引言:探索任务无关的提示压缩技术
在大型语言模型(LLMs)的应用中,提示(prompts)的使用已成为一种常见的技术,它通过丰富而信息量大的提示来处理复杂和多样化的任务。然而,这些提示往往很长,导致计算和财务成本增加,并可能降低LLMs的信息感知能力。为了解决这些问题,提示压缩技术应运而生,旨在在不丢失关键信息的前提下缩短原始提示。尽管已有研究提出了针对特定任务的提示压缩方法,但这些方法在效率和泛化性方面存在挑战。因此,本文将探索任务无关的提示压缩技术,以提高泛化性和效率。
标题:LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression
机构:清华大学,微软公司
论文链接:https://arxiv.org/pdf/2403.12968.pdf
公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
提出问题:现有提示压缩方法的局限性
在大型语言模型(LLM)的应用中,提示压缩是一种减少计算和财务成本、提高信息感知能力的直接解决方案。然而,现有的提示压缩方法存在一定的局限性。首先,信息熵作为压缩指标可能并不理想,因为它仅利用单向上下文,可能无法捕获压缩所需的所有关键信息;其次,信息熵与提示压缩目标未必对齐。此外,依赖于任务特定特征的压缩方法在部署时面临效率和泛化能力的挑战。例如,在基于检索的生成(RAG)应用中,可能需要根据相关查询多次压缩相同文档,这在任务感知的提示压缩中尤为明显。
数据蒸馏:构建有效的提示压缩数据集
1. 数据蒸馏过程简介
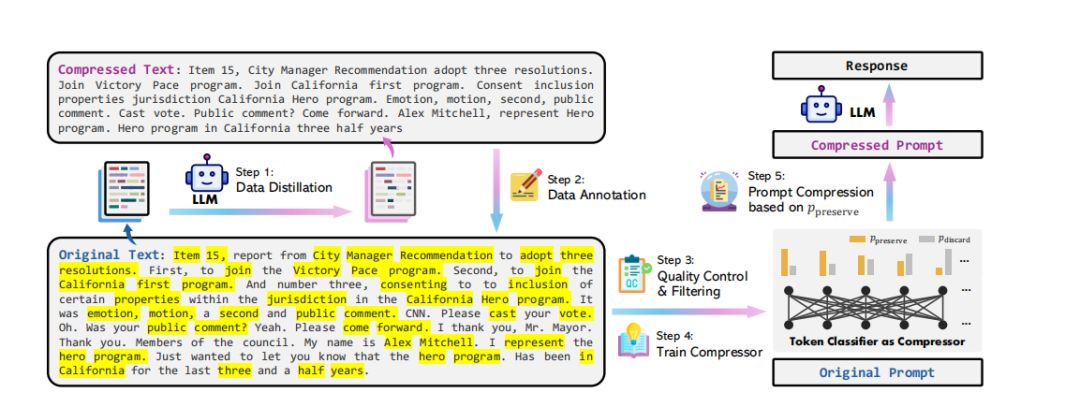
数据蒸馏是从大型语言模型(如GPT-4)中提取知识以进行有效的提示压缩的过程,旨在在不丢失关键信息的同时压缩提示。为了实现这一目标,研究者们设计了精心的指令,要求GPT-4仅通过丢弃原始文本中不重要的单词来压缩文本,并且在生成过程中不添加任何新单词。此外,为了应对信息密度的差异,研究者们采用了分块压缩的方法,将长文本分割成不超过512个令牌的多个块,然后指导GPT-4分别压缩每个块。
2. 数据注释算法
数据注释的目标是为原始文本中的每个令牌分配一个二进制标签,以确定在压缩后是否应保留该令牌。由于GPT-4可能无法精确遵循指令,研究者们采用了滑动窗口方法来限制搜索范围,并使用模糊匹配来处理GPT-4在压缩过程中可能对原始单词进行的更改。
3. 质量控制指标
为了评估GPT-4蒸馏生成的压缩文本以及自动注释标签的质量,研究者们引入了两个质量控制指标:变异率(VR)和对齐差距(AG)。变异率用于衡量压缩文本中与原始文本不同的单词比例,而对齐差距则用于评估自动注释标签的质量。通过这些指标,研究者们能够过滤掉低质量的样本,确保数据集的质量。
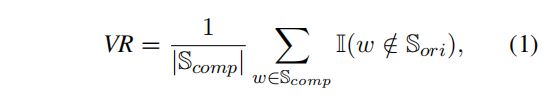
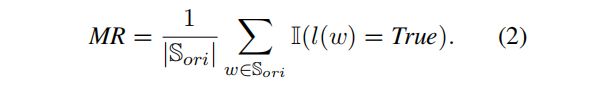
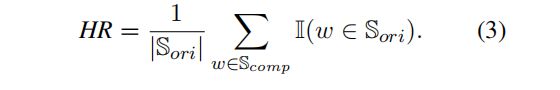
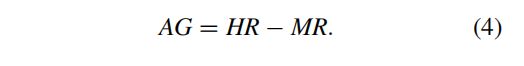
压缩器设计:任务无关的提示压缩模型
1. 二元分类问题的提出
