def forward(self,
features, # type: Dict[str, Tensor]
proposals, # type: List[Tensor]
image_shapes, # type: List[Tuple[int, int]]
targets=None # type: Optional[List[Dict[str, Tensor]]]
):
# type: (...) -> Tuple[List[Dict[str, Tensor]], Dict[str, Tensor]]
"""
Arguments:
features (List[Tensor])
proposals (List[Tensor[N, 4]])
image_shapes (List[Tuple[H, W]])
targets (List[Dict])
"""
# 检查targets的数据类型是否正确
if targets is not None:
for t in targets:
floating_point_types = (torch.float, torch.double, torch.half)
assert t["boxes"].dtype in floating_point_types, "target boxes must of float type"
assert t["labels"].dtype == torch.int64, "target labels must of int64 type"
if self.training:
# 划分正负样本,统计对应gt的标签以及边界框回归信息
proposals, matched_idxs, labels, regression_targets = self.select_training_samples(proposals, targets)
else:
labels = None
regression_targets = None
matched_idxs = None
# 将采集样本通过Multi-scale RoIAlign pooling层
# box_features_shape: [num_proposals, channel, height, width]
box_features = self.box_roi_pool(features, proposals, image_shapes)
# 通过roi_pooling后的两层全连接层
# box_features_shape: [num_proposals, representation_size]
box_features = self.box_head(box_features)
# 接着分别预测目标类别和边界框回归参数
class_logits, box_regression = self.box_predictor(box_features)
result: List[Dict[str, torch.Tensor]] = []
losses = {}
if self.training:
assert labels is not None and regression_targets is not None
loss_classifier, loss_box_reg = fastrcnn_loss(
class_logits, box_regression, labels, regression_targets)
losses = {
"loss_classifier": loss_classifier,
"loss_box_reg": loss_box_reg
