TCP粘包、拆包、编解码问题
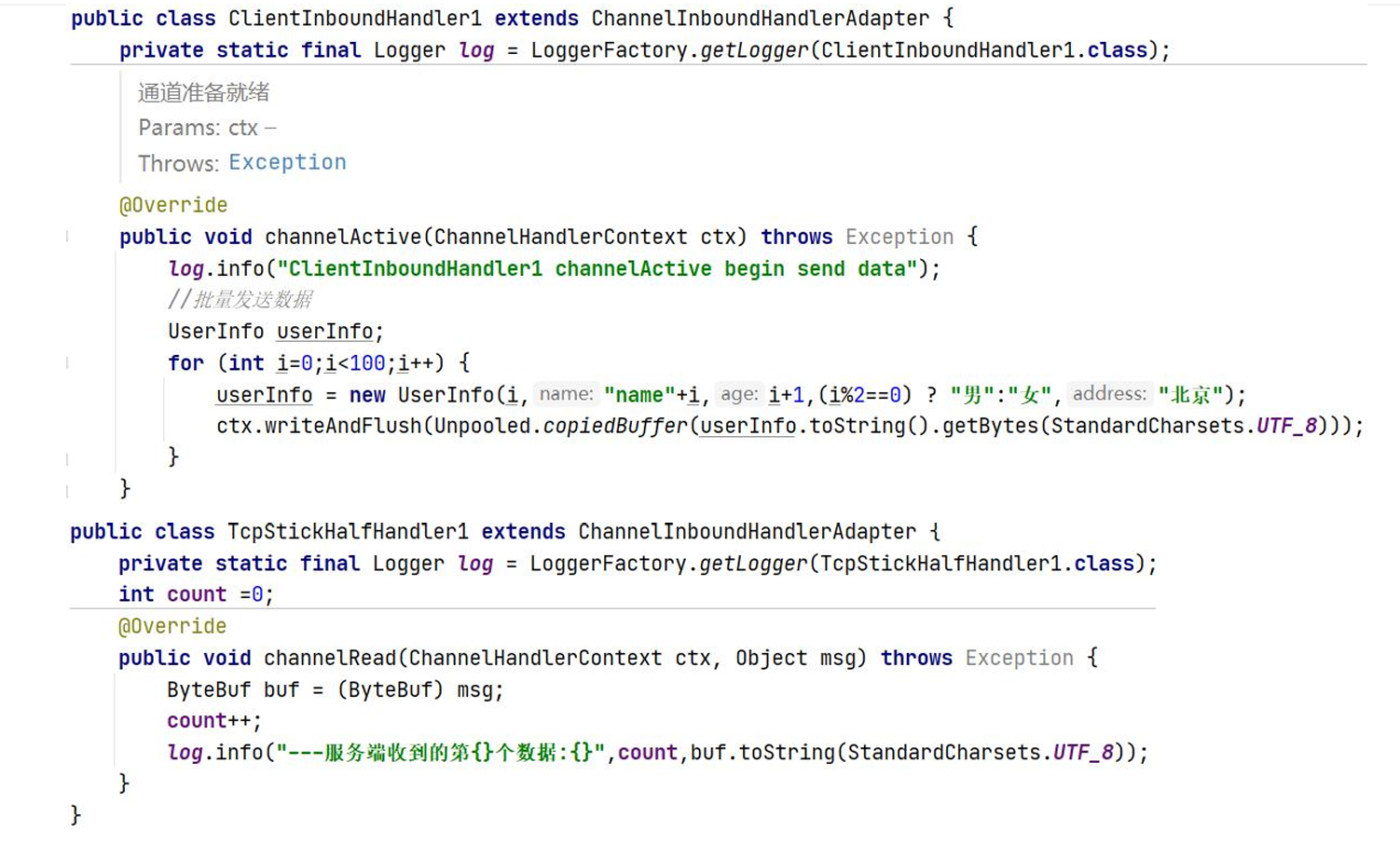
UserInfo userInfo1=new UserInfo();
ByteBuf buf = Unpooled.copiedBuffer(userInfo1.toString().getBytes(StandardCharsets.UTF_8));
UserInfo userInfo1=new UserInfo();这行代码创建了一个新的UserInfo对象,并将其引用存储在名为userInfo1的变量中。UserInfo可能是一个自定义类,用于存储用户信息。由于没有提供UserInfo类的细节,所以只能猜测它的用途和属性。Unpooled.copiedBuffer(userInfo1.toString().getBytes(StandardCharsets.UTF_8));这行代码执行了几个操作:
userInfo1.toString():调用userInfo1对象的toString()方法,这通常返回一个表示对象状态的字符串。如果没有重写UserInfo类的toString()方法,它会返回一个类名称和哈希码的组合字符串。getBytes(StandardCharsets.UTF_8):这会将toString()方法返回的字符串转换成字节序列,使用UTF-8编码。Unpooled.copiedBuffer(…):这个方法来自Netty框架,它创建一个新的缓冲区并将提供的数据复制到其中。Netty是一个流行的Java网络编程框架,通常用于高性能网络应用。Unpooled.copiedBuffer()方法创建的缓冲区是不池化的,意味着它并不是从Netty的字节缓冲池中获取的。
粘包拆包分析

从两个角度看粘包和拆包:
1、收发角度:一个发送可能被多次接收(半包),多个发送可能被一次接收(粘包)
2、传输角度:一个发送可能占用多个传输包(半包),多个发送可能公用一个传输包(粘包)
根本原因: TCP 协议是面向连接的、可靠的、基于字节流的传输层 通信协议,是一种流式协议,消息无边界。
对TCP而言,所有的数据都是一串串二进制,它不知道哪一段是完整的包。
解决方案
既然TCP不知道哪里是一段完整的包,那么我们该如何让它知道呢?
