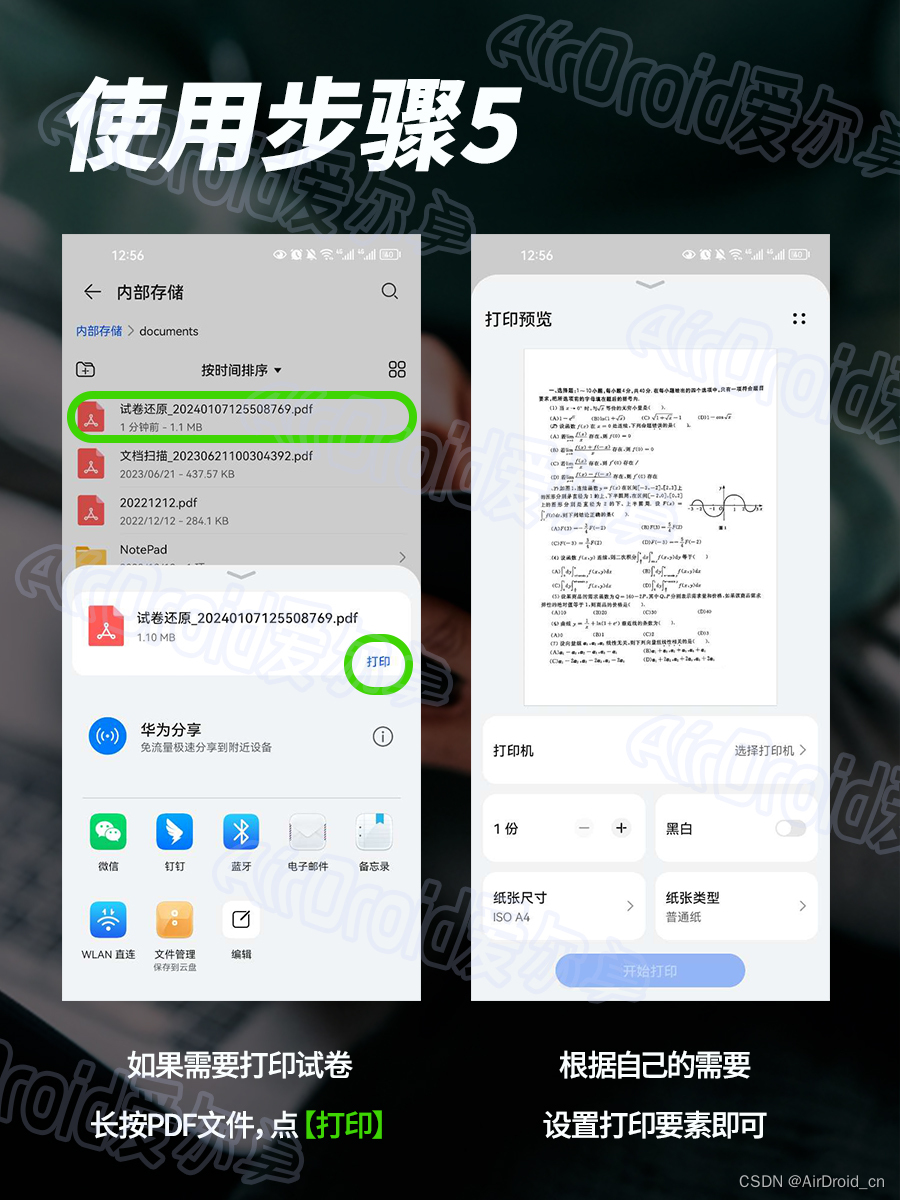
Self-Attention和RNN、LSTM的区别
- RNN的缺点:无法做长序列,当输入很长时,最后面的输出很难参考前面的输入,即长序列会缺失上文信息,如下:
- 可能一段话超过50个字,输出效果就会很差了
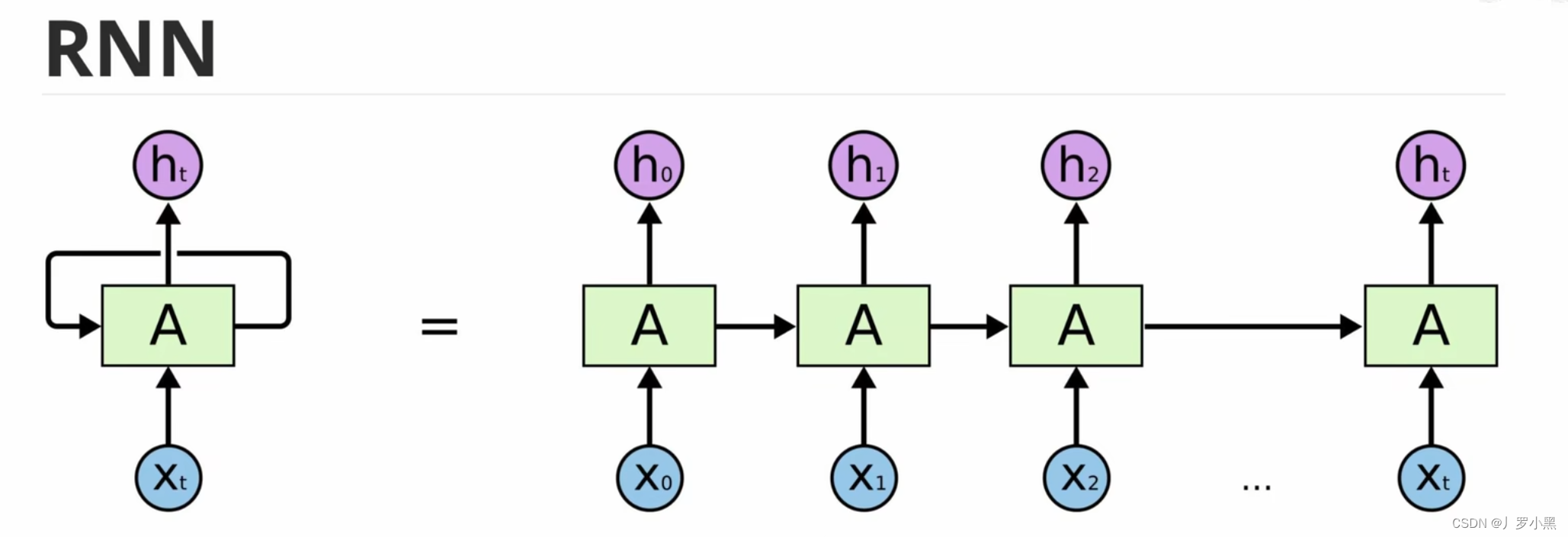
- 可能一段话超过50个字,输出效果就会很差了
- LSTM通过忘记门、输入门、输出门、记忆单元,来有选择性的记忆之前的信息,如下:
- 可能一段话超过200个字,输出效果才会很差
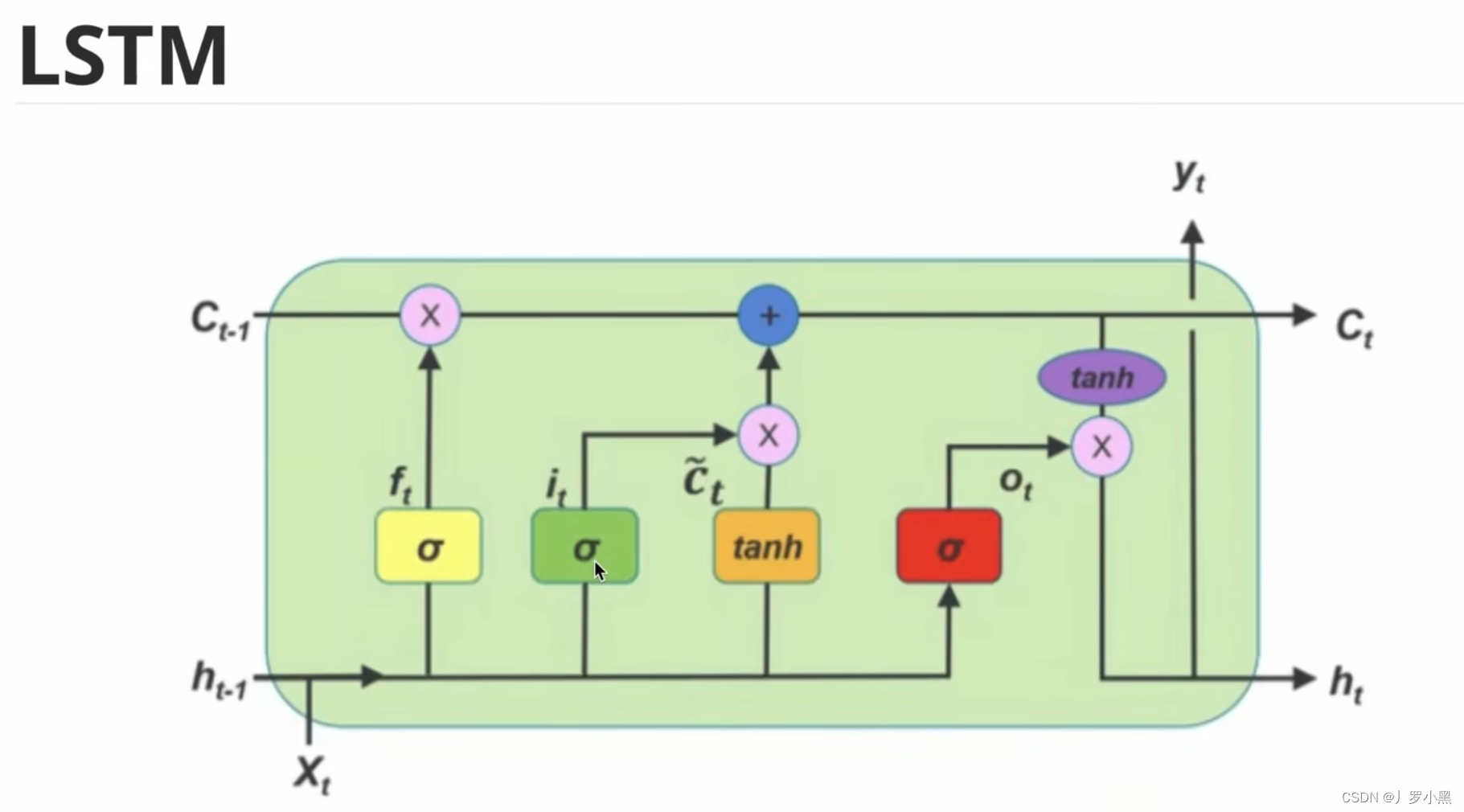
- 可能一段话超过200个字,输出效果才会很差
- 总结:RNN和LSTM无法解决长序列依赖问题,而且它们都是序列模型,必须上一个做完了才能做下一个,无法做并行
- Self-Attention针对以上的两个问题,有以下解决