}
else:
boxes, scores, labels = self.postprocess_detections(class_logits, box_regression, proposals, image_shapes)
num_images = len(boxes)
for i in range(num_images):
result.append(
{
"boxes": boxes[i],
"labels": labels[i],
"scores": scores[i],
}
)
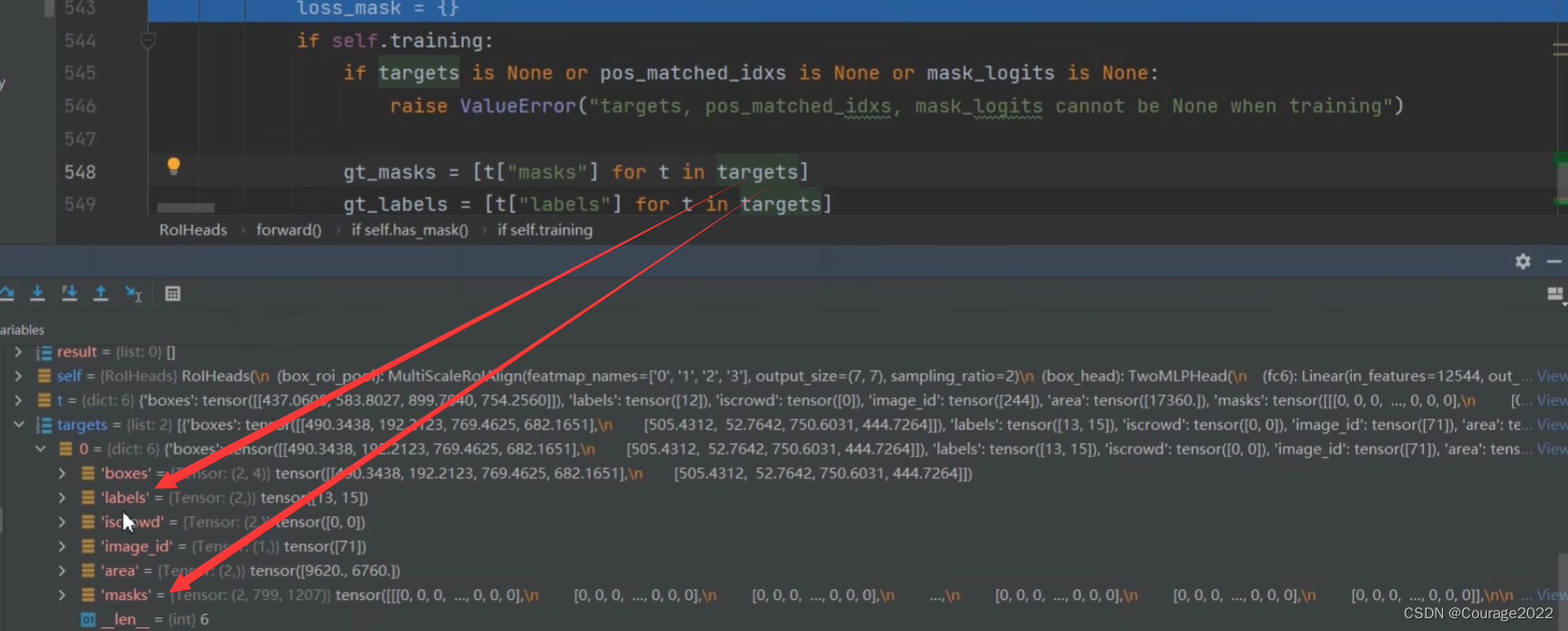
if self.has_mask():
mask_proposals = [p["boxes"] for p in result] # 将最终预测的Boxes信息取出
if self.training:
# matched_idxs为每个proposal在正负样本匹配过程中得到的gt索引(背景的gt索引也默认设置成了0)
if matched_idxs is None:
raise ValueError("if in training, matched_idxs should not be None")
# during training, only focus on positive boxes
num_images = len(proposals)
mask_proposals = []
pos_matched_idxs = []
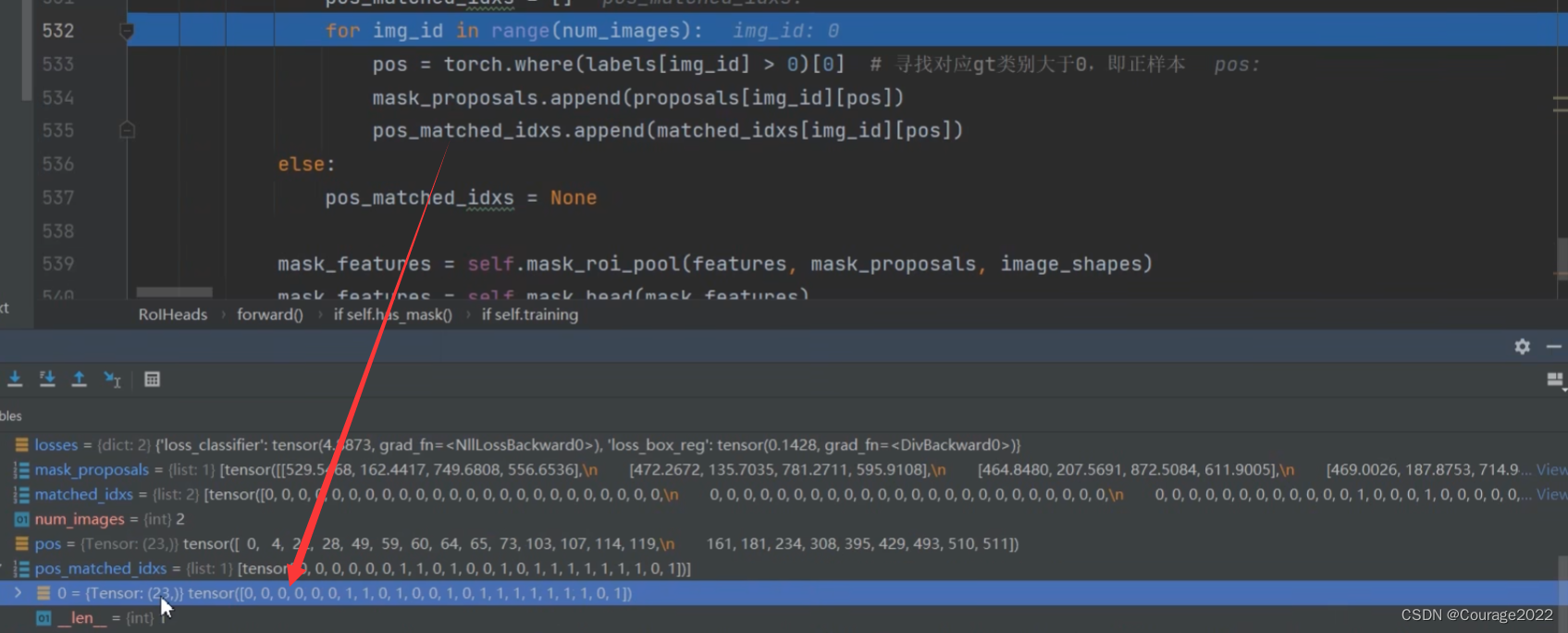
for img_id in range(num_images):
pos = torch.where(labels[img_id] > 0)[0] # 寻找对应gt类别大于0,即正样本
