Windpowerlib 是一个提供了一系列函数和类的库,用于计算风力涡轮机的功率输出。它最初是 feedinlib(风能和光伏)的一部分,但后来被分离出来,以建立一个专注于风能模型的社区。
这个库的主要目的是简化风力涡轮机的能量产出计算。通过提供一组预先定义的函数和类,Windpowerlib 使得工程师和研究人员能够更容易地评估风力发电系统的性能。这有助于在风能项目的规划、设计和分析阶段进行更准确的预测和优化。
适用场景:
- 风力发电项目规划:可以用于评估不同地点的风资源情况,为风力发电项目的规划提供数据支持。
- 风力发电系统优化:可以用于优化风力发电系统的设计和运行参数,提高发电效率和经济性。
- 风电功率预测:可以用于对未来一段时间内的风力发电功率进行预测,为电力系统运营和调度提供参考。
- 风力发电技术研究:可以用于研究不同风力发电技术的性能特点和优化方法,推动风力发电技术的进步和应用。
1. 模型描述
1.1. 风力发电厂
windpowerlib提供了三个类用于模拟风力发电:风力涡轮机(WindTurbine)、风力发电厂(WindFarm)和风力涡轮机集群(WindTurbineCluster)。
1.2. 天气数据的高度相关与转换
通常,我们只能获得地面以上有限高度范围内的天气数据。然而,在进行风力发电时间序列计算时,我们需要在被测风力发电机的轮毂高度处获取天气数据。因此,Windpowerlib提供了用于天气数据高度校正的功能。
风速模块中描述了将风速校正到风力发电机轮毂高度的功能。相应地,温度模块中提供了一个用于温度数据高度校正的功能。密度模块中可以找到密度计算的功能。
如果至少有两个不同高度的天气数据可用,可以通过使用工具模块中的线性或对数插值/外推功能来确定轮毂高度处的相应数值。
1.3. 功率输出计算
在windpowerlib中,可以通过功率曲线和功率系数曲线来计算风力馈入时间序列。用于功率输出计算的函数在“功率输出”模块中描述。
1.4. 尾流损失
在风电场中,尾流损失(Wake Losses)是一个重要的考虑因素。尾流损失是由于上游涡轮机产生的尾流效应,导致下游涡轮机接收到的风速降低,进而影响了整个风电场的能源产量。为了考虑这种尾流损失,windpowerlib库提供了两种选择:
-
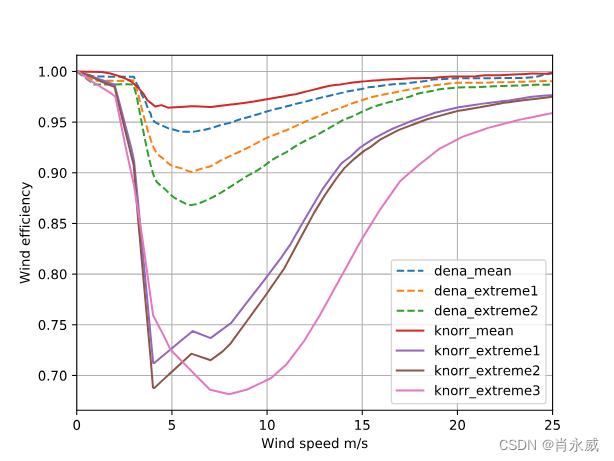
降低风速:通过使用风效率曲线(Wind Efficiency Curves),这些曲线描述了在不同风速下风电场内由于尾流损失导致的平均风速降低程度。windpowerlib提供了这些曲线,它们来自于dena-Netzstudie II研究和Kaspar Knorr的的论文(具体参考文献可通过get_wind_efficiency_curve()函数获取)。这些曲线是根据分布在德国各地的12个风电场(dena)或德国的2000多个风电场(Knorr)的风效率曲线平均得出的。
-
风电场效率(降低功率曲线中的功率):另一种方法是直接降低风电场的效率,即降低功率曲线中的功率输出。这可以通过在模拟或计算中使用降低后的效率值来实现。
提供的风效率曲线图中展示了所有可用的风效率曲线。这些曲线中带有“extreme”后缀的是单个风电场的风效率曲线,它们与相应的平均风效率曲线相比偏差极大。这些极端曲线有助于了解尾流损失的变异性和风电场之间的性能差异。
在风电场设计和性能分析中,选择合适的尾流损失模型和方法至关重要,因为它直接影响到风电场的能源产量预测和优化。使用windpowerlib提供的这些工具,可以更准确地模拟和评估风电场的实际性能。
在风电场模拟中,考虑尾流损失的第二种方法是将尾流损失应用于功率曲线,通过根据风电场的效率常数或在特定风速下减少功率值来实现(参见wake_losses_to_power_curve()函数)。与将风电场效率(曲线)应用于时间序列数据相比,将其应用于功率曲线具有进一步汇总以形成涡轮机集群功率曲线的优势(参见WindTurbineCluster)。
1.5. 功率曲线的平滑处理
为了考虑特定区域内风速的空间分布,windpowerlib库提供了一个用于功率曲线平滑处理的函数,它采用了Nørgaard和Holttinen的方法(具体参考文献可通过smooth_power_curve()函数获取)。平滑处理有助于减少由于测量误差、数据异常或湍流等因素导致的功率曲线波动,从而使功率曲线更接近实际情况。
1.6. 模型链(ModelChains)
模型链是windpowerlib库中的一个功能,旨在简化风电场模拟过程。它们类似于模型,将库中的所有功能组合在一起。通过指定所需的参数,用户可以选择使用windpowerlib库中的特定功能。对于未指定的参数,将使用默认值。
- ModelChain是一个用于确定单台风力涡轮机输出的模型。
- TurbineClusterModelChain是一个用于确定风电场或风力涡轮机集群输出的模型。
2. 安装
要求python3及以上环境。github地址:https://github.com/wind-python/windpowerlib。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple windpowerlib
