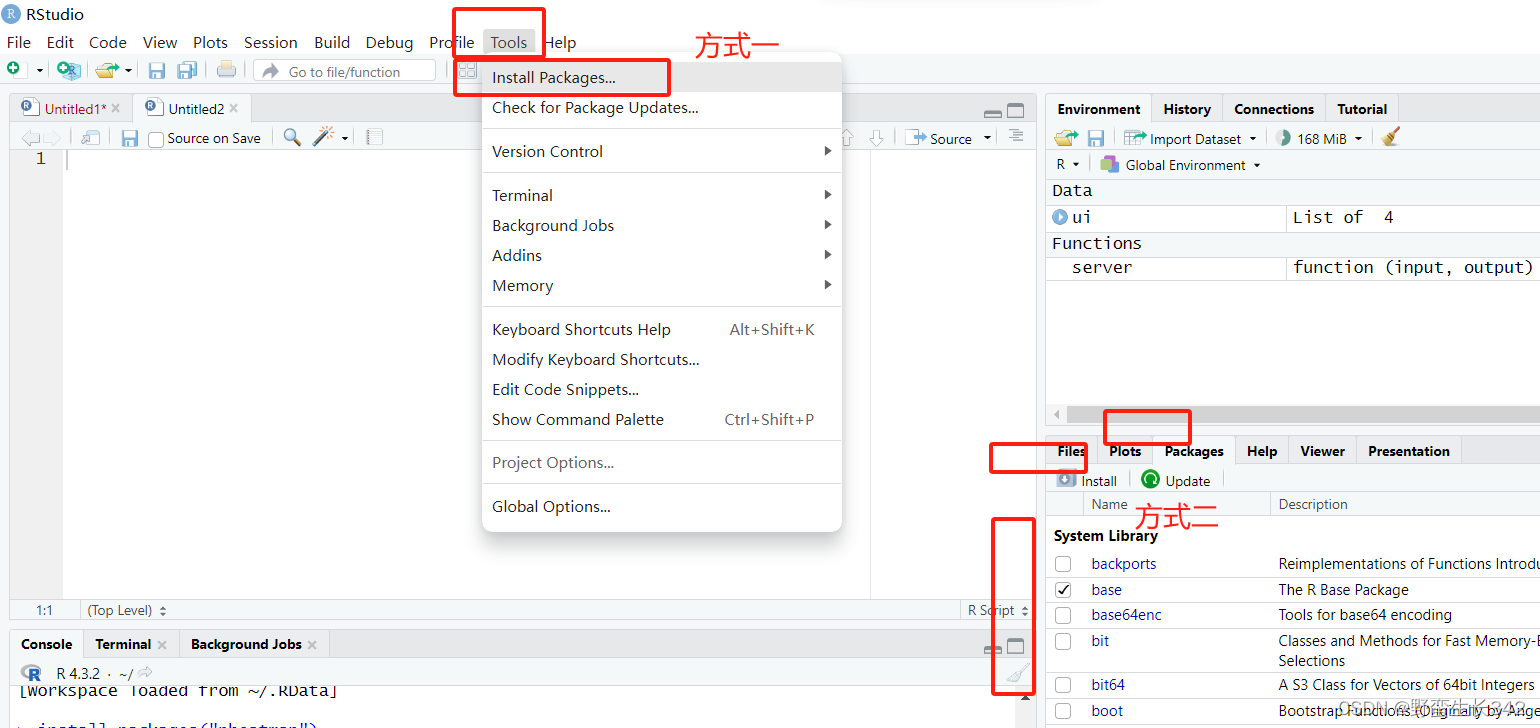
💡💡💡本文独家改进:Powerful-IoU更好、更快的收敛IoU,是一种结合了目标尺寸自适应惩罚因子和基于锚框质量的梯度调节函数的损失函数
💡💡💡MS COCO和PASCAL VOC数据集实现涨点
YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
✨✨✨ 新开专栏暂定免费限时开放,后续每月调价一次✨✨✨
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐现更新的所有改进点抢先使用私信我,目前售价68,改进点20+个⭐⭐⭐
⭐⭐⭐专栏涨价趋势 99 ->199->259->299,越早订阅越划算⭐⭐⭐