mask_proposals.append(proposals[img_id][pos])
pos_matched_idxs.append(matched_idxs[img_id][pos])
else:
pos_matched_idxs = None
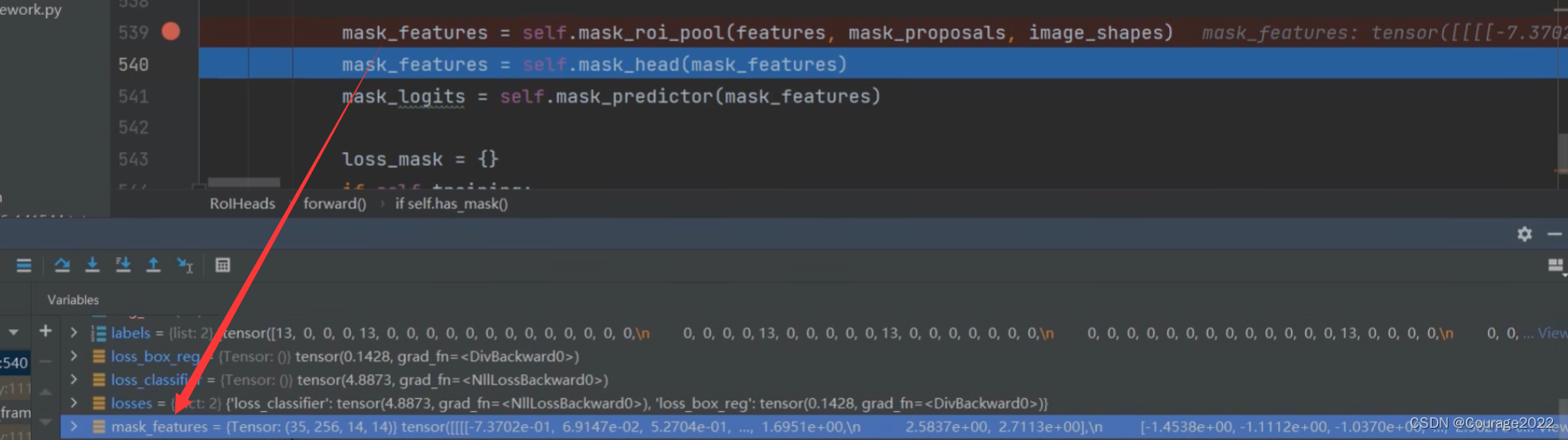
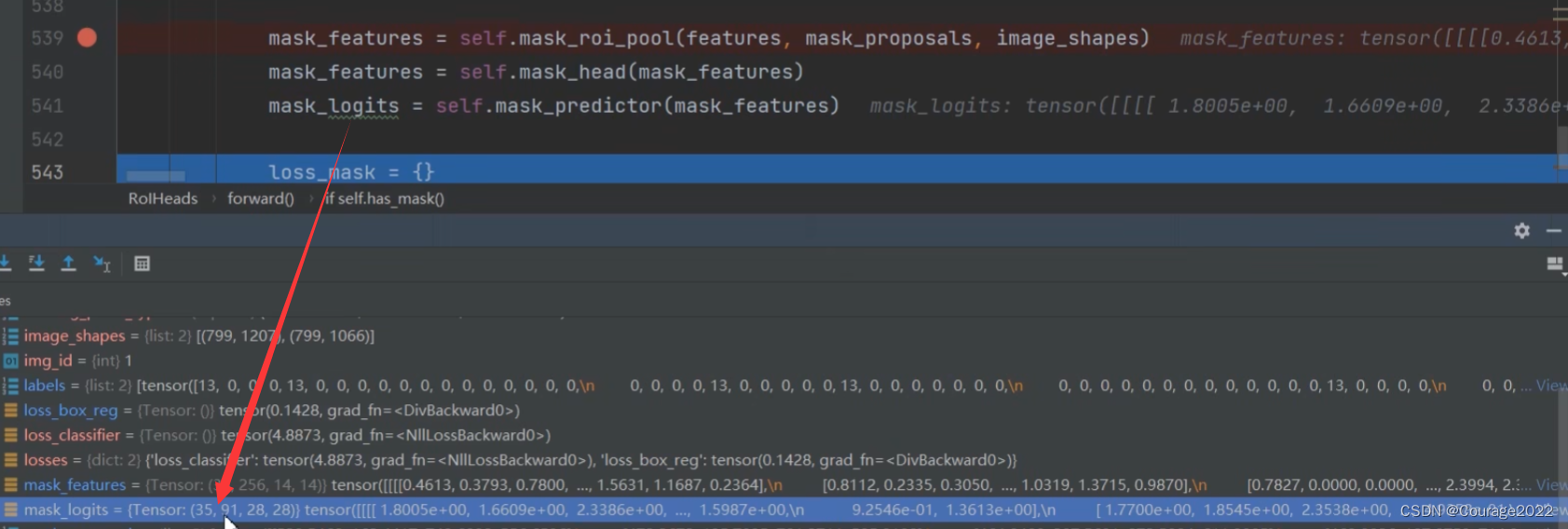
mask_features = self.mask_roi_pool(features, mask_proposals, image_shapes)
mask_features = self.mask_head(mask_features)
mask_logits = self.mask_predictor(mask_features)
loss_mask = {}
if self.training:
if targets is None or pos_matched_idxs is None or mask_logits is None:
raise ValueError("targets, pos_matched_idxs, mask_logits cannot be None when training")
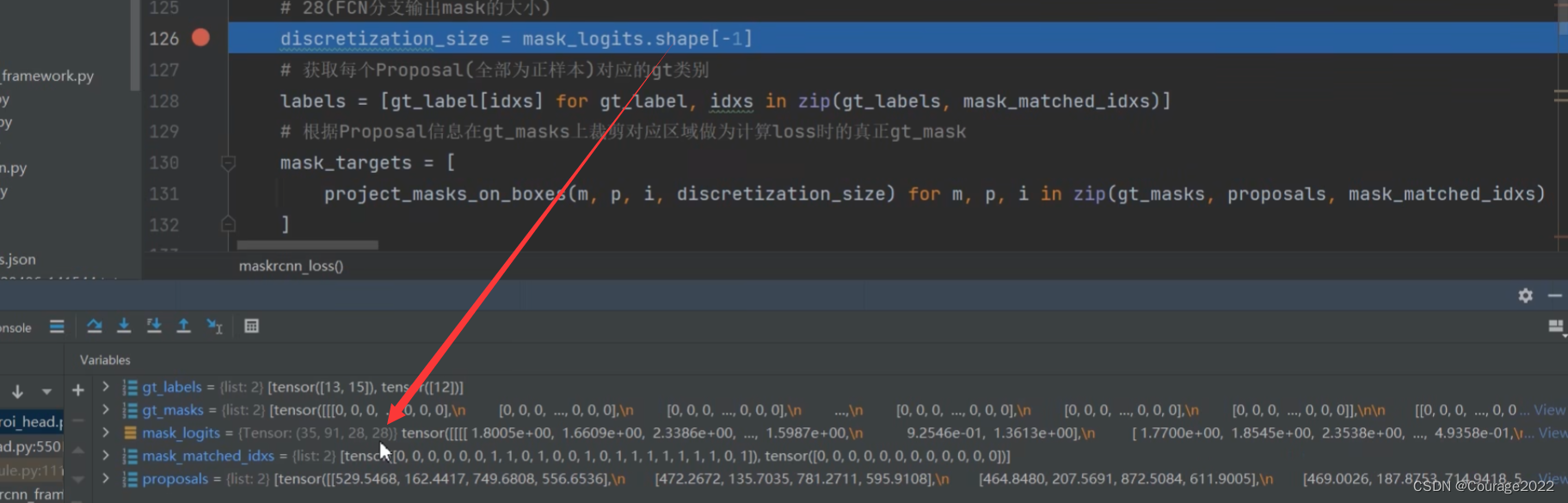
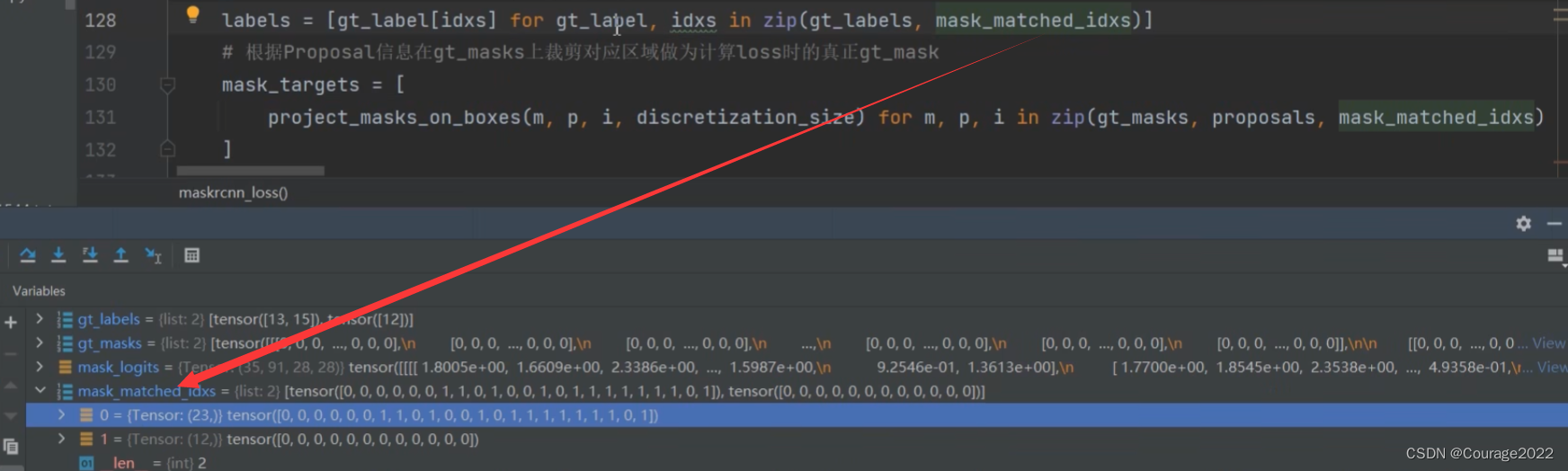
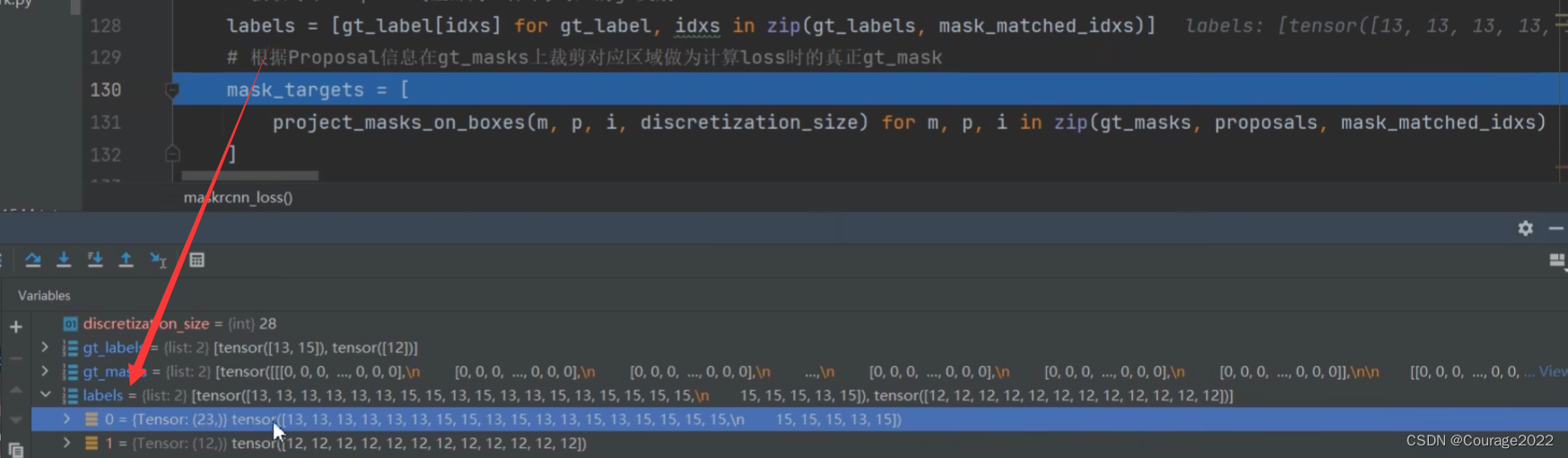
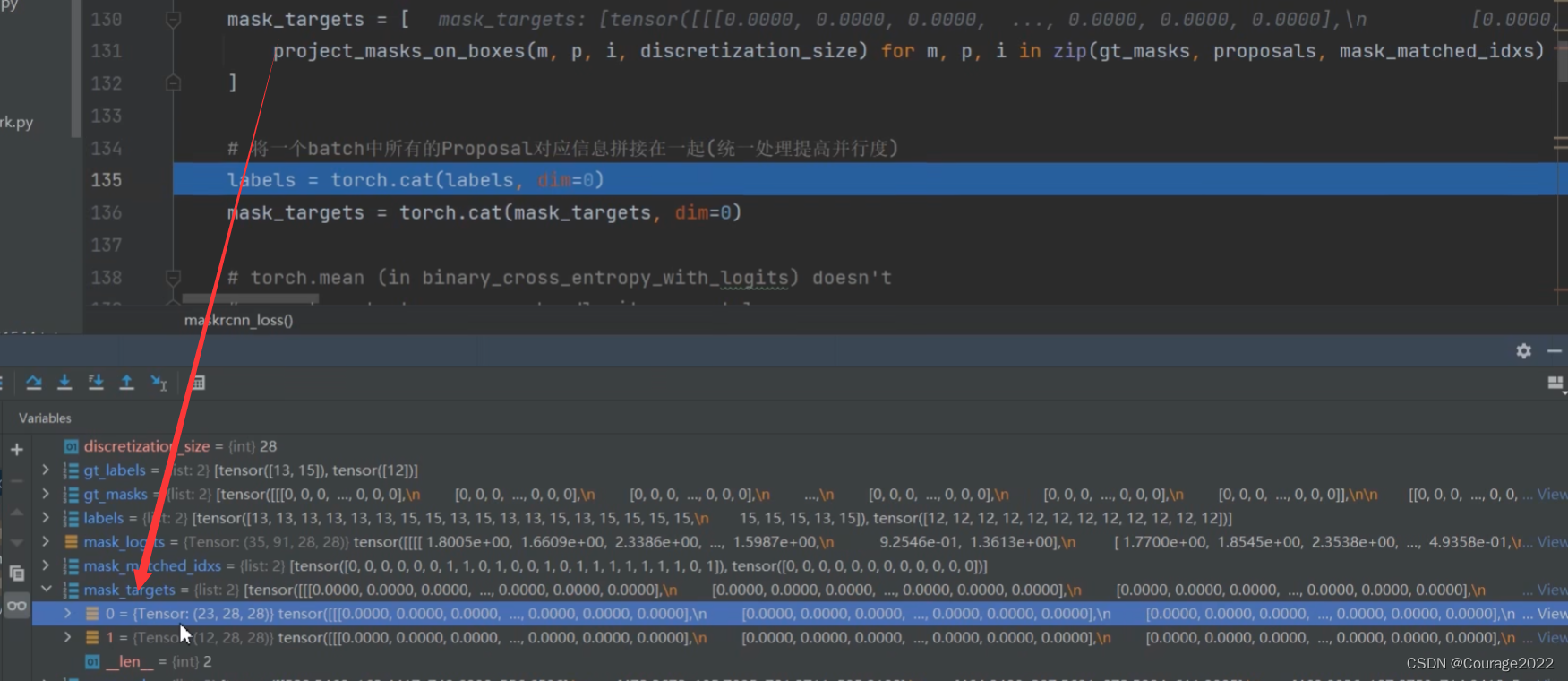
gt_masks = [t["masks"] for t in targets]