- 1、由于集合中的每一个词都会和其他的词做相似度计算,所以即使序列再长,两个词之间的联系都能通过相似度存储到它们的词向量上,保留下来。
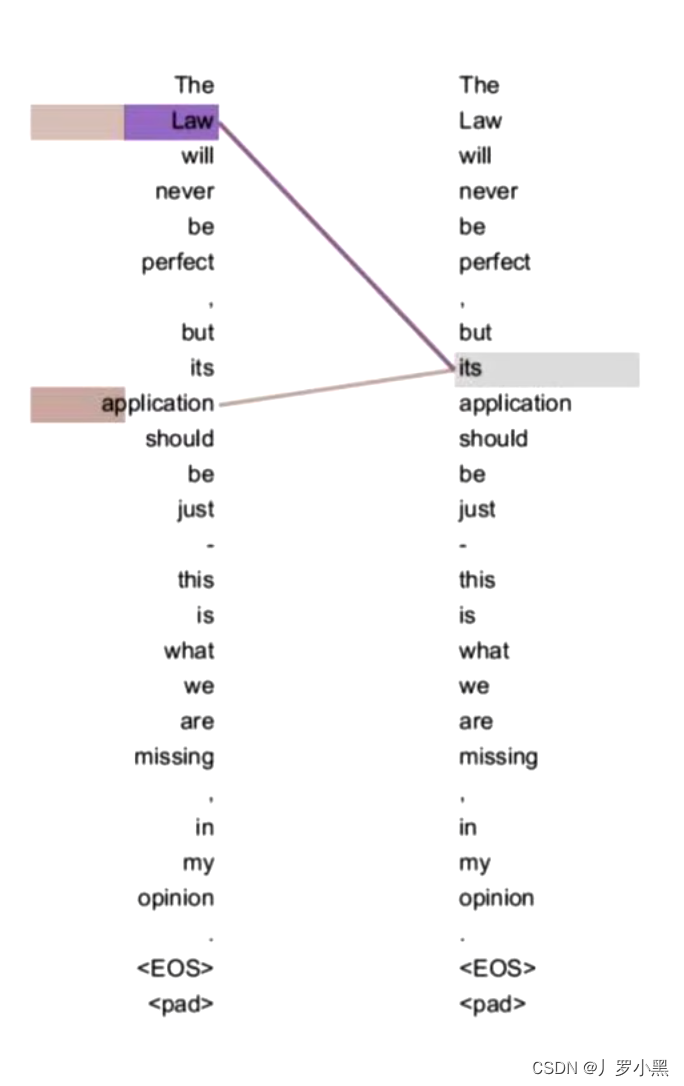
- 1、由于集合中的每一个词都会和其他的词做相似度计算,所以即使序列再长,两个词之间的联系都能通过相似度存储到它们的词向量上,保留下来。
- 2、由于我们将集合中的每一个词都要得到它的Q、K、V,并要做相似度计算以及乘和操作,所以不需要等前一个词做完了才能做下一个词,而是可以很多个词一起做,可以做并行,如下:
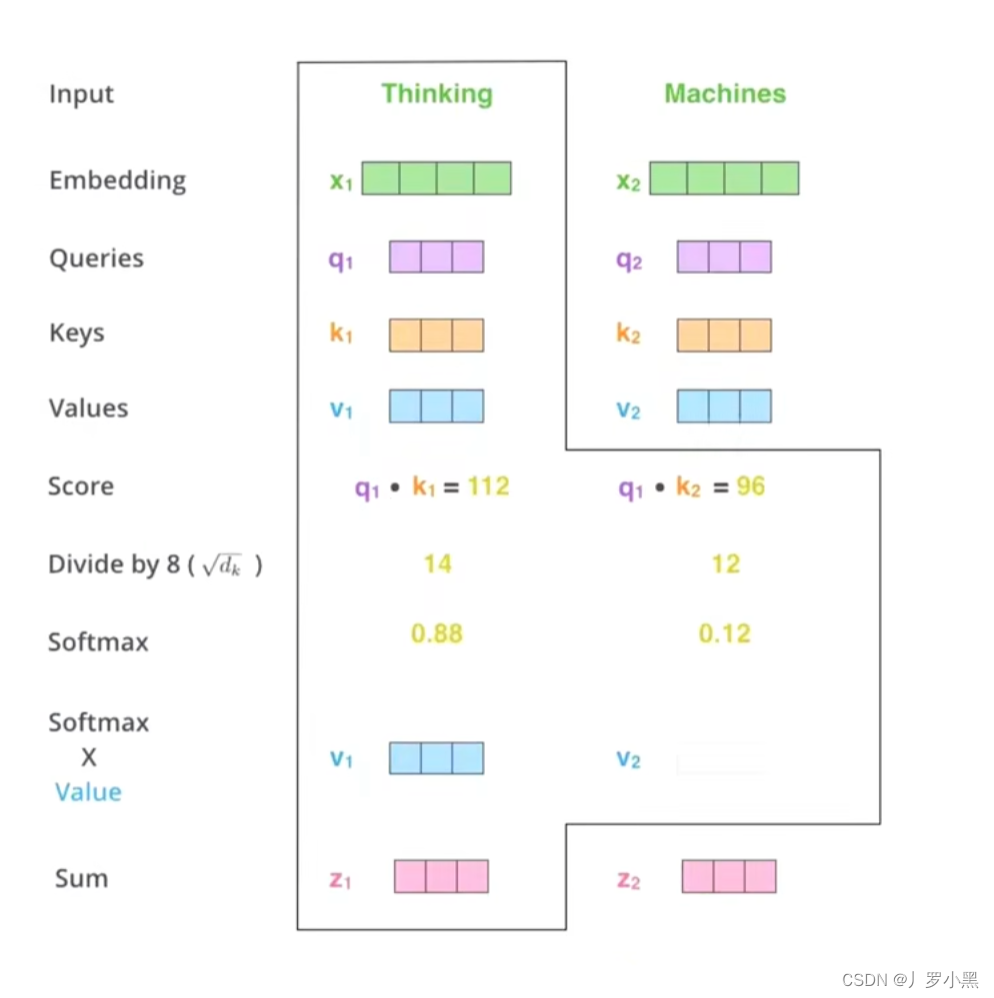
- 而且,通过Self-Attention得到的新的词向量具有句法特征和语义特征(词向量的表征更完善)
- 但是,Self-Attention的计算量特别大(集合中的每一个单词和其他所有单词都要计算相似度),所以在文本量为50个单词左右,模型的效果最好。而LSTM虽然没有解决长序列依赖,但是它在处理长文本任务时,文本量在200个单词左右,模型的效果最好
RNN(循环神经网络)
