Linux文件系列:磁盘,文件系统,软硬链接
- 一.磁盘相关知识
- 1.磁盘机械构成
- 2.磁盘物理存储
- 3.磁盘逻辑存储
- 1.LBA地址
- 2.磁盘的分区和分组
- 二.文件系统和inode
- 1.inode结构体
- 2.文件系统
- 1.Super Block(超级块)
- 2.Group Descriptor Table(块组描述表GDT)
- 3.inode Table
- 4.Data Blocks
- 5.Block Bitmap(块位图)
- 6.inode Bitmap
- 3.理解文件系统
- 4.几个补充的点
- 1.int block[15]的介绍
- 2.通过inode编号查找文件的分组
- 3.文件名和inode编号的映射
- 补充:重新理解目录文件的权限
- 4.重谈文件的增删查改
- 5.重谈文件路径
- 补充知识点:挂载
- 三.软硬链接
- 1.软硬链接的操作与现象
- 1.软链接
- 2.硬链接
- 2.软硬链接的原理
- 3.软硬链接的应用场景
- 1.软链接
- 2.硬链接
我们之前所学的都是被进程打开了的文件,接下来我们要学习没有被进程所打开的文件,它们是存储在磁盘当中的
要学习这些文件,首先我们要先学习一下磁盘
一.磁盘相关知识
1.磁盘机械构成
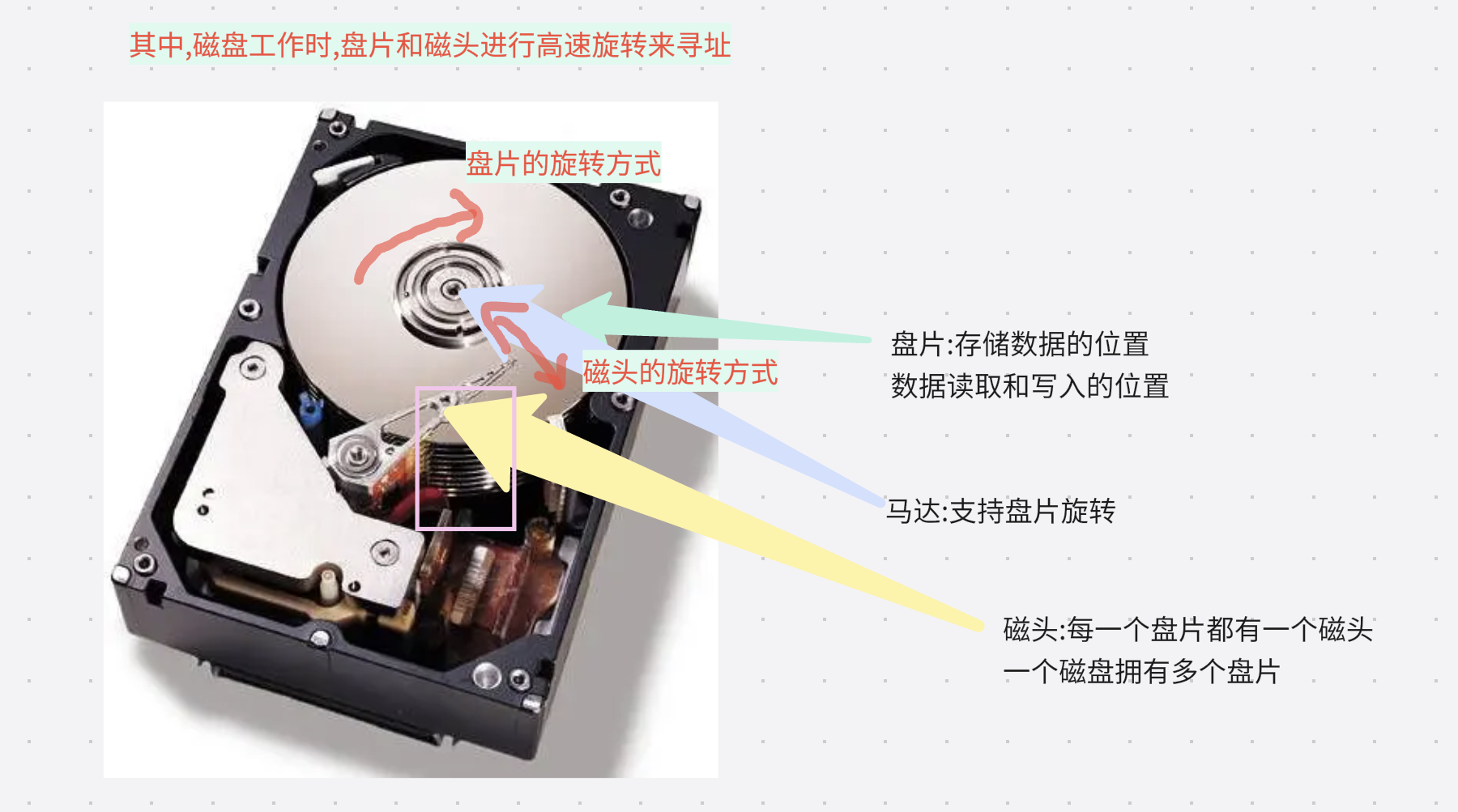
2.磁盘物理存储


3.磁盘逻辑存储
1.LBA地址

我们知道磁带在展开之后呈现一种带状结构,磁带中的数据就是以这种线性的方式进行存储的
那么我们可不可以把磁盘"展开"呢?