gt_labels = [t["labels"] for t in targets]
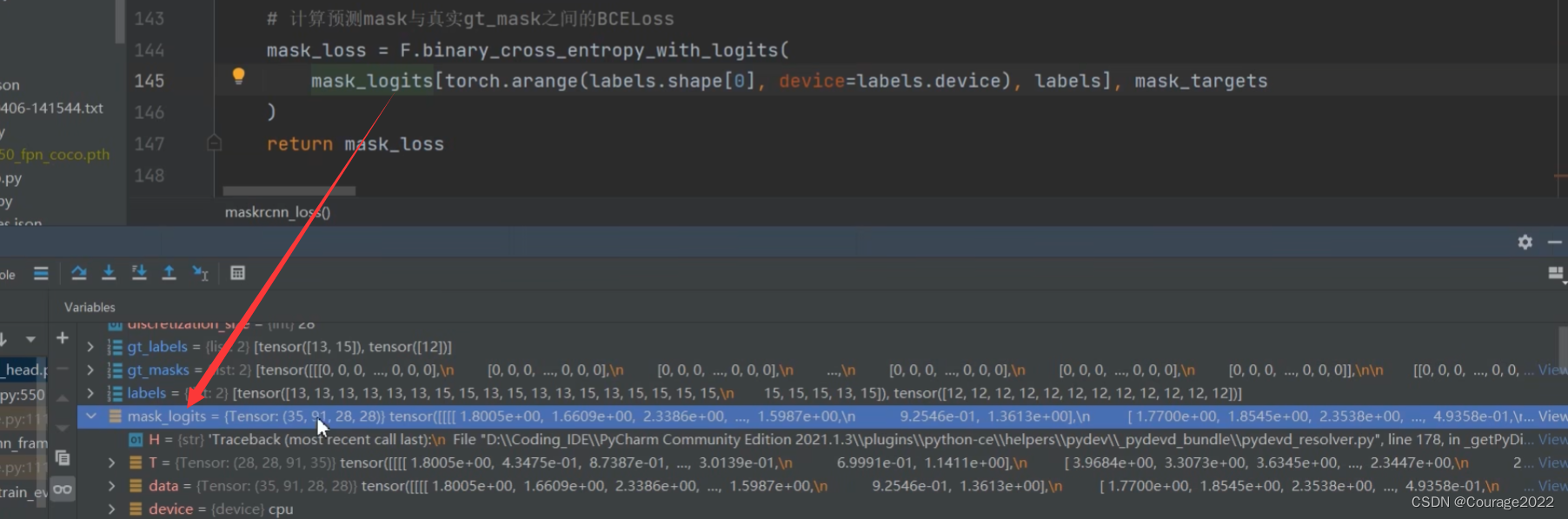
rcnn_loss_mask = maskrcnn_loss(mask_logits, mask_proposals, gt_masks, gt_labels, pos_matched_idxs)
loss_mask = {"loss_mask": rcnn_loss_mask}
else:
labels = [r["labels"] for r in result]
mask_probs = maskrcnn_inference(mask_logits, labels)
for mask_prob, r in zip(mask_probs, result):
r["masks"] = mask_prob
losses.update(loss_mask)
return result, losses
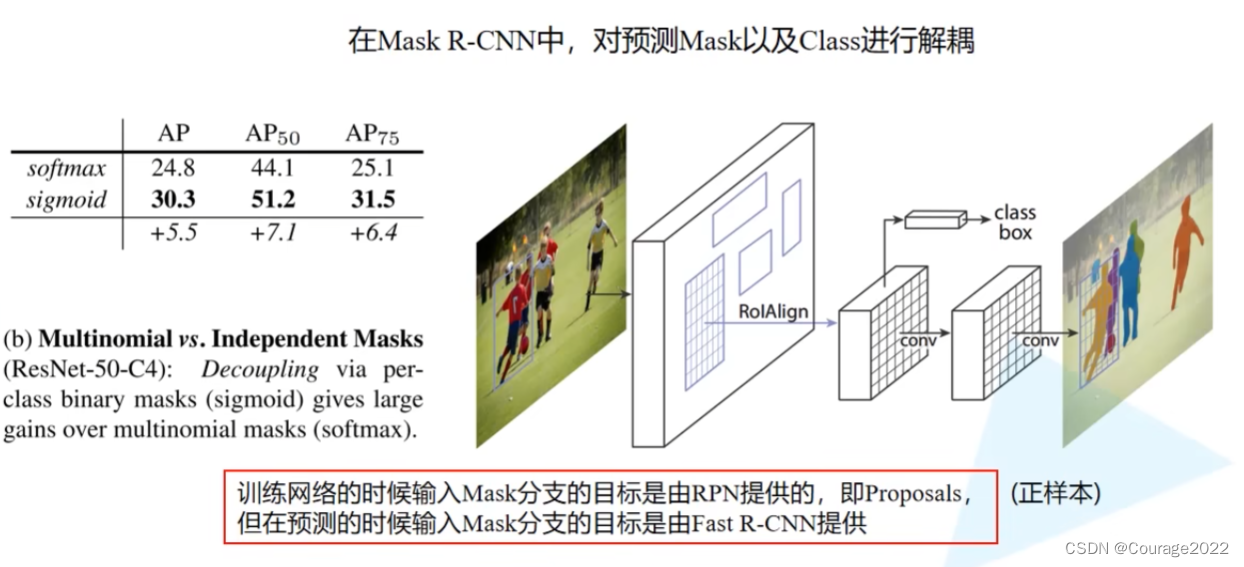
我们只说在Faster R-CNN中没有说过的部分:
我们判断是否有mask分支:if self.has_mask():
def has_mask(self):
if self.mask_roi_pool is None:
return False
if self.mask_head is None:
return False
if self.mask_predictor is None:
return False
return True
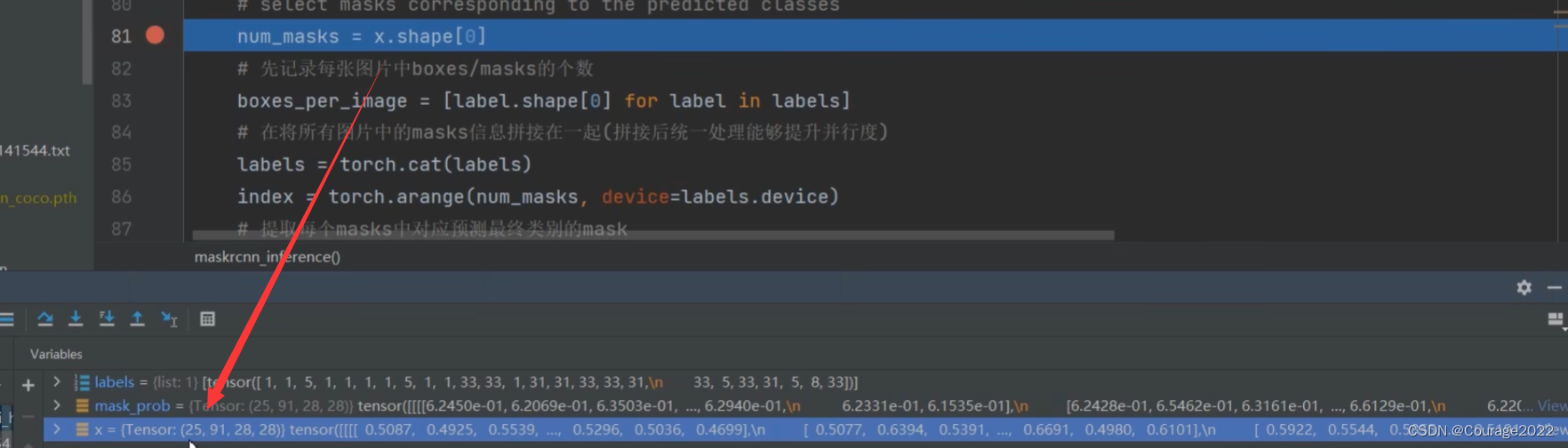
def maskrcnn_inference(x, labels):