3. 示例
示例模块展示了如何使用windpowerlib中的ModelChain类进行简单的风力发电计算。ModelChain类实现了一个模型链,确保用户能够轻松地开始使用Windpowerlib。它们就像将库中提供的所有功能组合在一起的模型一样工作。通过参数选择所需的windpowerlib功能。对于未指定的参数,将使用默认参数。
主要有三个步骤。首先,您需要导入天气数据,然后指定风力发电机,最后调用windpowerlib函数来计算馈入时间序列。
3.1. 数据说明
从文件中导入天气数据的。数据包括两个不同高度(单位:米/秒)的风速、两个不同高度(单位:开尔文)的空气温度、地表粗糙度长度(单位:米)和气压(单位:帕斯卡)。数据适用的高度(单位:米)在第二行指定。
- wind_speed,风速 (单位:米/秒)
- temperature,温度 (单位:开尔文)
- roughness_length, 粗糙度长度 (单位:米)
- pressure,压力 (单位:帕斯卡)
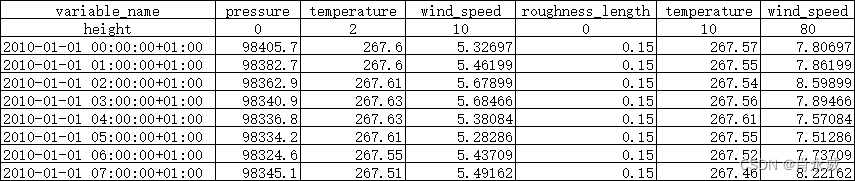
DataFrame 的列是一个 MultiIndex,其中第一级包含变量名(例如 ‘wind_speed’),第二级包含它适用的高度(例如,如果测量高度为10米,则为10)。索引是一个 DateTimeIndex。
数据文件地址:weather.csv。
3.2. 涡轮发电机模型说明
初始化三个WindTurbine对象:
- 使用windpowerlib提供的OpenEnergy Database(oedb)风力发电机库中的风力发电机数据,如下面的’enercon_e126’所示。
- 直接提供自己的功率(系数)曲线来指定自己的风力发电机,如下面的’my_turbine’所示。
- 在csv文件中提供自己的风力发电机数据,如下面的’my_turbine2’所示。
要获取所有提供了功率和/或功率系数曲线的风力发电机列表,可以执行
windpowerlib.wind_turbine.get_turbine_types()。
3.3. 使用ModelChain类计算风力发电机的输出功率
ModelChain是一个提供计算风力发电机功率输出所需的所有步骤的类。你可以使用默认的方法进行计算,如’my_turbine’所示,或者选择不同的方法,如’e126’所示。当然,你也可以在只改变一个或两个方法的情况下使用默认方法,如’my_turbine2’所示。
参数:
- weather : :pandas:
pandas.DataFrame<frame>
包含天气数据时间序列的数据框。 - my_turbine : :class:
~.wind_turbine.WindTurbine
具有自提供功率曲线的WindTurbine对象。 - e126 : :class:
~.wind_turbine.WindTurbine
具有来自OpenEnergy数据库风力发电机库的功率曲线的WindTurbine对象。 - my_turbine2 : :class:
~.wind_turbine.WindTurbine
具有来自示例文件的功率系数曲线的WindTurbine对象。
3.4. 示例代码
import pandas as pd
from windpowerlib import ModelChain, WindTurbine, create_power_curve
from matplotlib import pyplot as plt
def get_weather_data(filename="weather.csv"):
# read csv file
weather_df = pd.read_csv(
filename,
index_col=0,
header=[0, 1],
)
weather_df.index = pd.to_datetime(weather_df.index, utc=True)
# change time zone
weather_df.index = weather_df.index.tz_convert("Europe/Berlin")
return weather_df
def initialize_wind_turbines():
# **** Data is provided in the oedb turbine library **********************
enercon_e126 = {
"turbine_type": "E-126/4200", # turbine type as in register
"hub_height": 135, # in m
}
e126 = WindTurbine(**enercon_e126)
# **** Specification of wind turbine with your own data ******************
# **** NOTE: power values and nominal power have to be in Watt
my_turbine = {