在逻辑上面我们可以想象一下磁盘"展开"后的样子,给磁盘上的每一个扇区进行编号,然后"折"回去.
最后只需要通过一种映射关系和CHS定位法不就可以定位到具体的扇区了吗?
其实"展开"之后,磁盘就类似于数组了,此时对磁盘的管理就变成了对数组的管理了
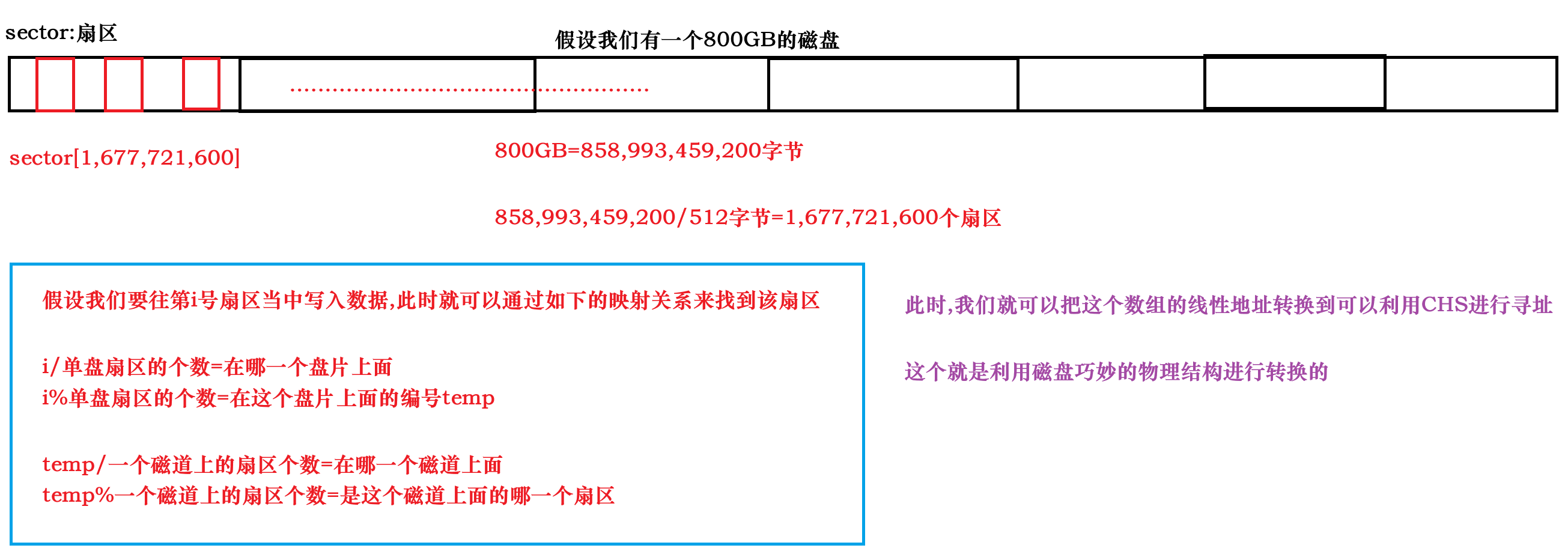
我们知道磁盘是外设,将磁盘加载到内存当中是很慢的,因此操作系统认为512字节太小了
因此操作系统认为IO的基本单位是4KB,将这个数组划分为若干个4KB的数据块,
数据块和扇区之间就要进行一些映射关系完成这种转换
一个数据块对应于8个扇区
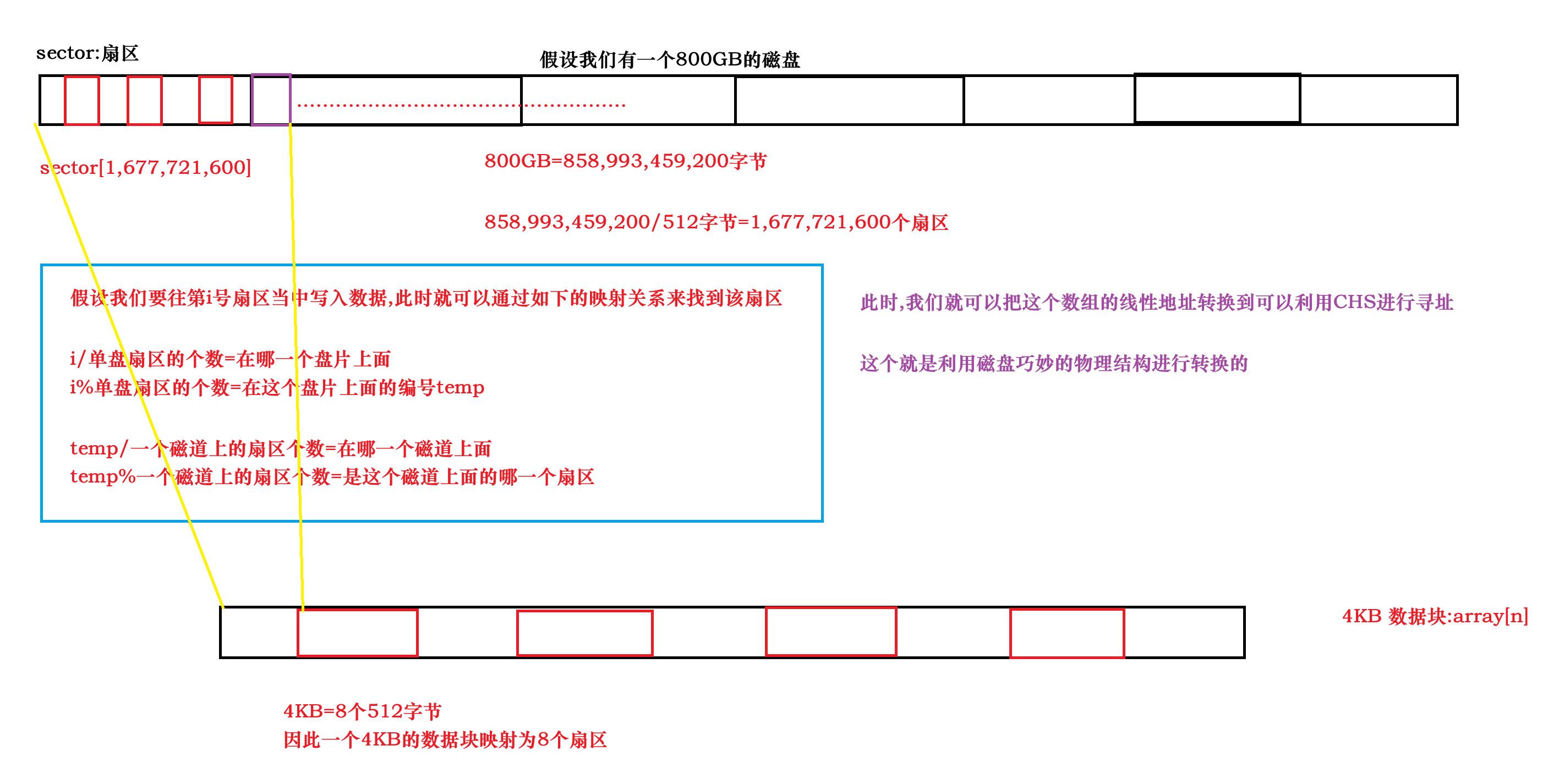
这些数据块所对应的地址就被称为LBA(Logical Block Address 即:逻辑块地址)地址
2.磁盘的分区和分组
假设我们有800GB的磁盘,如何对这800GB进行管理呢?
我们都知道电脑当中有若干盘:C盘,D盘等等…
其实,我们日常提到的C盘,D盘…等等,本质上都只是对一块磁盘的不同分区而已,C盘是一个分区,D盘是一个分区…
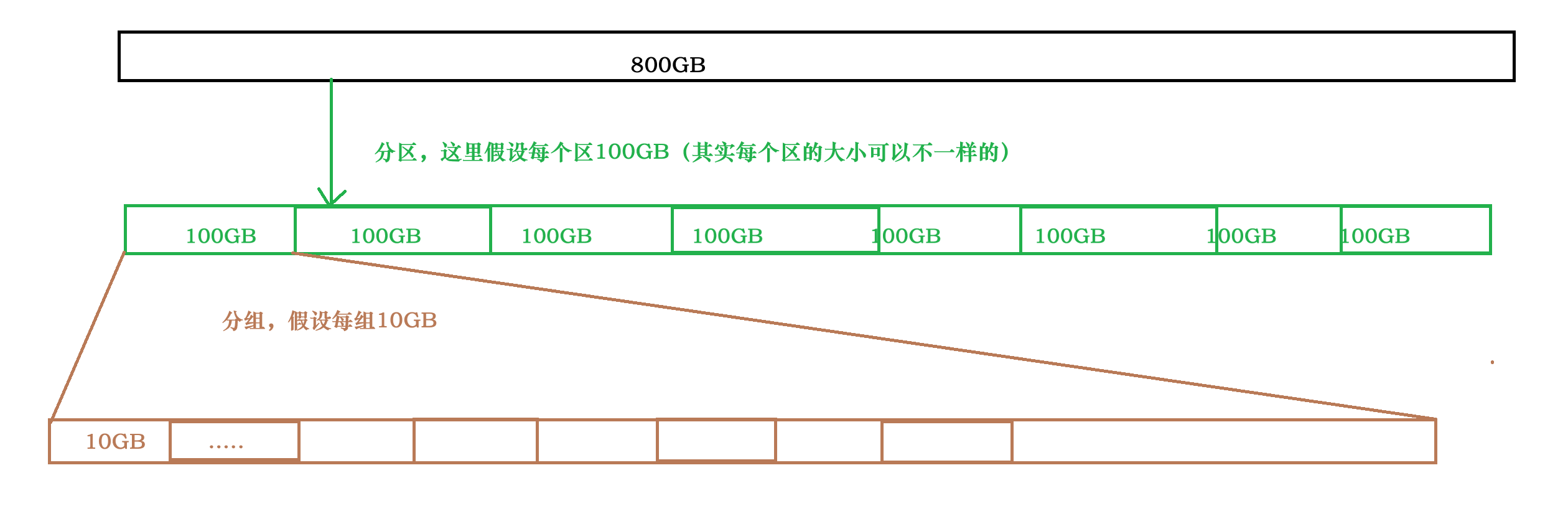
其实这里采用了分治的思想,将800GB分为8个区,每个区100GB,只要管理好100GB,那么不就能够照猫画虎管理好这800GB了吗?
那么如何管理好100GB呢?
将100GB分为10个组,每个组10GB,只要管理好10GB,那么不就能管理好这100GB了吗?
那么如何管理好10GB呢?
