目录
- 概述
- 效果
- 需要的依赖
- 如何运行
- 算法原理
- 实验
- 输入处理
- 网络结构
- 训练
- 代码
概述
使用DQN实现《飞行的小鸟》游戏,代码可修改扩展为其他游戏,适合学习研究用。
效果

需要的依赖
Python 2.7 or 3
TensorFlow 0.7
pygame
OpenCV-Python
如何运行
运行主函数 deep_q_network.py即可。
算法原理
输入输出关系:深度强化学习是q学习的一个变种,其输入是原始像素,其输出是一个价值函数估计未来的回报。
Deep Q-Network Algorithm伪代码如下:
Initialize replay memory D to size N
Initialize action-value function Q with random weights
for episode = 1, M do
Initialize state s_1
for t = 1, T do
With probability ϵ select random action a_t
otherwise select a_t=max_a Q(s_t,a; θ_i)
Execute action a_t in emulator and observe r_t and s_(t+1)
Store transition (s_t,a_t,r_t,s_(t+1)) in D
Sample a minibatch of transitions (s_j,a_j,r_j,s_(j+1)) from D
Set y_j:=
r_j for terminal s_(j+1)
r_j+γ*max_(a^' ) Q(s_(j+1),a'; θ_i) for non-terminal s_(j+1)
Perform a gradient step on (y_j-Q(s_j,a_j; θ_i))^2 with respect to θ
end for
end for
实验
输入处理
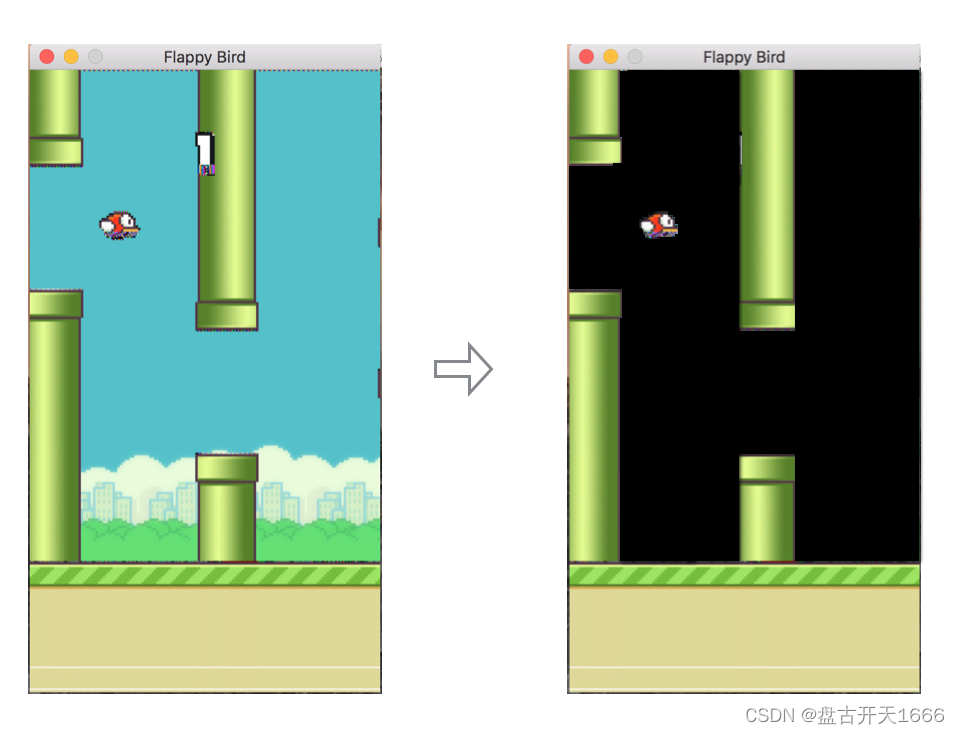
由于深层 Q 网络是在每个时间步骤观察到的游戏屏幕的原始像素值上进行训练的,发现,删除原始游戏中出现的背景可以使它收敛得更快。这个过程可以用下图表示:
网络结构
先对游戏输入图像进行了以下预处理步骤:
- 将图像转换为灰度图
- 将图像调整为 80x80 大小
- 将最后 4 个帧堆叠在一起,为网络生成 80x80x4 输入数组
网络的架构如下图所示。第一层使用 8x8x4x32 内核在 4 的步幅大小上卷积输入图像。输出然后通过 2x2 最大池层。第二层在 2 的步幅上使用 4x4x32x64 内核进行卷积。然后我们再次进行最大池。第三层在 1 的步幅上使用 3x3x64x64 内核进行卷积。然后我们再次最大池。最后一个隐藏层由 256 个完全连接的 ReLU 节点组成。
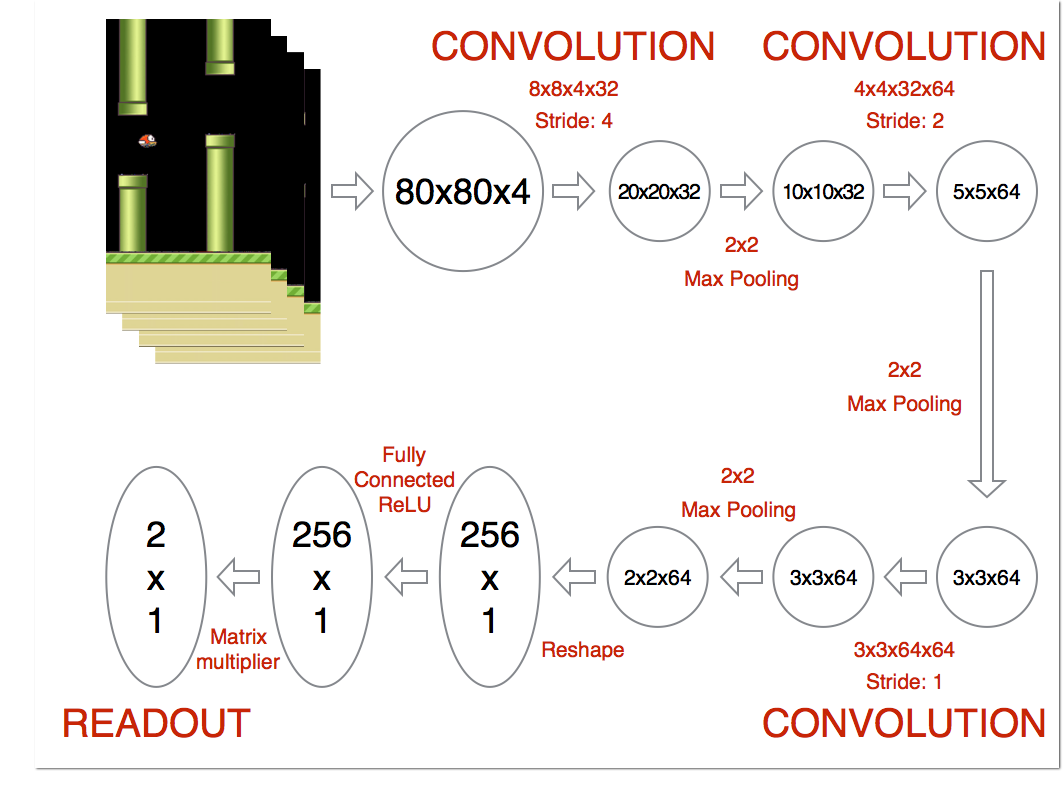
最终输出层的维度与游戏中可以执行的有效操作数量相同,其中 0 索引总是对应于什么也不做。这个输出层的值代表给定输入状态的 Q 函数的每个有效操作。在每个时间步,网络使用ϵ贪心策略执行与最高 Q 值对应的操作。
训练
首先,我使用标准差为 0.01 的正态分布随机初始化所有权重矩阵,然后将重放记忆大小设置为 500,000 次实验。
我开始训练,在最初的 10,000 个时间步中随机均匀选择操作,而不更新网络权重。这使得系统在训练开始前填充重放记忆。