"nominal_power": 3e6, # in W
"hub_height": 105, # in m
"power_curve": pd.DataFrame(
data={
"value": [
p * 1000
for p in [0.0, 26.0, 180.0, 1500.0, 3000.0, 3000.0]
], # in W
"wind_speed": [0.0, 3.0, 5.0, 10.0, 15.0, 25.0],
}
), # in m/s
}
my_turbine = WindTurbine(**my_turbine)
# **** Specification of wind turbine with data in own file ***************
# Read your turbine data from your data file using functions like
# pandas.read_csv().
# >>> import pandas as pd
# >>> my_data = pd.read_csv("path/to/my/data/file")
# >>> my_power = my_data["my_power"]
# >>> my_wind_speed = my_data["my_wind_speed"]
my_power = pd.Series(
[0.0, 39000.0, 270000.0, 2250000.0, 4500000.0, 4500000.0]
)
my_wind_speed = (0.0, 3.0, 5.0, 10.0, 15.0, 25.0)
my_turbine2 = {
"nominal_power": 6e6, # in W
"hub_height": 115, # in m
"power_curve": create_power_curve(
wind_speed=my_wind_speed, power=my_power
),
}
my_turbine2 = WindTurbine(**my_turbine2)
return my_turbine, e126, my_turbine2
def calculate_power_output(weather, my_turbine, e126, my_turbine2):
# **** ModelChain with non-default specifications ************************
modelchain_data = {
"wind_speed_model": "logarithmic", # 'logarithmic' (default),
# 'hellman' or
# 'interpolation_extrapolation'
"density_model": "ideal_gas", # 'barometric' (default), 'ideal_gas' or
# 'interpolation_extrapolation'
"temperature_model": "linear_gradient", # 'linear_gradient' (def.) or
# 'interpolation_extrapolation'
"power_output_model": "power_coefficient_curve", # 'power_curve'
# (default) or 'power_coefficient_curve'
"density_correction": True, # False (default) or True
"obstacle_height": 0, # default: 0
"hellman_exp": None,
} # None (default) or None
# initialize ModelChain with own specifications and use run_model method
# to calculate power output
mc_e126 = ModelChain(e126, **modelchain_data).run_model(weather)
# write power output time series to WindTurbine object
e126.power_output = mc_e126.power_output
# ************************************************************************
# **** ModelChain with default parameter *********************************
mc_my_turbine = ModelChain(my_turbine).run_model(weather)
# write power output time series to WindTurbine object
my_turbine.power_output = mc_my_turbine.power_output
