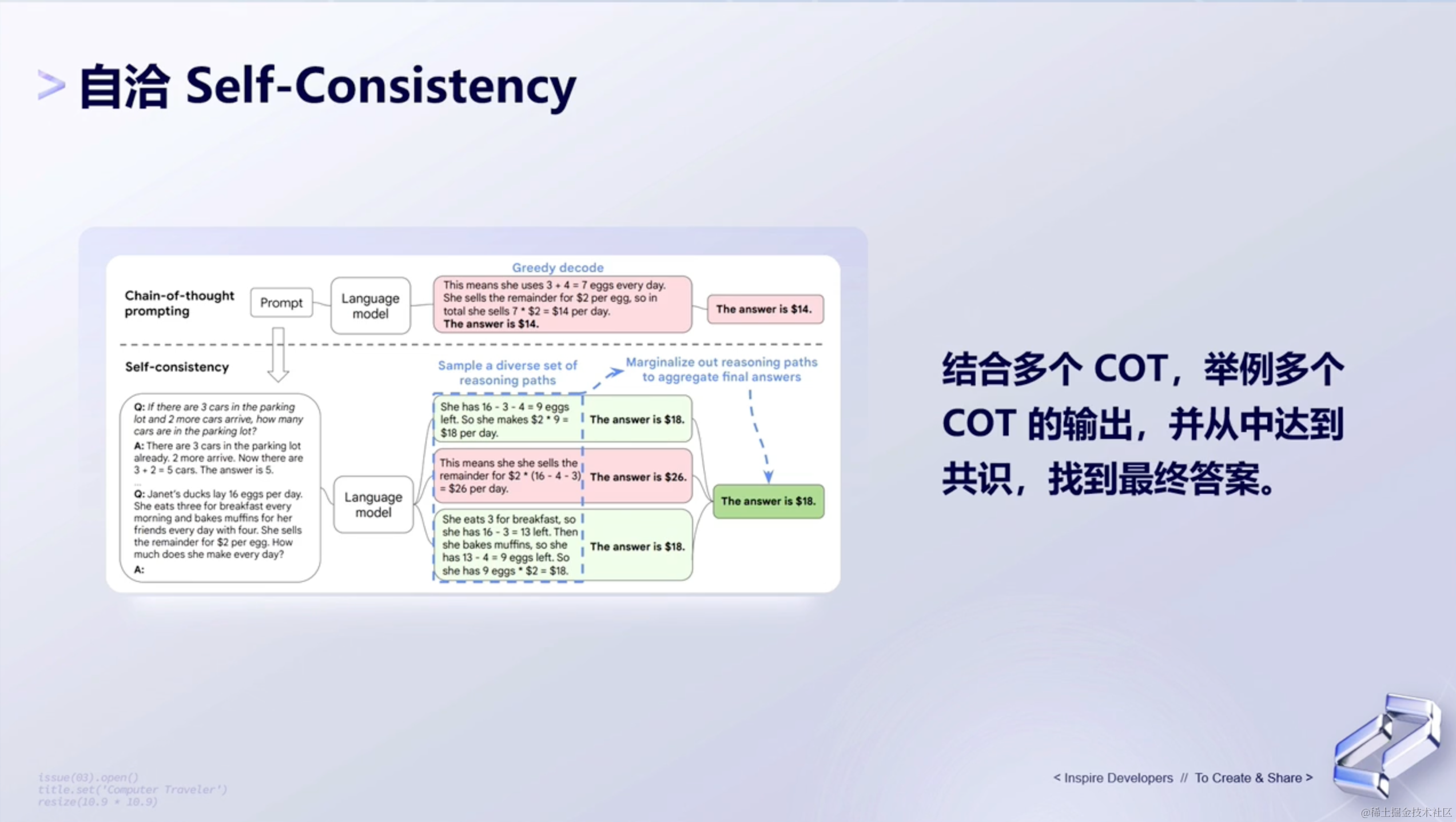
(1)自洽Self-Consistency
自洽,表示的是:在一个情境或故事中,所有的信息都是一致的,没有矛盾,这种一致性可以帮助人们更容易地回忆或理解信息。
对于PaLM2来说,它的自洽,并不会像传统贪婪解码greedy decode直接输出最终结果的形式,而是会对用户的输入有一些随机性,让模型基于chain-of-thought 的随机性,输出多个不同的答案。
对于这多个不同的答案,会相当于去投票,选出概率最高的答案做最终的输出。
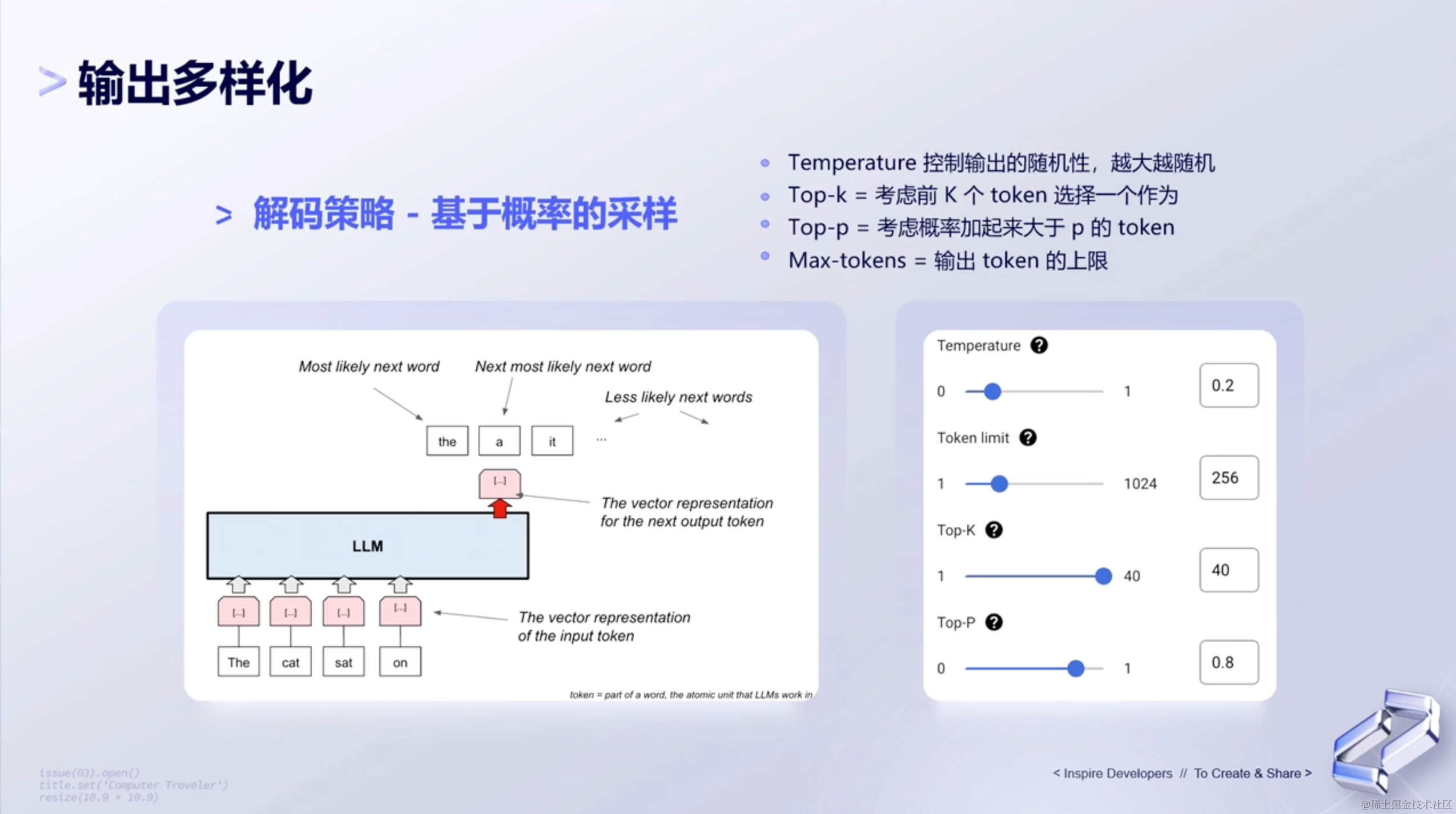
(2)输出多样化
“输出多样化”指的是在给定的输入条件下,模型或系统能够产生多种不同的输出结果。这种多样性可以帮助模型或系统更好地适应不同的情境和需求,提供更加丰富和多样的响应。
也就是说,我们可以自己设定一定的条件,让模型根据用户所选择的条件,来生成答案。
说了这么多,那如何保证输出的多样化呢?
