目录
理论
实践
理论
https://arxiv.org/abs/1810.04805

BERT(Bidirectional Encoder Representations from Transformers)是一种自然语言处理(NLP)模型,由Google在2018年提出。它是基于Transformer模型的预训练方法,通过在大规模的无标注文本上进行预训练,学习到了丰富的语言表示。
BERT的主要特点是双向性和预训练-微调框架。在传统的语言模型中,只使用了单向的上下文信息,而BERT利用了双向Transformer编码器来同时考虑上下文的信息,使得模型能够更好地理解句子中的语义和关系。BERT采用了Transformer的多层编码器结构,其中包含了自注意力机制(self-attention mechanism),能够有效地捕捉句子中不同位置的依赖关系。
单向的Transformer一般被称为Transformer decoder,其每一个token(符号)只会attend到目前往左的token。而双向的Transformer则被称为Transformer encoder,其每一个token会attend到所有的token。
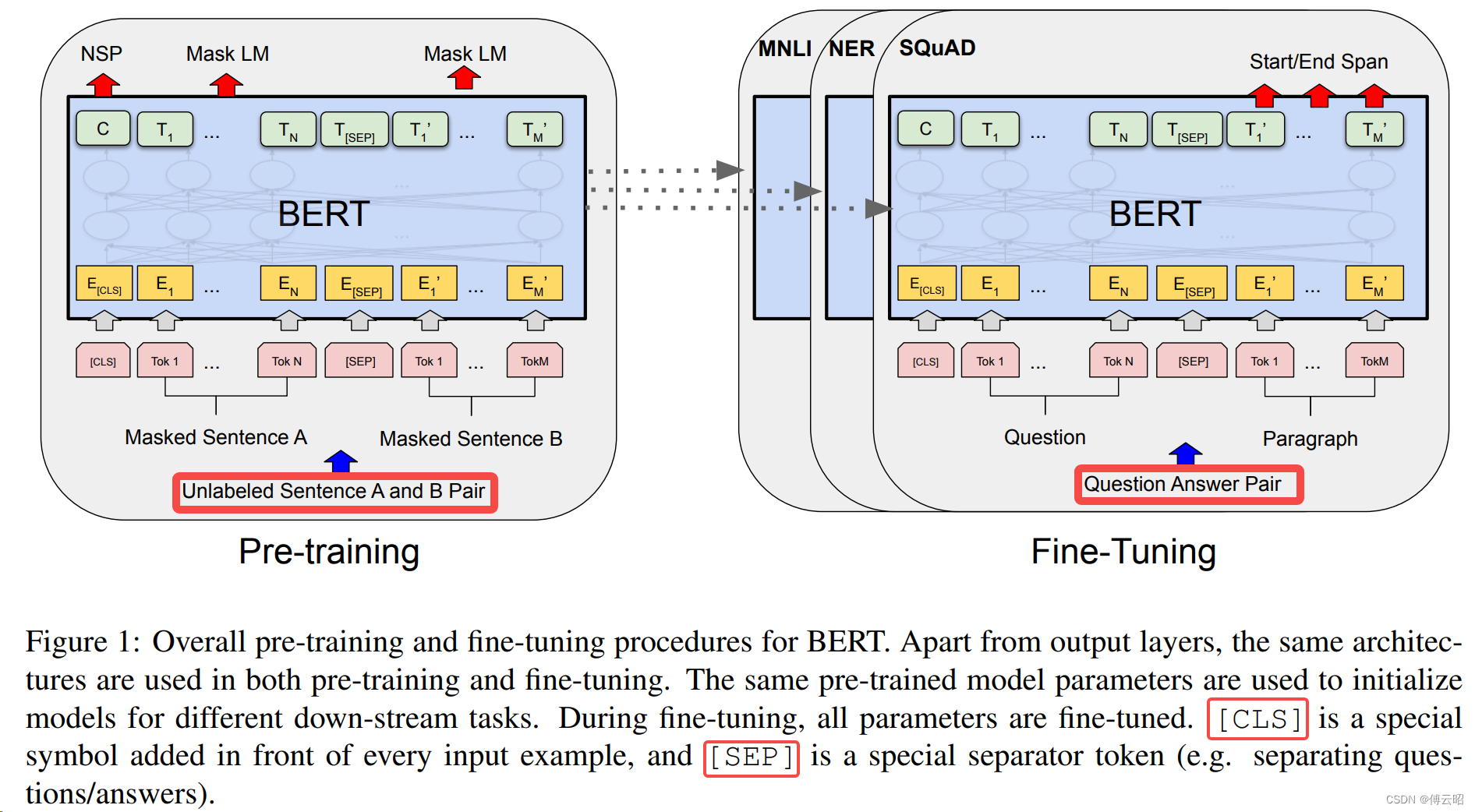
BERT模型通过两个阶段的训练来获得语言表示。首先,它在大规模无标注的文本上进行预训练,使用两个任务:掩码语言建模(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction,NSP)。
在MLM任务中,随机掩盖输入句子的一些词汇,模型需要预测这些被掩盖的词汇。MLM任务的目的是让模型通过上下文来推断被掩盖的词汇,从而学习到丰富的语言表示。在预训练阶段,BERT模型会使用大规模的无标注文本进行训练,其中包括了来自维基百科、新闻文章、书籍等的文本数据。模型在这些大规模数据上进行预训练,通过尝试预测被掩盖词汇的方法来学习词汇的上下文关系和语义。在MLM任务中,模型的输入句子经过编码器(Transformer)进行编码,然后通过一个全连接层(输出层)来预测被掩盖的词汇。对于被掩盖的位置,模型会生成一个概率分布,以表示每个可能的词汇是被掩盖位置的预测。