解决TCP粘包,半包问题的根本:找出消息的边界
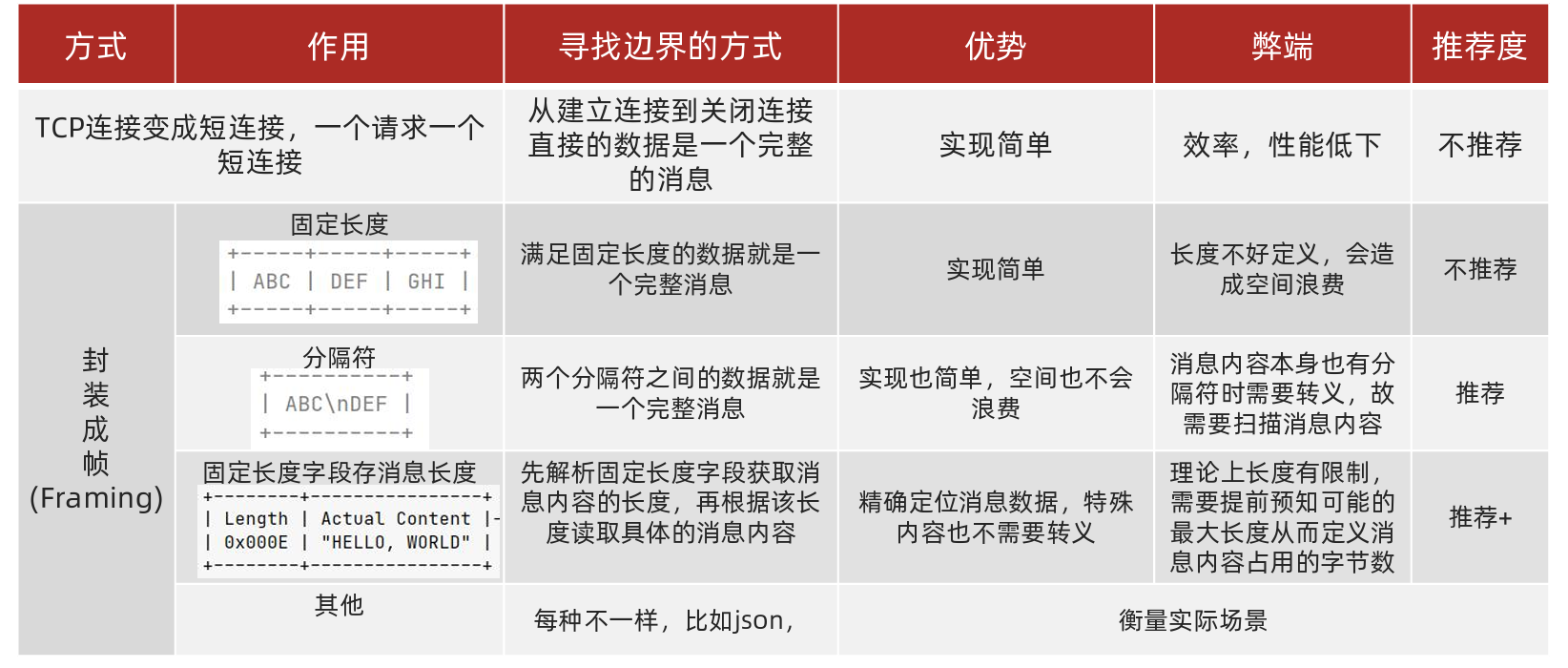
封装成帧
Netty提供了针对封装成帧这种形式下不同方式的拆包器,所谓的拆包其实就是数据的解码,所谓解码就是将网络中的一 些原始数据解码成上层应用的数据,那对应在发送数据的时候要按照同样的方式进行数据的编码操作然后发送到网络中。

主要探讨固定长度字段存消息长度
分隔符解码器-LineBasedFrameDecoder

功能和特性
- 行分割:
LineBasedFrameDecoder根据换行符(\n)或回车换行符(\r\n)分割接收到的数据。每当它遇到这些字符时,就认为一行数据结束。 - 处理粘包/半包问题:在 TCP 传输中,发送的数据可能会在接收端合并(粘包)或分裂(半包)。这个解码器能够正确处理这种情况,确保每次只输出完整的行。
- 简化文本协议的处理:由于很多基于文本的协议使用行作为消息的基本单位,因此这个解码器在处理这类协议时非常有效。
构造函数参数
- maxFrameLength:这个参数定义了单行的最大长度。如果读取的行超过这个长度,
LineBasedFrameDecoder会抛出TooLongFrameException异常。这是一个重要的安全特性,防止因极端长的行导致的内存问题。 - stripDelimiter:这是一个布尔值参数,用于决定解码后的数据是否包含行结束符。通常设置为
true,以便在解码后的数据中移除换行符或回车换行符。 - failFast:这也是一个布尔值参数,用于决定在超过最大长度时解码器是立即抛出异常(
true),还是等到下一个换行符出现时才抛出异常(false)。
使用示例
ChannelPipeline pipeline = socketChannel.pipeline();
pipeline.addLast(new LineBasedFrameDecoder(8192, true, false));
在这个例子中,LineBasedFrameDecoder 设置了最大行长度为 8192 字节,会剔除换行符,并且在检测到超长行时立即抛出异常。
分隔符解码器-DelimiterBasedFrameDecode
功能
- 基于分隔符的解码:它检测指定的分隔符来确定消息的边界。这种方式常见于文本协议,如基于换行符或特定字符(如
|、,等)的分隔。 - 处理粘包/半包问题:在TCP传输中,由于TCP是一个基于流的协议,消息的边界可能会丢失(即所谓的“粘包”问题)。
DelimiterBasedFrameDecoder通过识别分隔符来重新构建这些边界。