注意,在接下来的 3000,000 个帧中将ϵ从 0.1 线性退火到 0.0001。我这样设置的原因是,在我们的游戏中,代理可以在每 0.03 秒内选择一个操作(FPS=30),高ϵ将使它抖动太多,从而使它保持在游戏屏幕的顶部,最终以笨拙的方式撞到管道。这种情况将使 Q 函数相对较慢地收敛,因为它只有在ϵ较低时才开始看到其他条件。但是,在其他游戏中,将ϵ初始化为 1 更合理。
在训练时间内,在每个时间步,网络从重放记忆中采样大小为 32 的小批量进行训练,并使用学习率为 0.000001 的 Adam 优化算法在上述损失函数上执行梯度步。在退火完成后,网络继续无限期地训练,ϵ固定为 0.001。
代码
主函数
import tensorflow as tf
import cv2
import random
import numpy as np
from collections import deque
#Game的定义类,此处Game是什么不重要,只要提供执行Action的方法,获取当前游戏区域像素的方法即可
class Game(object):
def __init__(self): #Game初始化
# action是MOVE_STAY、MOVE_LEFT、MOVE_RIGHT
# ai控制棒子左右移动;返回游戏界面像素数和对应的奖励。(像素->奖励->强化棒子往奖励高的方向移动)
pass
def step(self, action):
pass
# learning_rate
GAMMA = 0.99
# 跟新梯度
INITIAL_EPSILON = 1.0
FINAL_EPSILON = 0.05
# 测试观测次数
EXPLORE = 500000
OBSERVE = 500
# 记忆经验大小
REPLAY_MEMORY = 500000
# 每次训练取出的记录数
BATCH = 100
# 输出层神经元数。代表3种操作-MOVE_STAY:[1, 0, 0] MOVE_LEFT:[0, 1, 0] MOVE_RIGHT:[0, 0, 1]
output = 3
MOVE_STAY =[1, 0, 0]
MOVE_LEFT =[0, 1, 0]
MOVE_RIGHT=[0, 0, 1]
input_image = tf.placeholder("float", [None, 80, 100, 4]) # 游戏像素
action = tf.placeholder("float", [None, output]) # 操作
#定义CNN-卷积神经网络
def convolutional_neural_network(input_image):
weights = {'w_conv1':tf.Variable(tf.zeros([8, 8, 4, 32])),
'w_conv2':tf.Variable(tf.zeros([4, 4, 32, 64])),
'w_conv3':tf.Variable(tf.zeros([3, 3, 64, 64])),
'w_fc4':tf.Variable(tf.zeros([3456, 784])),
'w_out':tf.Variable(tf.zeros([784, output]))}
biases = {'b_conv1':tf.Variable(tf.zeros([32])),
'b_conv2':tf.Variable(tf.zeros([64])),
'b_conv3':tf.Variable(tf.zeros([64])),
'b_fc4':tf.Variable(tf.zeros([784])),
'b_out':tf.Variable(tf.zeros([output]))}