# type: (Tensor, List[Tensor]) -> List[Tensor]
"""
From the results of the CNN, post process the masks
by taking the mask corresponding to the class with max
probability (which are of fixed size and directly output
by the CNN) and return the masks in the mask field of the BoxList.
Args:
x (Tensor): the mask logits
labels (list[BoxList]): bounding boxes that are used as
reference, one for ech image
Returns:
results (list[BoxList]): one BoxList for each image, containing
the extra field mask
"""
# 将预测值通过sigmoid激活全部缩放到0~1之间
mask_prob = x.sigmoid()
# select masks corresponding to the predicted classes
num_masks = x.shape[0]
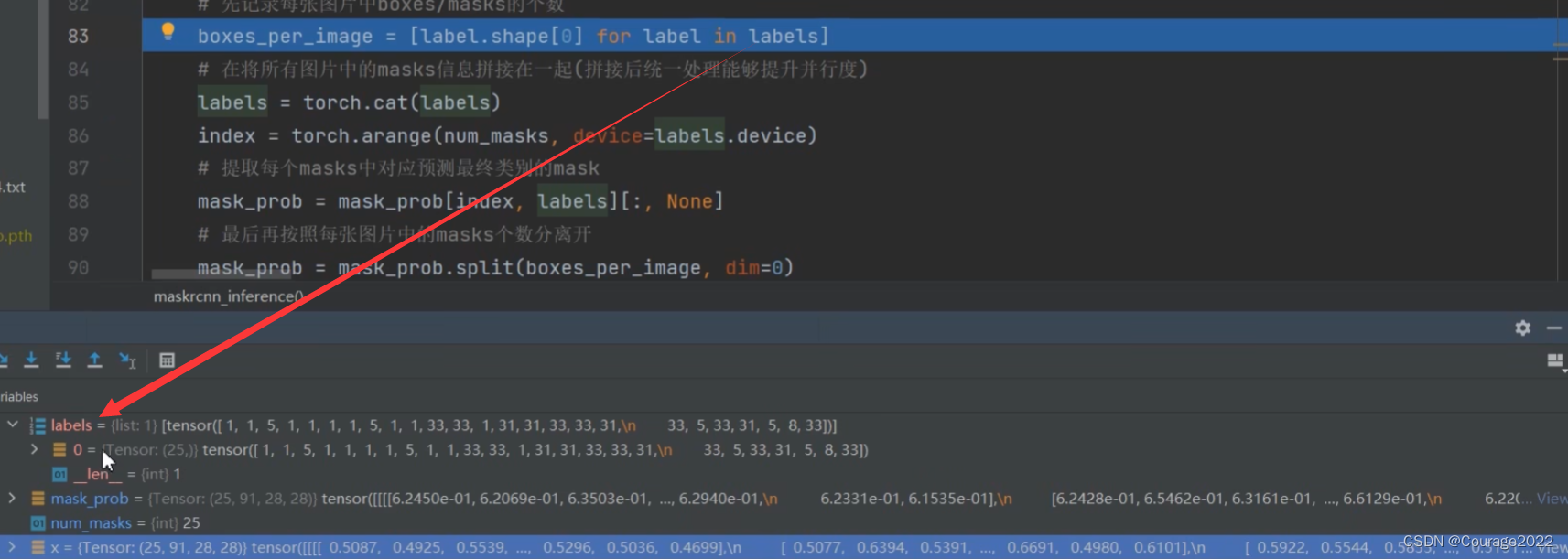
# 先记录每张图片中boxes/masks的个数
boxes_per_image = [label.shape[0] for label in labels]
# 在将所有图片中的masks信息拼接在一起(拼接后统一处理能够提升并行度)
labels = torch.cat(labels)