这就是我们接下来要探讨的问题:文件系统和inode
二.文件系统和inode
1.inode结构体
我们知道:文件=内容+属性
其中文件内容的大小是不确定的,但是文件属性的大小是确定的
操作系统想要管理文件,就要通过"先描述,在组织"的原则来进行管理,
因此需要抽象出描述文件属性的结构体(就是这里要介绍的inode结构体)
大致的成员变量如下:
struct inode
{
类型;
大小;
权限;
时间;
.....
inode编号;
int block[15];
};
我们要说明的几点如下:
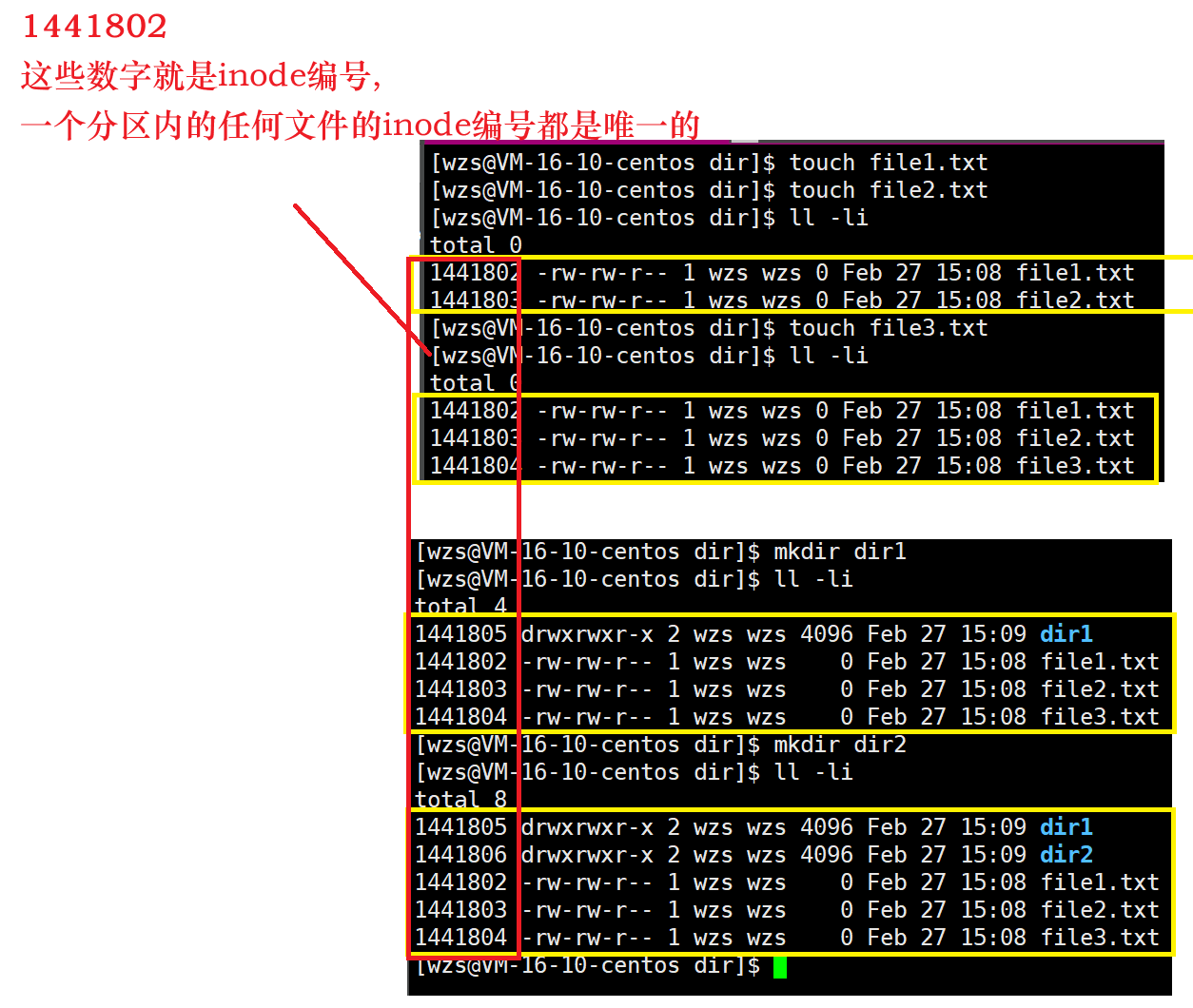
- 文件名不属于文件属性,而属于文件内容!!(因为文件名是可变的,文件名的长度不同,所占用的空间大小不同)
- 文件的唯一标识是inode编号,inode编号在每一个分区内是唯一的,在每一个分组内不是唯一的
- inode结构体的大小是128字节
- int block[15]是用来查找该文件所对应的内容的一个字段,我们后面会介绍的
ll -li 查看inode编号的命令
2.文件系统
每个分区都对应一个文件系统
下面我们介绍Linux操作系统下的ext2文件系统
ext2文件系统会根据分区的大小将该分区划分为若干个Block Group,而每个Block Group都有着相同的组成结构
而且文件的内容和属性是分区域存储的
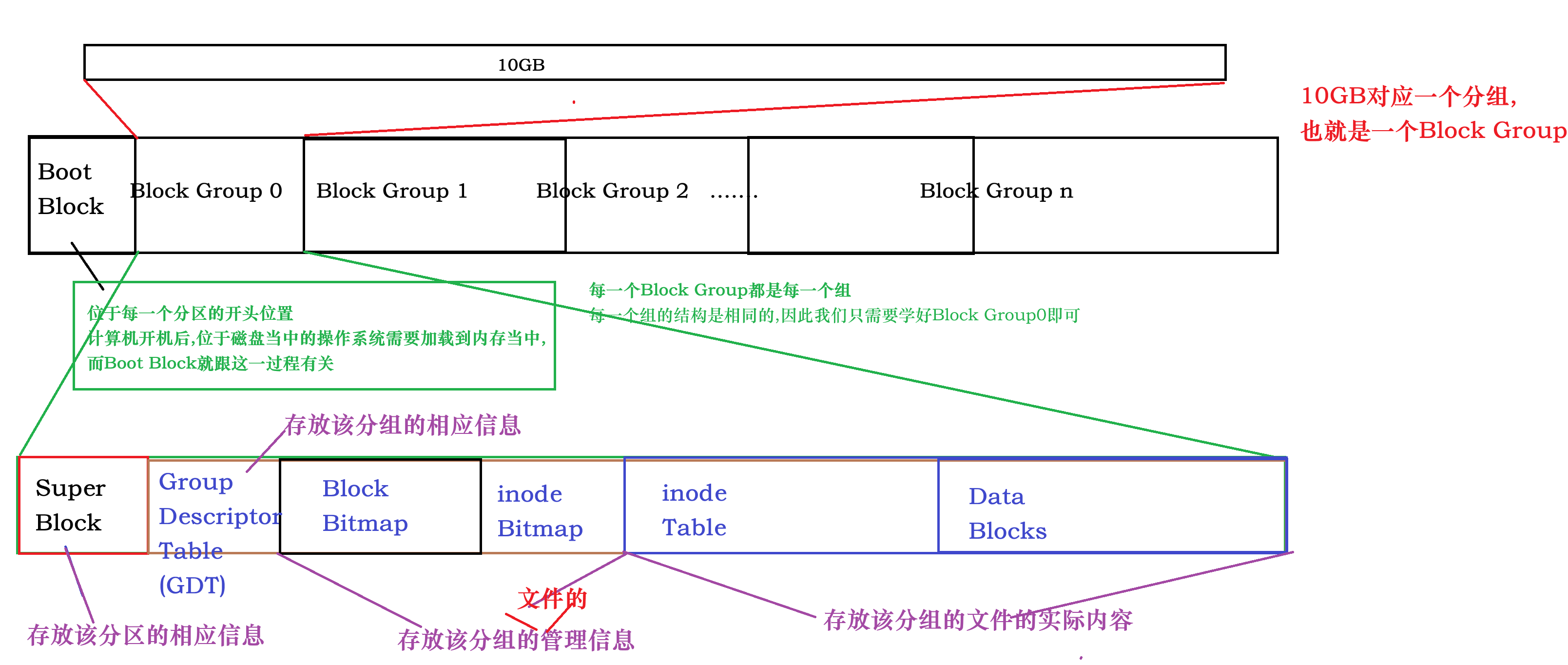
不是每一个分组当中都有Super Block,但是每个分组当中都有其余的这5个字段
下面我们分别介绍一下这几个字段:
1.Super Block(超级块)
1.存放该分区(即该文件系统)的相应信息,记录的信息主要有:
block和inode的总量,未使用和已经使用了的block和inode的数量,每个block和inode的大小等等
2.由于Super Block存放的是该分区的相应信息,因此无需所有的分组都具有该字段(否则会浪费大量空间),只有小部分分组当中具有该字段
3.Super Block的信息被破坏,就意味着整个文件系统的结构就被破坏了
4.为什么不让它跟Boot Block一样只存一份呢?
