【探索多模态视觉问答】数据集概览及特点分析
引言
在计算机视觉和自然语言处理领域,视觉问答(VQA)是一个重要的任务,旨在让计算机理解图像内容并回答关于图像的问题。为了促进和评估多模态模型在视觉问答任务上的表现,研究人员构建了多个丰富的数据集。本文将介绍几个主要的视觉问答数据集,包括VQA v2.0、VizWiz-VQA、GQA、POPE、MM-VET、MME、MMBench和SEED-Bench。我们将分析这些数据集的特点、构建方式以及在评估多模态模型方面的作用,旨在为研究人员提供对多模态视觉问答数据集的全面认识。
VQA-V2
VQA (v2.0) 全称 Visual Question Answering (v2.0),是一个人工标注的、关于图像的开放式问答数据集。回答这些问题,需要对图像、语言以及常识都具备一定的理解力。
该数据集包括:
- 265,016 张图像(源自 COCO 以及 abstract scenes 数据集)
- 每幅图像涉及到的问题数量大于等于 3(平均 5.4个问题)
- 每个问题包含 10 个基准真相 (ground truth)
- 每个问题包含 3 个合理(但不一定正确)的答案
- 自动评估指标

下载链接:https://hyper.ai/datasets/15514
VizWiz-VQA
VizWiz-VQA (Visual Question Answering) 是一个盲人视觉问答的图像数据集。盲人用户使用 VizWiz 软件拍摄一张照片,并记录一个关于该照片的口头问题和该问题的 10 个众包答案。该数据集用于解决以下两个问题,一是预测一个视觉问题的答案,二是判断一个视觉问题能否被回答。