YOLOv9魔改:注意力机制、检测头、blcok魔改、自研原创等
YOLOv9魔术师
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

YOLOv9框架图
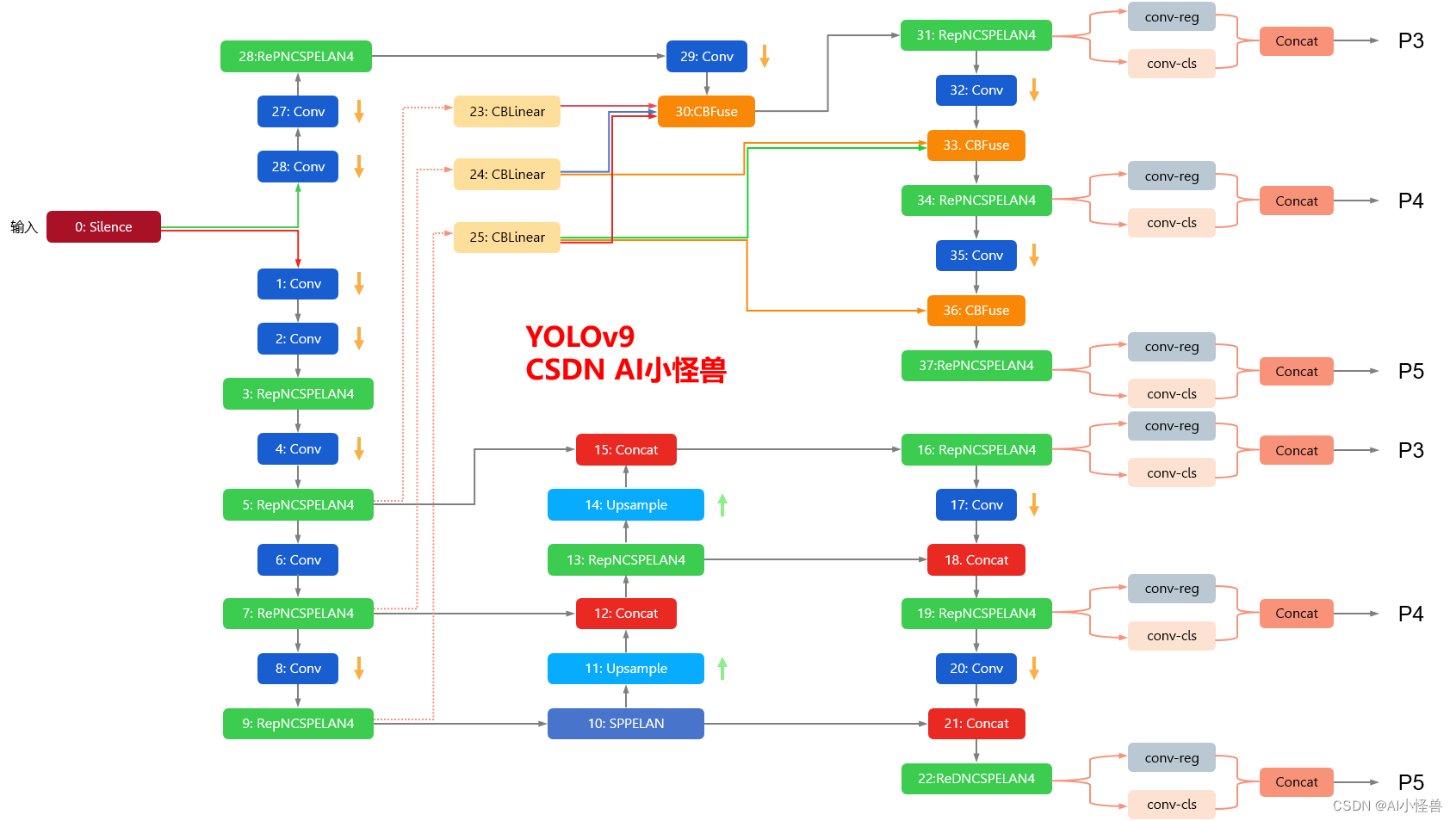
1.1 YOLOv9框架介绍
YOLOv9各个模型介绍

2.Powerful-IoU介绍

链接:https://www.sciencedirect.com/science/article/abs/pii/S0893608023006640
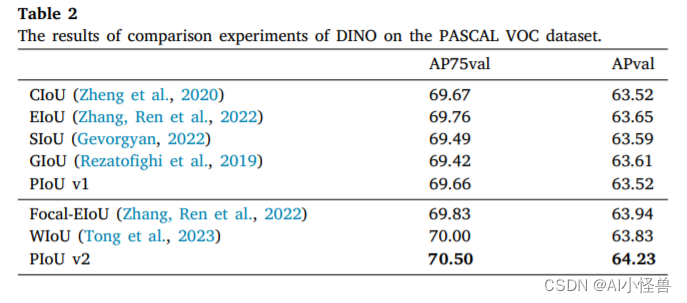
摘要:边界框回归(Bounding box regression, BBR)是目标检测中的核心任务之一,而BBR的损失函数对其性能影响很大。然而,我们观察到现有的基于iou的损失函数受到不合理的惩罚因素的影响,导致锚框在回归过程中膨胀,显著减缓了收敛速度。为了解决这个问题,我们深入分析了锚框增大的原因。为此,我们提出了一种结合了目标尺寸自适应惩罚因子和基于锚框质量的梯度调节函数的强效iou (PIoU)损失函数。PIoU损耗引导锚框沿着有效路径回归,从而比现有的基于iou的损耗更快地收敛。此外,我们还研究了聚焦机制,并引入了一个非单调注意层,将其与PIoU结合,得到了一个新的损失函数PIoU v2。PIoU v2损耗增强了对中等质量锚框的聚焦能力。通过将PIoU v2整合到流行的目标检测器(如YOLOv8和DINO)中,我们在MS COCO和PASCAL VOC数据集上实现了平均精度(AP)的提高和性能的改进,从而验证了我们提出的改进策略的有效性。
图1所示。基于不同iou的损失函数指导下的锚框回归过程。彩色框是在回归过程中由不同损失函数引导的锚框。很明显,以PIoU损失为导向的锚盒是最快回归到接近目标盒的。此外,除PIoU损失外,所有损失函数引导的锚盒都存在面积扩大问题,而PIoU损失引导的锚盒则不存在面积扩大问题。