我们可以通过调整temperature、top-k和top-p的值,来让模型根据我们所调整的条件,生成对应的答案。其中,temperature 用来控制随机性,top-k 和 top-p 控制候选池的大小。
(3)最少到最多提示
最少到最多提示,有以下两步策略👇🏻:
- 查询大语言模型,将当前任务分解成多个子问题。
- 按顺序在大语言模型中进行查询,使用前一个子问题的输出来解决下一个子问题。
看起来有点抽象,具体表达的是什么意思呢?具体如下:
- 将一个大任务分解成多个子任务,对每一个子任务去基于大语言模型给出输出,给出答案,之后再把这个答案贴给大语言模型,然后基于原始的
instruction,再加上现在子问题的答案,让大语言模型给出最终的答案。 - 提供多步策略,分解,再加上按步去执行,最终生成的一个答案。
- 这也是很常见的一种方式,社区里有很多大语言模型都在用这种方式,去一步步的调用
function或者plugin,去生成最后的答案。

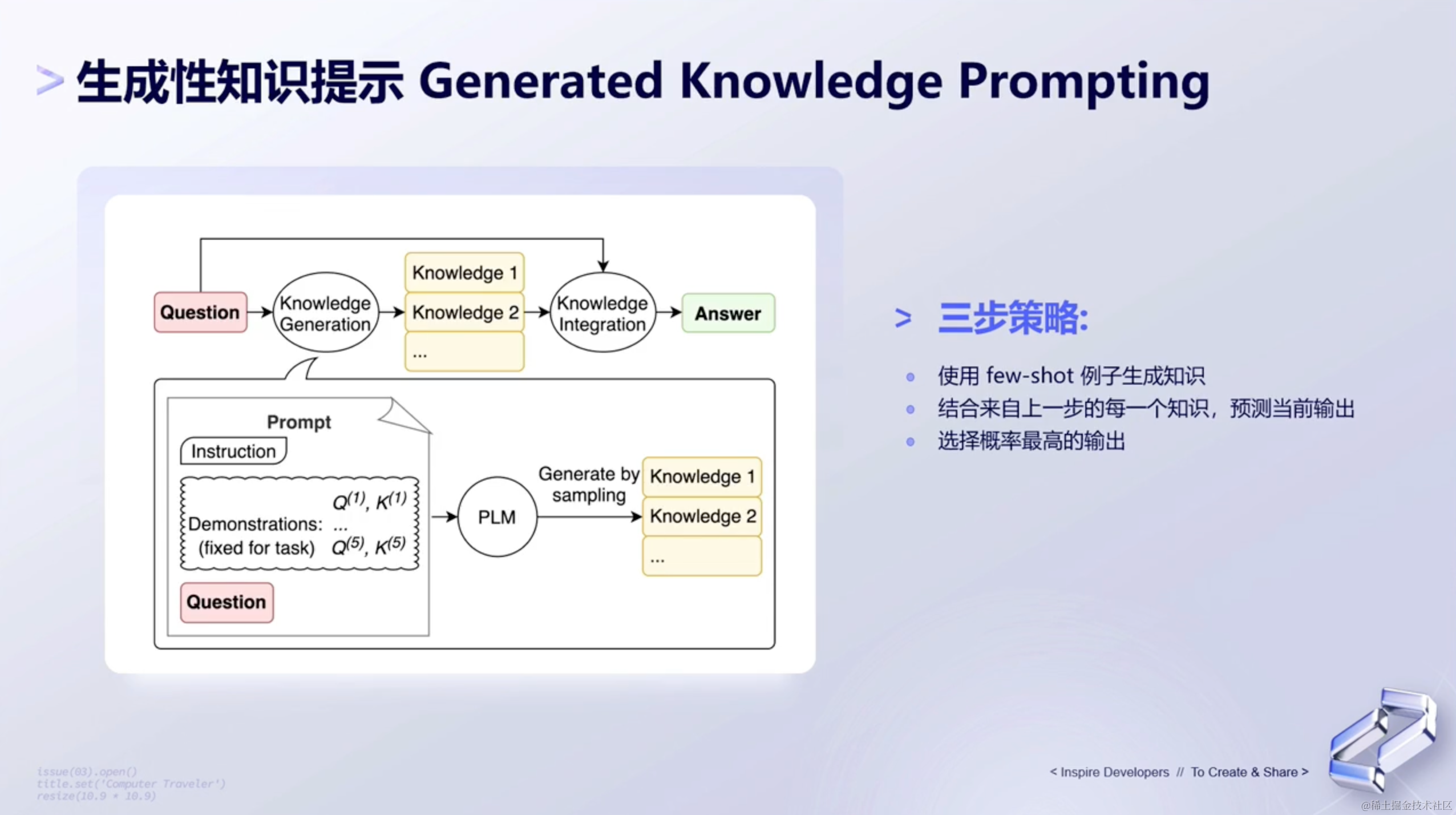
(4)生成性知识提示
生成性知识提示,指的是模型会选择概率最高的来做输出,这是来自其它研究机构所发表的提示词方式。
这种prompt方式,旨在基于当前的问题用大语言模型先生成一些knowledge,然后基于这些knowledge bullet,继续喂给到大语言模型。之后大语言模型去结合我们往后提问的问题,去生成不同的答案。
对于最终的答案,LLM会找出一致性最高的或者概率最高的,或者是投票最多的答案,作为最终的输出。
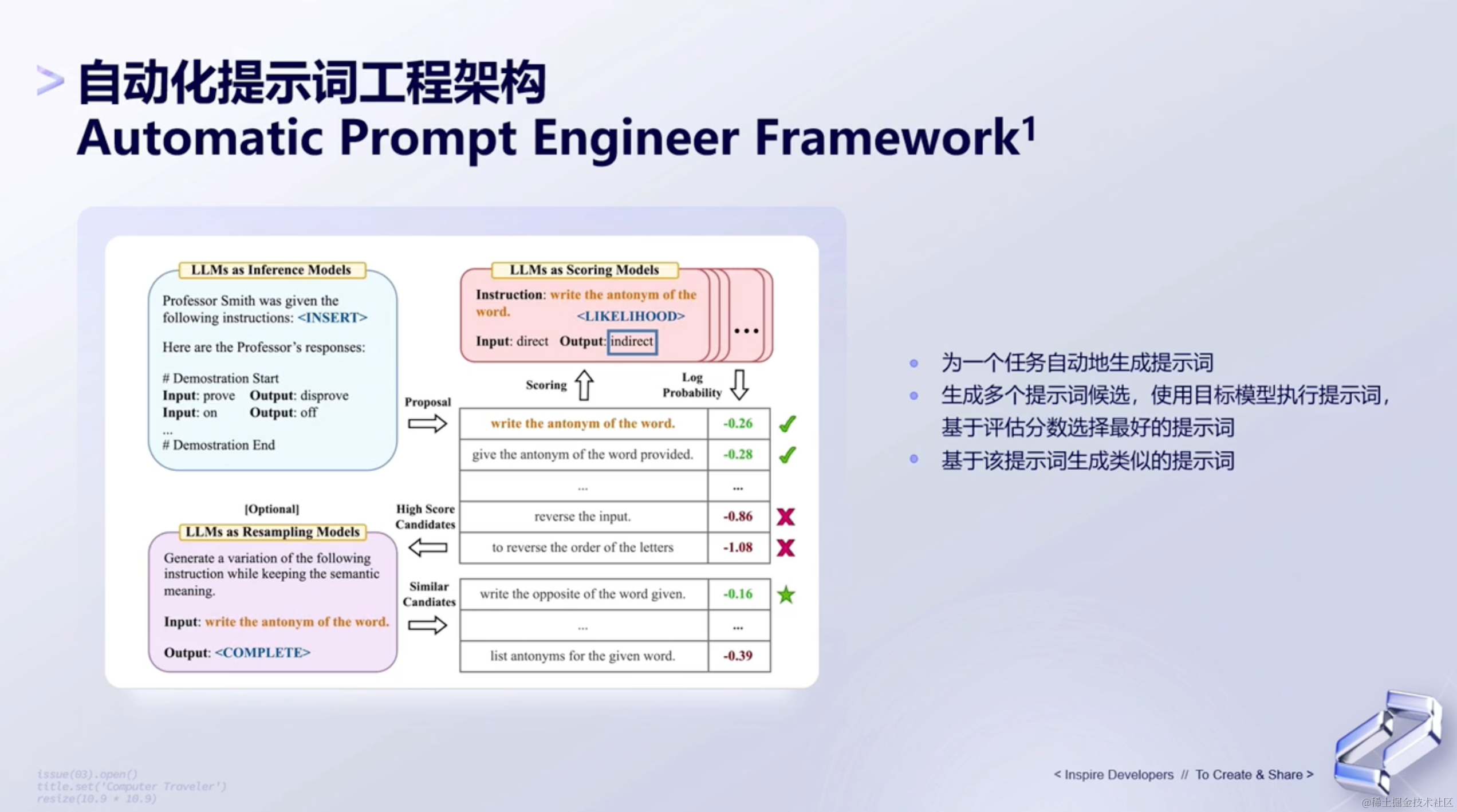
(5)自动化提示词工程架构
自动化提示词,其实就是想让大家有技巧的去输入。它不是让我们自己去优化提示词,而是让大语言模型自动地去生成和优化提示词。具体怎么操作呢?具体如下:
- 先用过一个大语言模型,按照我们描述的任务,生成提示词。
- 再通过另一个大语言模型,去基于提示词给出结果。判断结果的好坏,按排序找出最好的提示词。然后去扩展这个提示词,完成我们最终对提示词的构建。
(6)对抗性提示词
当我们面对一个商业应用的时候, 一个安全性的保证是很重要的。比如用户可能会问:什么什么产品的序列号,什么什么产品的秘钥。用户有可能会通过以下三种方式去提问模型:
- 提示词注入 —— 提示词通过改变行为来尝试攻击模型
- 提示泄漏 —— 提示词尝试获得提示词和模型的机密信息
- 越狱 —— 提示词尝试越过安全审核功能

那模型要怎么样去对抗一些不合理的需求呢,面对对抗性的问题,该如何解决呢?有以下三个建议:
PaLM2自己本身会有一个提示词,去指示这个模型的任务。然后PaLM2会把这些提示词做一个包装,对用户再暴露出来一个更简单的接口。那么PaLM2给到用户的输入,其实是有像三明治这样的防御的方式。前面有提示词,后面也有提示词。以达到让这个接口去针对用户的提示词,做一些检测和输出的屏蔽等等。通过这种形式,去防御用户想要去攻击这个模型的一些行为。- 第二种是包括
Google在内会经常用到的,为了安全审核,会去对输入还有输出,都会通过一些安全审核,再去做一些内容审核,即content moderation,去检测一些文本的合规性。包括一些合理性、版权的侵权性等等,然后通过模型的叠加,能够强制性让模型保证有安全性的输出,而且不被提示词所影响。 - 通过
Fine-Tuning、Prompt-tuning等方式,能够让模型的输出是更加符合我们的要求的。

7、总结
最后,我们来说下提示词从哪里开始呢?分成五步:
- 如何开始呢? —— 比如说,拿到
generative ai studio,基于PaLm2的这个模型,我们就先一点点地去设计这个提示词。 - 精确 —— 可以让它去按照一个角色,通过一系列的训练,去给出输出。
- 一次问一个任务 —— 同时,还要让模型尽量少地执行任务,一次性不要问太多,这样能得到更准确的答案。
- 避免冗长 —— 避免有过于冗长的提示词,包裹提示词的允许也是会有影响的。
- 分解成简单任务 —— 因此,我们可以去实试验不用的组合,找到合理的提示词。

三、📡微调模型
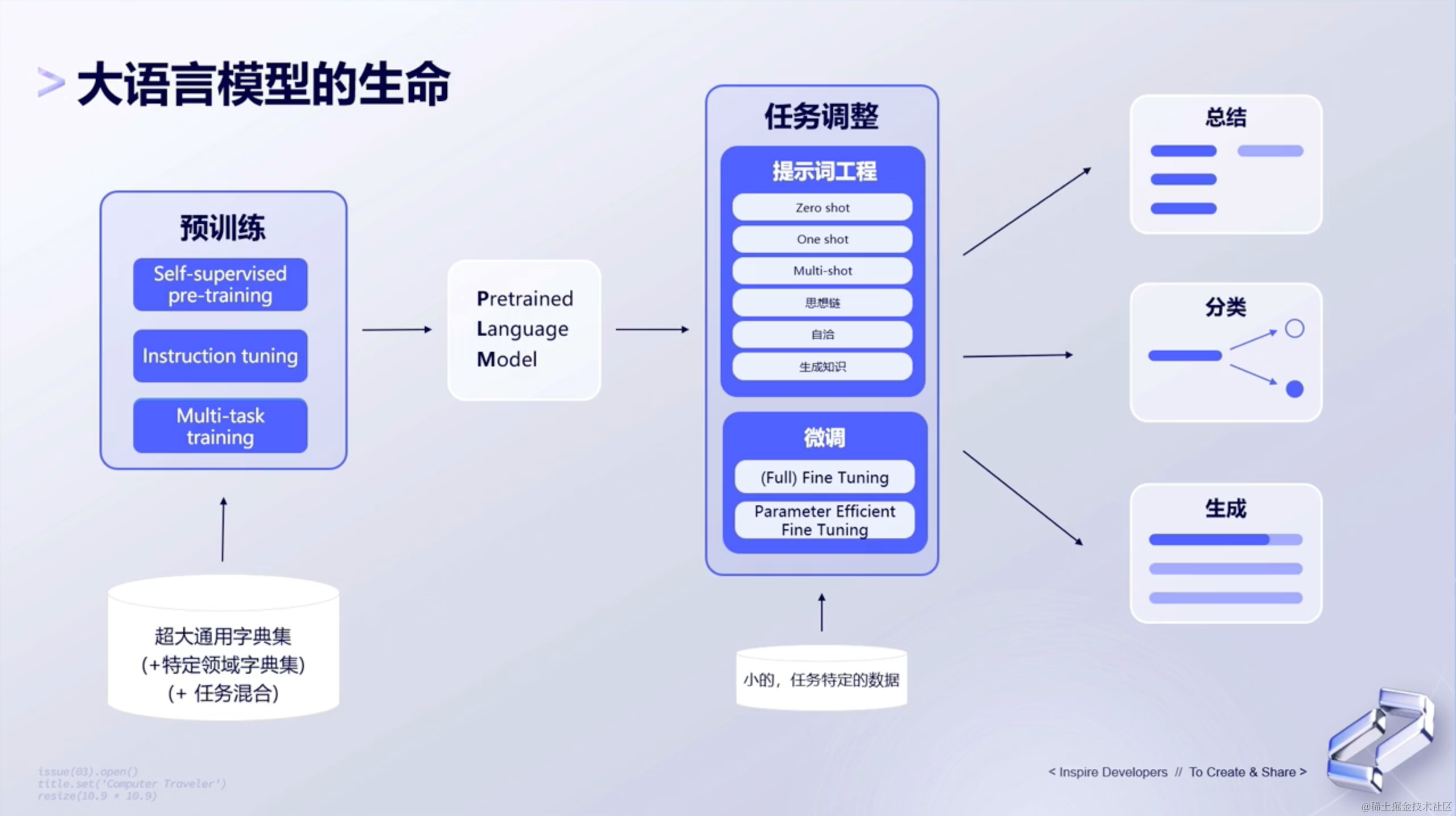
1、大语言模型的生命
我们从下图的左下角开始,一步步剖析。
首先,我们需要有训练数据,可以把这些数据理解为左下角的超大通用字典集。这些字典集可能来源于百度、google或者各大网站的数据,也可能是某一个特定领域的数据,比如:医疗领域。
