DBscan算法原理 :
dbscan算法-CSDN博客
法一(调库) :
直接调库 :
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import DBSCAN
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import StandardScaler
# 加载数据集
iris = datasets.load_iris()
X = iris.data
# 数据预处理,标准化数据
scaler = StandardScaler()
X = scaler.fit_transform(X)
# 使用DBSCAN聚类算法
dbscan = DBSCAN(eps=0.5, min_samples=5) # 获取DBSCAN聚类对象
y_pred = dbscan.fit_predict(X)
# 输出聚类结果
print('聚类结果:', y_pred)
# 可视化
pca = PCA(n_components=2)
transformed = pca.fit_transform(X)
print(transformed)
# 绘制聚类结果
plt.scatter(transformed[:, 0], transformed[:, 1], c=y_pred)
plt.xlabel('Component 1')
plt.ylabel('Component 2')
plt.title('DBSCAN Clustering on Iris Dataset')
plt.show()其中重要的代码也就两行 :
# 使用DBSCAN聚类算法
dbscan = DBSCAN(eps=0.5, min_samples=5) # 获取DBSCAN聚类对象
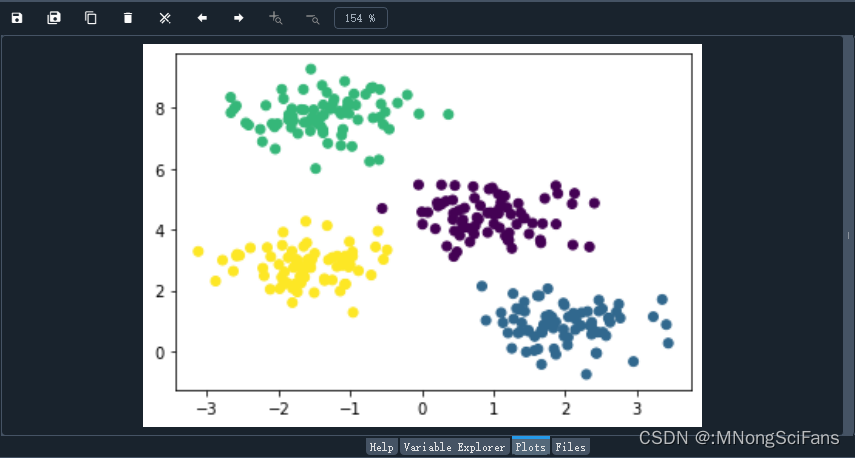
y_pred = dbscan.fit_predict(X)实现效果 :

法二(手写):
思路 : 根据原理实现,可根据具体注释理解(相信一定能够看懂)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import DBSCAN
from sklearn.decomposition import PCA
def distance(p1, p2): # 计算两点的欧式距离
return np.sqrt(np.sum((p1 - p2) ** 2))
def region_query(data, idx , eps): # 获取与data相邻点的下标集合
neighbors = [] # 创建空邻居列表
for index, point in enumerate(data):
if distance(point, data[idx]) <= eps:
neighbors.append(index)
return neighbors
def expand_cluster(data, labels, point_index, cluster_label, eps, min_samples): # 对点进行扩展
neighbors = region_query(data, point_index, eps)
if len(neighbors) < min_samples:# 领域内少于min_samples --> 为噪声点
labels[point_index] = -1 # 标记为噪声点
return False
else:
labels[point_index] = cluster_label # 标记为当前标签
for neighbor_index in neighbors:
if labels[neighbor_index] == 0:# 该点未访问过
labels[neighbor_index] = cluster_label
expand_cluster(data, labels, neighbor_index, cluster_label, eps, min_samples) # 继续找下去 , 递归
return True
def dbscan(data, eps, min_samples):
n = len(data) # 求数据的长度
labels = np.zeros(n) # 0表示未分类 : 先全部赋值为 0
cluster_label = 0 # 簇的数量 / 簇的标记 , 每当一个新的聚类被创建时,cluster_label的值会递增,以便为下一个聚类指定不同的标签。
# 类似于BFS
for idx in range(n):# 访问所有点
if labels[idx] == 0:# 当前点未访问
if expand_cluster(data, labels, idx , cluster_label + 1, eps, min_samples):
cluster_label += 1
return labels
# 准备数据准备
iris = datasets.load_iris()
x = iris.data # 导入鸢尾花数据集
# DBSCAN进行聚类
eps = 0.5 # 邻域半径
min_samples = 5 # 最小样本数
labels = dbscan(x, eps, min_samples) # 获取聚类结果
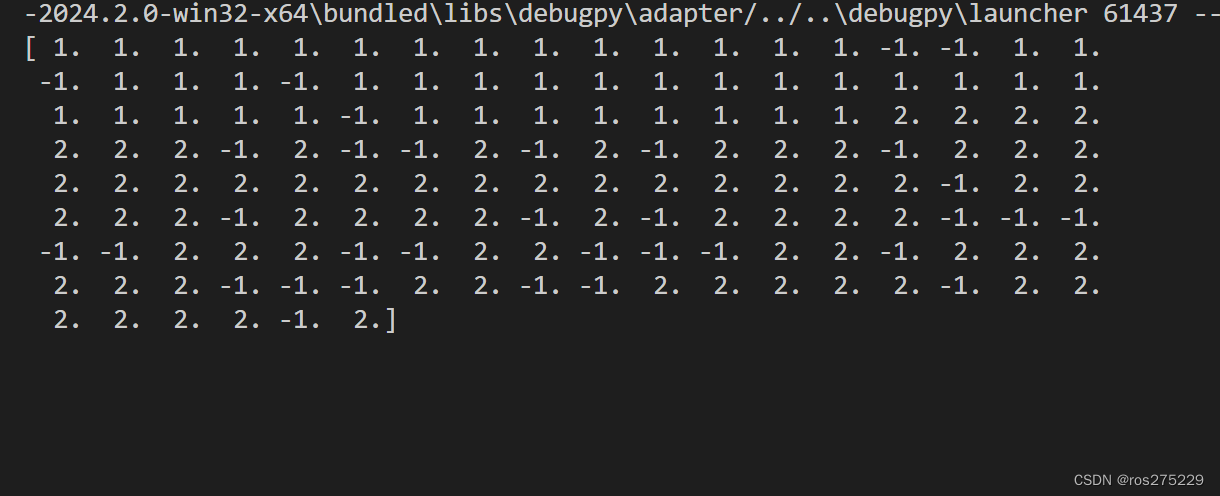
print(labels)
# 可视化
pca = PCA(n_components=2)
transformed = pca.fit_transform(x)
plt.scatter(transformed[:, 0], transformed[:, 1], c=labels)
plt.xlabel('Component 1')
plt.ylabel('Component 2')
plt.title('DBSCAN Clustering on Iris Dataset')
plt.show()实现效果 :

具体分类数据 :


![每日一题 --- 209. 长度最小的子数组[力扣][Go]](https://img-blog.csdnimg.cn/direct/cf7ba345cbee450f860f0ae86cf678cd.png)