构造函数参数
- maxFrameLength:最大帧长度,即单个解码后的消息的最大长度。如果读取的消息超过此长度,则会抛出
TooLongFrameException。 - stripDelimiter:布尔值,指示解码后的帧是否包含分隔符本身。通常设为
true以从解码的帧中剔除分隔符。 - delimiter:分隔符。可以是一个或多个,使用Netty的
ByteBuf对象表示。
使用示例
假设有一个基于文本的协议,消息以\n(换行符)结束。
ChannelPipeline pipeline = socketChannel.pipeline();
ByteBuf delimiter = Unpooled.wrappedBuffer(new byte[] { '\n' });
pipeline.addLast(new DelimiterBasedFrameDecoder(8192, true, delimiter));
在这个例子中,DelimiterBasedFrameDecoder会查找换行符,将接收的数据分割成单独的行,并将每行作为一个单独的帧传递到管道中的下一个处理器。
注意事项
- 资源管理:由于使用了
ByteBuf作为分隔符,需要注意内存管理和引用计数,尤其是在自定义分隔符的情况下。 - 性能考虑:如果消息非常大或分隔符非常频繁,
DelimiterBasedFrameDecoder可能会影响性能。选择合适的maxFrameLength和合理的分隔符是关键。 - 安全性:设置合理的
maxFrameLength可以防止由于异常大的帧而导致的内存溢出攻击。
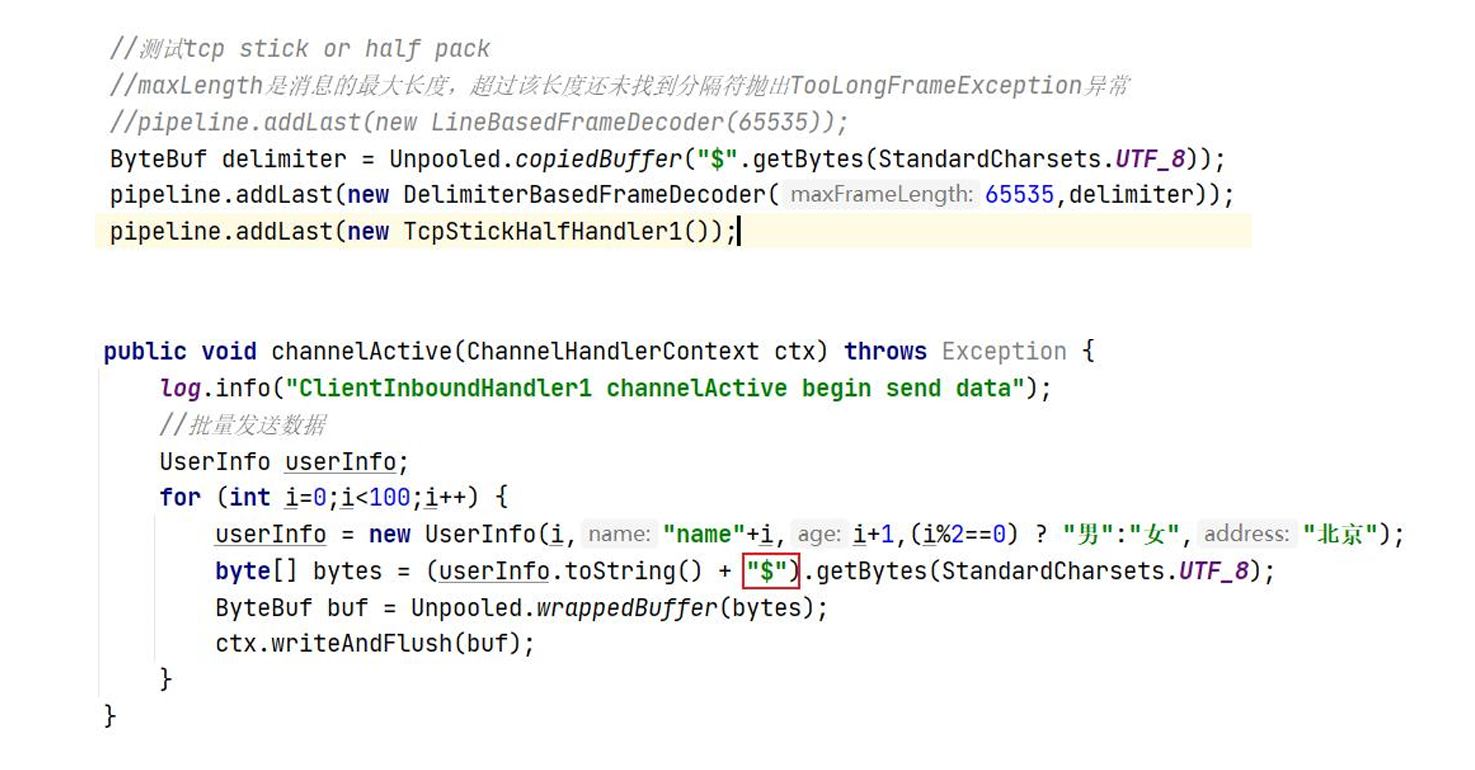
基于长度的域解码器-LengthFieldBasedFrameDecode
- lengthFieldOffset:length域的偏移,正常情况下读 取数据从偏移为0处开始读取,如果有需要可以从其 他偏移量处开始读取
- lengthFieldLength:length域占用的字节数
- lengthAdjustment:在length域和content域中间是 否需要填充其他字节数
- initialBytesToStrip:解码后跳过的字节

pipeline.addLast(new ProtobufEncoder());
pipeline.addLast(new LengthFieldBasedFrameDecoder(65536,0,4,0,4));
LengthFieldPrepender