通常情况下,模型会根据预训练过程中的目标函数(如交叉熵损失)来优化预测结果。通过进行MLM任务的预训练,BERT模型能够学习到词汇的上下文信息和语义表示,从而在下游任务中具有更好的表现。在微调阶段,模型会使用有标签的数据进行进一步的训练,以适应特定任务的要求,并通过微调来提升模型在特定任务上的性能。对比gpt,中间的词只能和前面的词做attention而不能和后面的词做attention,所以没法做到上下文综合理解。
在NSP任务中,模型接收两个句子作为输入,要判断这两个句子是否是原文中的连续句子。
在预训练完成后,BERT模型可以用于各种下游任务的微调,如文本分类、命名实体识别、问答等。在微调阶段,模型会在特定任务的标注数据上进行进一步的训练,以适应具体任务的要求。只需要添加一个额外的输出层进行fine-tune,就可以在各种各样的下游任务中取得state-of-the-art的表现。在这过程中并不需要对BERT进行任务特定的结构修改。
RoBERTa(Robustly Optimized BERT Approach)是由Facebook AI于2019年提出的一种语言模型,它是在BERT模型的基础上进行改进和优化的。RoBERTa的目标是通过更大规模的数据和更长的训练时间来获得更强大的语言表示能力。相比于BERT,RoBERTa采用了一系列的训练技巧和策略,如动态掩码、更长的训练序列、更大的批量大小等,以提升模型的性能。RoBERTa在多项自然语言处理任务上取得了显著的性能提升,并成为了当前领域内的重要基准模型之一。
实践
https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling
安装:
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
pip install -r requirements.txt
python run_clm.py \
--model_name_or_path openai-community/gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir /tmp/test-clm