- RNN,当前的输出 o t o_t ot取决于上一个的输出 o t − 1 o_{t-1} ot−1(作为当前的输入 x t − 1 x_{t-1} xt−1)和当前状态下前一时间的隐变量 h t h_t ht,隐变量和隐变量的权重 W h h W_hh Whh存储当前状态下前一段时间的历史信息,如果我们去掉 W h h ∗ h t − 1 W_{hh} * h_{t-1} Whh∗ht−1,RNN就退化为MLP
- 在RNN中,我们根据前一个的输出和当前的隐变量,就可以预测当前的输出。当前的隐变量也是由上一个隐变量和前一个输出
(即当前的输入)所决定的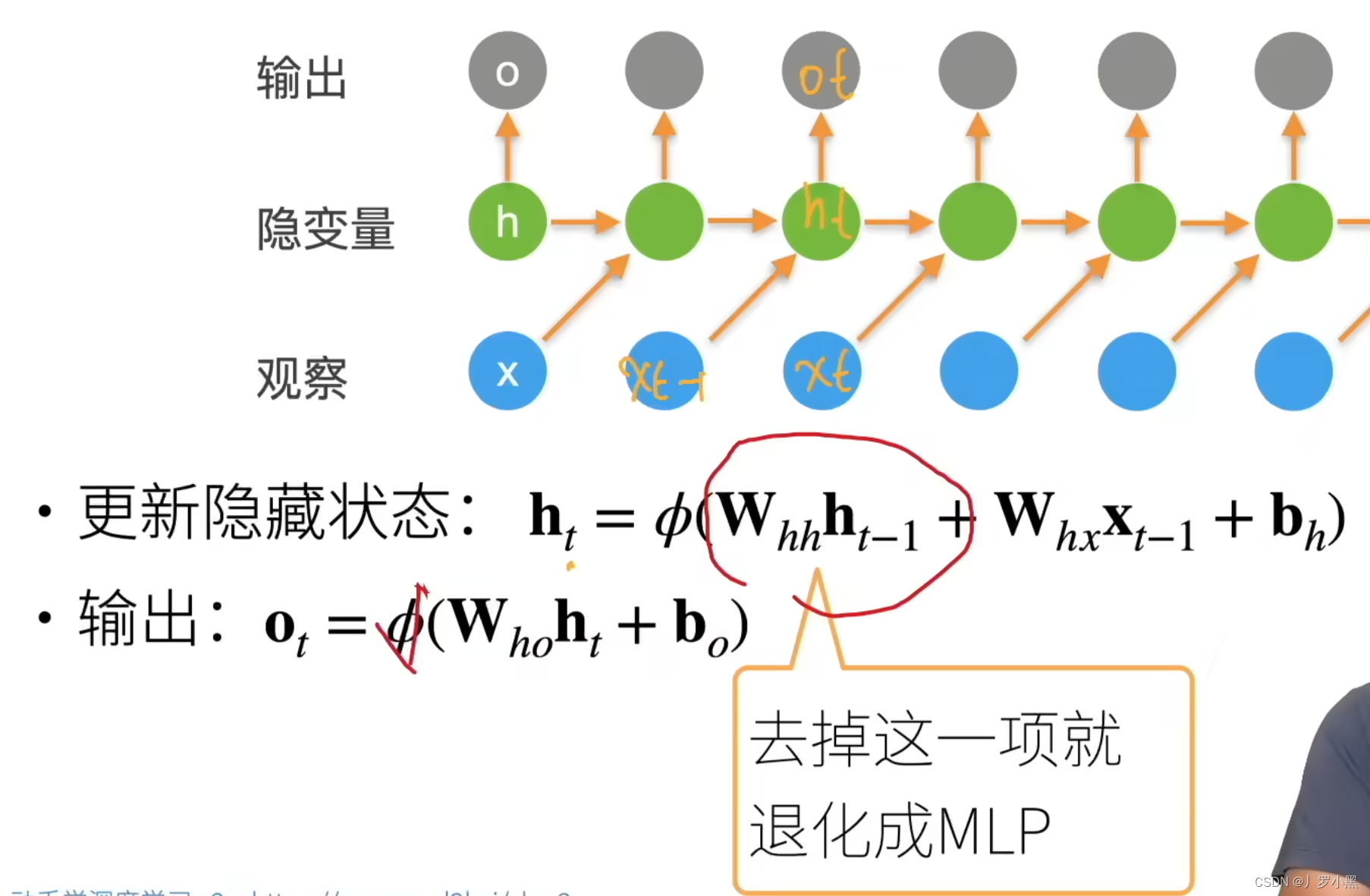

- 所以RNN其实就是MLP多了一个时间轴,能存储前一段时间的历史信息,并根据这个历史信息来更新层的参数
- 同时由于RNN会不加选择的存储前一段时间的历史信息,所以如果序列太长,即句子太长,隐变量会存储太多信息,那么RNN就不容易提取很早之前的信。