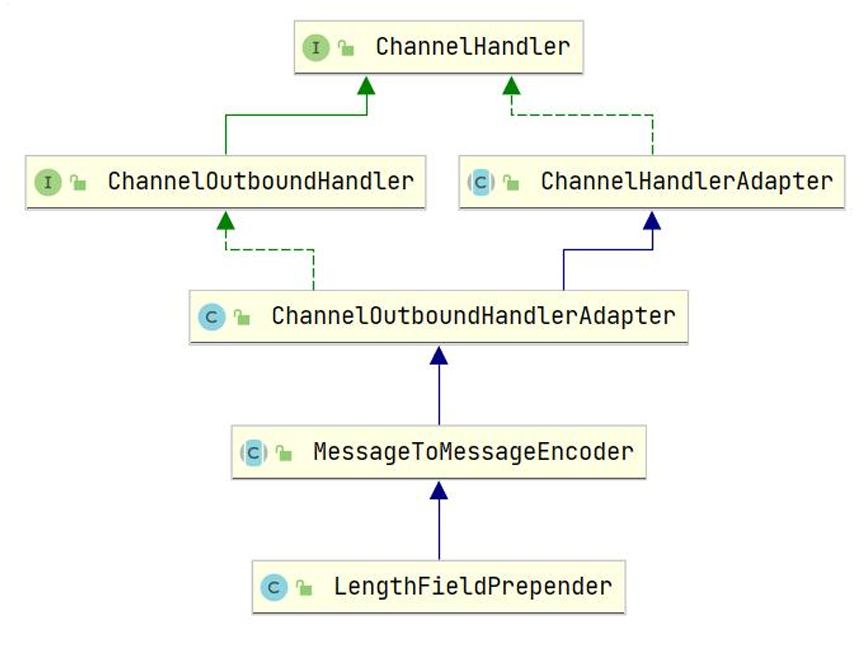
从继承关系可以看出来,这是一个可以处理收、发的处理器
int lengthFieldLength: 这个参数定义了长度字段占用的字节数。例如,如果你设置了3,那么长度字段将会使用3个字节来表示后续消息体的长度。boolean lengthIncludesLengthFieldLength: 如果设置为true,表示长度字段的值包括自身长度在内。也就是说,传给writeXXX方法的数据长度,除了实际的消息体长度外,还包括了长度字段本身的长度。如果设置为false,则长度字段仅表示消息体的长度。int lengthAdjustment: 这个参数用于调整长度字段的值。它可以是正数或负数,用于添加或减去从消息体真实长度中得到的长度值。例如,如果消息体后面还有额外的固定头部数据,而长度字段需要包含这部分数据,你可以设置一个正的lengthAdjustment。ByteOrder byteOrder: 定义长度字段中数值的字节序。例如,如果是ByteOrder.BIG_ENDIAN(大端字节序),高位字节存储在低地址;如果是ByteOrder.LITTLE_ENDIAN(小端字节序),低位字节存储在低地址。

pipeline.addLast(new LengthFieldPrepender(4));
pipeline.addLast(new ProtobufEncoder());
其他编解码器
Netty中提供了ByteToMessageDecoder的抽象实现,自定义解码器只需要继承该类,实现decode()即可。Netty也提供 了一些常用的解码器实现,用于数据入站的解码操作,基本都是开箱即用的;当然数据出站也需要采用对应的编码器。
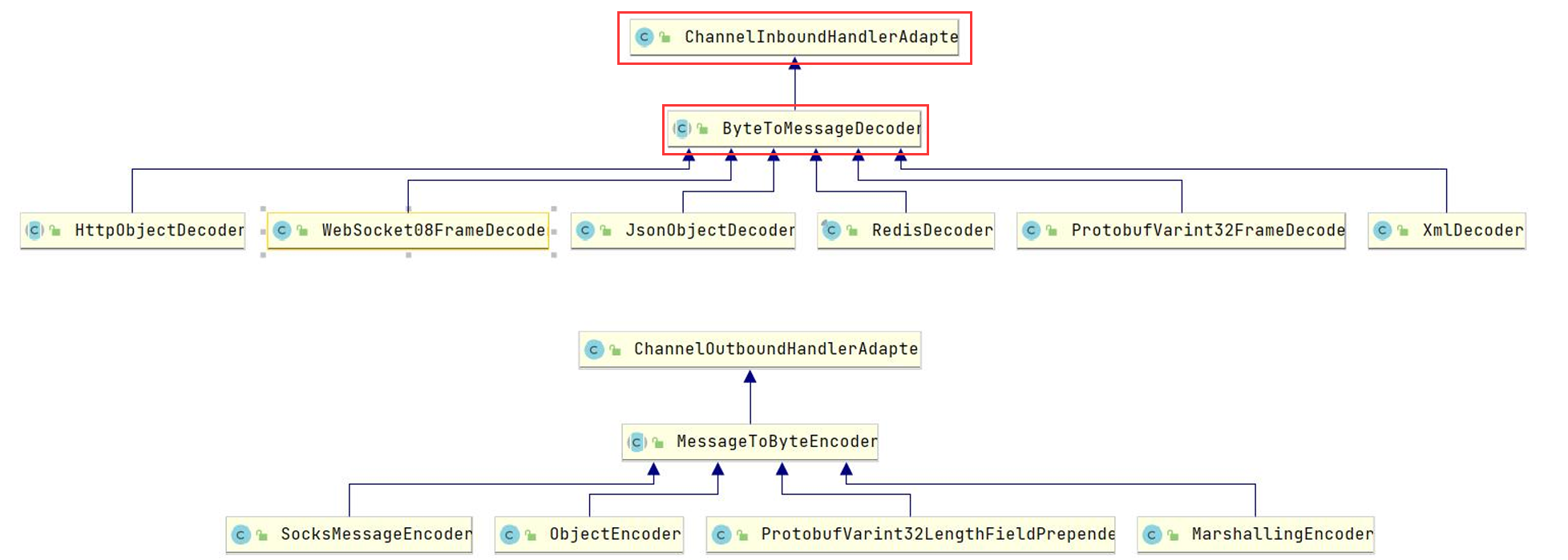
二次编解码
- 我们把解决半包粘包问题的常用三种解码器叫一次解码器,其作用是将原始数据流(可能会出现粘包和半包的数据流) 转换为用户数据(ByteBuf中存储),但仍然是字节数据,所以我们需要二次解码器将字节数组转换为java对象,或者 将将一种格式转化为另一种格式,方便上层应用程序使用。
- 一次解码器继承自:ByteToMessageDecoder
- 二次解码器继承自:MessageToMessageDecoder
- 但他们的本质 都是继承ChannelInboundHandlerAdapter
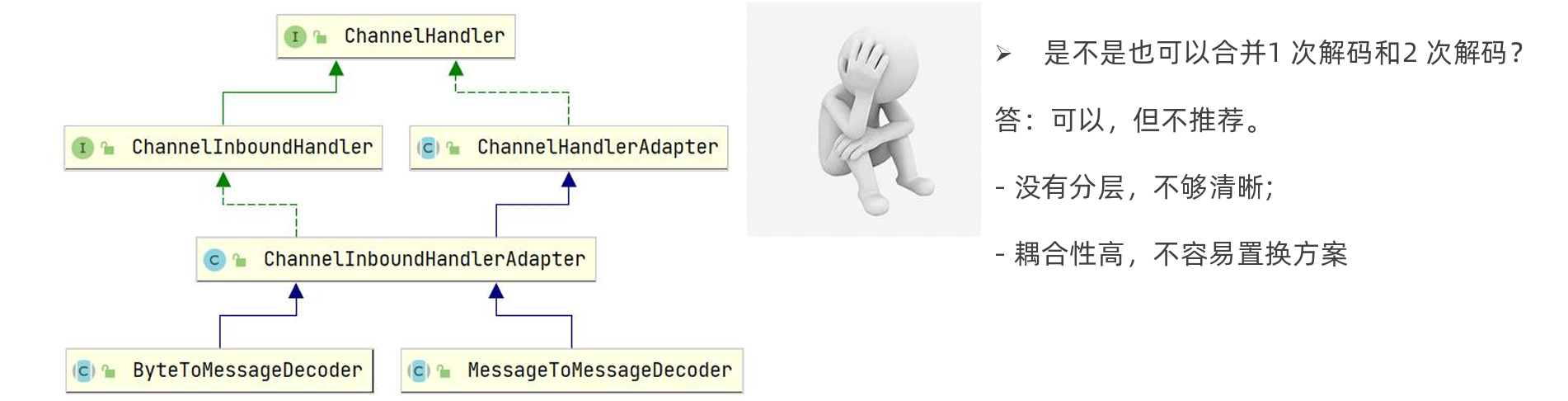