然后呢,有了预训练数据后,下一步就要进行预训练了。预训练有三种形式:自我监督预训练、指令调优、多任务训练。通过这几种预训练方式先把数据进行第一遍训练,训练完成之后,就得到Pretrained Language Model,也就是通过预训练完成的模型。
接下来,需要对预训练好的模型,通过提示词工程和微调的方式,对整个模型任务做调整。除此之外呢,有时候后可能提示词工程和微调不能满足用户自己的需求,那么我们还可以在倾入一些少量的、特定的数据给到模型,让模型做进一步的任务调整。
最后,模型训练完成啦!我们可以用这个模型来帮助我们总结、分类和生成我们想要的东西。
2、调整语言模型适应下游任务
为了去Fine-tuning模型,我们会有几种方式。
(1)few-shot形式
首先第一种是最简单的,通过few-shot的形式。对于这种形式来说,我们并没有真正去Tune这个模型,而是给了它一些例子,让模型知道怎么去输出。
- 但这个就比较有局限性,它并没有真正的去改变这个模型,而且可能用户给模型的例子也是比较有限的。

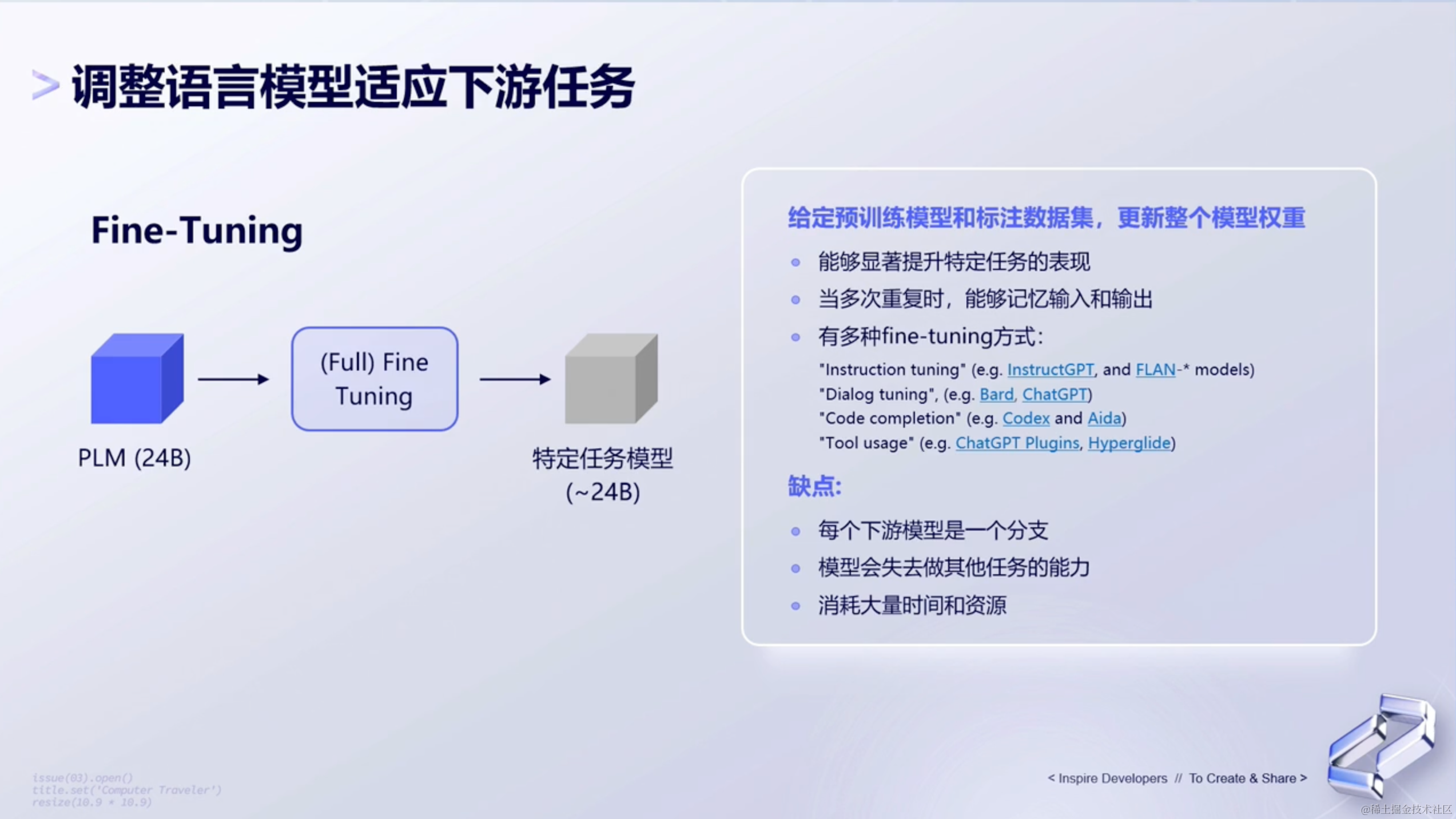
(2)full-fine-tuning
第二种是真正的fine-tuning,即full-fine-tuning。
比如说去训练整个拥有24B参数规模的模型,那么在训练的时候,且我们通过多次fine-tune去训练模型的时候,模型就能很好的去训练这个任务,甚至说能记忆我们给到的输入和输出,去完成专有的任务。这样的情况下模型就能够很好的实现我们上面说到的各种提示词的任务,包括一些保护能力。
但是呢,局限性在于:
- 比较耗时耗资源,有时候我们可能需要花好几天的时间才能tune完。
- 包括说它可能也会失去一些对于其他语言任务的执行能力。
所以现在,包括Google在内的一些厂商,会用到Parameter-Efficient Tuning这样的一种方式,去训练模型的一部分。
或者通过训练adapter-model,然后把这个adapter-model,跟大模型拼接在一起,让小模型去完成大语言模型的一些调整。
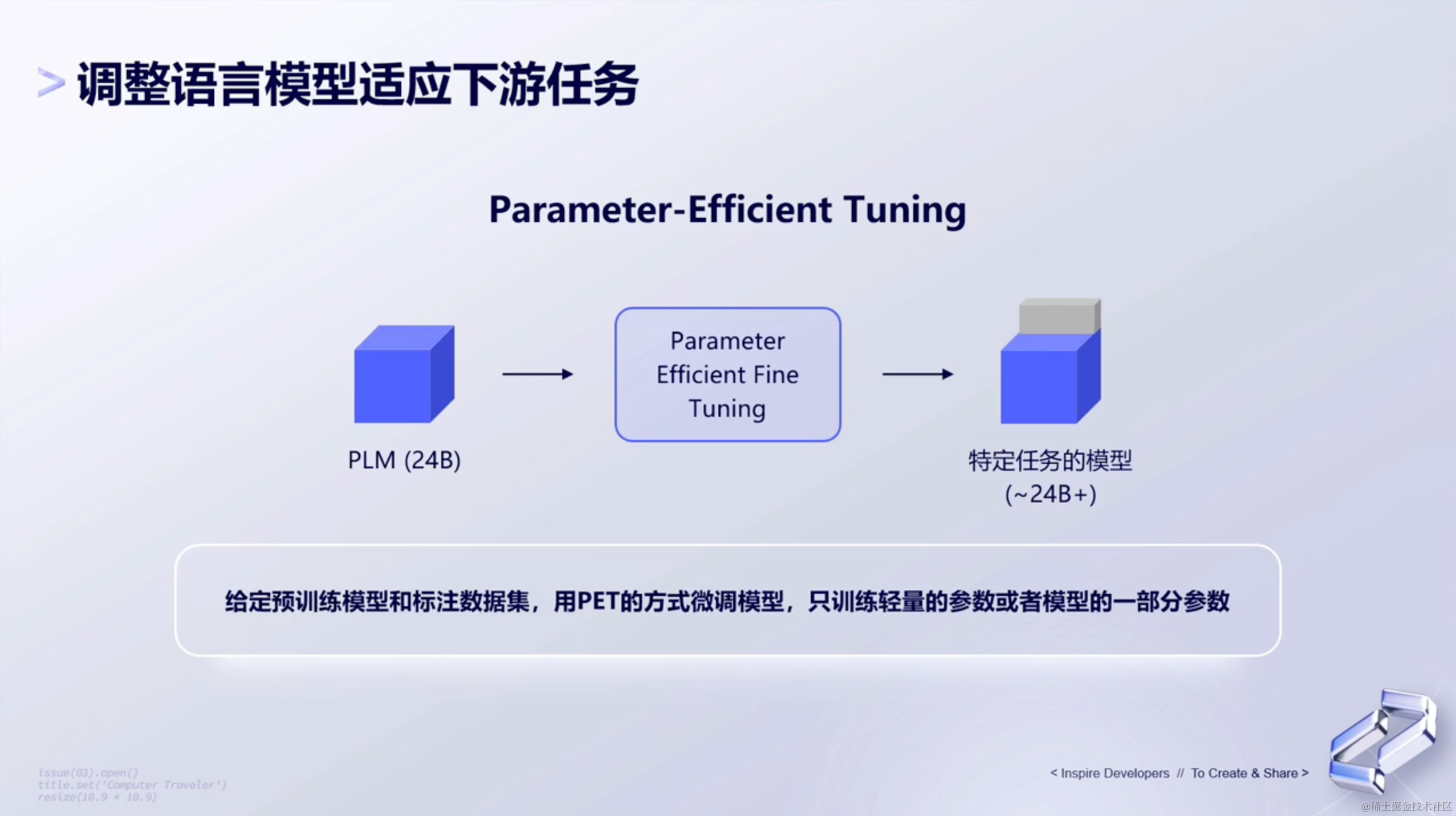
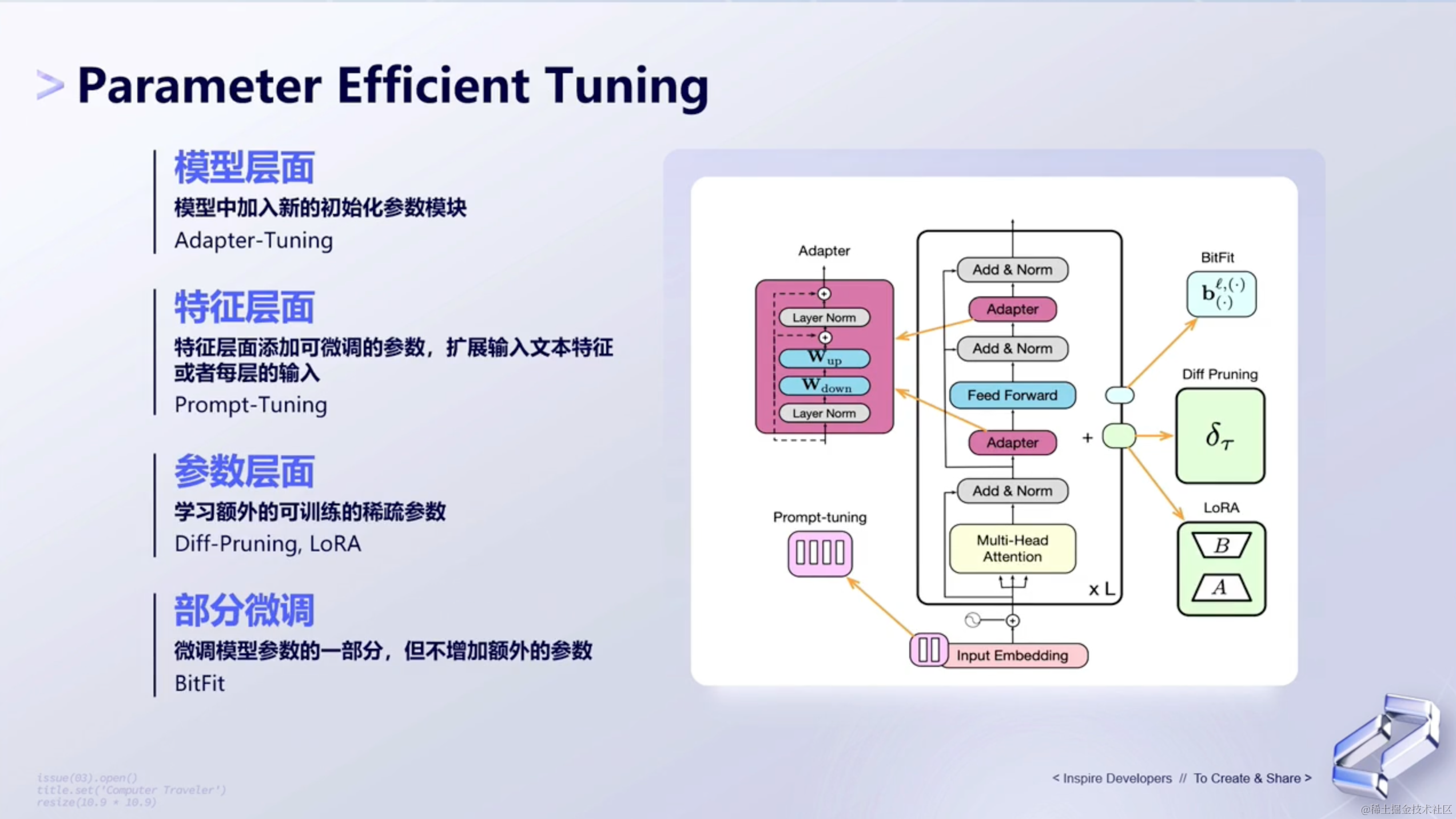
3、Parameter Efficient Tuning