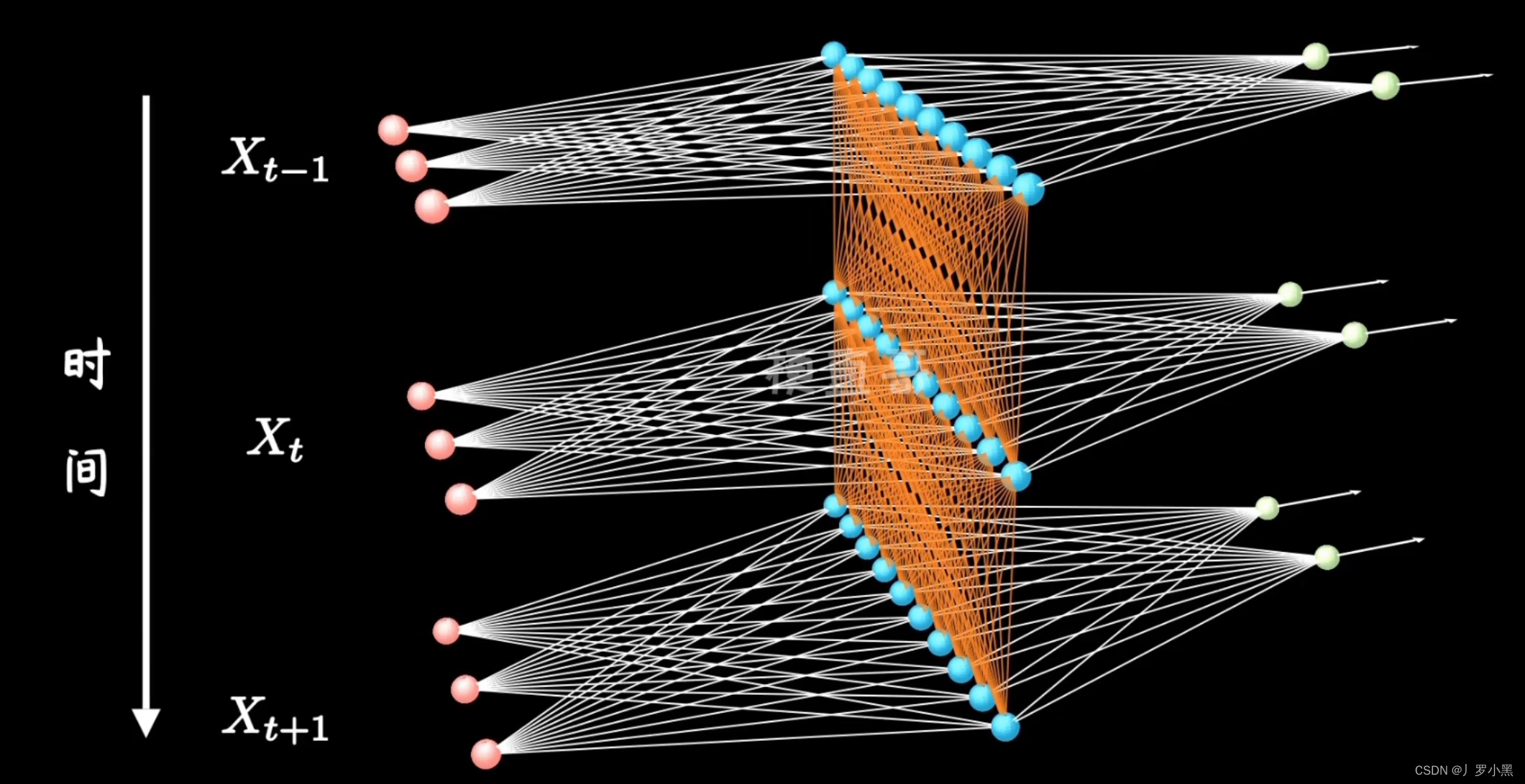
- 同时由于RNN会不加选择的存储前一段时间的历史信息,所以如果序列太长,即句子太长,隐变量会存储太多信息,那么RNN就不容易提取很早之前的信。
GRU(门控神经网络)
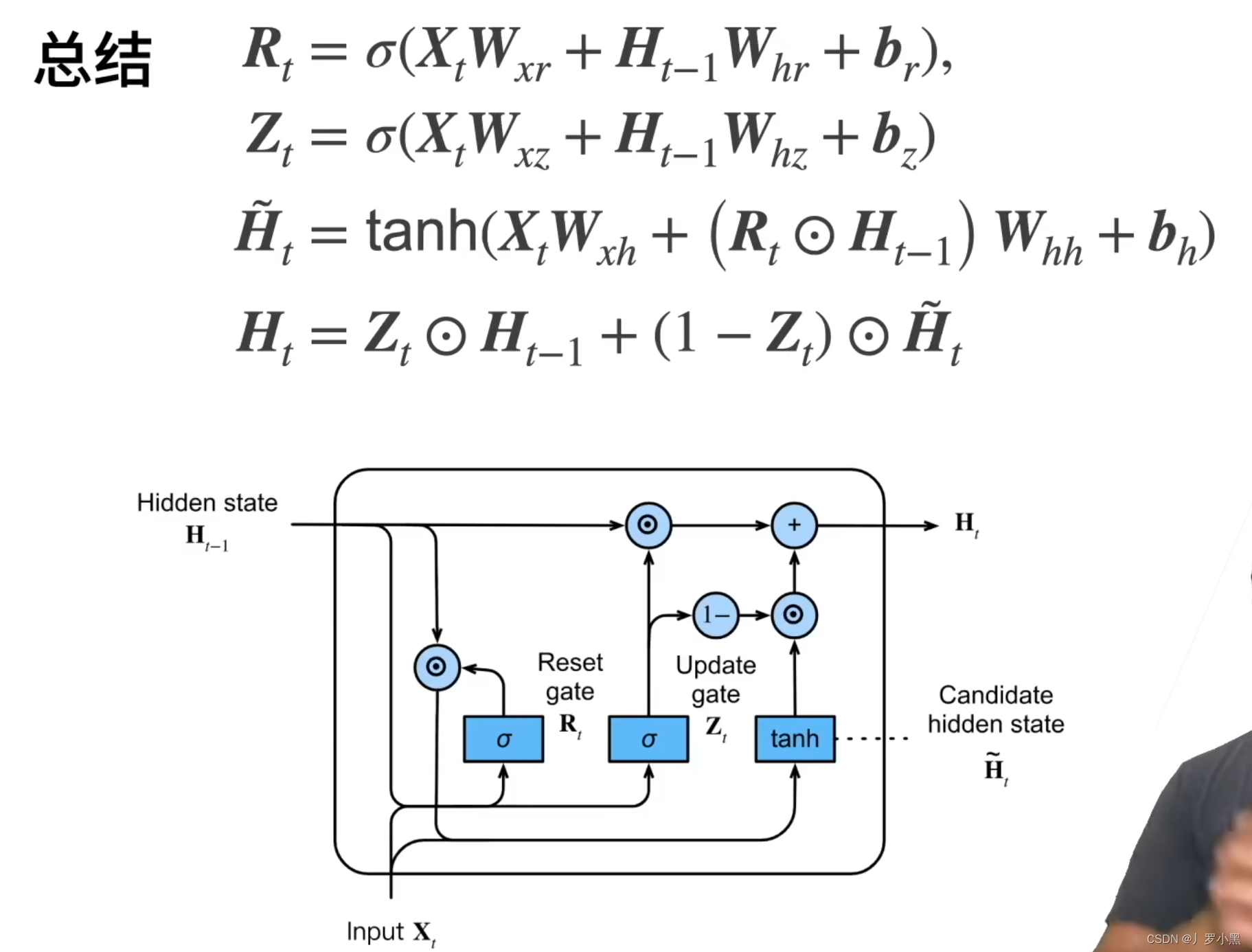
- 为了解决RNN处理不了很长的序列,我们可以有选择的存储历史信息,通过更新门和重置门,来只关注有变化的重点信息

- GRU引入了
R
t
R_t
Rt、
Z
t
Z_t
Zt、
H
~
t
\widetilde{H}_t
H
t
- 其中
R
t
R_t
Rt、
Z
t
Z_t
Zt为控制单元,是可以学习的参数,由于最后用了sigmoid函数,所以范围在(0,1),表示要不要进行Reset和Update操作

- 其中
H
~
t
\widetilde{H}_t
H
t为候选隐变量,跟
R
t
R_t
Rt有关,
R
t
∗
H
t
−
1
R_t * H_{t-1}
Rt∗Ht−1表示:候选隐变量要使用多少过去隐变量的信息

