目录
介绍:
模板:
例题:从景色、花费、饮食,男女比例四个方面去选取目的地
准则重要性矩阵:
每个准则的方案矩阵:
一致性检验:
特征值法求权值:
完整代码:
运行结果:
介绍:
层次分析法(Analytic Hierarchy Process, AHP)是一种多准则决策分析方法,它将多个准则组织成一个层次结构,通过对各个层次之间的比较和权重的计算,最终得到准则的相对重要性和最优解决方案。
层次分析法的基本思想是将复杂的决策问题分解为一系列层次,从总体目标到具体准则和方案,建立层次结构模型。在层次结构模型中,各层次之间的关系通过比较矩阵来表示,比较矩阵中的元素表示各个准则或方案之间的相对重要性。
在层次分析法中,通过对比较矩阵进行一系列计算,可以得到各个准则和方案的权重,从而评估它们的相对重要性。最终,通过计算各个方案的综合评价值,可以选择最优解决方案。
层次分析法的特点是能够处理多个准则之间的相对重要性,能够量化主观判断,并且易于理解和应用。它广泛应用于决策分析、资源分配、评估和排序等领域。
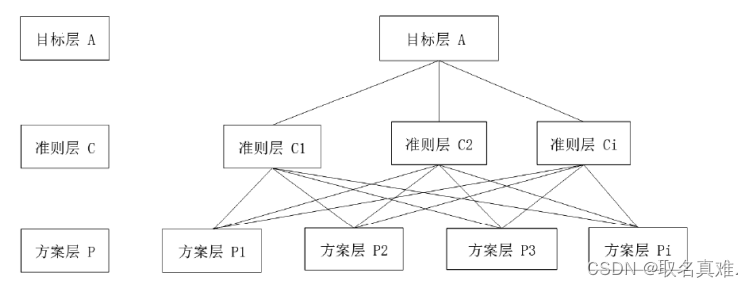
模板:
#以下是一个使用Python实现层次分析法的简单模板:
```python
import numpy as np
def ahp(criteria_matrix):
n = len(criteria_matrix)
weights_matrix = np.zeros((n, n))
# Step 1: 计算准则矩阵的列向量归一化
column_sums = criteria_matrix.sum(axis=0)
normalized_matrix = criteria_matrix / column_sums
# Step 2: 计算每个准则的权重
weights = normalized_matrix.sum(axis=1) / n
# Step 3: 计算每个准则之间的相对重要性
for i in range(n):
for j in range(n):
weights_matrix[i, j] = weights[i] / weights[j]
# Step 4: 计算最终权重
final_weights = weights_matrix.sum(axis=1) / n
return final_weights
# 测试代码
criteria_matrix = np.array([[1, 1/2, 2], [2, 1, 3], [1/2, 1/3, 1]])
weights = ahp(criteria_matrix)
print("准则的权重:", weights)
```
在这个模板中,我们首先定义了一个名为`ahp`的函数,它接收一个准则矩阵作为参数。准则矩阵是一个n×n的二维数组,表示准则之间的相对重要性。
在函数内部,我们首先计算准则矩阵的列向量归一化,然后计算每个准则的权重。接下来,我们通过两层循环计算每个准则之间的相对重要性,并将结果存储在权重矩阵中。
最后,我们计算权重矩阵每一行的平均值作为最终的权重,并返回结果。
在测试代码中,我们创建了一个准则矩阵`criteria_matrix`,然后调用`ahp`函数计算准则的权重,并打印出结果。
请注意,这只是一个简单的模板,可以根据具体的应用场景进行修改和扩展。例题:从景色、花费、饮食,男女比例四个方面去选取目的地


准则重要性矩阵:

# 准则重要性矩阵,即为我们在这里的时候要输入准则性矩阵
criteria = np.array([
[1,1/2,4,3],
[2,1,5,5],
[1/4,1/5,1,1/4],
[1/3,1/5,4,1]]) 每个准则的方案矩阵:
# 对每个准则,方案优劣排序,即为方案层也会有一个一致矩阵,所以需要判
b1 = np.array([[1, 2, 5], [1 / 2, 1, 2], [1 / 5, 1 / 2, 1]])
b2 = np.array([[1, 2, 3], [1 / 2, 1, 2], [1 / 3, 1 / 2, 1]])
b3 = np.array([[1,1,3],[1,1,2],[1/3,1/2,1]])
b4 = np.array([[1,3,5],[1/3,1,4],[1/5,1/4,1]])
b = [b1, b2, b3, b4]一致性检验:
进行一致性检验是为了确定层次分析法的结果是否可信和可靠。一致性检验是通过计算一致性指标来评估判断矩阵的相对一致性。
在层次分析法中,判断矩阵是用专家主观判断准则之间的相对重要性构成的,因此可能存在主观性的偏差和一致性问题。如果判断矩阵不一致,那么使用该矩阵计算得到的权重可能是不准确的,从而导致决策结果的偏离。