conv1 = tf.nn.relu(tf.nn.conv2d(input_image, weights['w_conv1'], strides = [1, 4, 4, 1], padding = "VALID") + biases['b_conv1'])
conv2 = tf.nn.relu(tf.nn.conv2d(conv1, weights['w_conv2'], strides = [1, 2, 2, 1], padding = "VALID") + biases['b_conv2'])
conv3 = tf.nn.relu(tf.nn.conv2d(conv2, weights['w_conv3'], strides = [1, 1, 1, 1], padding = "VALID") + biases['b_conv3'])
conv3_flat = tf.reshape(conv3, [-1, 3456])
fc4 = tf.nn.relu(tf.matmul(conv3_flat, weights['w_fc4']) + biases['b_fc4'])
output_layer = tf.matmul(fc4, weights['w_out']) + biases['b_out']
return output_layer
#训练神经网络
def train_neural_network(input_image):
argmax = tf.placeholder("float", [None, output])
gt = tf.placeholder("float", [None])
#损失函数
predict_action = convolutional_neural_network(input_image)
action = tf.reduce_sum(tf.mul(predict_action, argmax), reduction_indices = 1) #max(Q(S,:))
cost = tf.reduce_mean(tf.square(action - gt))
optimizer = tf.train.AdamOptimizer(1e-6).minimize(cost)
#游戏开始
game = Game()
D = deque()
_, image = game.step(MOVE_STAY)
image = cv2.cvtColor(cv2.resize(image, (100, 80)), cv2.COLOR_BGR2GRAY)
ret, image = cv2.threshold(image, 1, 255, cv2.THRESH_BINARY)
input_image_data = np.stack((image, image, image, image), axis = 2)
with tf.Session() as sess:
#初始化神经网络各种参数
sess.run(tf.initialize_all_variables())
#保存神经网络参数的模块
saver = tf.train.Saver()
#总的运行次数
n = 0
epsilon = INITIAL_EPSILON
while True:
#神经网络输出的是Q(S,:)值
action_t = predict_action.eval(feed_dict = {input_image : [input_image_data]})[0]
argmax_t = np.zeros([output], dtype=np.int)
#贪心选取动作
if(random.random() <= INITIAL_EPSILON):
maxIndex = random.randrange(output)
else:
maxIndex = np.argmax(action_t)
