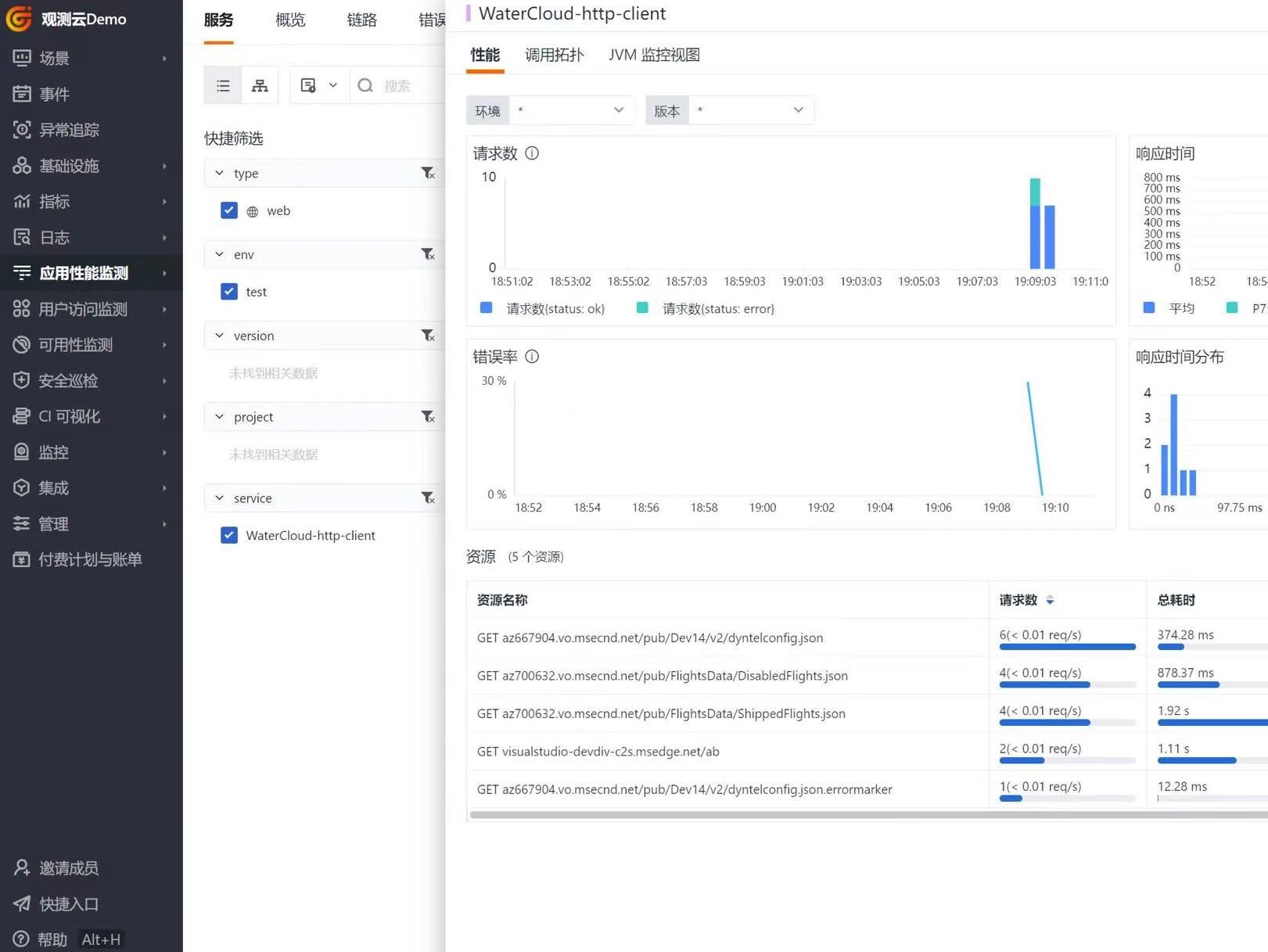
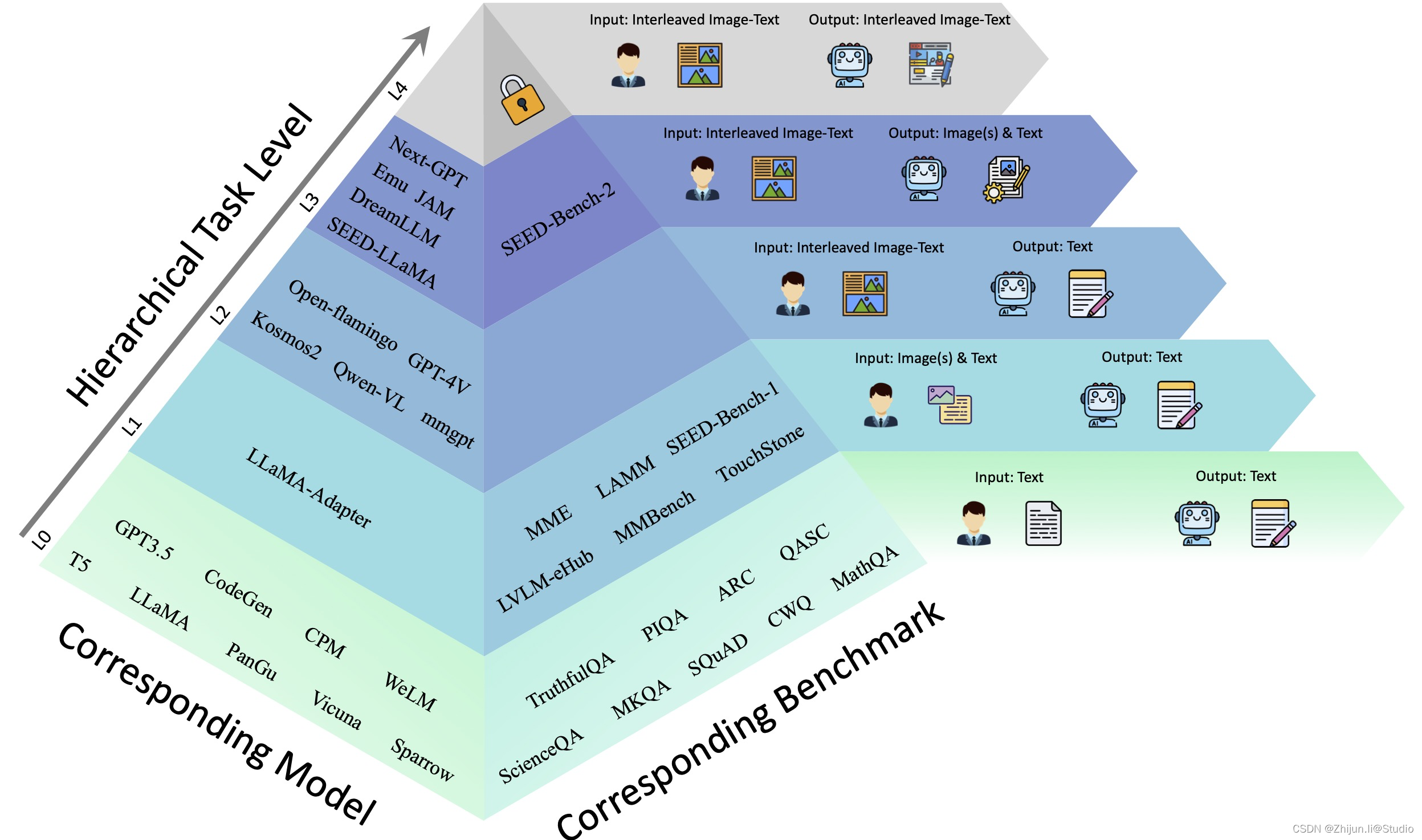
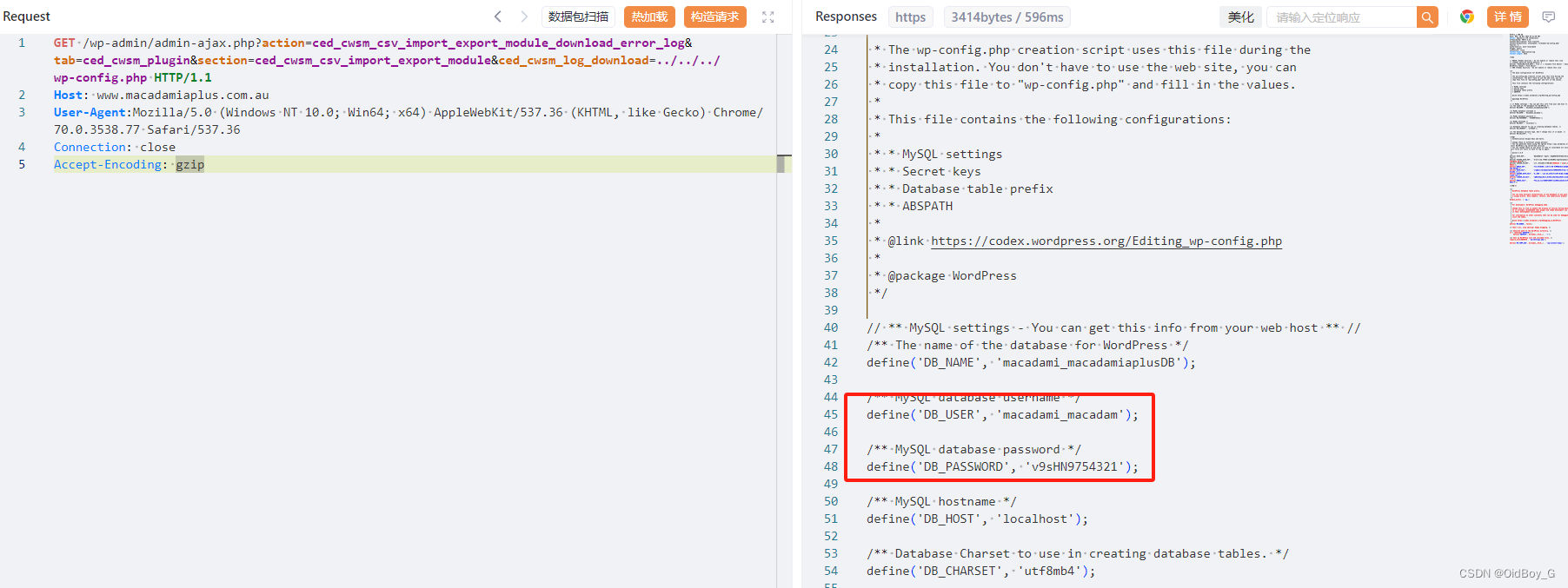
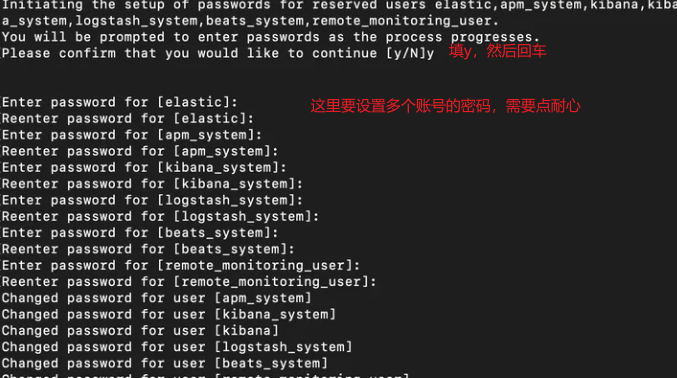
要实现试卷的OCR识别算法,可以采取以下步骤:
-
数据预处理:首先需要对试卷图片进行预处理,包括图像降噪、灰度化、二值化等操作,以便提高后续文字识别的准确性。
-
文字检测:利用文字检测算法定位试卷图片中的文字区域,可以使用传统的基于边缘检测或者深度学习的方法来实现文字检测。
-
文字识别:对文字区域进行OCR文字识别,将图片中的文字转换为计算机可识别的文本信息。可以使用深度学习模型,如基于卷积神经网络(CNN)和循环神经网络(RNN)的模型,如CRNN模型或Transformer模型,进行文字识别。
-
后处理:对识别的文本结果进行后处理,包括去除错误识别的字符、纠正错别字等操作,以提高最终识别结果的准确性。
-
结果输出:将识别的文本结果输出到文本文件或数据库中,以便后续进行文字分析或其他处理。
以上是一个简单的试卷OCR识别算法的基本步骤,具体的实现过程可以根据具体需求和场景进行调整和优化。