Parameter Efficient Tuning,简写为PET。它是一种用于在不需要微调所有模型参数的情况下,有效地将预先训练的语言模型 (PLM) 适应各种下游应用的方法。它基于预训练大模型训练出垂直领域模型。具体做法是在预训练大模型的基础上,利用特定领域的数据微调模型,以得到在特定领域性能更优的模型。
那从研究层面来讲,PET包括了多种不同的算法,并且在不同的层面去做调优。
(1)模型层面
模型层面如何做到调优呢?如下所示👇🏻:
- 在
transformer结构或者decoder结构里面,加了adapter层,如下图中粉红色的这一列。 - 在这个里面我们会有两个初始化参数的模块,我们去训练这两个模块。
(2)特征层面
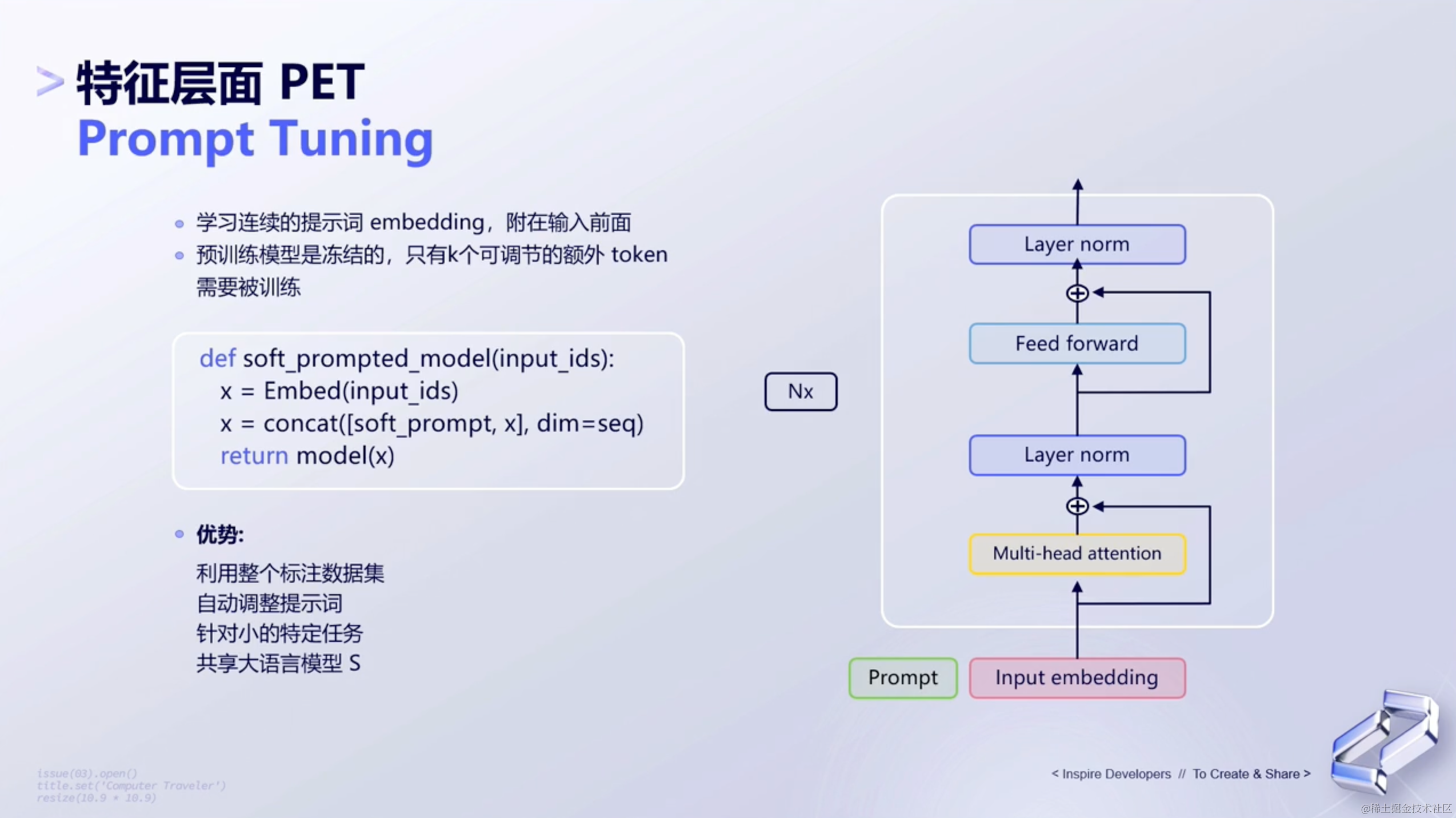
特性层面如何调优呢?如下所示👇🏻:
- 特征层面调优相当于在特征层面去做一个模型,这种方式也对应
Google Research提出来的一种算法:提示词调优Prompt Tuning。 Prompt Tuning是一种在预训练语言模型(Pre-trained Language Model)中利用提示词(Prompt)进行微调的方法。它的核心思想是在输入序列中加入特定的提示,以引导模型产生所需的输出。- 在
Prompt Tuning中,首先将输入的文本序列改写为包含提示的形式。例如,如果要预测一个句子"The cat sat on the mat."的下一个单词,可以将输入改写为"[MASK] sat on the mat.",其中[MASK]作为一个占位符,表示需要预测的单词。 - 接下来,将包含提示的输入序列通过预训练模型的编码器进行编码,得到输入嵌入标识,也就是
Input Embedding。在这个阶段,模型会尝试学习提示词所对应的知识或任务,从而调整其内部参数。 - 然后,将经过
Prompt编码后的嵌入标识输入到预训练模型的解码器部分,通常会采用一些fine-tuning的方式(如MAE、MAML等)进行微调。这些微调方法会根据特定的任务或数据分布来调整模型的参数,从而使得模型能够更好地适应特定领域的任务。 - 总的来说,
Prompt Tuning通过在输入序列中加入特定的提示,引导预训练模型学习所需的知识或任务,并利用一些fine-tuning方法对模型参数进行调整,从而实现高效的微调。