下载链接:https://hyper.ai/datasets/17831
GQA
以往的VQA数据集总是被大家诟病存在各种缺陷
- 数据集总是存在明显的语言先验,比如说,当问及的一个桌子的材料的时候,答案十有八九是木头。这样一来,模型只需要学会挖掘训练数据的统计规律就能很好地回答问题,而不需要准确地理解场景;
- 数据集中的大多数问题没有用到组合式的语言,从而仅仅测试了模型的物体识别能力,模型缺乏基于视觉的推理能力。比如说,上图这个问题包含很多的对象和一些关系,这种组合式的问题对VQA模型来说是很难的,原先数据集压根儿就无法训练模型的推理能力;
- 以前的数据集缺乏将问题中的关键词与图中的对应区域相联系的标记信息,这使得研究者难以定位出模型出错的原因。
为了解决以上这些问题,构造了GQA数据集,用于真实世界图像推理和组合问题回答。
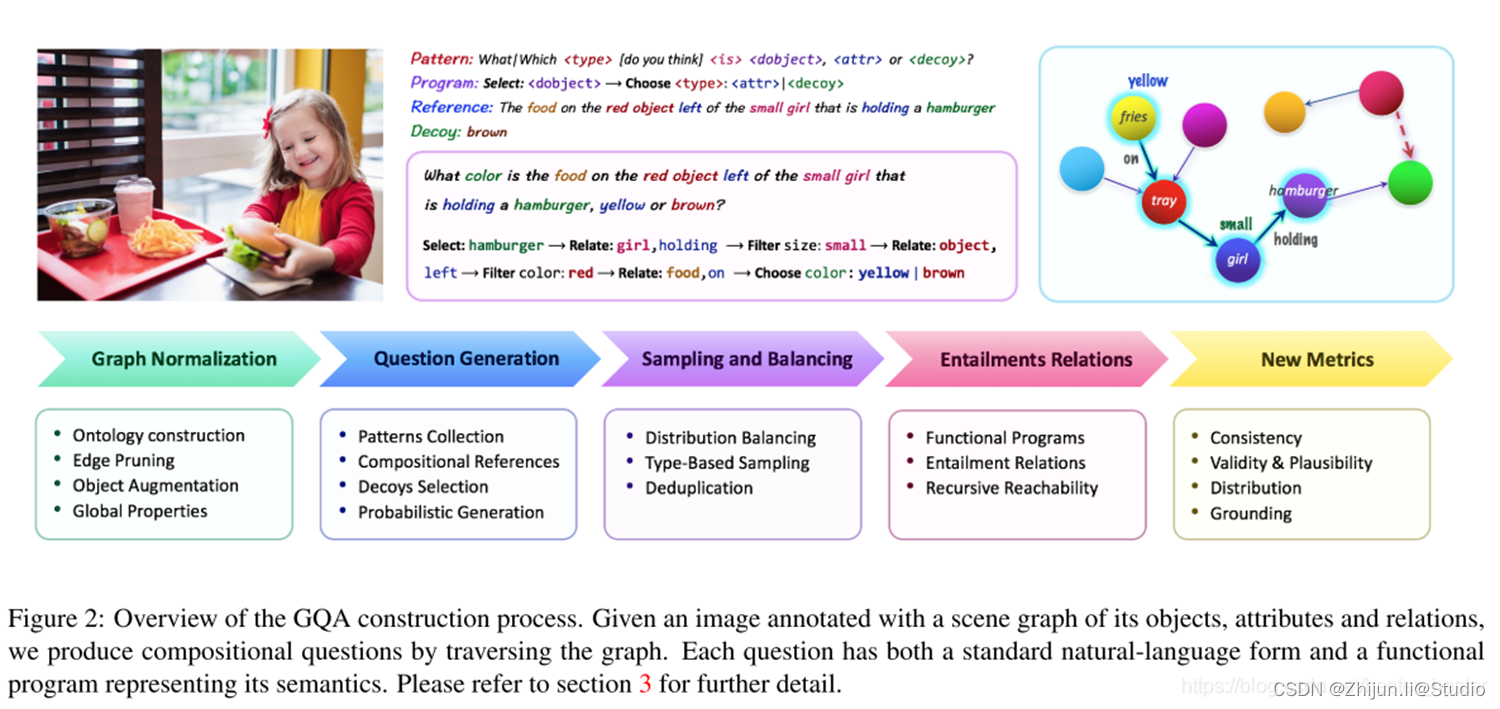
GQA数据集按照图中这些流程进行构造,构建的流程和细节非常多非常复杂,大的流程主要有四步:
(1)获取每张图像的场景图(这一步用的另一个数据集:Visual Genome数据集的研究成果);
(2)遍历图中的对象,对象的属性以及对象之间的关系,生成语义丰富且多样的问题;
(3)减少答案分布的偏差,从而得到一个平衡的数据集;
(4)讨论问题功能表示,给出回答一个问题的所需要的推理步骤。
下载链接:https://cs.stanford.edu/people/dorarad/gqa/download.html