# ************************************************************************
# **** ModelChain with non-default value for "wind_speed_model" **********
mc_example_turbine = ModelChain(
my_turbine2, wind_speed_model="hellman"
).run_model(weather)
my_turbine2.power_output = mc_example_turbine.power_output
return
def plot_or_print(my_turbine, e126, my_turbine2):
# plot or print turbine power output
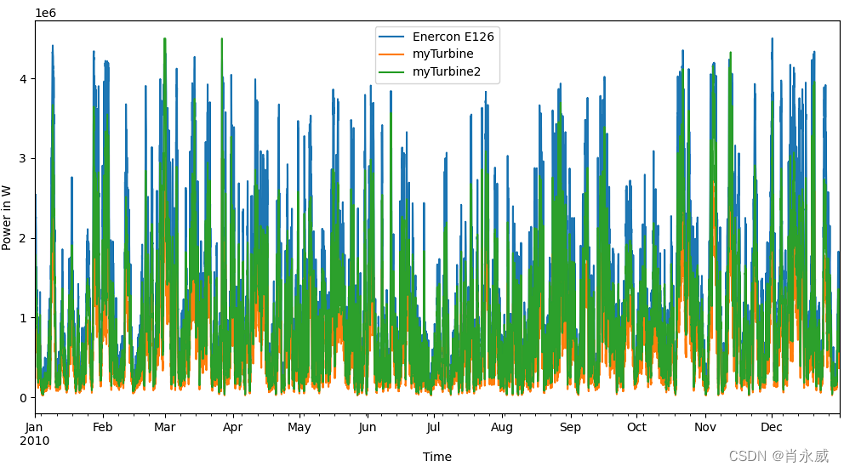
e126.power_output.plot(legend=True, label="Enercon E126")
my_turbine.power_output.plot(legend=True, label="myTurbine")
my_turbine2.power_output.plot(legend=True, label="myTurbine2")
plt.xlabel("Time")
plt.ylabel("Power in W")
plt.show()
# plot or print power curve
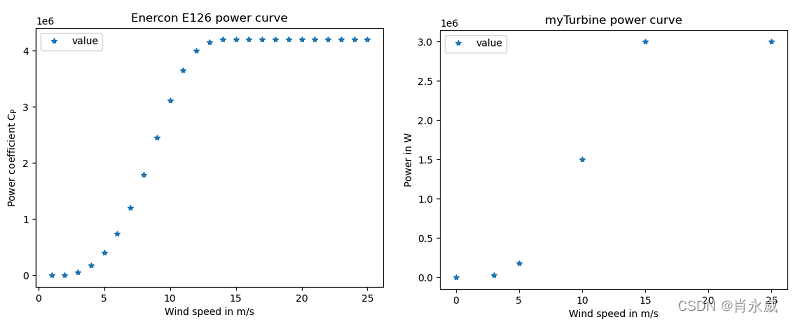
if e126.power_curve is not False:
e126.power_curve.plot(
x="wind_speed",
y="value",
style="*",
title="Enercon E126 power curve",
)
plt.xlabel("Wind speed in m/s")
plt.ylabel("Power coefficient $\mathrm{C}_\mathrm{P}$")
plt.show()
if my_turbine.power_curve is not False:
my_turbine.power_curve.plot(
x="wind_speed",
y="value",
style="*",
title="myTurbine power curve",
)
plt.xlabel("Wind speed in m/s")
plt.ylabel("Power in W")
plt.show()
if my_turbine2.power_curve is not False:
my_turbine2.power_curve.plot(
x="wind_speed",
y="value",
style="*",
title="myTurbine2 power curve",
)
plt.xlabel("Wind speed in m/s")
plt.ylabel("Power in W")
plt.show()
def run_example():
weather = get_weather_data("weather.csv")
my_turbine, e126, my_turbine2 = initialize_wind_turbines()
calculate_power_output(weather, my_turbine, e126, my_turbine2)
plot_or_print(my_turbine, e126, my_turbine2)
if __name__ == "__main__":
run_example()
3.5. 结果
全年功率曲线
风速功率曲线
4. 总结
Windpowerlib的主要目标是为风能行业提供一个简单易用的工具,以支持风力涡轮机的设计和优化。
风力涡轮发电模型构成:
- 风速模型:根据地理位置、气候条件等因素,生成风速时间序列数据。
- 风力涡轮机模型:包括涡轮机的功率曲线、叶片几何参数、控制系统等。
- 风场布局模型:描述风力涡轮机在风场中的布局和相对位置。
- 尾流模型:计算风力涡轮机之间的尾流影响,评估风场内的能量损失。
特点:
- 灵活性:Windpowerlib提供了丰富的接口,可以根据需要自定义各种参数和模型。
- 易于使用:Windpowerlib的设计初衷是简化风力涡轮机的建模和分析过程,因此它的API设计简洁明了,易于上手。
- 可扩展性:Windpowerlib的架构允许用户轻松地添加新的功能和模型,以满足特定需求。
优点:
- 快速评估风力涡轮机的性能:通过Windpowerlib,用户可以快速计算风力涡轮机的功率曲线、能量产量等关键性能指标。
- 支持多种场景分析:Windpowerlib支持多种场景分析,如不同风速、不同风向、不同地形等条件下的性能评估。
- 可视化结果:Windpowerlib提供了丰富的可视化工具,可以直观地展示风力涡轮机的性能和风场布局等信息。