因为万一某个分组当中的Super Block的损坏了,可以用其他分组内的Super Block恢复过来,提高文件系统的容错率
2.Group Descriptor Table(块组描述表GDT)
存放该分组的相应信息,每一个分组都有该字段,记录的信息主要有:
该分组已经使用了多少个inode,一共有多少个inode,
Group Descriptor Table,Block Bitmap,inode Bitmap,inode Table,Data Blocks这些字段的区域划分等等
3.inode Table
存放文件的属性(即inode结构体)
4.Data Blocks
数据区:存放文件内容的区域
5.Block Bitmap(块位图)
记录着Data Block中哪个数据块已经被占用了,哪个数据块尚未被占用
根据位图的特性,我们可以得出:
比特位的位置:表示的是块号
比特位的内容:对应的块是否被占用了
6.inode Bitmap
跟Block Bitmap类似,只不过记录的是哪个inode是否空闲可用而已
3.理解文件系统
我们知道:
Super Block记录着该分区/文件系统的相应信息
因此就可以通过对Super Block进行管理来完成对这个分区/文件系统的管理
因此操作系统可以将Super Block使用某种数据结构(例如链表)来进行管理
此时对分区/文件系统的管理就变成了对链表的增删查改
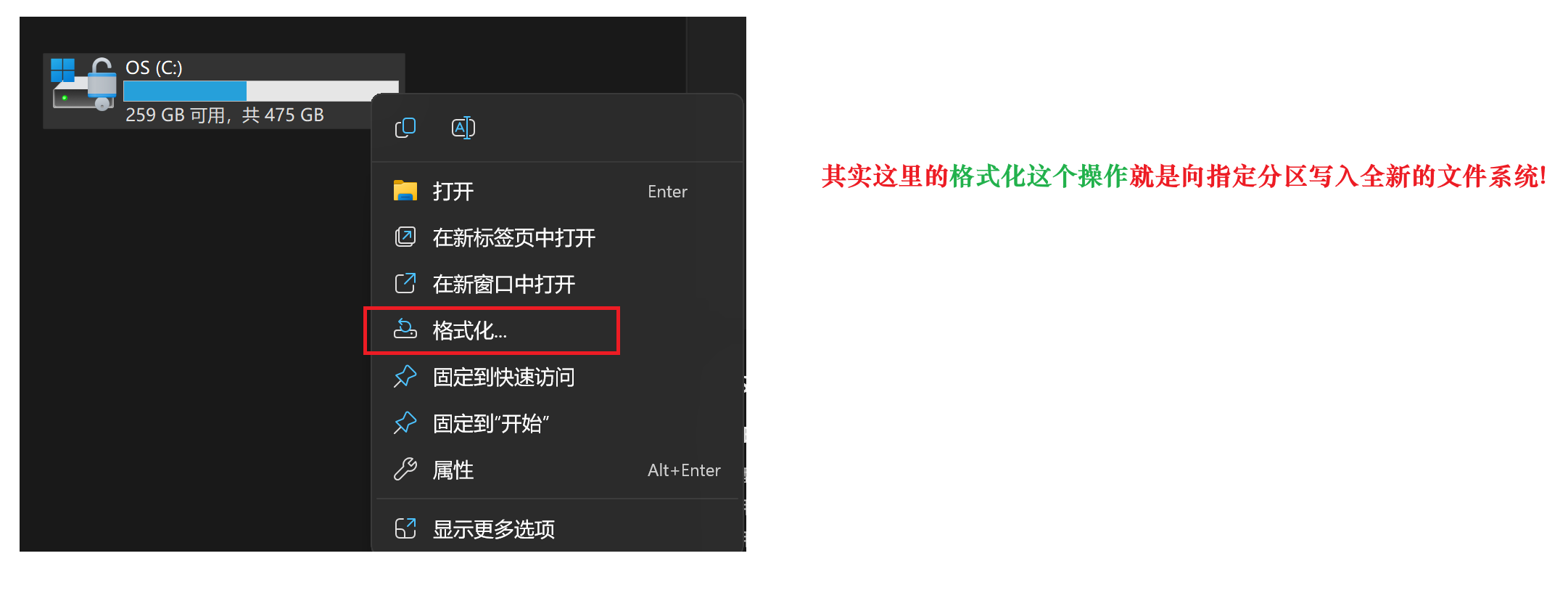
但是分区当中的每个分组内的这些字段也不是与生俱来的,
而是在分区之后通过格式化这个操作写入文件系统的信息(也就是
划分完各个管理字段的区域,填好每个Super Block GDT等等数据,从而完成文件系统的搭建)
其中不同分区可以写入不同或者相同的文件系统
4.几个补充的点
了解了这些字段之后,我们可能还会有些疑问:
1.前面的int block[15]还没有介绍呢
2.inode编号在每个分区内唯一,在每个分组中不唯一
不过如何通过inode编号来定位这个文件在哪个分区里面,在哪个分组里面呢?
3.为什么我们可以通过文件名来操作一个文件呢?
文件名不是不属于文件属性吗?
4.如何理解文件的新建和删除,查找和修改呢?
5.文件路径是怎么一回事?
下面我们就来解决这些问题
1.int block[15]的介绍
我们回过头来重新理解一下这个int block[15]
它是负责查找对应文件的内容的
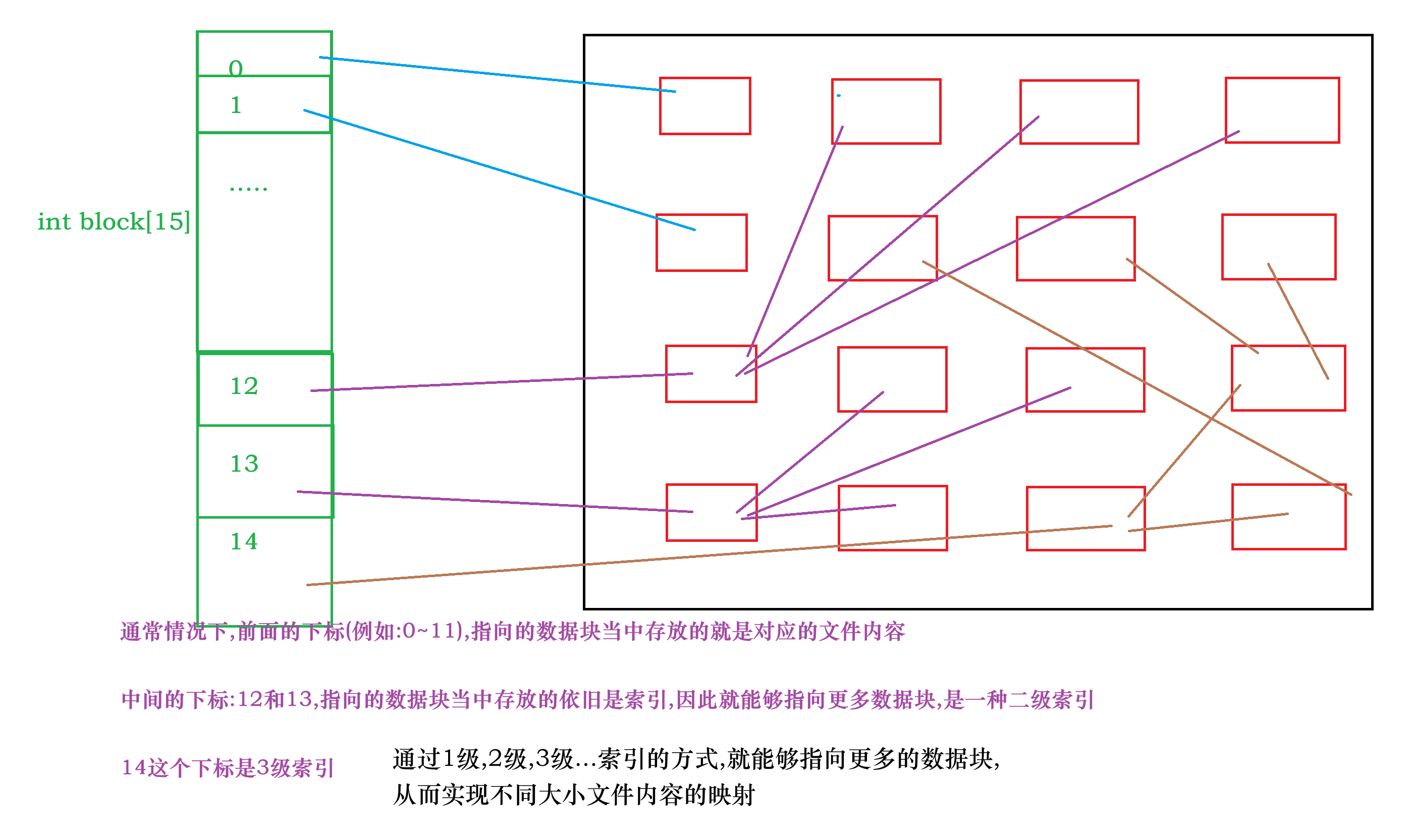
2.通过inode编号查找文件的分组
为什么不先介绍查找分区呢?