- 而 H t H_t Ht为真正的新的隐变量,跟 Z t Z_t Zt有关, ( 1 − Z t ) ⊙ H ~ t (1 - Z_t)\odot\widetilde{H}_t (1−Zt)⊙H t表示:新的隐变量要使用多少当前输入的信息
- 通常情况下:GRU会在以下极端情况中,进行可学习的调整,来决定是多去看当前的输入信息,还是多去看前一次的隐变量
- 极端情况如下:
- 其中
R
t
R_t
Rt、
Z
t
Z_t
Zt为控制单元,是可以学习的参数,由于最后用了sigmoid函数,所以范围在(0,1),表示要不要进行Reset和Update操作
- 当 Z t Z_t Zt为0, R t R_t Rt为1时: H t H_t Ht = H ~ t \widetilde{H}_t H t,不遗忘前一次的隐变量,GRU就退化为RNN
- 当 Z t Z_t Zt为1时:不考虑候选隐变量, H t H_t Ht = H t − 1 H_{t-1} Ht−1,即不使用 X t X_t Xt更新隐变量,当前隐变量和上一次的隐变量相同
- 当
R
t
R_t
Rt为0,
Z
t
Z_t
Zt为0时:
H
t
H_t
Ht =
H
~
t
\widetilde{H}_t
H
t,不使用前一次的隐变量,只用
X
t
X_t
Xt来更新隐变量
LSTM(长短期记忆网络)
- LSTM和GRU都是实现这个效果:是要多去看现在的输入信息,还是要多去看前一次的隐变量,即过去的信息
- 但是LSTM可以多实现一个效果:什么都不看,直接重置清零
- LSTM中的状态有两个:
C
t
C_t
Ct记忆单元、
H
t
H_t
Ht隐变量
- 注意:LSTM额外引入的 C t C_t Ct记忆单元, C t C_t Ct的范围无法保证,可以用来增加模型复杂度,多存储信息。但是最终仍然需要让 H t H_t Ht的范围仍在(-1,1)之间,防止梯度爆炸。
- 注意:LSTM中的忘记门、输入门、输出门的具体公式和GRU的更新门、重置门一样
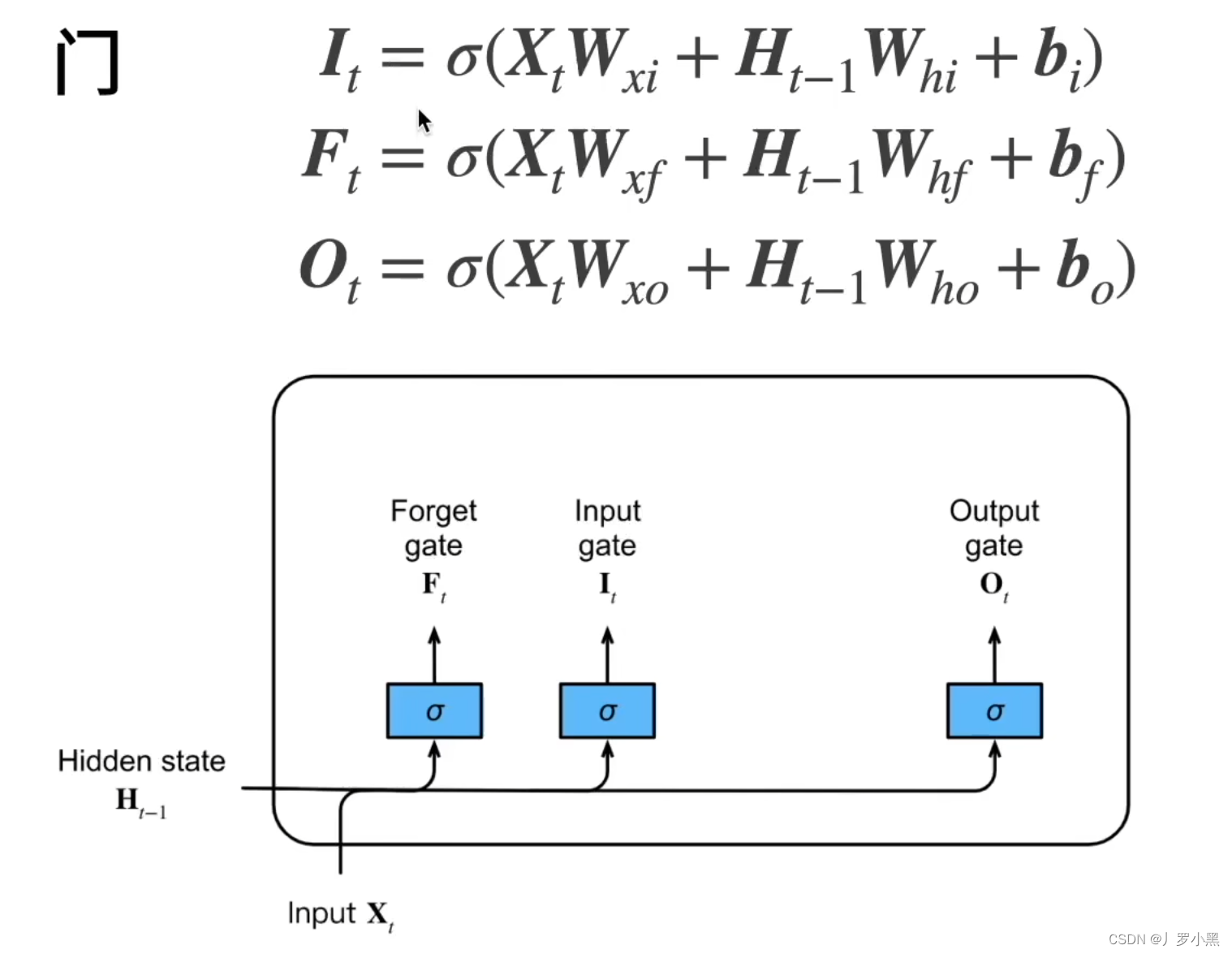

-
C