参考链接:https://blog.csdn.net/qq_40481602/article/details/125627062
PPOE
POPE 将幻觉评估转换为让模型回答一系列关于物体是否存在于图像中的判断题(例如’Is there a car in the image?')。具体而言,给定一个图像数据集和每张图像包含的物体标注,POPE将构造一系列由图像,问题和回答组成的三元组。
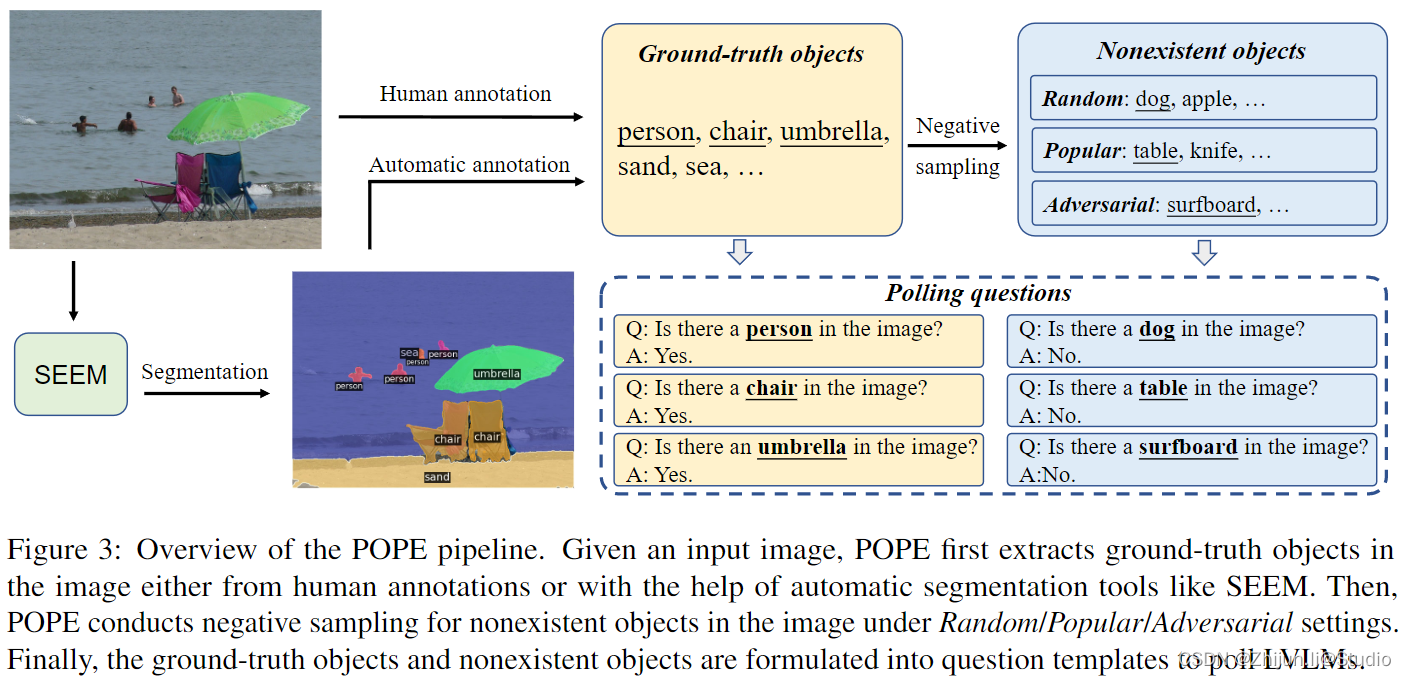
github链接:https://github.com/RUCAIBox/POPE
参考文章:https://www.kuxai.com/article/1327
MM-VET
与传统的VL基准测试只需要一两个能力不同,MM-Vet专注于不同核心VL能力的集成,包括识别、OCR、知识、语言生成、空间感知和数学。
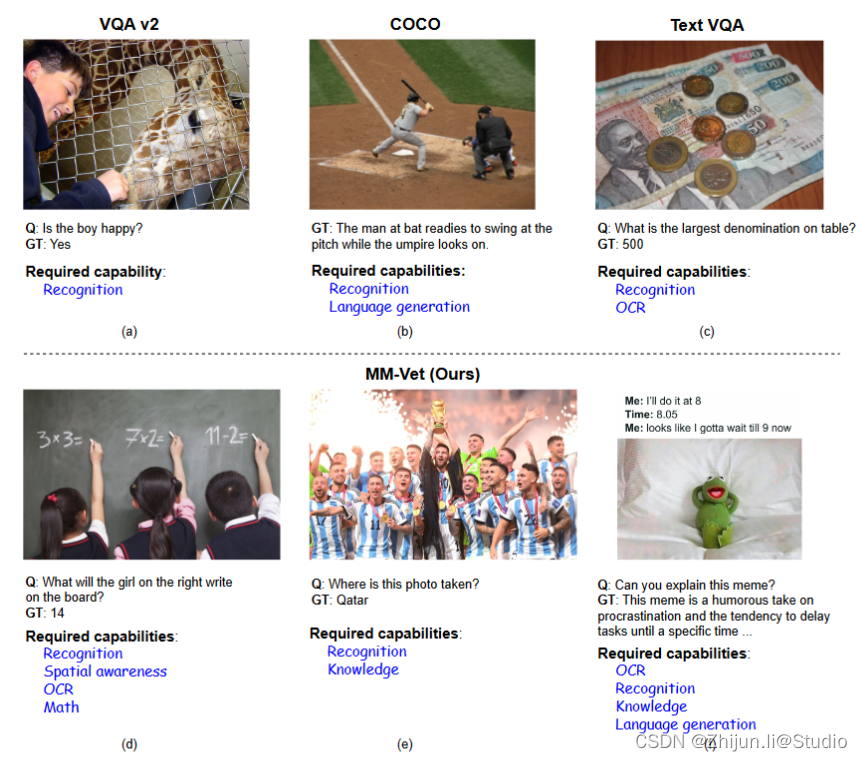
github链接:https://github.com/yuweihao/MM-Vet
MME
(1)MME涵盖了感知和认知能力的考试。除了OCR,感知还包括粗粒度和细粒度对象的识别。前者识别物体的存在、数量、位置和颜色。后者可以识别电影海报、名人、场景、地标和艺术品。认知包括常识推理,数值计算,文本翻译,代码推理。子任务总数达到14个。
(2)所有指令-答案对都是手动构建的。对于研究中涉及的少数公共数据集,只使用图像,而不直接依赖其原始注释。同时,通过真实照片和图像生成来收集数据。