- 用户数据(ByteBuf )和 Java Object之间的转换,或者将将一种格式转化为另一种格式(譬如将应用数据转化成某种 协议数据)
- Java 序列化:不推荐使用,占用空间大,也只有java语言能用
- Marshaling:比java序列化稍好
- XML:可读性好,但是占用空间大
- JSON:可读性也好,空间较小
- MessagePack:占用空间比JSON小,可读性不如JSON,但也还行
- Protobuf:性能高,体积小,但是可读性差
- hessian:跨语言、高效的二进制序列化协议,整体性能和protobuf差不多。
常用的二次解码器
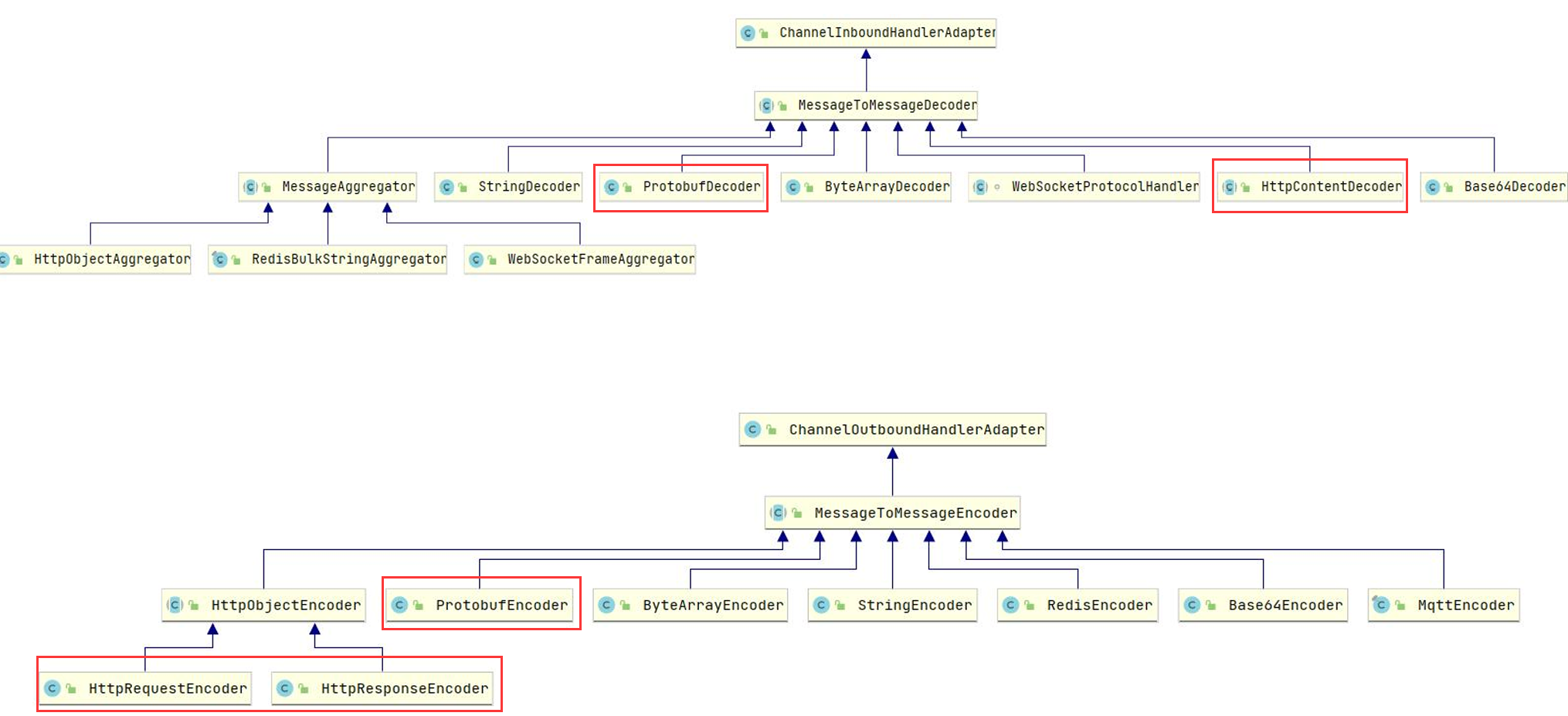
常用二次编码器使用实例

StringDecoder、StringEncoder
pipeline.addLast(new StringDecoder());
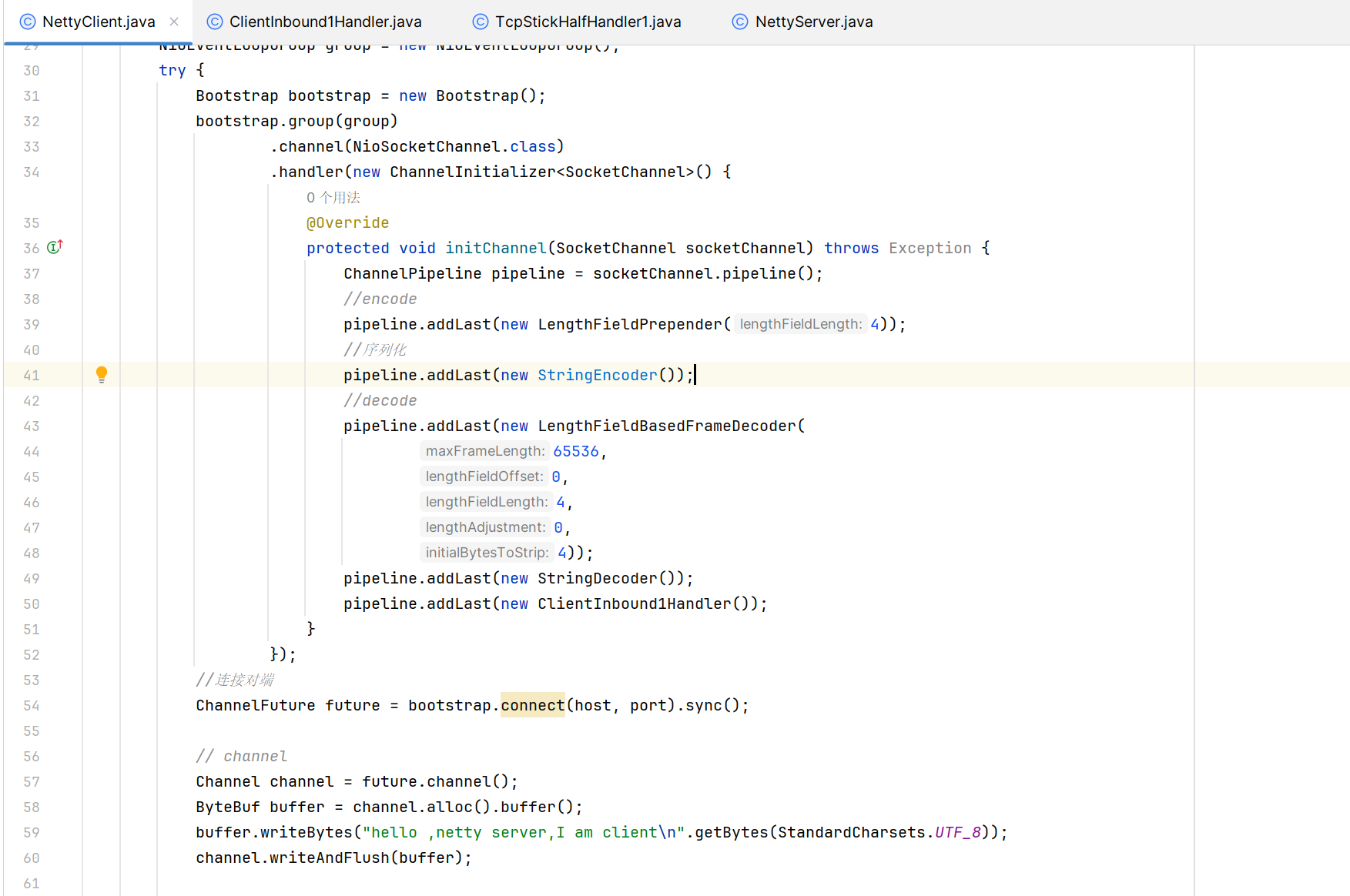
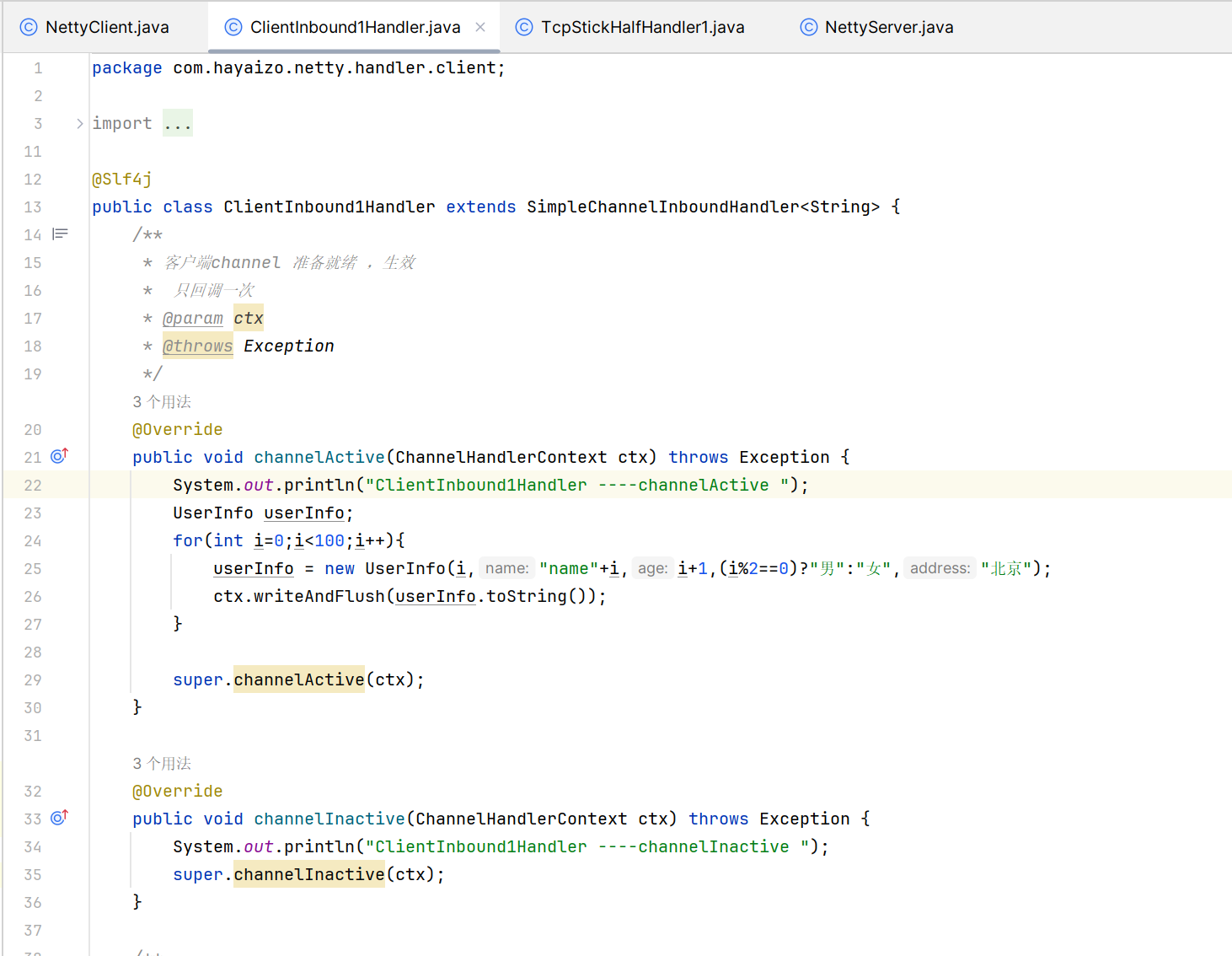
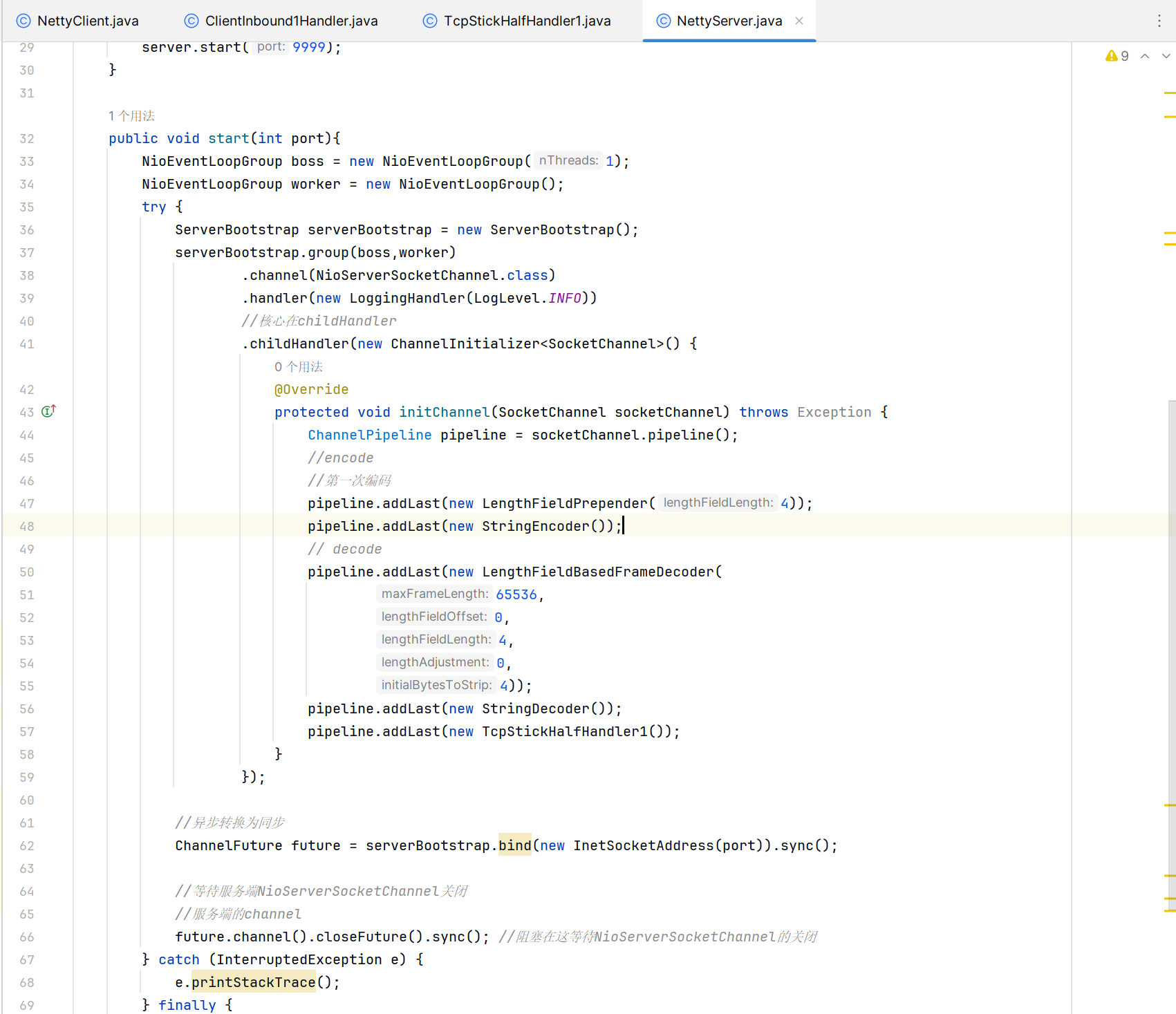


ProtobufDecoder、ProtobufEncoder
maven依赖:
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.22.2</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java-util</artifactId>
<version>3.22.2</version>
</dependency>
插件依赖:
<build>
<extensions>
<extension>
<groupId>kr.motd.maven</groupId>
<artifactId>os-maven-plugin</artifactId>
<version>1.6.2</version>
</extension>
</extensions>
<plugins>
<plugin>
<groupId>org.xolstice.maven.plugins</groupId>
<artifactId>protobuf-maven-plugin</artifactId>
<version>0.6.1</version>
<configuration>
<!-- 工具版本 -->
<protocArtifact>com.google.protobuf:protoc:3.22.2:exe:${os.detected.classifier}</protocArtifact>