一致性检验通常使用一致性比率(Consistency Ratio,CR)来进行评估。CR是通过计算判断矩阵的最大特征值和一致性指标的比值得到的。如果CR小于某个阈值(通常为0.1),那么判断矩阵被认为是一致的,可以用来计算权重。如果CR大于阈值,那么判断矩阵存在较大的一致性问题,需要重新进行调整或修改。
通过一致性检验,我们可以对层次分析法的结果进行质量控制,确保决策结果的准确性和可信度。
# 一致性检验
def calculate_weight(data):
RI = (0, 0.00001, 0.52, 0.89, 1.12, 1.26, 1.36, 1.41, 1.46, 1.49, 1.52, 1.54, 1.56, 1.58, 1.59)
# 转化为array类型的对象
in_matrix = np.array(data)
n, n2 = in_matrix.shape
eig_values, eig_vectors = np.linalg.eig(in_matrix) # np.linalg.eig(matri)返回特征值和特征向量
# eigvalues为特征向量,eigvectors为特征值构成的对角矩阵(而且其他位置都为0,对角元素为特征值)
max_index = np.argmax(eig_values) # argmax为获取最大特征值的下标,而且这里是获取实部
# print(max_index)
max_eig = eig_values[max_index].real # 这里max_eig是最大的特征值
# print(max_eig)
eig_=calculate_feature_weight(in_matrix,n)
if n > 15:#超过十五个特征,相对效果差
CR = None
warnings.warn(("无法判断一致性"))
else:
CI = (max_eig - n) / (n - 1)
if RI[n - 1] != 0:
CR = CI / RI[n - 1]
if CR < 0.1:
print("一致性可以被接受")
else:
print("一致性不能被接受")
return max_eig, CR, eig_
特征值法求权值:
# 特征值法求权重
def calculate_feature_weight(matrix, n):
# 特征值法主要是通过求出矩阵的最大特征值和对应的特征向量,然后对其特征向量进行归一化,最后获得权重
eigValue, eigVectors = np.linalg.eig(matrix)# np.linalg.eig(matri)返回特征值和特征向量
max_index = np.argmax(eigValue)# argmax为获取最大特征值的下标,而且这里是获取实部
max_eig = eigValue[max_index].real#这里max_eig是最大的特征值
eig_ = eigVectors[:, max_index].real#最大特征值对应的特征向量
eig_ = eig_ / eig_.sum()
return eig_# 这里返回的是特征向量完整代码:
#coding=gbk
import numpy as np
import pandas as pd
import warnings
# 一致性检验
def calculate_weight(data):
RI = (0, 0.00001, 0.52, 0.89, 1.12, 1.26, 1.36, 1.41, 1.46, 1.49, 1.52, 1.54, 1.56, 1.58, 1.59)
# 转化为array类型的对象
in_matrix = np.array(data)
n, n2 = in_matrix.shape
# 判断矩阵是否为方阵,而且矩阵的大小为n,n2
eig_values, eig_vectors = np.linalg.eig(in_matrix) # np.linalg.eig(matri)返回特征值和特征向量
# eigvalues为特征向量,eigvectors为特征值构成的对角矩阵(而且其他位置都为0,对角元素为特征值)
max_index = np.argmax(eig_values) # argmax为获取最大特征值的下标,而且这里是获取实部
# print(max_index)
max_eig = eig_values[max_index].real # 这里max_eig是最大的特征值
# print(max_eig)
eig_=calculate_feature_weight(in_matrix,n)