index = torch.arange(num_masks, device=labels.device)
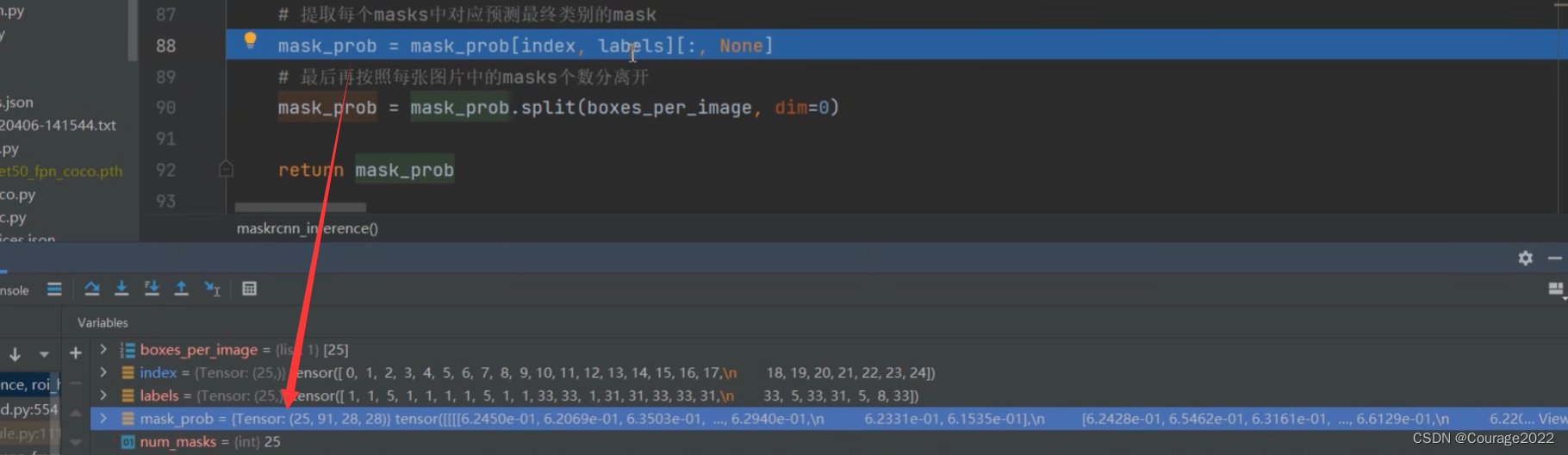
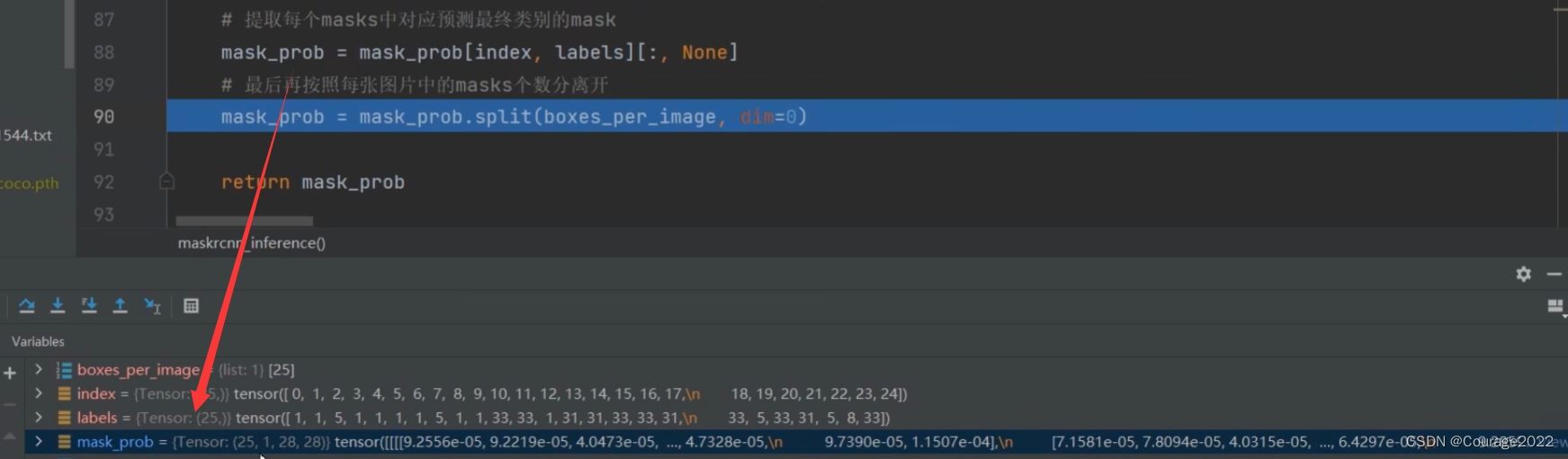
# 提取每个masks中对应预测最终类别的mask
mask_prob = mask_prob[index, labels][:, None]
# 最后再按照每张图片中的masks个数分离开
mask_prob = mask_prob.split(boxes_per_image, dim=0)
return mask_prob
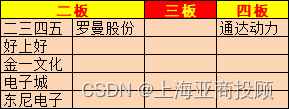
简介靶机地址https://www.vulnhub.com/entry/hacknos-os-hacknos-2,403/#Difficulty : Easy to IntermediateFlag : 2 Flag first user And second rootLearning : Web Application | Enumeration | Password Cracking测试过程信息收集nmap扫描端口nmap -p- -A 192.168.1.103 -…
new和make
new
// The new built-in function allocates memory. The first argument
// is a type,not a value, and the value returned is a pointer to a
// newly // allocated zero value of that type.