<pluginId>protobuf-java</pluginId>
<!--默认值,proto源文件路径-->
<protoSourceRoot>${project.basedir}/src/main/proto</protoSourceRoot>
<pluginArtifact>io.grpc:protoc-gen-grpc-java:1.54.0:exe:${os.detected.classifier}</pluginArtifact>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
<!-- <goal>compile-custom</goal>-->
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
proto文件
syntax = "proto3";
option java_package = "com.hayaizo.netty.pojo";
option java_outer_classname = "MessageProto";
option java_multiple_files = false;
message Message {
string id = 1;
string content = 2;
}
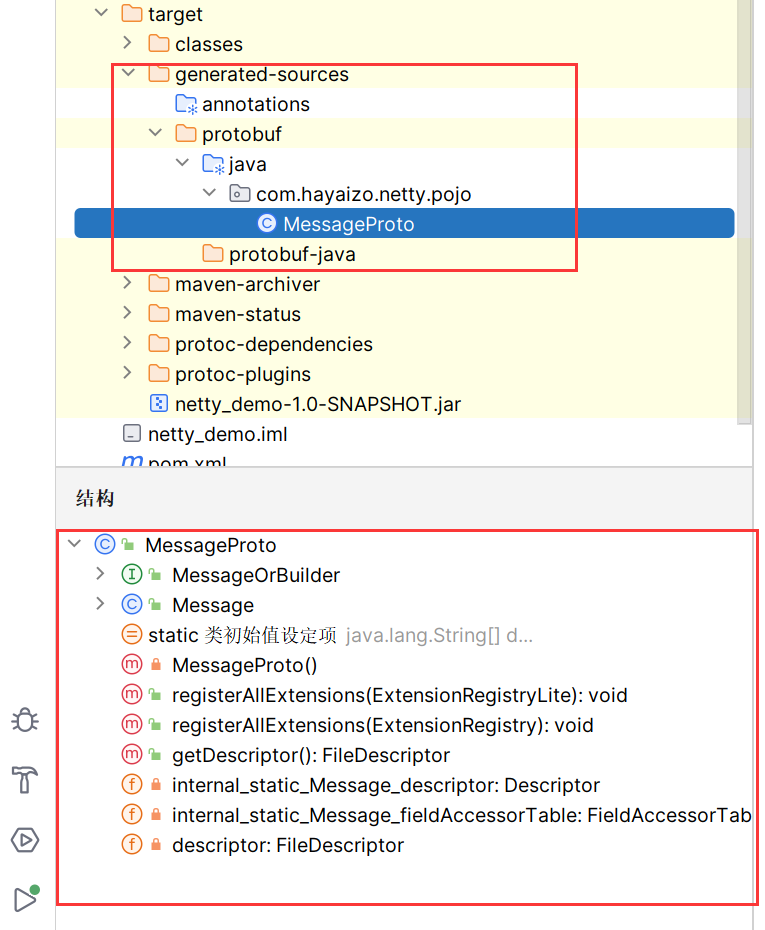
pipeline.addLast(new ProtobufEncoder());//编码
pipeline.addLast(new ProtobufDecoder(MessageProto.Message.getDefaultInstance()));//解码
MessageProto.Message.getDefaultInstance())是指定编、接码对象的
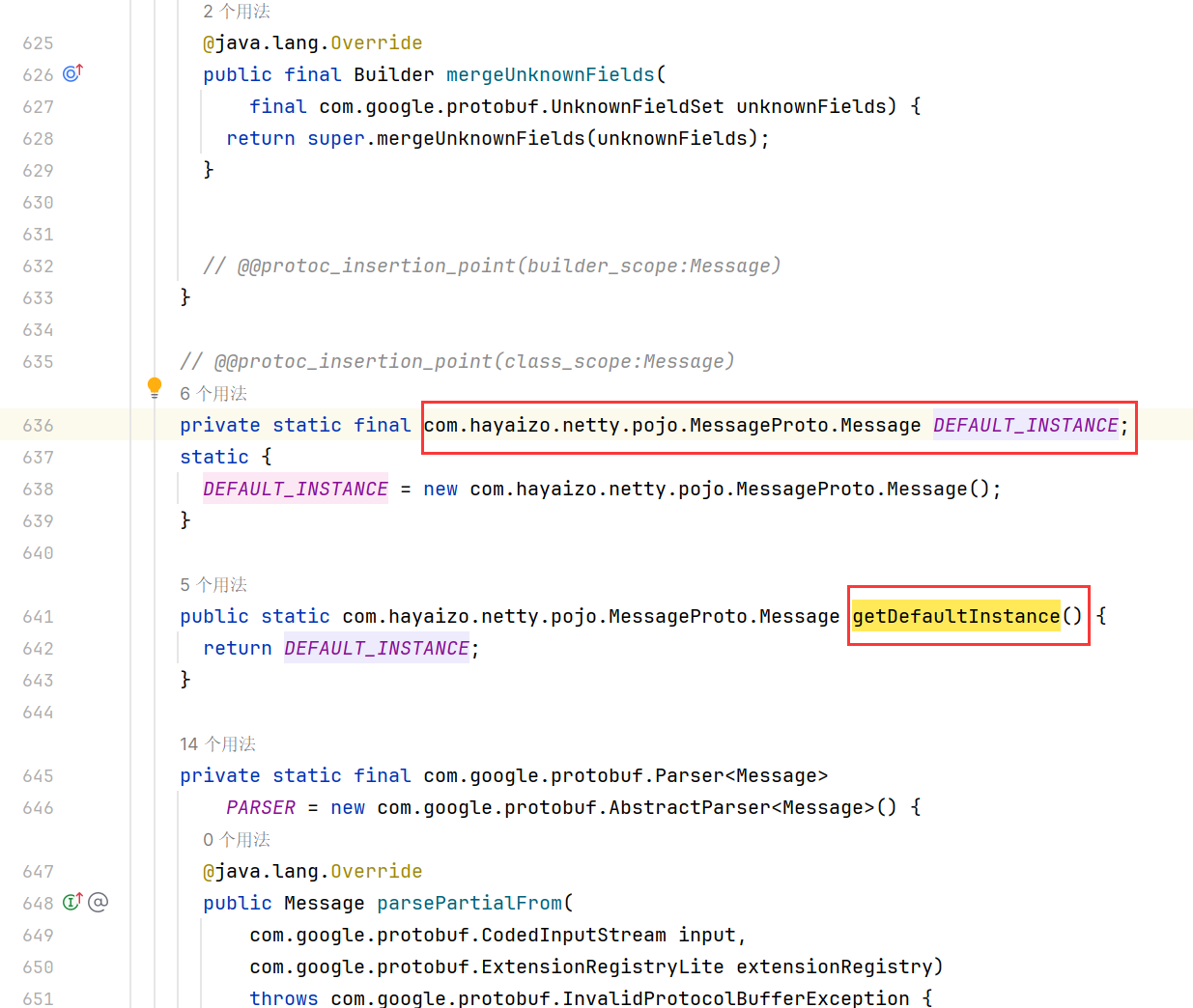
可以看到,返回的就是我们在proto文件中定义的类,如果要实现多个类都能被编、接码,可以对其进行封装一下。
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//ByteBuf buf = (ByteBuf) msg;
String buf = (String) msg;
//UserInfo buf = (UserInfo) msg;
MessageProto.Message m = (MessageProto.Message) msg;