图2所示。基于IoU的损失。(a)和(b)中的损失函数都使用诸如锚框和目标框的最小外部边界框(灰色虚线框)的对角线长度或面积等维度信息作为损失因子的分母。相反,(c)中的PIoU损耗仅使用目标盒的边缘长度作为损耗因子的分母。

图3所示。一个扩展锚框的例子。在左图中,锚框的中心位置为(4,4),宽度为4,高度为2。在右图中,锚框的中心位置也是(4,4),但宽度为6,高度为3。可以观察到,尽管锚盒尺寸增大,但𝑅𝐺𝐼𝑜𝑈、𝑅𝐷和𝛥减小。然而,𝑅P𝐼𝑜𝑈并没有表现出这样的行为。

2.1 PIoU v2损失
在本节中,我们将探讨聚焦机制在我们提出的损失函数中的应用。为了解决第2.2节中提到的Focal EIoU (Zhang, Ren et al., 2022)和WIoU (Tong et al., 2023)的局限性,我们设计了一个由单个超参数控制的非单调注意函数与PIoU相结合。PIoU v2损耗在PIoU损耗上增加注意层后得到,增强了对中高质量锚盒的聚焦能力,提升了目标检测器的性能。注意函数和PIoU v2损失定义为:

2.2 实验结果

2.Powerful-IoU加入到YOLOv9
2.1Powerful-IoU实现路径为utils/metrics.py
本部分后续开源
2.2 utils/loss_tal_dual.py
训练方法为 train_dual,因此本博客以此展开
1)首先进行注册
from utils.metrics import piou1)修改class BboxLoss(nn.Module):
iou = bbox_iou(pred_bboxes_pos, target_bboxes_pos, xywh=False, CIoU=True)修改为
iou = piou(pred_bboxes_pos, target_bboxes_pos, xywh=False, PIoU2=True)⭐⭐⭐现更新的所有改进点抢先使用私信我,目前售价68,改进点20+个⭐⭐⭐
⭐⭐⭐专栏涨价趋势 99 ->199->259->299,越早订阅越划算⭐⭐⭐