因为查找分区和路径有关,谈完路径之后我们会谈查找分区的

这里到inode Bitmap当中进行查找主要是为了确认这个文件是否真的存在
3.文件名和inode编号的映射
我们知道,每一个普通文件都一定在一个目录当中
而目录也是文件,目录文件的内容就是
文件名和inode编号的映射关系,因此可以通过文件名映射到对应的inode编号,因此我们就可以通过文件名来操作一个文件了
补充:重新理解目录文件的权限
此时我们就能够更好的理解目录文件的权限了

4.重谈文件的增删查改
当我们新建一个文件时:
1.在inode bitmap当中查找尚未被使用的inode结构体,将这个结构体的内容填好,分配给这个文件,并且将这个比特位置为1(表示这个inode结构体已经被占用了)
2.修改该文件所在的目录文件的内容,添加上这个新文件的文件名和inode编号的映射关系
3.写入内容时直接在data Block处写入即可,根据内容大小来调整int block[15]字段的映射关系
当我们删除一个文件时:
只需要根据inode编号找到inode bitmap中对应的比特位,将这个比特位由1置为0(表示这个inode结构体和它所对应的数据块已经空闲了,可以被新的文件所占用了,也就达到了删除的目的)
这样做显著提高了删除文件的效率
因此我们平常在下载APP时会比较慢,而删除APP时特别的快
关于文件的查和改大家也能凭借自己去理解了,我这里就不赘述了
5.重谈文件路径
谈完文件的增删查改之后,我们已经显然得知:对一个文件进行增删查改都跟该文件所处目录有关系
也就是说我想要访问当前目录的某个文件test.txt,就必须要先访问当前目录,而当前目录也是一个文件,是在上一个目录当中的文件
因此要想访问当前目录,就必须先访问上一个目录…
因此查找一个文件时都必须要这样逆向的,如同递归般地往上走,直到到达根目录为止
因此要访问某个文件,就必须要知道当前文件的路径,然后按照这个路径对该文件进行逆向查找
而这个过程,就是对路径进行解析的过程
例如:
我目前在这个路径下

我想要访问当前目录下的test.txt这个文件
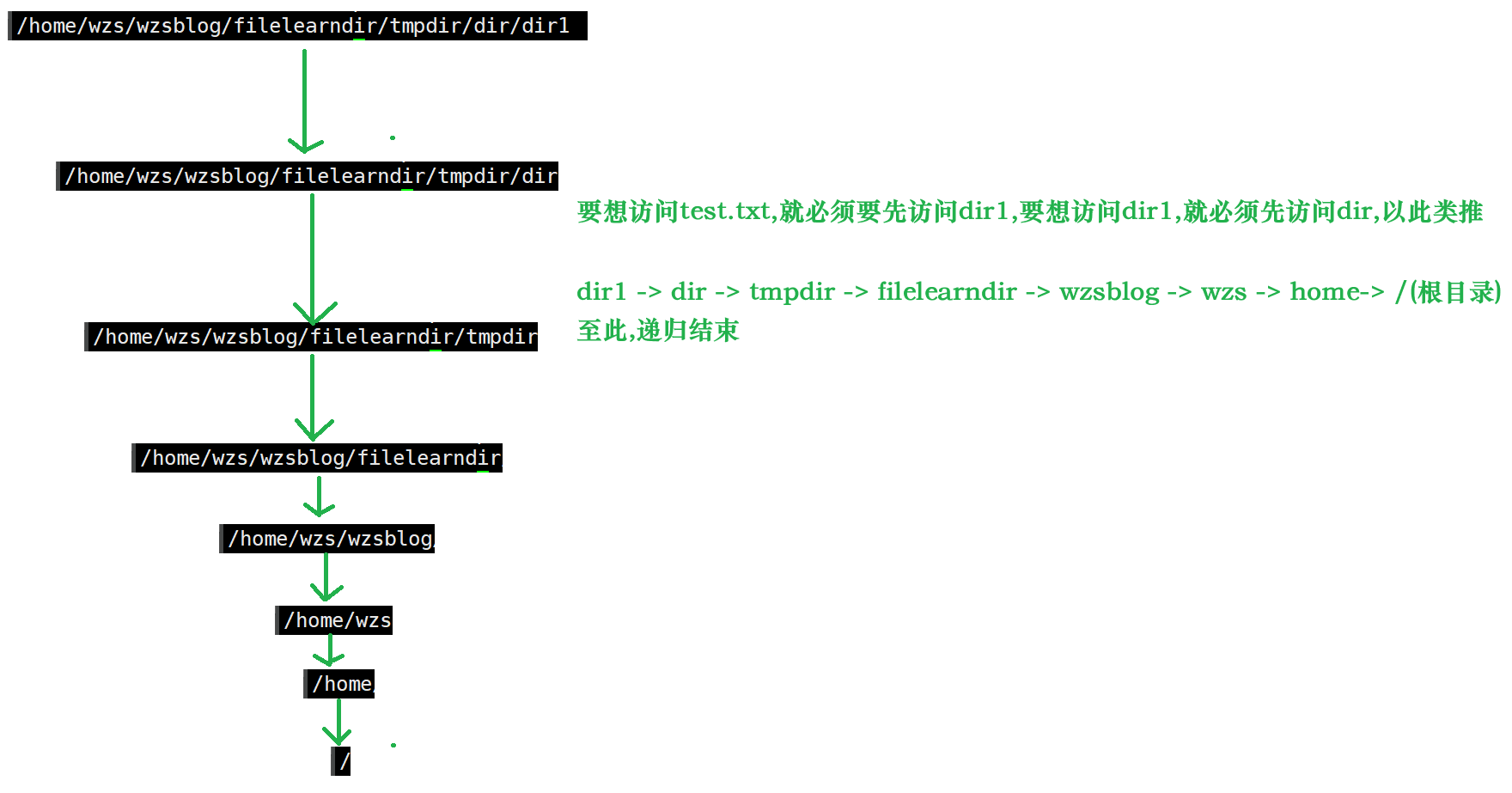

谈完了路径解析之后,下面我们来探讨一下如何判断当前文件在哪一个分区下面
补充知识点:挂载
我们要补充一个知识点:挂载
一个被写入文件系统的分区,想要被Linux操作系统使用,就必须要先把这个具有文件系统的分区进行"挂载"
什么叫做"挂载"呢?