在设计任务无关的提示压缩模型时,我们首先将提示压缩问题转化为一个二元分类问题。这种方法的核心思想是将每个词汇单元视为一个独立的实体,并为其分配一个标签,标签的值为“保留”或“丢弃”。这样的设计保证了压缩后的提示与原始提示在内容上的忠实度,同时也简化了压缩模型的设计,因为它将复杂的压缩任务简化为了一个简单的分类问题。
2. 压缩策略和模型架构
在压缩策略方面,我们采用了基于Transformer编码器的架构,该架构能够捕捉到每个词汇单元的双向上下文信息,从而为压缩任务提供必要的信息。通过这种方式,我们的模型能够在压缩过程中保留所有对于理解原始提示至关重要的信息。此外,我们的模型还通过使用较小的模型(如XLM-RoBERTa-large和mBERT)来显式学习压缩目标,从而实现了更低的延迟。
实验设计与评估
1. 实验设置和评价指标
实验的设置包括了在多个领域内外的数据集上评估我们的压缩模型,这些数据集包括MeetingBank、LongBench、ZeroScrolls、GSM8K和BBH。我们使用了一系列评价指标来衡量压缩后的提示在不同任务中的表现,这些任务包括摘要生成和问答。在摘要任务中,我们采用了ROUGE指标来评估生成摘要的质量;在问答任务中,我们使用了LongBench提供的评价脚本和指标。
2. 基准测试和结果分析
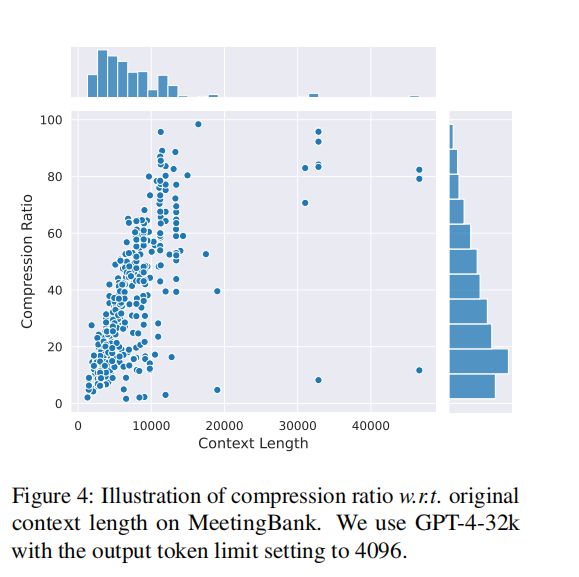
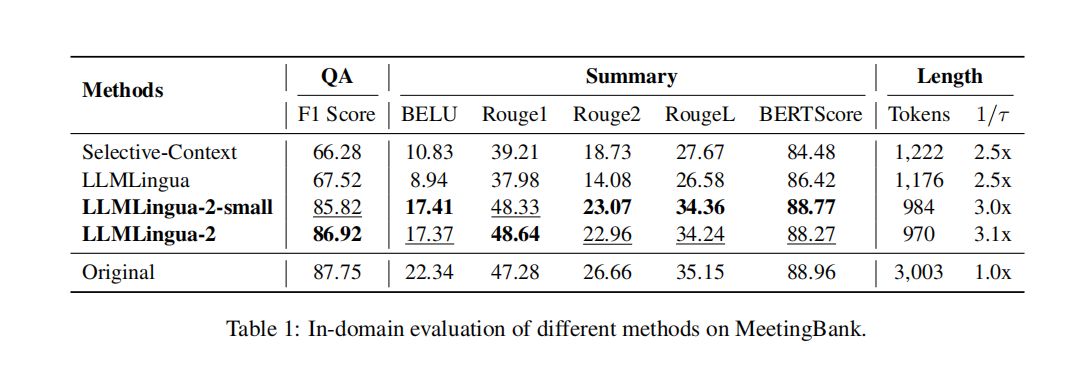
在基准测试中,我们的模型与几个强基线进行了比较,包括Selective-Context和LLMLingua,这两种方法都基于LLaMA-2-7B。尽管我们的模型在大小上远小于基线中使用的LLaMA-2-7B,但在MeetingBank的内部评估中,我们的方法在问答和摘要任务上都取得了显著的性能提升,几乎达到了原始提示的性能水平。此外,我们的模型在外部基准测试中也展现出了良好的泛化能力,即使是较小的模型也能在不同任务中取得与原始提示相当或甚至更好的性能。在使用Mistral-7B作为目标LLM的评估中,我们的方法同样展现出了显著的性能提升,这进一步证明了我们的模型具有良好的泛化能力。在延迟评估中,我们的模型在不同的压缩比率下都实现了显著的速度提升,同时还降低了对硬件资源的需求。
结论:LLMLingua-2的性能和效率
在本研究中,我们提出了LLMLingua-2,这是一个用于任务不可知的提示压缩的模型,旨在提高大型语言模型(LLMs)的泛化能力和效率。LLMLingua-2通过数据蒸馏过程从LLM(如GPT-4)中提取知识,以在不丢失关键信息的前提下压缩提示。我们还引入了一个抽取式文本压缩数据集,并公开发布了该数据集。
1. 性能:LLMLingua-2在多个领域内外的数据集上进行了评估,包括MeetingBank、LongBench、ZeroScrolls、GSM8K和BBH。结果显示,尽管LLMLingua-2的模型规模较小,但它在性能上显著优于强基线,并展示了出色的泛化能力。特别是,当以Mistral-7B作为目标LLM时,LLMLingua-2不仅保持了与原始提示相当的性能,甚至在某些情况下超越了原始提示。
2. 效率:LLMLingua-2在压缩速度上比现有的提示压缩方法快3倍至6倍,并且在端到端延迟上实现了1.6倍至2.9倍的加速,同时压缩比率达到2倍至5倍。此外,LLMLingua-2的GPU内存开销也大大减少,降低了硬件资源的需求。