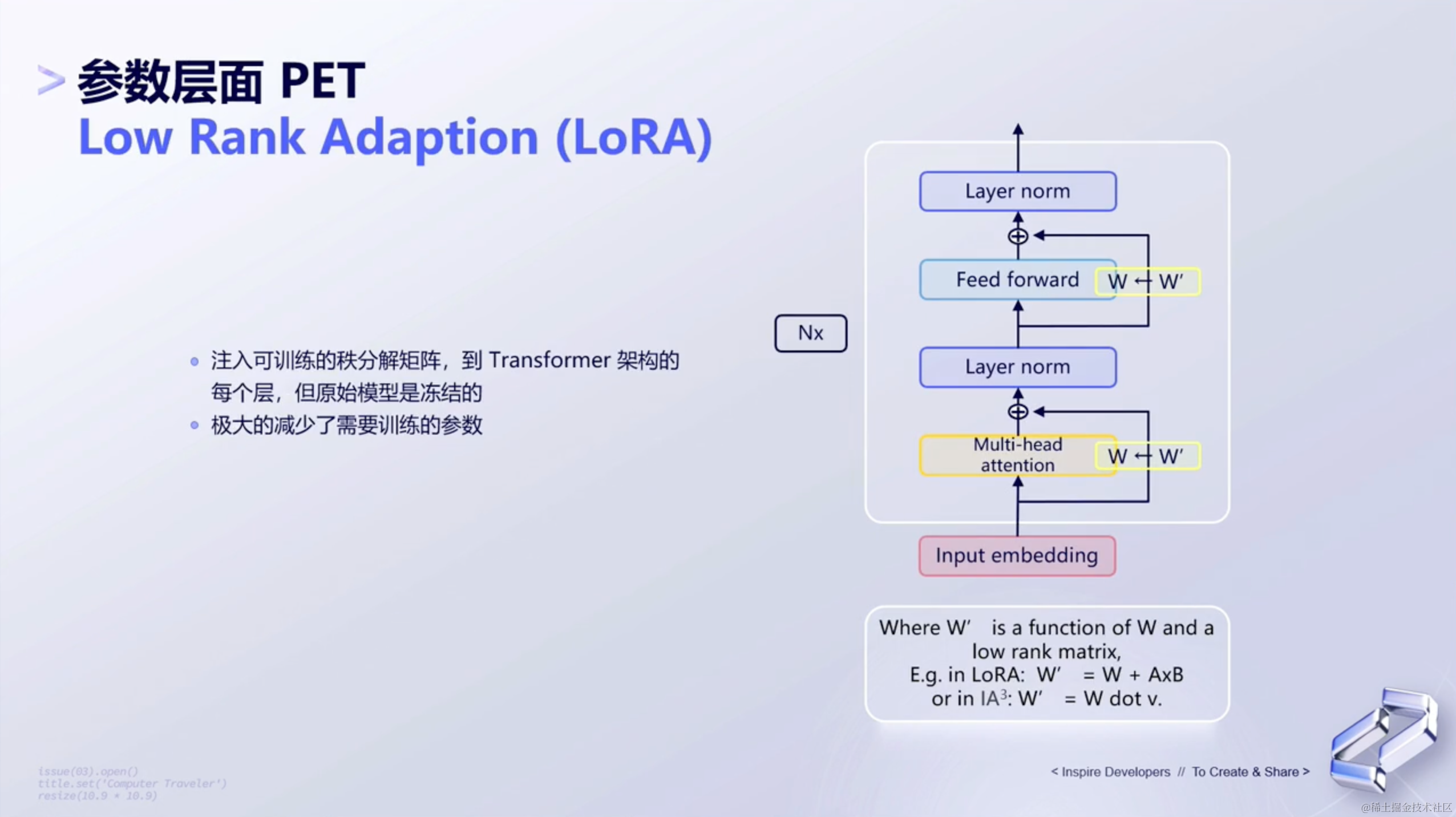
(3)参数层面
特性层面如何调优呢?如下所示👇🏻:
- 这是非常常见的一种方式,也就是
LoRA的方式。这种方式会引导模型去去训练一些稀疏的参数,以使得能够实现模型的fine tuning。
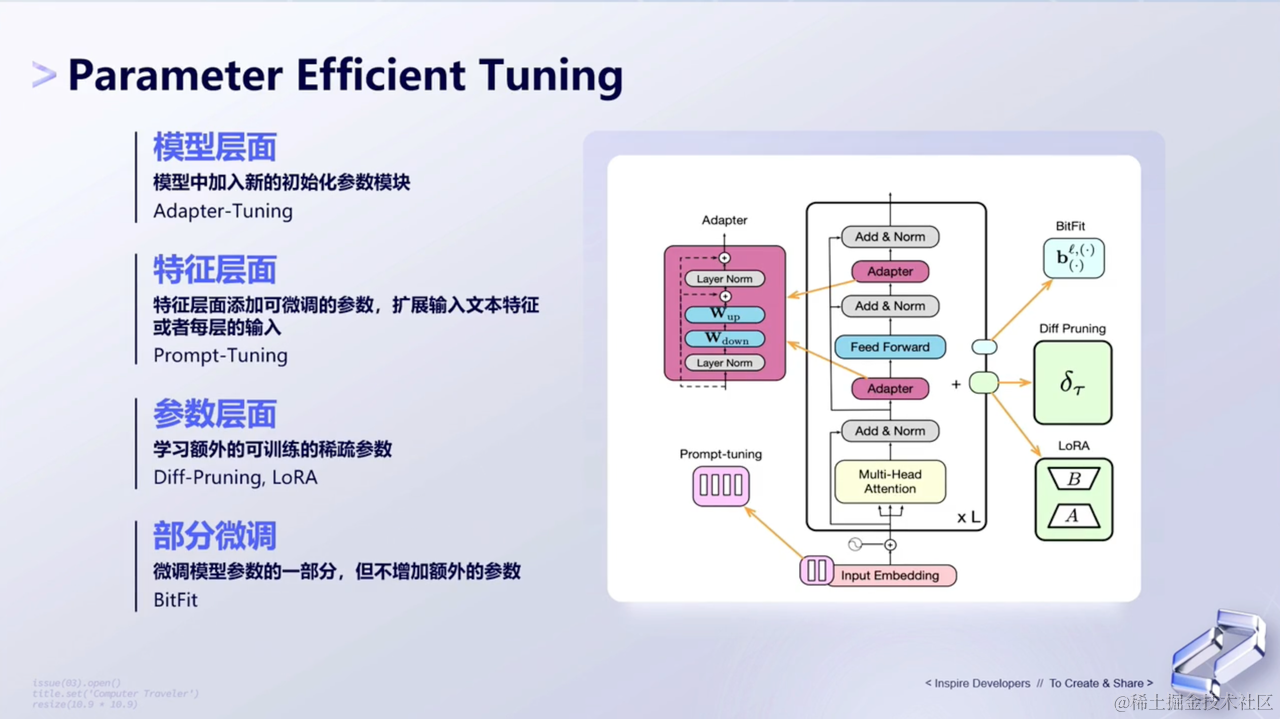
(4)部分微调
- 对于部分微调(Partial Fine-tuning)来说,它只微调模型的一部分参数,而不是对所有参数进行微调。这样做的好处是不需要像完全微调(Full Fine-tuning)那样重新训练整个模型,从而节省计算资源和时间。
- 与完全微调相比,部分微调不增加额外的参数(即不增加额外的比特位或权重),而是利用已经在预训练模型中学习到的知识来快速适应新的任务或数据分布。这种方法的优点是能够保留预训练模型已经学到的广泛知识和通用特征,同时只需要对与特定任务相关的部分参数进行调整。
- 具体来说,部分微调通常基于对任务相关性的判断来选择需要微调的模型层。例如,在NLP任务中,可以选择只微调模型的顶层和最后几层,因为这些层通常包含更多的任务相关特征。通过只微调部分参数,可以降低过拟合的风险,提高模型的泛化能力,并且减少对计算资源的消耗。
4、tuning表现举例
(1)用文本和对话来举例
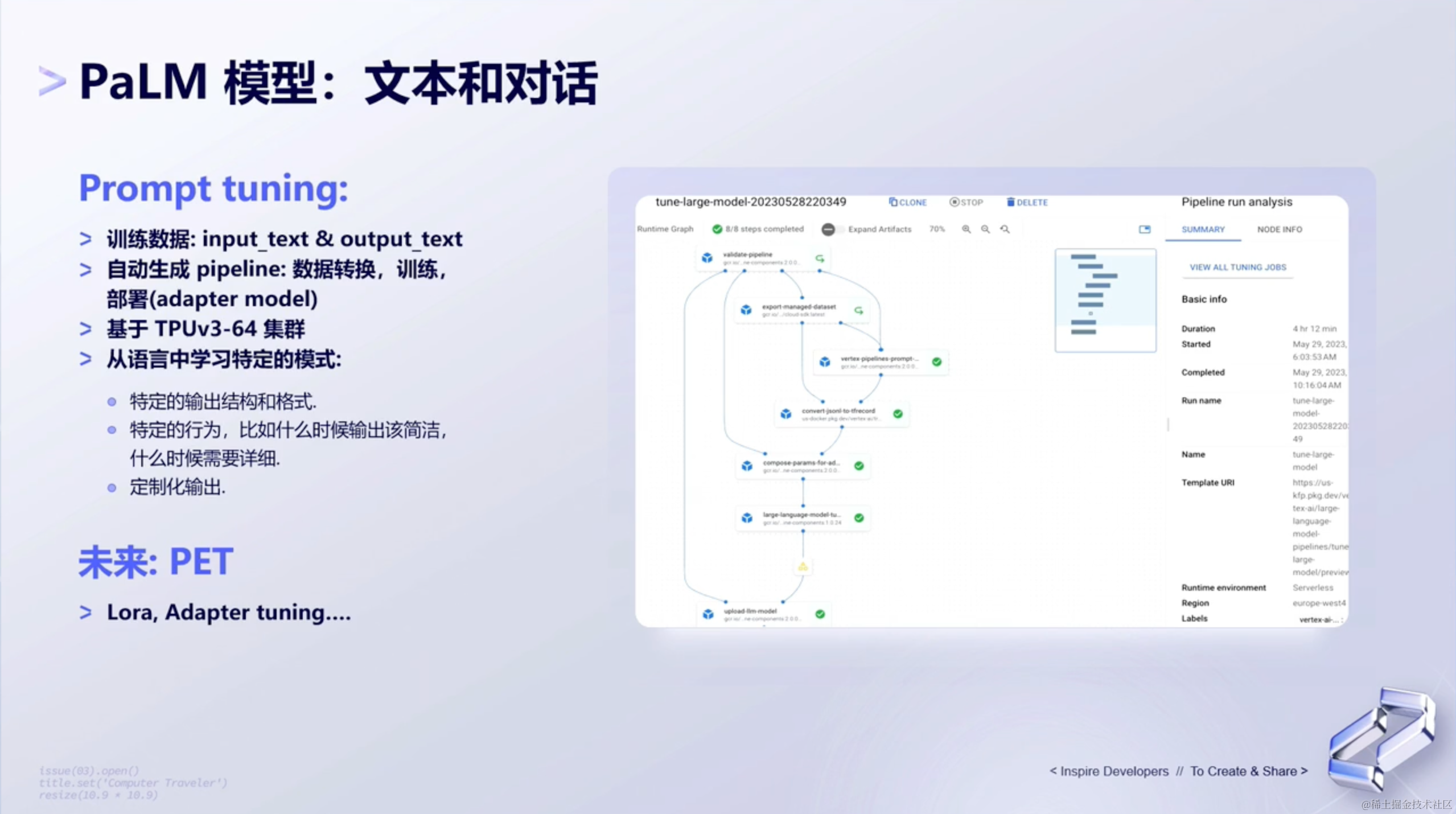
像PaLM2,本身实现了很多不同的fine tuning能力,比如:①Prompt tuning的能力;②或者基于PET的Lora、Adapter tuning的能力。
PaLM2的基层是基于Google Flow去构建了整个训练的pipeline,这表明,可以先对数据去进行一些分析,包括预处理。预处理是指对原始数据进行清洗、标准化、特征工程等操作,以便于模型能够更好地学习和预测。
之后呢,可以使用PaLM2提供的Prompt Tuning或者PET Tuning所提供的方式进行微调训练。
最后,模型训练完成后,可以将训练得到的模模型部署到真正的生产环境中,用于线上服务(serving)或推理(inference)。 在这个阶段,模型可以处理实际的用户输入,并生成相应的输出。
(2)PaLM 微调:Demo
下面展示一个PaLM2微调的demo👇🏻:
5、基于强化学习的微调形式
(1)使用人类反馈提升模型能力
除了前面谈到的微调形式,PaLM2还有基于强化学习的微调形式。这样的模型有以下两个特点:
- 通过适应用户需求提升模型 ——
RLHF使用人类反馈作为奖励信号,指导模型生成高质量的语言输出。 - 不需要改变模型尺寸 ——
RLHF训练出来的模型,更加准确和可靠。
RLHF适用于一些看中客户满意度的场景,比如:医疗、金融、电商等等。一般来说,我们的客户想要问的问题都很明确,所以human feedback会更强烈一些。

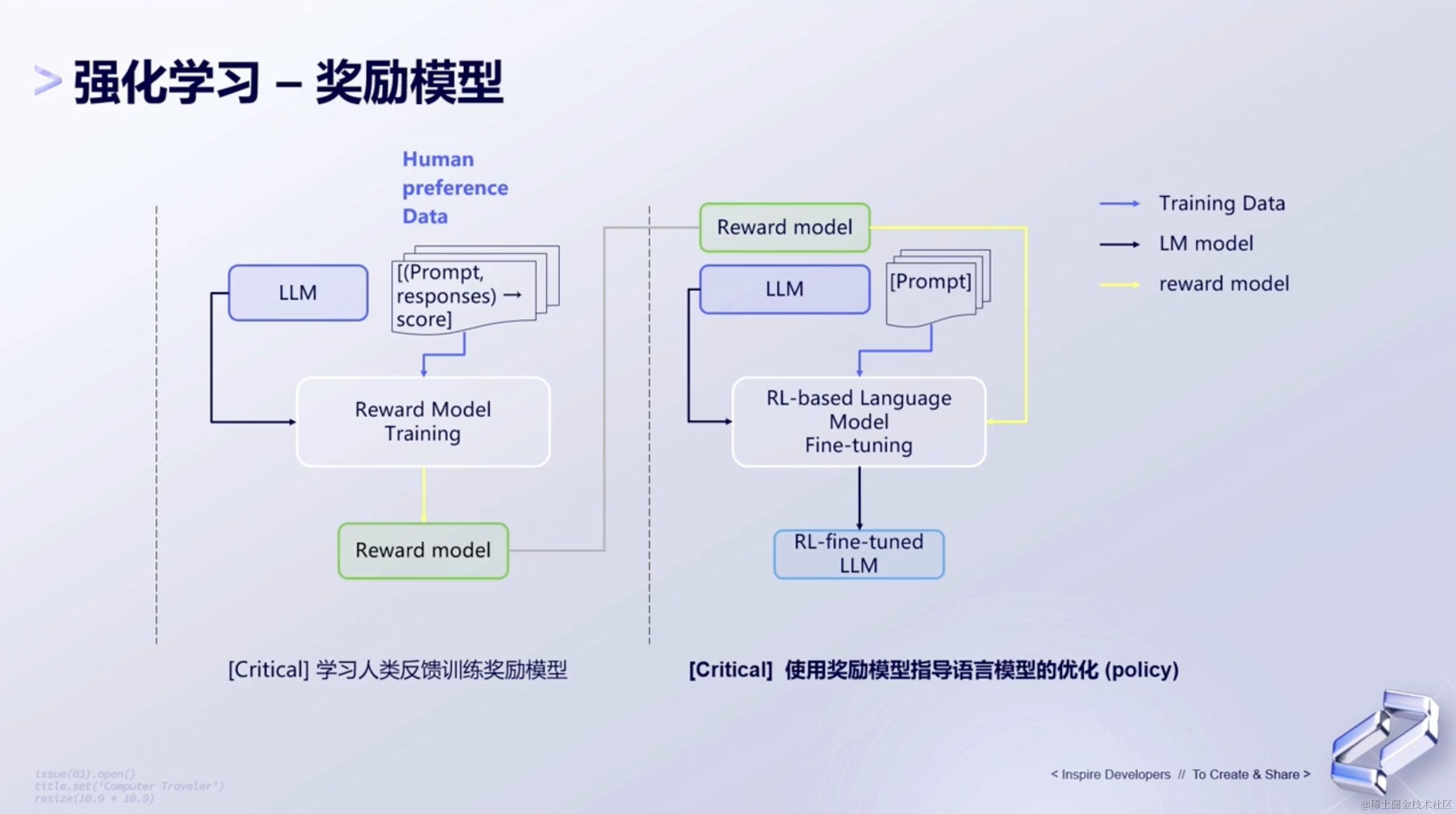
(2)强化学习 - 奖励模型
一般来讲,我们可以先去训练一个奖励模型(Reward Model),该模型可以根据用户的反馈或其他指标,为模型的行为生成一个奖励信号。这个奖励信号可以指导强化学习算法优化模型的行为,以获得更好的效果。
接下来,根据用户的反馈或打分,训练一个分类模型。这个分类模型的作用是将用户的反馈转化为二分类或多分类的标签,以便于后续的强化学习训练。
然后,基于强化学习的方式,利用奖励模型和分类模型对大语言模型进行微调(tuning)。强化学习是一种通过与环境的交互来学习最优行为的机器学习方法。在这个过程中,大语言模型将根据环境(即用户的反馈)来调整其行为,以最大化奖励信号。
这个流程已经在PaLM(Pathways Language Model)上得到了实现,并取得了不错的效果。
6、未来展望
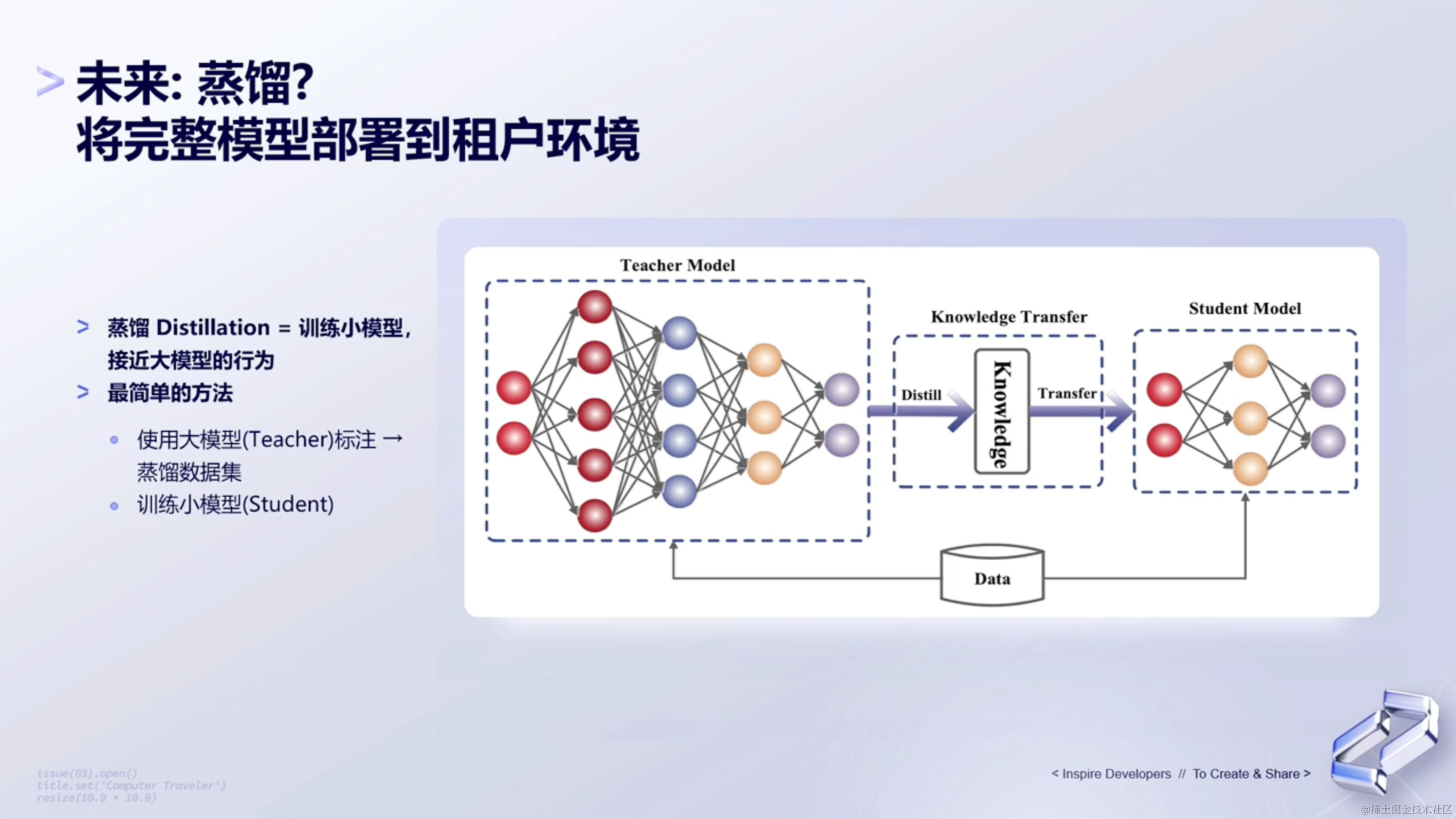
未来,Google Cloud也在探讨如何能够将大语言模型完全的fine tune,怎么样去更好更快速的fine tune,然后更高性价比的去服务于这个模型。
Google也在尝试通过蒸馏的形式,将Teacher model通过蒸馏的方式,去蒸馏成一个Student Model。然后把小模型serve到云上面,之后让所有的用户能够利用更小的加速器资源,不管是TPU还是GPU,然后能够更高性价比地、更经济实惠地去获取到模型的输出。
四、💰创新应用
最后,来展望下PaLM 2的一些创新应用。
1、Generative AI Studio
刚才前面说到的能力,都是在Generative AI Studio可以去通过提示词进行输入。