简而言之,挂载就是把一个文件系统的分区写入到一个目录当中,而访问该分区就是通过该分区所挂载的目录进行访问的
因此,通过对路径前缀的解析,我们就能够优先区分出文件在哪一个分区下面,因此inode编号对于分区而言是可以不唯一的,因为查找一个文件所在分区是通过文件路径来查找的,而不是通过inode编号来查找的
三.软硬链接
1.软硬链接的操作与现象
1.软链接
我们之前提到过软链接,对应博客:Linux中的shell外壳与权限(包含目录文件的权限,粘滞位的来龙去脉)
当时我们将软链接文件当作快捷方式一样来看待,今天,我们再来理解一下这个软链接文件
创建软链接文件的命令:
ln -s 目标文件名 链接文件名 (这个-s可以理解为-soft)
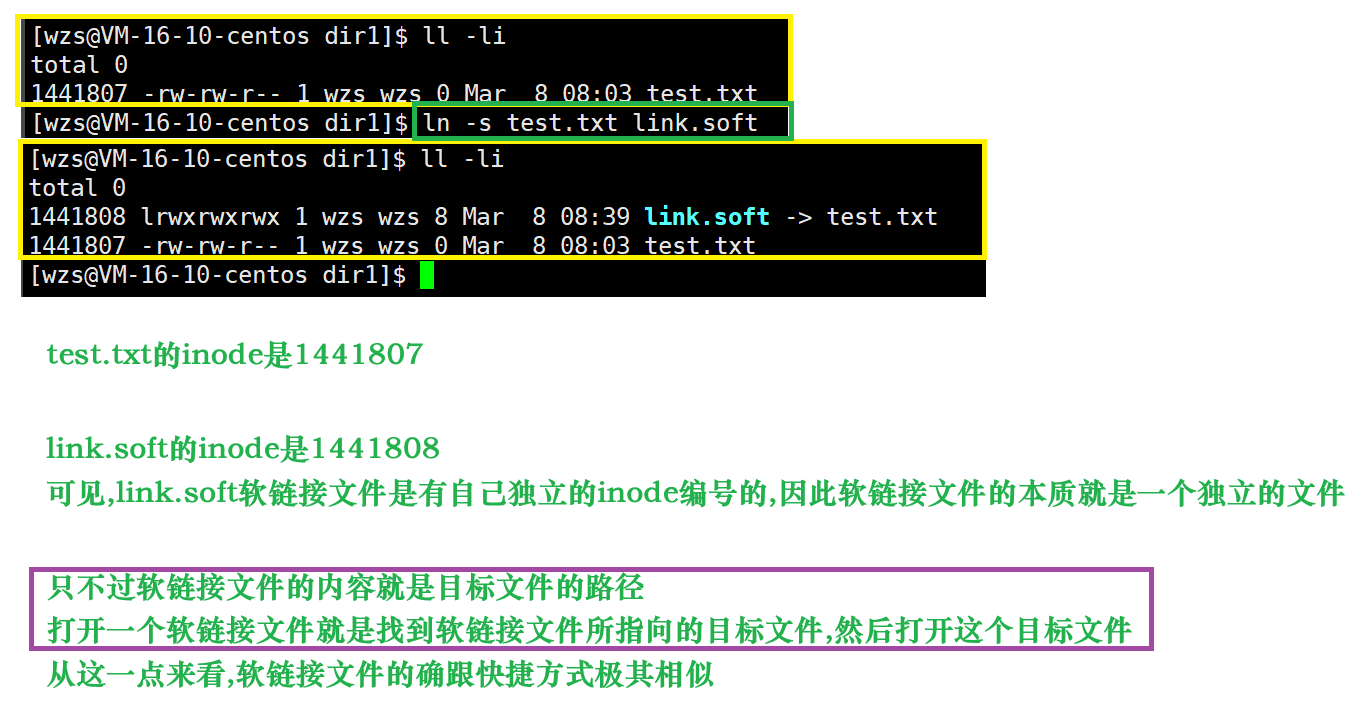
为了证明软链接存放的就是目标文件的路径,我们在当前目录新建一个目录dir,然后将目标文件test.txt移动到dir下面,然后查看链接文件的内容
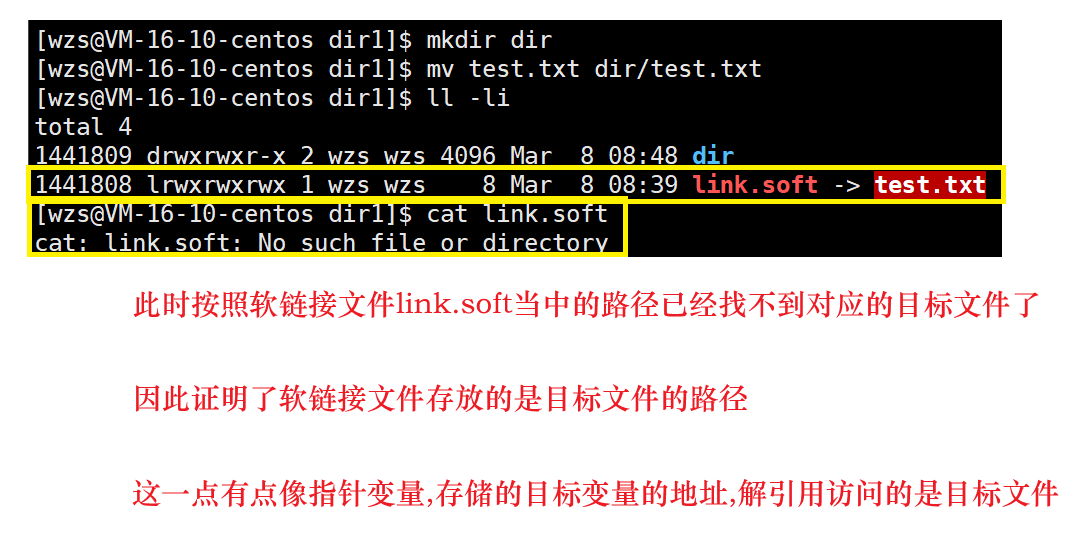
然后我们把test.txt再移动回来

此时,这个软链接文件就正常了
下面我们证明一下访问软链接文件就是访问目标文件
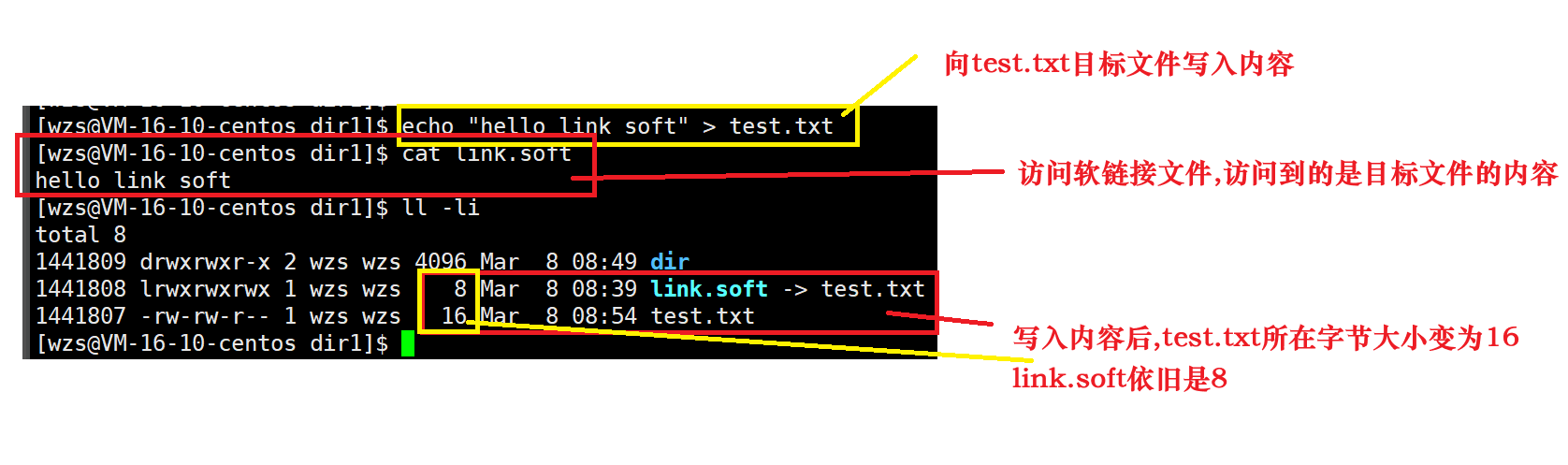
证明完毕
2.硬链接
创建硬链接文件的命令:
ln 目标文件名 链接文件名

下面我们向hello.txt目标文件当中写入内容
然后看一看这两个文件的变化
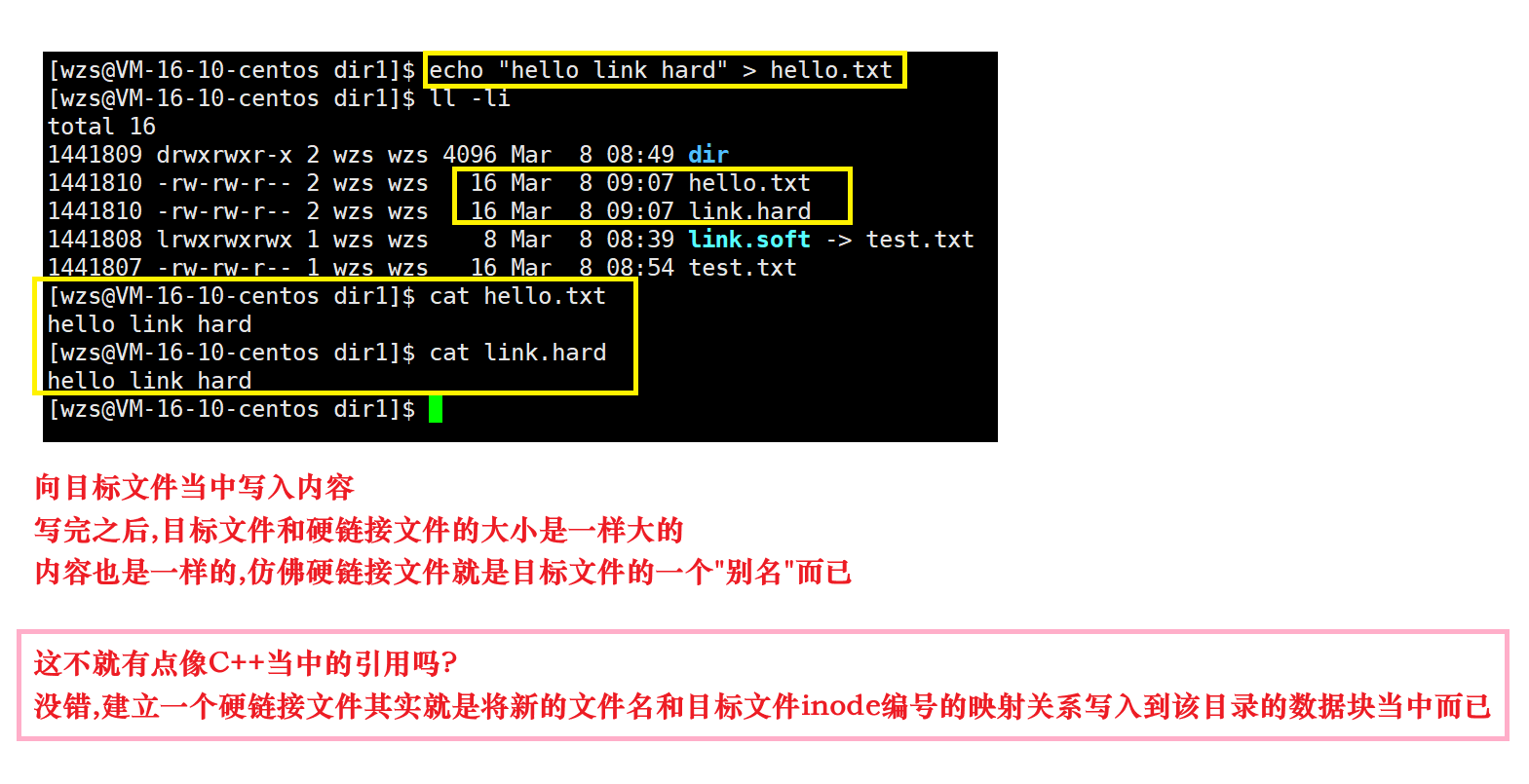
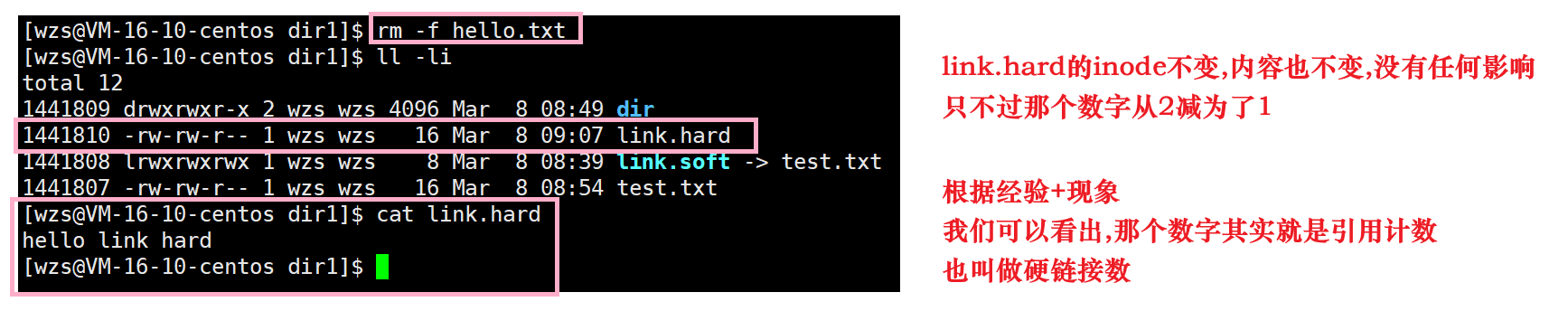
下面我们把目标文件hello.txt删除,然后访问硬链接文件link.hard的内容
2.软硬链接的原理
经过上面的现象+经验总结
我们可以得出:
软链接的本质就是一个独立文件,软链接文件的内容就是目标文件的路径
访问软链接文件,本质就是访问目标文件
硬链接的本质就是在指定的目录下,插入新的文件名和目标文件inode编号的映射关系,并让inode的引用计数++
删除文件时,先将硬链接数–,如果硬链接数减为0,那么就会将该文件所对应的inode bitmap的比特位全部清0
3.软硬链接的应用场景
1.软链接
软链接的应用场景就是作为"快捷方式"发挥作用
当我们想要访问一个路径较为麻烦的文件时,可以为这个文件建立软链接,放在我们规定的位置,这样就能够通过访问软链接文件从而访问这个文件了
这是文心一言上面给出的答案,大家可以对照理解一下

2.硬链接
先抛出一个问题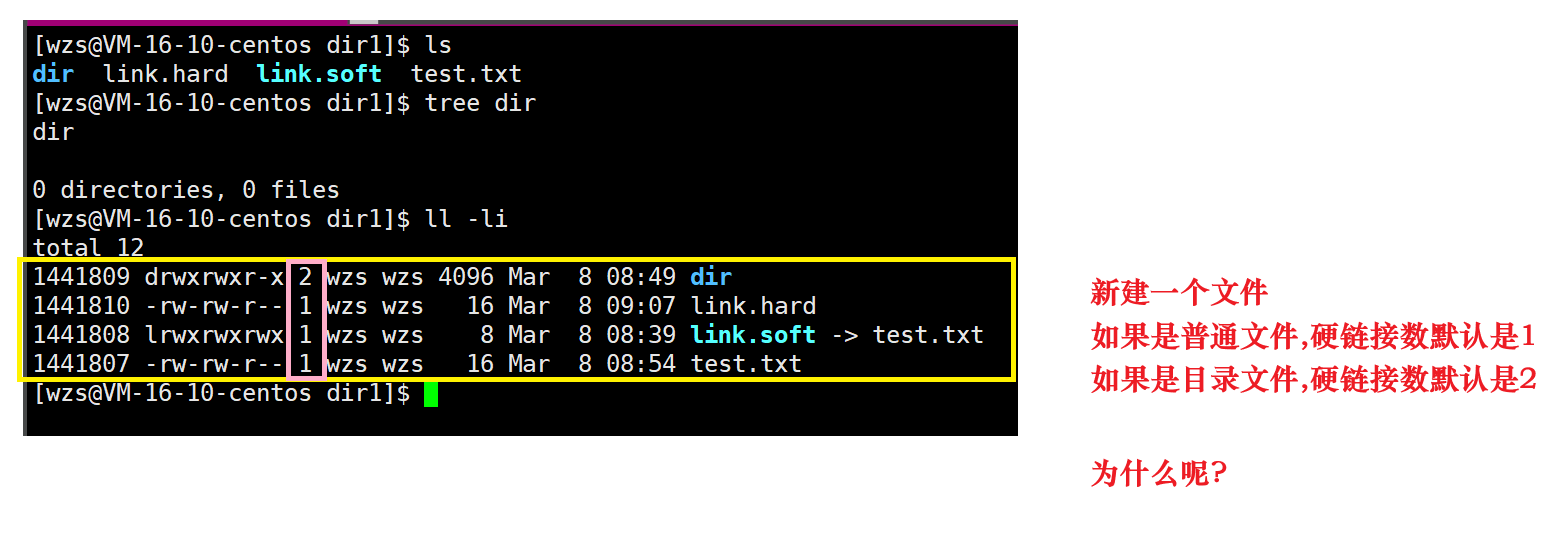
我们首先想到的就是这个目录当中有没有什么奇怪的东西呢?