(3)MME的指令设计简洁,避免了提示工程对模型输出的影响。一个好的MLLM应该能够推广到这样简单和经常使用的指令,这对所有模型都是公平的。
(4)得益于“请回答是或否”的指令设计,可以很容易地根据MLLM的“是”或“否”输出进行定量统计,准确客观。

论文链接:https://paperswithcode.com/paper/mme-a-comprehensive-evaluation-benchmark-for
MM-Bench
MMBench 是从公共数据集和互联网等多个来源收集的,目前包含 2974 道选择题,涵盖 20 个能力维度。将现有的20个能力维度构建为3个能力维度级别,从L-1到L-3。
- 将感知和推理作为能力分类中的顶级能力维度,称为 L-1能力维度。
- 对于L-2能力,我们从L-1感知推导出:1.粗粒度感知,2.细粒度单实例感知,3.细粒度跨实例感知;以及 1. 属性推理,2.关系推理,3. L-1 推理的逻辑推理。使我们的基准尽可能细粒度,以便为开发多模态模型提供信息反馈。
- 我们进一步从 L-2 能力维度推导出L-3 能力维度。
MMBench 是第一个涵盖如此多能力维度的大规模评估多模态数据集。
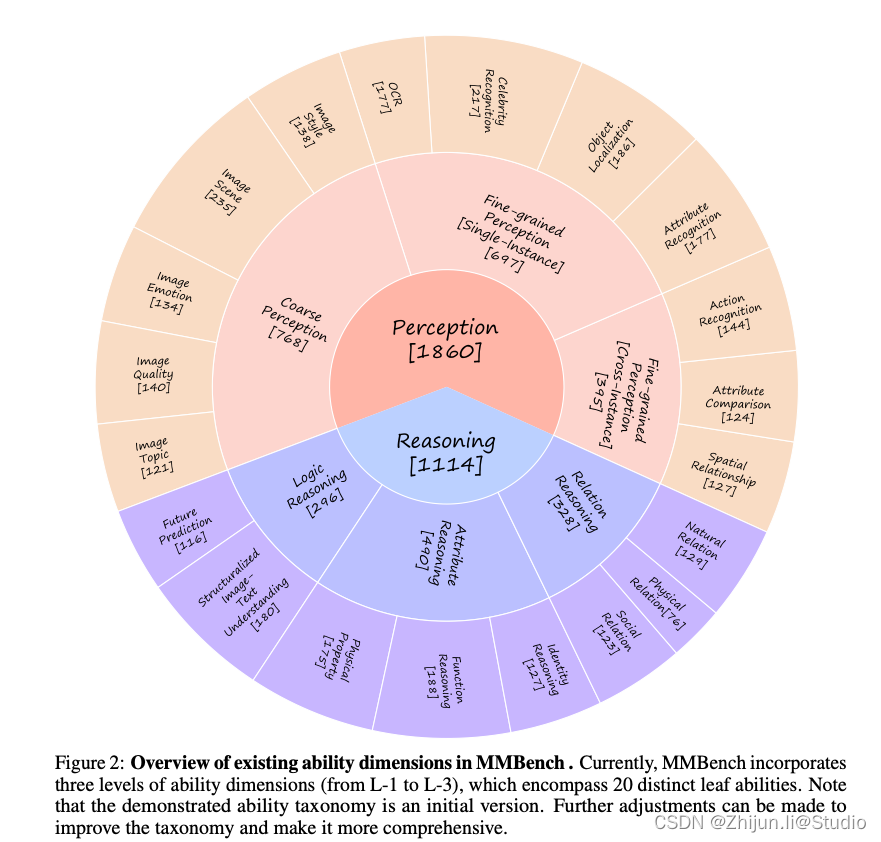
github链接:https://github.com/open-compass/MMBench
SEED-Bench
SEED-Bench-2 包含 24K 个多项选择题,具有准确的人工注释,跨越 27 个维度,包括文本和图像生成的评估。
github链接:https://github.com/ailab-cvc/seed-bench