func new(Type) *Type对于官方是这么解释new的:这个…
https://blog.csdn.net/qq_41694024/category_12155708.html ③应有深度学习的基础
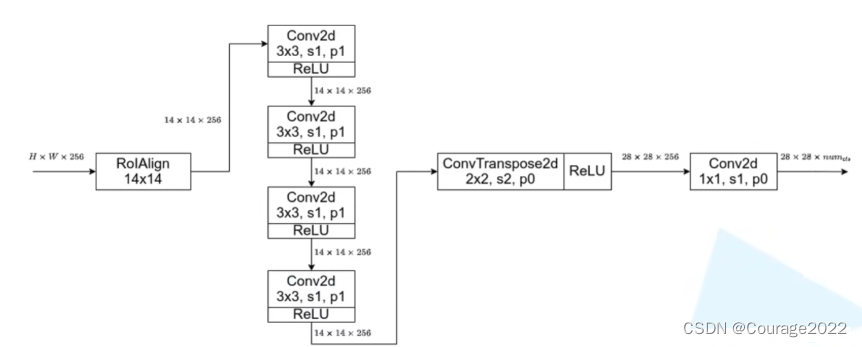
下采样到
的大小,我们在构造mask_roi_pool时,参数featmap_names是指采用FPN结构时,在哪些特征层进行目标特征采样,output_size指采样的高和宽,sampling_ratio采样率默认为2,即采样四个点,之前我们有说过这里不再赘述。
的卷积层。(2.2节)。
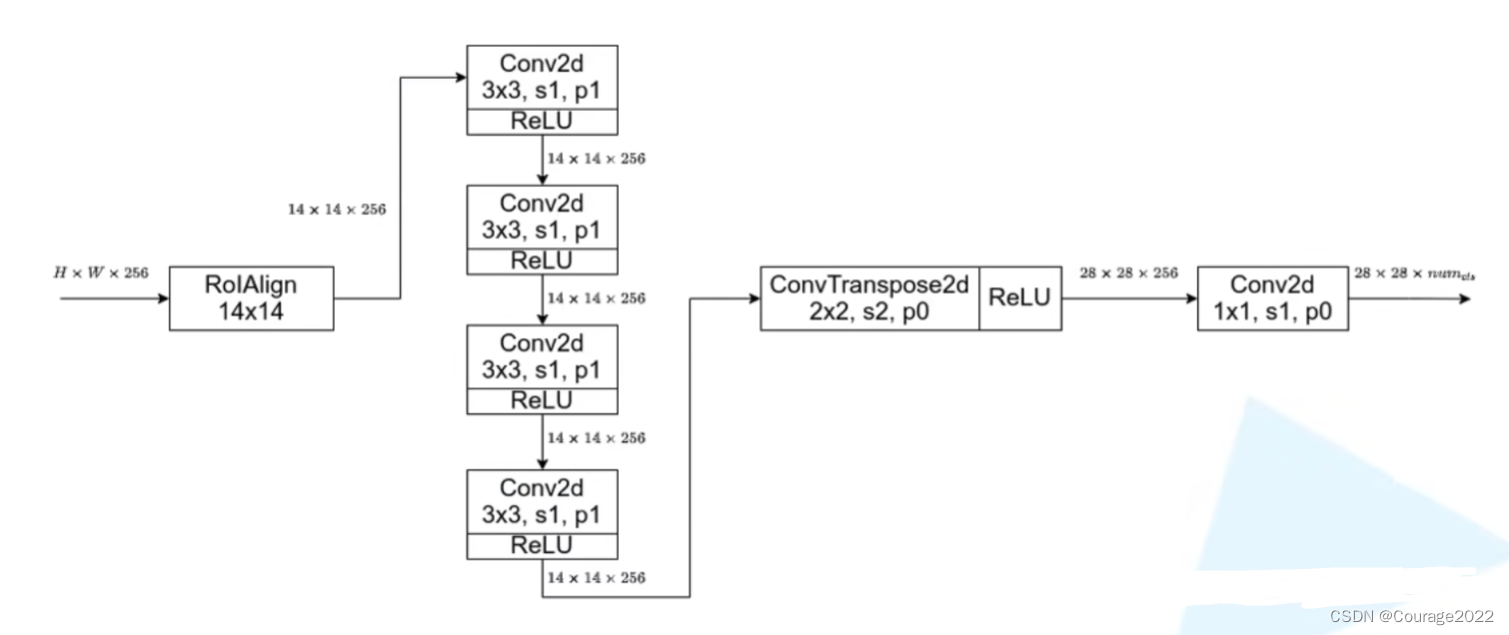

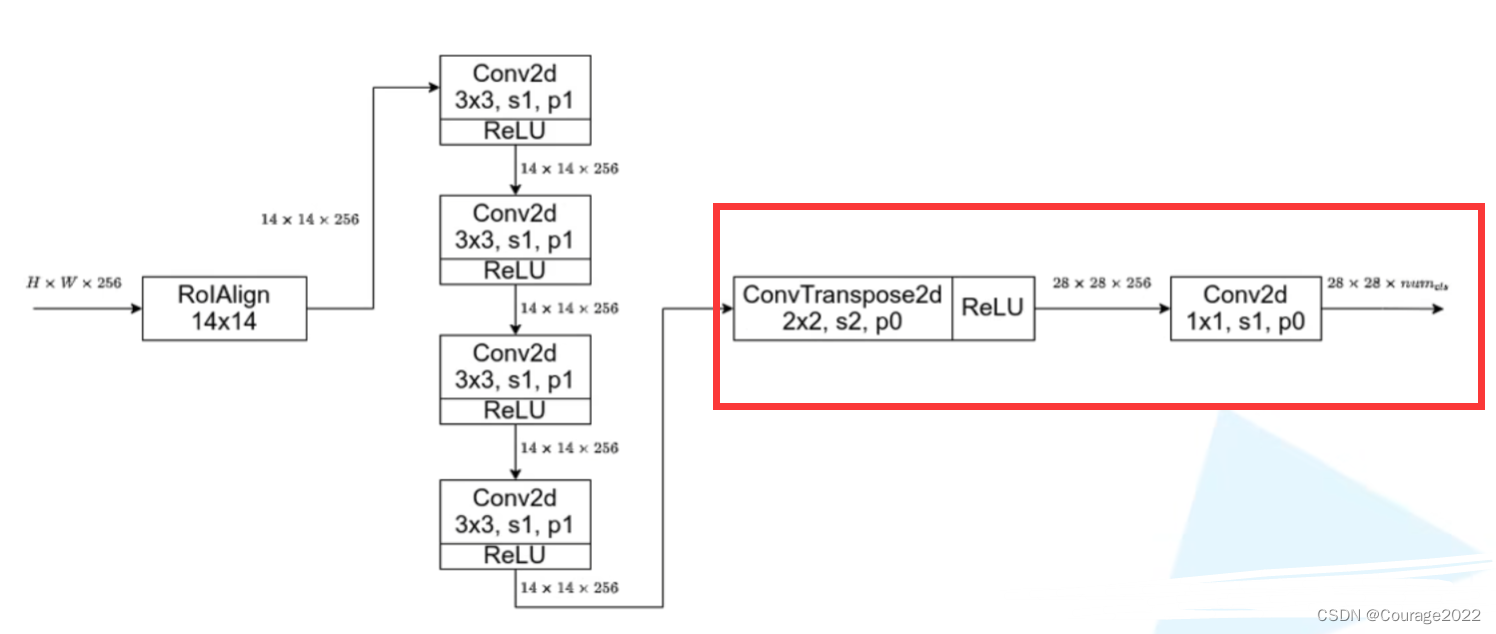
,步距为2,padding为0。再用ReLU激活函数激活。
,步距为1,padding为0。


的。