还真有,就是我们习以为常的隐藏目录:一个点和两个点
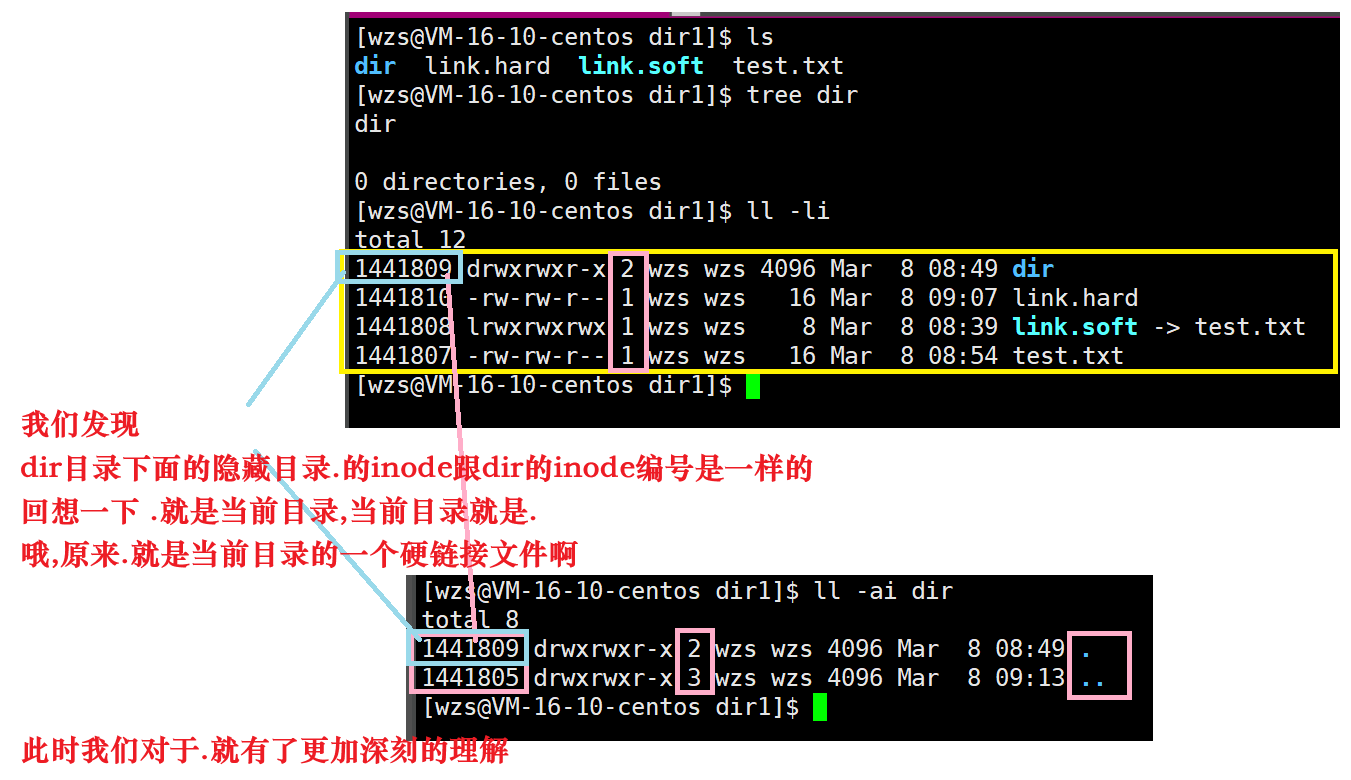
也就是说,新建一个目录时,因为这个目录当中默认就有隐藏目录.
而.就是这个目录的一个硬链接文件,因此新建目录的硬链接数就是2
可是又出现了另一个问题:
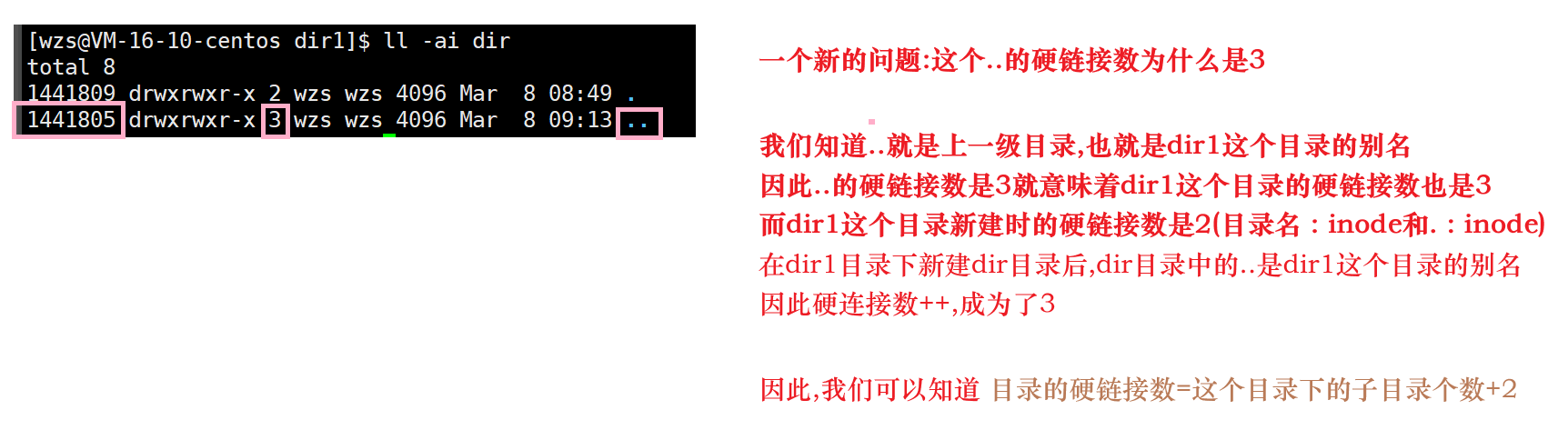
解决完这个问题之后,我们就能显而易见地看出硬链接的应用场景了
用于目录当中的一个点和两个点
我们知道:我们可以给普通文件创建硬链接文件,那么可不可以给目录文件创建硬链接文件呢?
我们试一下,不行

以上就是Linux文件系列:磁盘,文件系统,软硬链接的全部内容,希望能对大家有所帮助!







![LeetCode每日一题[c++]-322.零钱兑换](https://img-blog.csdnimg.cn/direct/ac538a8588c3496eae163cacb0d1863e.png)
