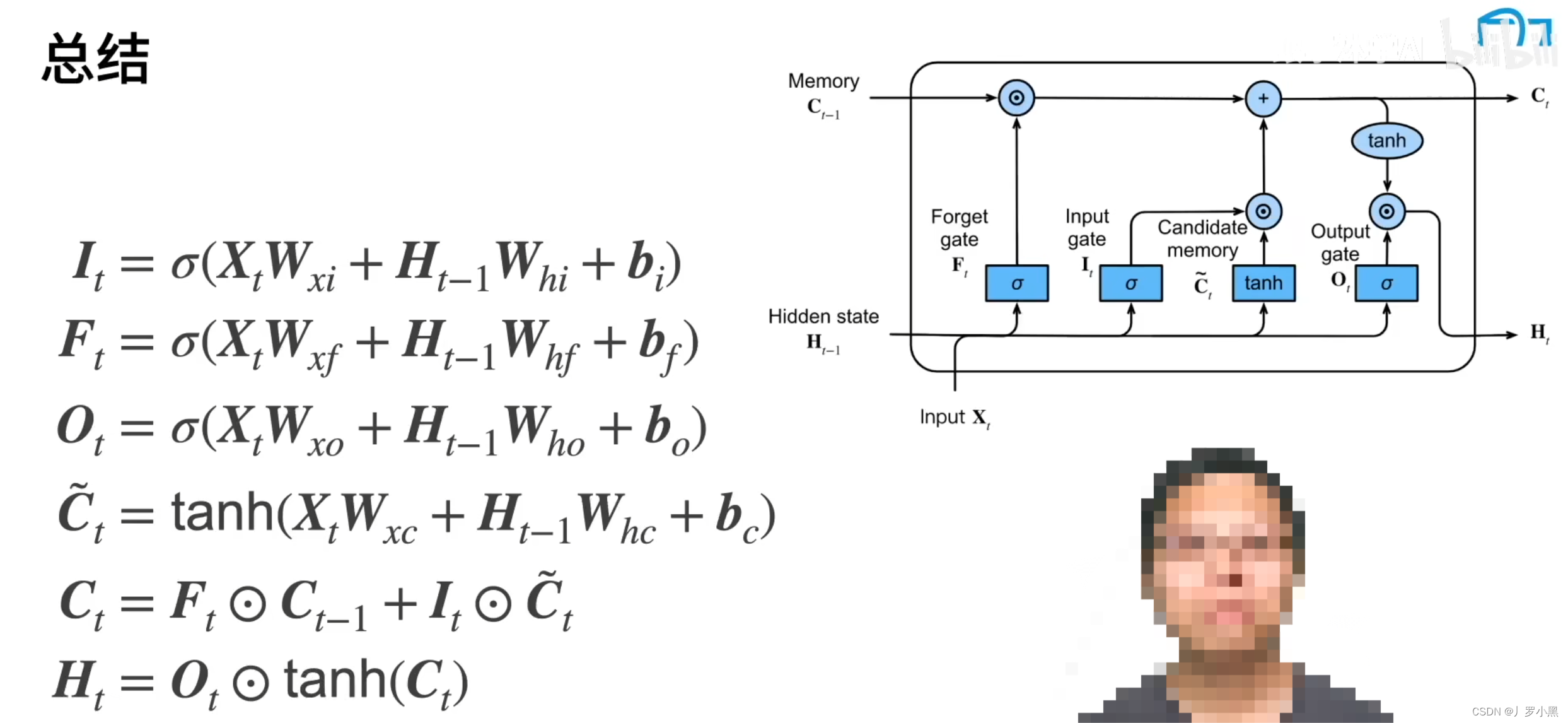
Bayesian optimization 是一种用于调节机器学习模型超参数的方法,而随机森林 (Random Forest, RF) 是一种强大的机器学习算法,常用于回归和分类任务。将它们结合起来可以提高模型性能,这就是 Bayes-RF 的基本思想。
下面是一个基于贝叶斯优化算法优化随机森林(RF)数据回归预测的典型流程:
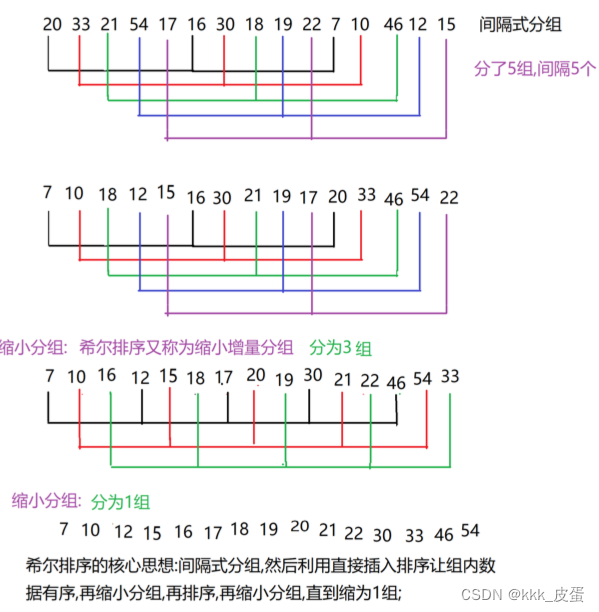
-
准备数据:
- 准备包含特征和目标变量的数据集。确保数据集已经进行了预处理,包括缺失值处理、特征缩放等。
- 将数据集划分为训练集和测试集,以便在模型训练和评估中使用。
-