~
t
\widetilde{C}_t
C
t候选记忆单元:LSTM中的候选记忆单元和RNN中的
H
t
H_t
Ht的计算公式一样,没有用到任何门,但是由于最后用了tanh(),所以范围在(-1,1)之间

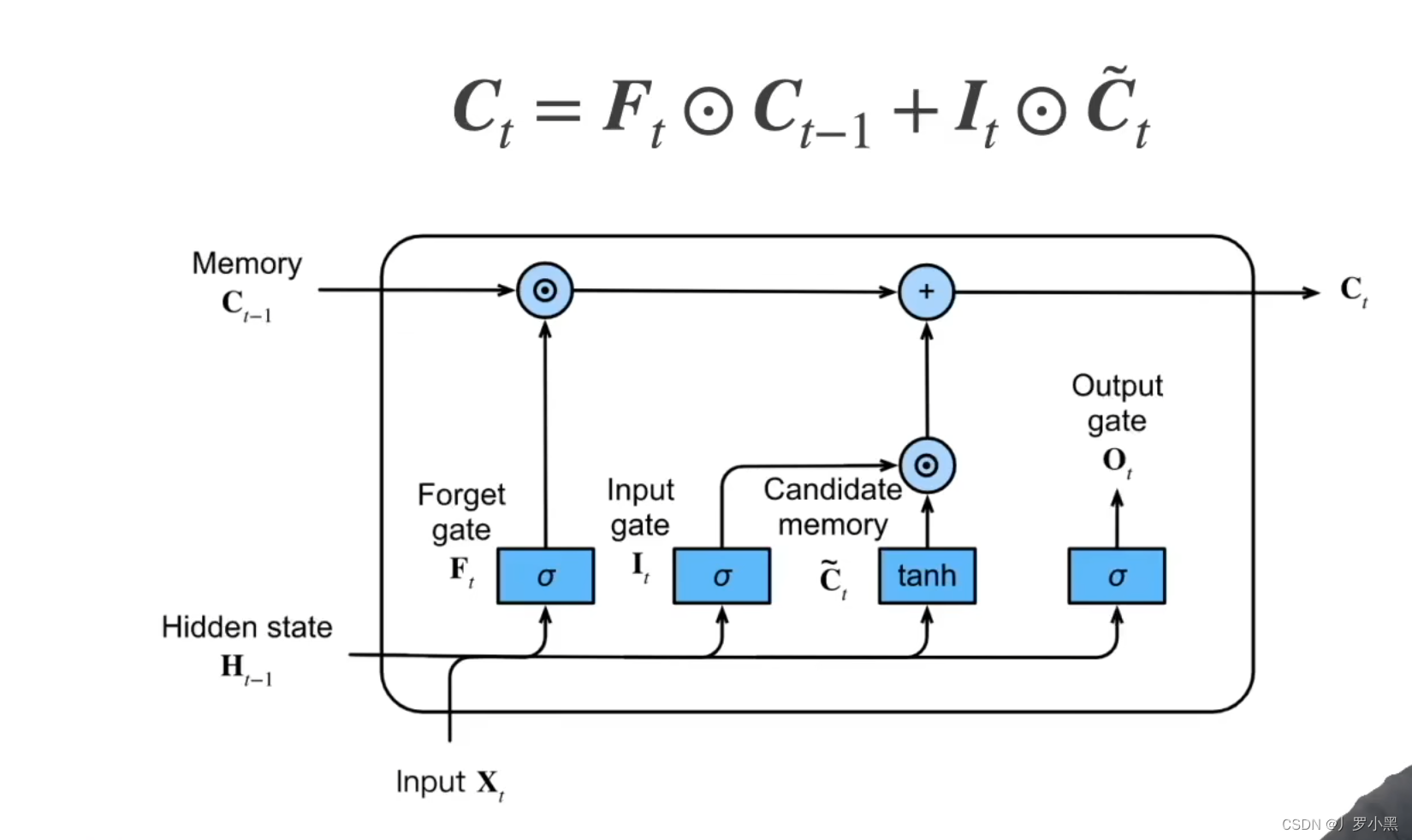
-
C
t
C_t
Ct记忆单元:LSTM中的记忆单元和GRU中的
H
t
H_t
Ht不一样,记忆单元可以既多看上一个的记忆单元,又多看当前的候选记忆单元(当前的输入信息
X
t
X_t
Xt)。记忆单元也可以即不要上一个的记忆单元,又不要当前的候选记忆单元。但是GRU中的
H
t
H_t
Ht为
Z
T
Z_T
ZT和
1
−
Z
t
1-Z_t
1−Zt,所以要么多看上一个的隐变量,要么多看当前的候选隐变量
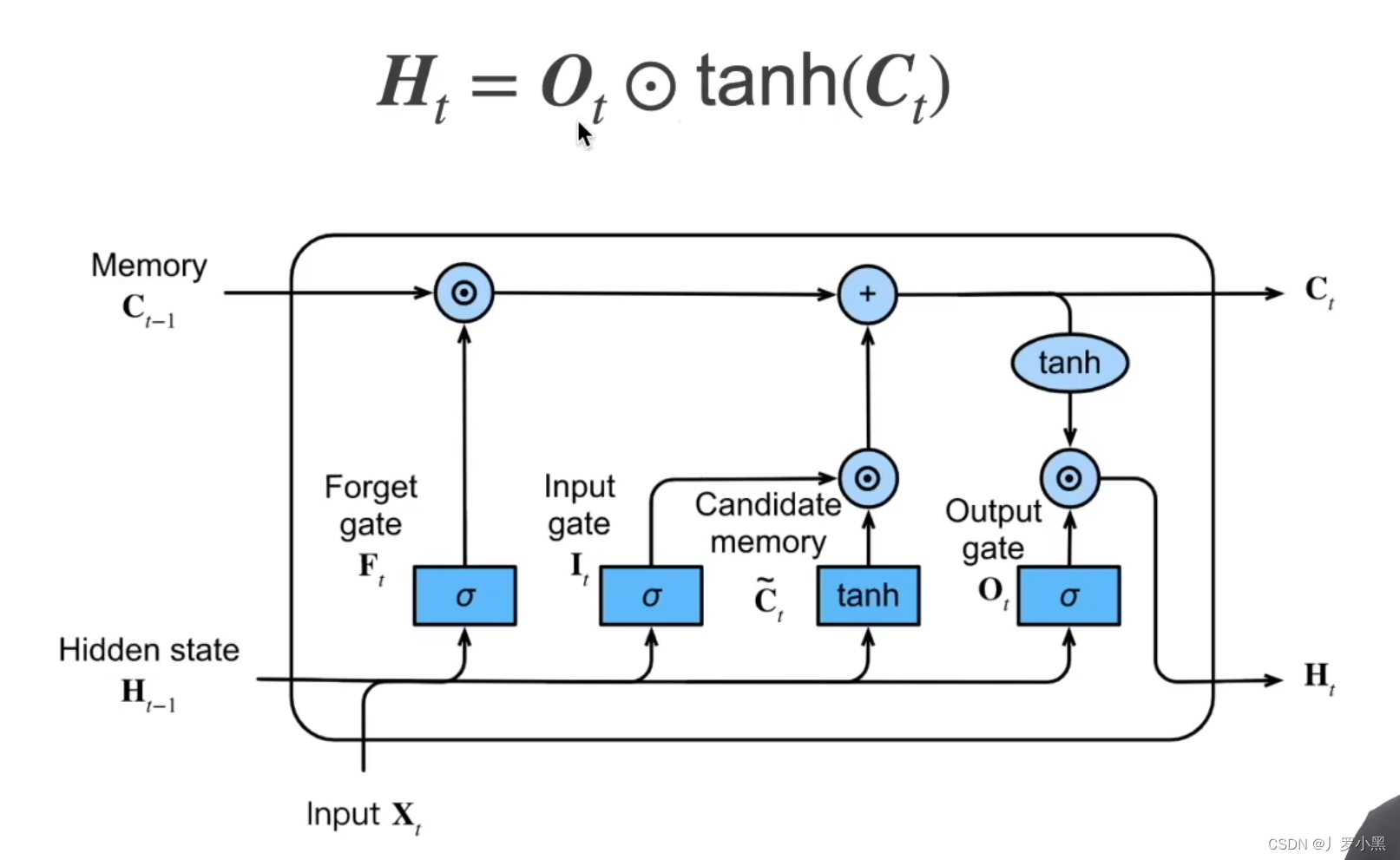
-
H
t
H_t
Ht隐变量:由于
F
t
F_t
Ft和
I
t
I_t
It都是(0,1),而
C
~
t
\widetilde{C}_t