2、PaLM 模型 - 文本和对话
然后也可以基于不同的文本和对话模型去实现用户想要的输出。

3、Codey 模型 - 文本生成代码
第三种是codey模型,我们可以让模型帮助我们生成我们想要的代码。

4、Embeddings API
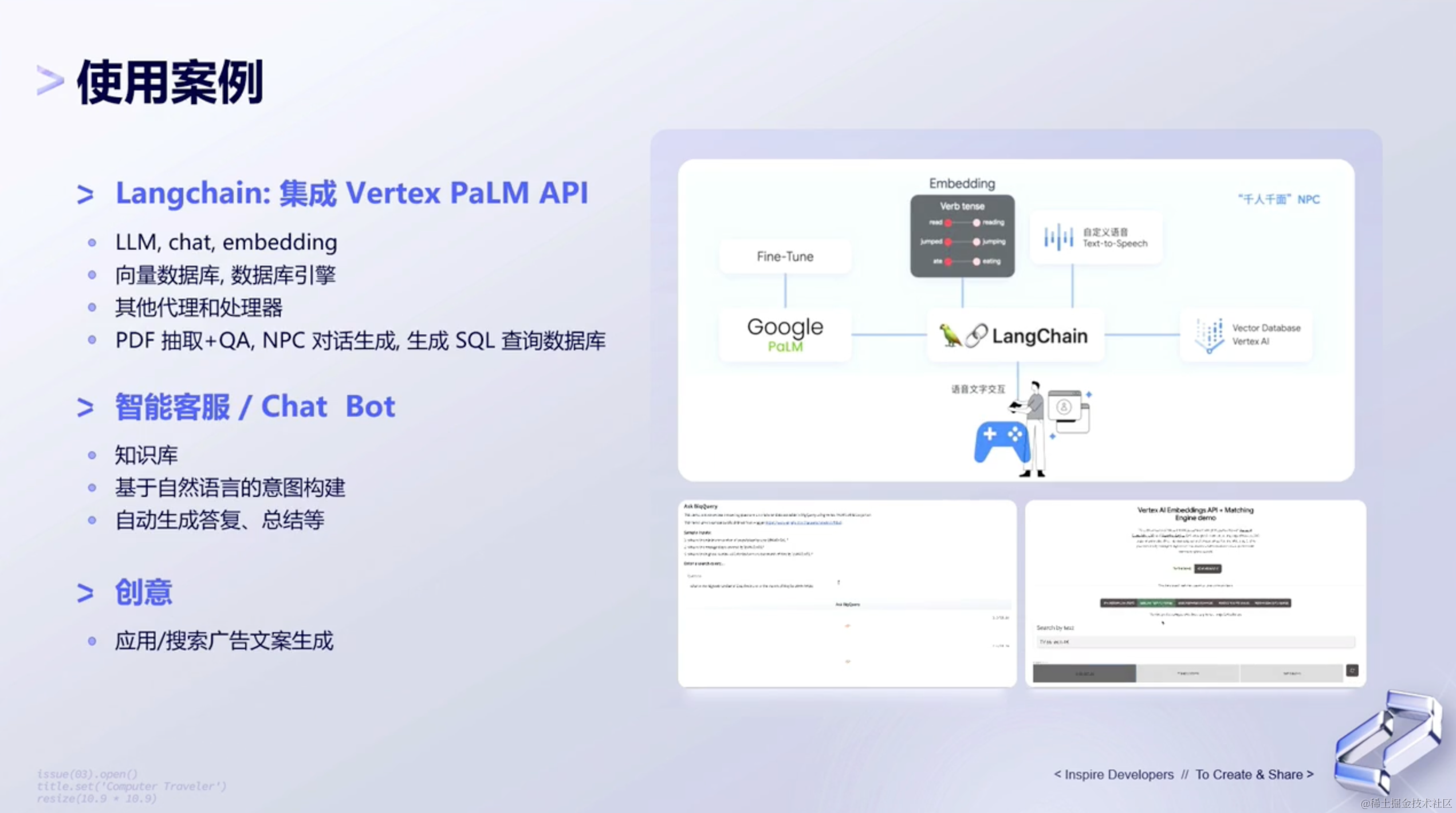
除此之外,PaLM2其实还有Embedding的服务。可以去生成文本或者图像的Embedding。
那对于Embedding来说,PaLM 2 还有很多的使用案例。比如:
- 通过
LangChain+embedding+向量数据库,去做一些知识的检索。 - 然将这些东西结合之后,作为
context传递进去,去作为文本的抽取,也可以去做Q&A,或者去做知识库。 - 甚至也可以在游戏领域去做一些
npc的保存和生成。

还有一些其他更场景化的使用案例。比如:
- 案例1: 通过给到一段自然的query,然后通过大语言模型去生成一段sql,mysql就可以直接到数据库里面,去完成一段查询。方便一些分析师,对整个行业或者数据库的一些分析。(上面的图)
- 案例2: 也可以做智能客服的场景,通过
text和image embedding,结合向量数据库,可以在零售行业,去通过图像检索出来对应的一些商品,并且是通过文本的一些形式检索出来 一些对应的商品。(右下角的图) - 案例3: 除此之外,可能还有一些像创意/广告文案这些,都可以通过大语言模型,然后结合一些向量数据库,embedding等这样一些不同的服务来实现。(左下角的图)
结束语
到这里,对于Google PaLM2的整个应用生态的介绍也就接近尾声啦!
在上面的文章中,我们首先对大语言模型及PaLM2进行了简单介绍,接着,还给大家介绍了几种提示词工程,包括但不限于自洽、思想链、对抗性提示词等等方式。
在第三部分,还给大家介绍了大语言模型整个微调的过程。最后,介绍了大语言模型未来会发展的一些创新应用。
这篇文章基于小编对开发者大会相关模块的主题做了一些整理和输出,有可能存在部分内容还理解不到位,欢迎小伙伴们交流&勘误。salute~🍻
参考材料
-
稀土开发者大会2023·大模型与AIGC-掘金
-
🎬 PPT下载&回放链接|2023稀土开发者大会大模型与 AIGC 分论坛