定义目标函数:
- 创建一个评估指标,用于衡量模型的性能。通常情况下,回归任务中可以使用均方误差(Mean Squared Error, MSE)或其他适当的指标。
- 定义一个目标函数,接受随机森林的超参数作为输入,并返回评估指标的值。
-
选择优化算法:
- 选择合适的贝叶斯优化算法库,例如
BayesianOptimization或Optuna。 - 确定超参数的搜索空间,包括随机森林的树的数量、树的最大深度、叶子节点的最小样本数等。
- 选择合适的贝叶斯优化算法库,例如
-
进行贝叶斯优化:
- 在定义的超参数搜索空间中,使用贝叶斯优化算法来寻找最佳超参数组合。
- 在每次迭代中,根据先前的评估结果,选择下一个要评估的超参数组合,以尽可能快地找到全局最优解。
- 在目标函数中评估每个超参数组合,并记录评估结果。
-
获取最佳超参数:
- 根据贝叶斯优化的结果,确定最佳的超参数组合。
-
训练模型:
- 使用在上一步中找到的最佳超参数组合,在整个训练集上训练随机森林模型。
-
评估模型:
- 使用测试集评估训练好的模型的性能,以确保模型在未见过的数据上的泛化能力。
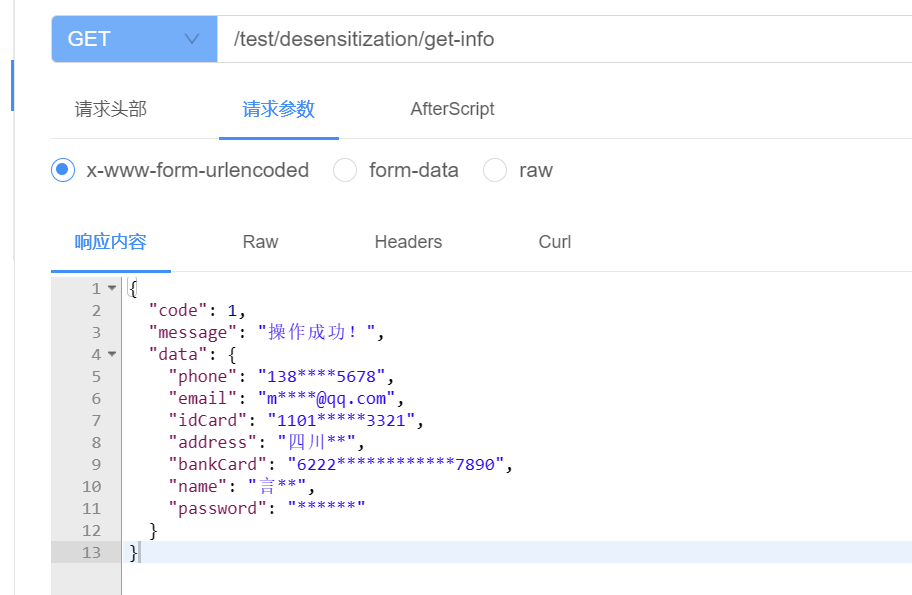
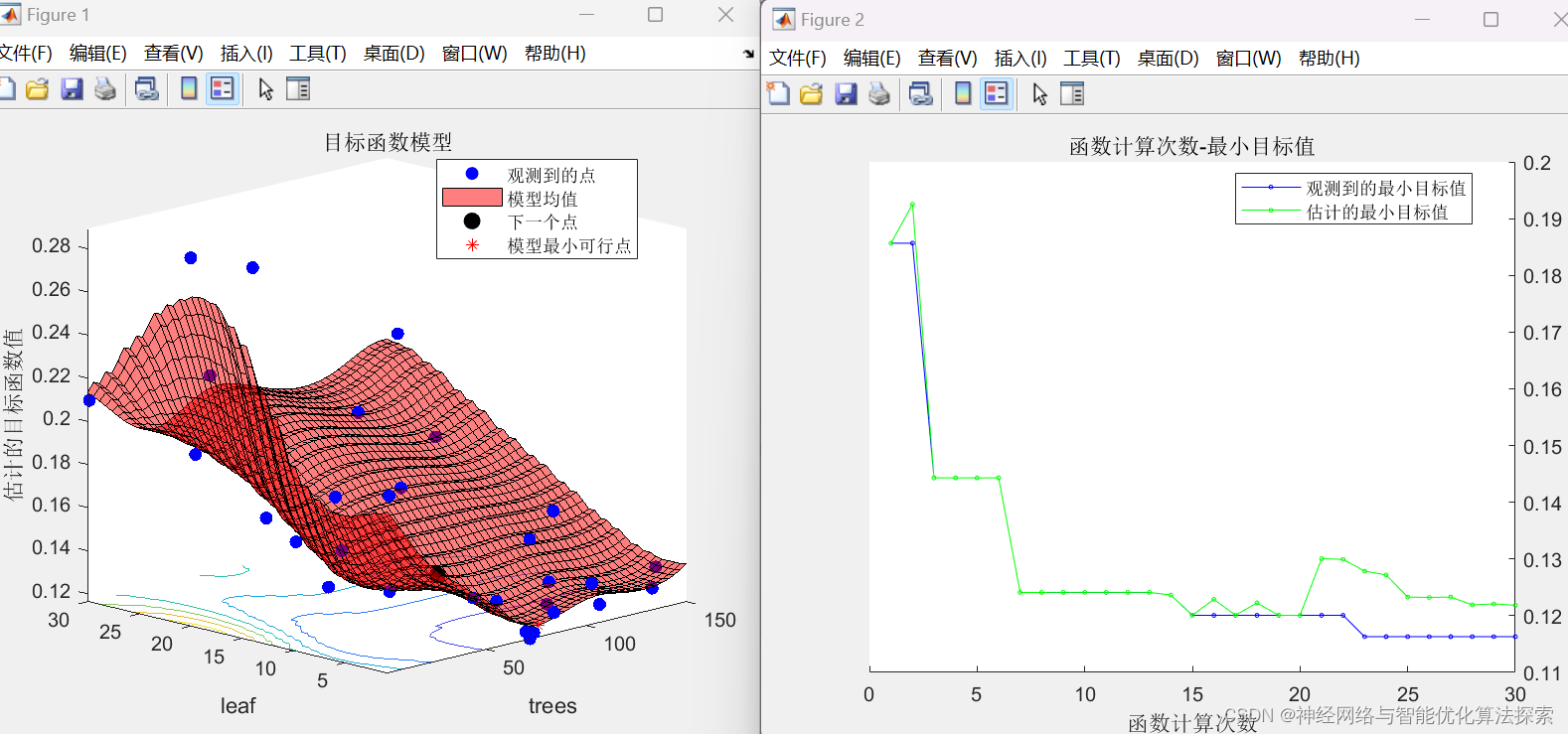
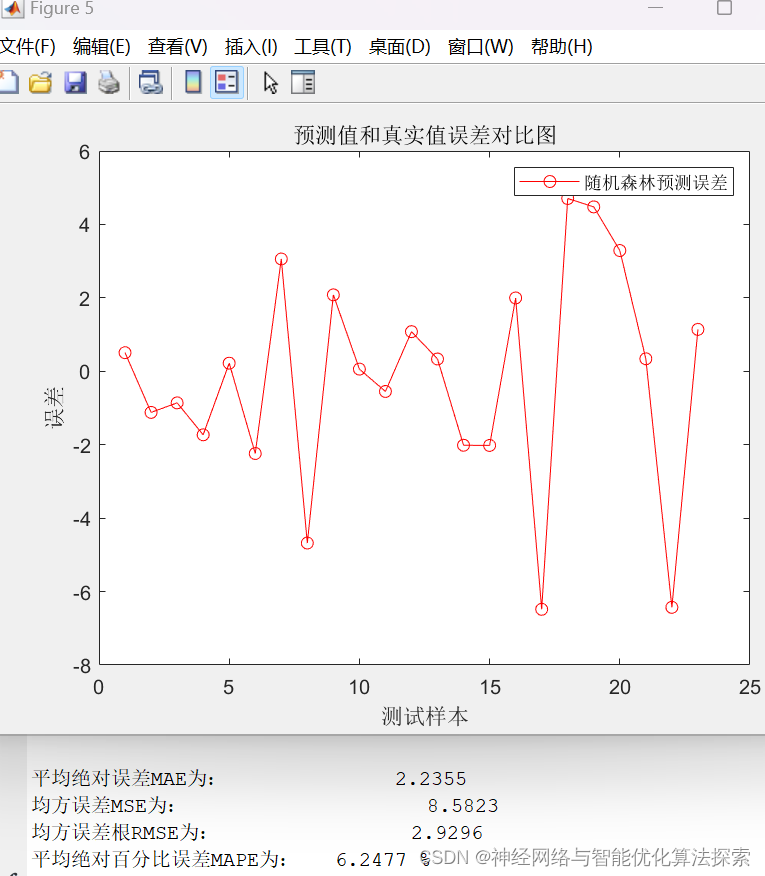
测试结果如下:


代码获取方式如下:
https://mbd.pub/o/bread/mbd-ZZ2Tmp1p