if n > 15:#超过十五个特征,相对效果差
CR = None
warnings.warn(("无法判断一致性"))
else:
CI = (max_eig - n) / (n - 1)
if RI[n - 1] != 0:
CR = CI / RI[n - 1]
if CR < 0.1:
print("一致性可以被接受")
else:
print("一致性不能被接受")
return max_eig, CR, eig_
# 特征值法求权重
def calculate_feature_weight(matrix, n):
# 特征值法主要是通过求出矩阵的最大特征值和对应的特征向量,然后对其特征向量进行归一化,最后获得权重
eigValue, eigVectors = np.linalg.eig(matrix)# np.linalg.eig(matri)返回特征值和特征向量
max_index = np.argmax(eigValue)# argmax为获取最大特征值的下标,而且这里是获取实部
max_eig = eigValue[max_index].real#这里max_eig是最大的特征值
eig_ = eigVectors[:, max_index].real#最大特征值对应的特征向量
eig_ = eig_ / eig_.sum()
return eig_# 这里返回的是特征向量
if __name__ == "__main__":
# 准则重要性矩阵,即为我们在这里的时候要输入准则性矩阵
criteria = np.array([
[1,1/2,4,3],
[2,1,5,5],
[1/4,1/5,1,1/4],
[1/3,1/5,4,1]])
# 对每个准则,方案优劣排序,即为方案层也会有一个一致矩阵,所以需要判
b1 = np.array([[1, 2, 5], [1 / 2, 1, 2], [1 / 5, 1 / 2, 1]])
b2 = np.array([[1, 2, 3], [1 / 2, 1, 2], [1 / 3, 1 / 2, 1]])
b3 = np.array([[1,1,3],[1,1,2],[1/3,1/2,1]])
b4 = np.array([[1,3,5],[1/3,1,4],[1/5,1/4,1]])
b = [b1, b2, b3, b4]
matrix_in = criteria
max_eigen, CR, criteria_eigen = calculate_weight(matrix_in)
print("准则层:最大特征值:{:.5f},CR={:<.5f},检验{}通过".format(max_eigen, CR, '' if CR < 0.1 else "不"))
print("准则层权重为{}\n".format(criteria_eigen))
max_eigen_list = []
CR_list = []
eigen_list = []
for i in b:
max_eigen, CR, eigen = calculate_weight(i)#每个准则
max_eigen_list.append(max_eigen)#存最大特征值
CR_list.append(CR)#存CR
eigen_list.append(eigen)#存特征向量
pd_print = pd.DataFrame(eigen_list, index=["准则" + str(i) for i in range(0, criteria.shape[0])],
columns=["方案" + str(i) for i in range(0, b[0].shape[0])])
pd_print.loc[:, '最大特征值'] = max_eigen_list
print("方案层")
print(pd_print)
print("\n")
# 目标层
object = np.dot(criteria_eigen.reshape(1, -1), np.array(eigen_list))
print("\n目标层", object)
print("最优选择方案{}".format(np.argmax(object)))
print("即为苏杭")运行结果:
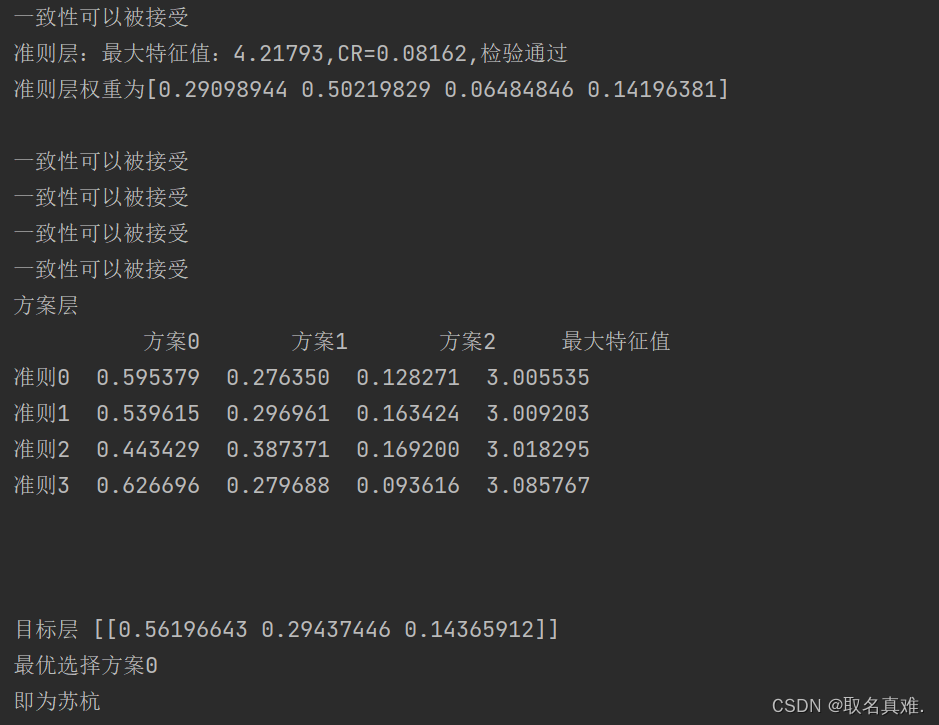




![每日一题 --- 209. 长度最小的子数组[力扣][Go]](https://img-blog.csdnimg.cn/direct/cf7ba345cbee450f860f0ae86cf678cd.png)