//UserInfo userInfo = (UserInfo)msg;
count++;
//log.info("---服务端收到的第{}个数据:{}",count,buf.toString());
//log.info("---服务端收到的第{}个数据:{}",count,buf.toString(StandardCharsets.UTF_8));
log.info("---服务端收到的第{}个数据:{}",count,m.getContent() + "---" + m.getId());
log.info("服务器收到的第{}个数据{}",count,buf.toString());
super.channelRead(ctx, msg);
}
在服务端的channelRead中,数据进来经过了两次解码,现在的msg拿到的就是MessageProto.Message类型的对象,可以直接使用。
Protostuff编解码
protostuff是一个基于protobuf实现的序列化方法,它较于protobuf最明显的好处是,在几乎不损耗性能的情况下做到了不用我们 写.proto文件来实现序列化
导入maven依赖
<!--基于google protobuf的工具类 protostuff-->
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>io.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.6.0</version>
</dependency>
创建UserInfo类
package com.hayaizo.netty.pojo;
import java.io.Serializable;
public class UserInfo implements Serializable {
private Integer id;
private String name;
private Integer age;
private String gender;
private String address;
public UserInfo() {
}
public UserInfo(Integer id, String name, Integer age, String gender, String address) {
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.address = address;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public String toString() {
return "UserInfo{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
", gender='" + gender + '\'' +
", address='" + address + '\'' +
'}';
}
}
说一下ProtoStuffEncoder
package com.hayaizo.netty.codec;
import com.hayaizo.netty.pojo.UserInfo;
import com.hayaizo.netty.util.ProtostuffUtil;
import io.netty.buffer.ByteBuf;
import io.netty.channel.ChannelHandlerContext;
import io.netty.handler.codec.MessageToMessageEncoder;
import java.util.List;
public class ProtoStuffEncoder extends MessageToMessageEncoder<UserInfo> {
@Override
protected void encode(ChannelHandlerContext ctx, UserInfo msg, List<Object> out) throws Exception {
try {
byte[] bytes = ProtostuffUtil.serialize(msg);
ByteBuf buf = ctx.alloc().buffer(bytes.length);
buf.writeBytes(bytes);
out.add(buf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
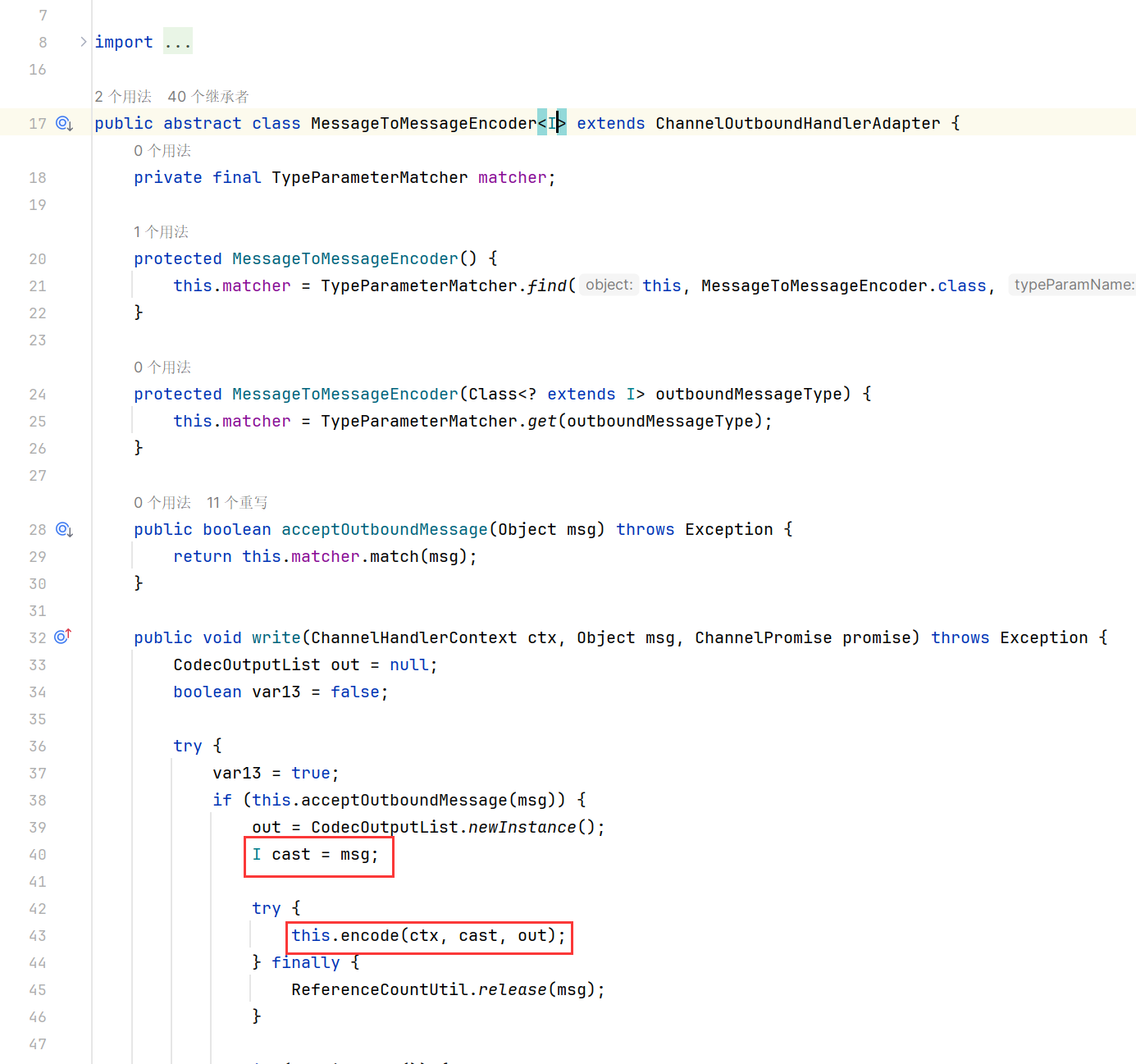
这里的I表示要编、解码的类型,将Object类型的msg转换为I类型。

这个encode也是我们要自己实现的类
往后写消息也是传递的out,所以只要把数据存入out中就会自动向后传递了。
pipeline.addLast(new ProtoStuffDecoder());
pipeline.addLast(new ProtoStuffEncoder());