C
t在(-1,1),但是
C
t
−
1
C_{t-1}
Ct−1可以特别大(跟
C
C
C的初始值有关),所以上一步的
C
t
C_t
Ct的范围无法保证,那么为了防止梯度爆炸,我们需要再做一次tanh()变换。
- 注意:此时的
O
t
O_t
Ot来控制要不要输出当前的输入信息和前一次的隐变量,当
O
t
O_t
Ot为0时,表示重置清零
- 注意:此时的
O
t
O_t
Ot来控制要不要输出当前的输入信息和前一次的隐变量,当
O
t
O_t
Ot为0时,表示重置清零
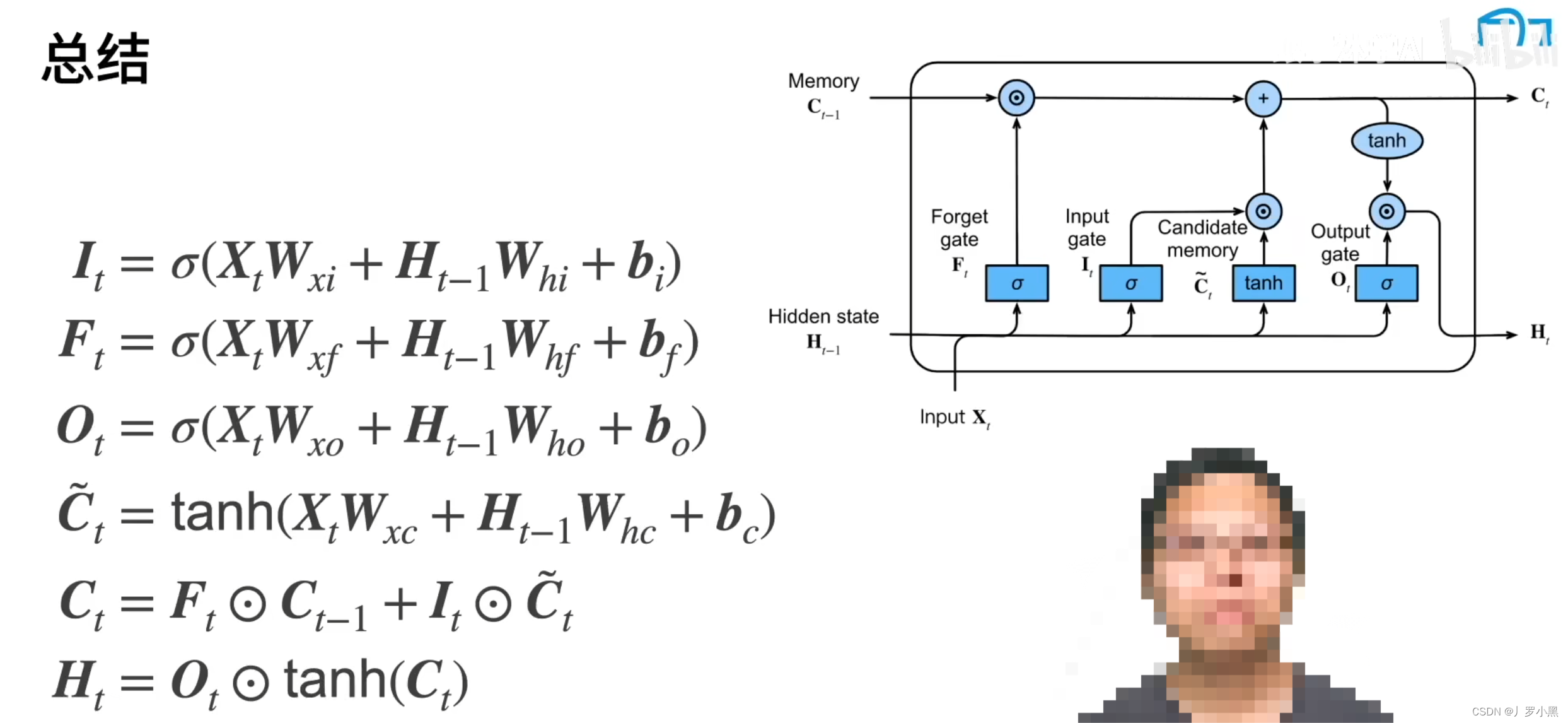
- 总结:通过引入记忆单元,LSTM比GRU更灵活,即可以既多看当前的候补记忆单元(当前的输入信息
X
t
X_t
Xt),又可以多看前一个的记忆单元,也可以两者都不看都忘掉。通过引入记忆单元还可以多存储信息。同时保留
H
t
H_t
Ht,防止梯度爆炸,还能重置清零隐变量
参考文献
- 11 Self-Attention相比较 RNN和LSTM的优缺点