#将action对应的Q(S,a)最大值提取出来
argmax_t[maxIndex] = 1
#贪婪的部分开始不断的增加
if epsilon > FINAL_EPSILON:
epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / EXPLORE
#将选取的动作带入到环境,观察环境状态S'与回报reward
reward, image = game.step(list(argmax_t))
#将得到的图形进行变换用于神经网络的输出
image = cv2.cvtColor(cv2.resize(image, (100, 80)), cv2.COLOR_BGR2GRAY)
ret, image = cv2.threshold(image, 1, 255, cv2.THRESH_BINARY)
image = np.reshape(image, (80, 100, 1))
input_image_data1 = np.append(image, input_image_data[:, :, 0:3], axis = 2)
#将S,a,r,S'记录的大脑中
D.append((input_image_data, argmax_t, reward, input_image_data1))
#大脑的记忆是有一定的限度的
if len(D) > REPLAY_MEMORY:
D.popleft()
#如果达到观察期就要进行神经网络训练
if n > OBSERVE:
#随机的选取一定记忆的数据进行训练
minibatch = random.sample(D, BATCH)
#将里面的每一个记忆的S提取出来
input_image_data_batch = [d[0] for d in minibatch]
#将里面的每一个记忆的a提取出来
argmax_batch = [d[1] for d in minibatch]
#将里面的每一个记忆回报提取出来
reward_batch = [d[2] for d in minibatch]
#将里面的每一个记忆的下一步转台提取出来
input_image_data1_batch = [d[3] for d in minibatch]
gt_batch = []
#利用已经有的求解Q(S',:)
out_batch = predict_action.eval(feed_dict = {input_image : input_image_data1_batch})
#利用bellman优化得到长期的回报r + γmax(Q(s',:))
for i in range(0, len(minibatch)):
gt_batch.append(reward_batch[i] + GAMMA * np.max(out_batch[i]))
#利用事先定义的优化函数进行优化神经网络参数
print("gt_batch:", gt_batch, "argmax:", argmax_batch)
optimizer.run(feed_dict = {gt : gt_batch, argmax : argmax_batch, input_image : input_image_data_batch})
input_image_data = input_image_data1
n = n+1
print(n, "epsilon:", epsilon, " ", "action:", maxIndex, " ", "_reward:", reward)
train_neural_network(input_image)
注意:完整项目代码链接