RobertaForMaskedLM = RobertaModel + RobertaLMHead

RobertaModel = RobertaEmbeddings + RobertaEncoder + RobertaPooler
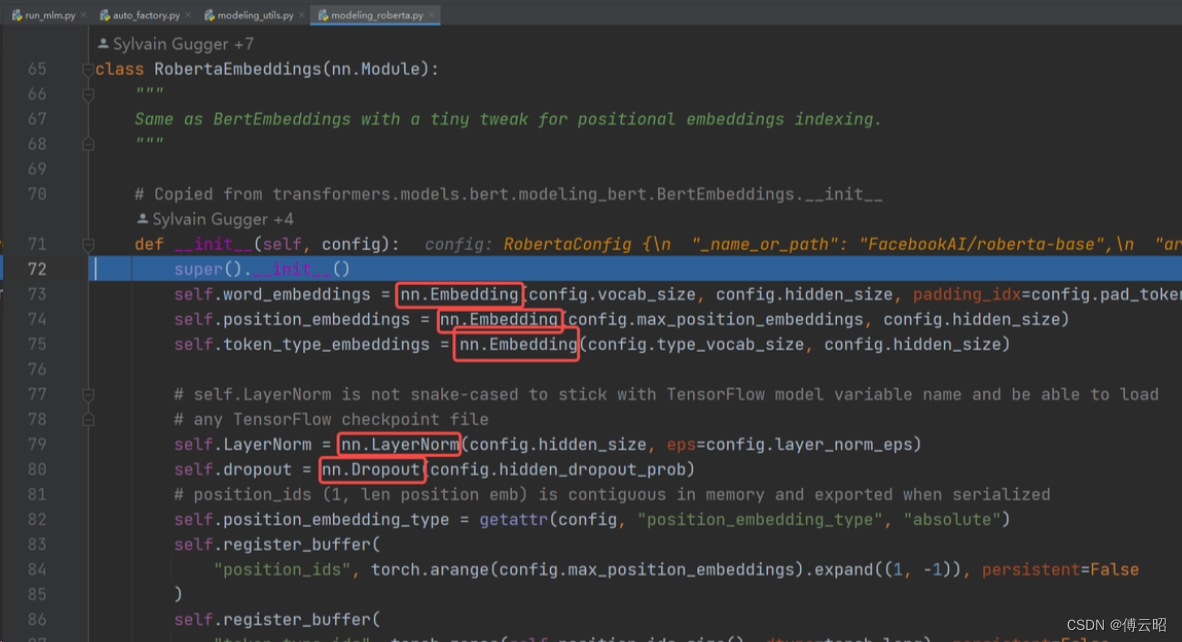
RobertaEmbeddings = nn.Embedding(word,position,token_type) + nn.LayerNorm + nn.Dropout
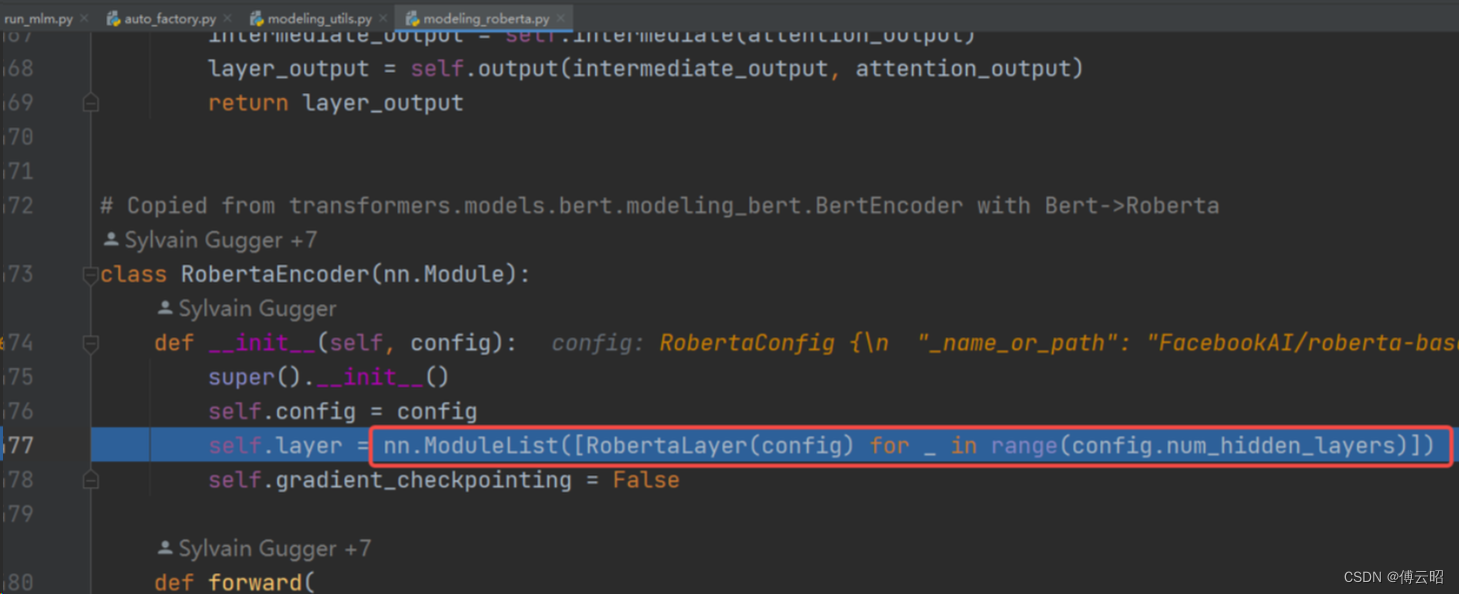
RobertaEncoder = nn.ModuleList([RobertaLayer(config))
RobertaLayer = RobertaAttention + RobertaIntermediate + RobertaOutput

RobertaAttention = RobertaSelfAttention + RobertaSelfOutput
基本上就是x--》q,k,v-->q*k-->mask-->softmax-->*v

RobertaIntermediate = Fc + activate

RobertaOutput = Linear + dropout + layernorm
RobertaPooler = Linear + 激活函数Tanh

RobertaLMHead = Linear + gelu + layernorm +linear
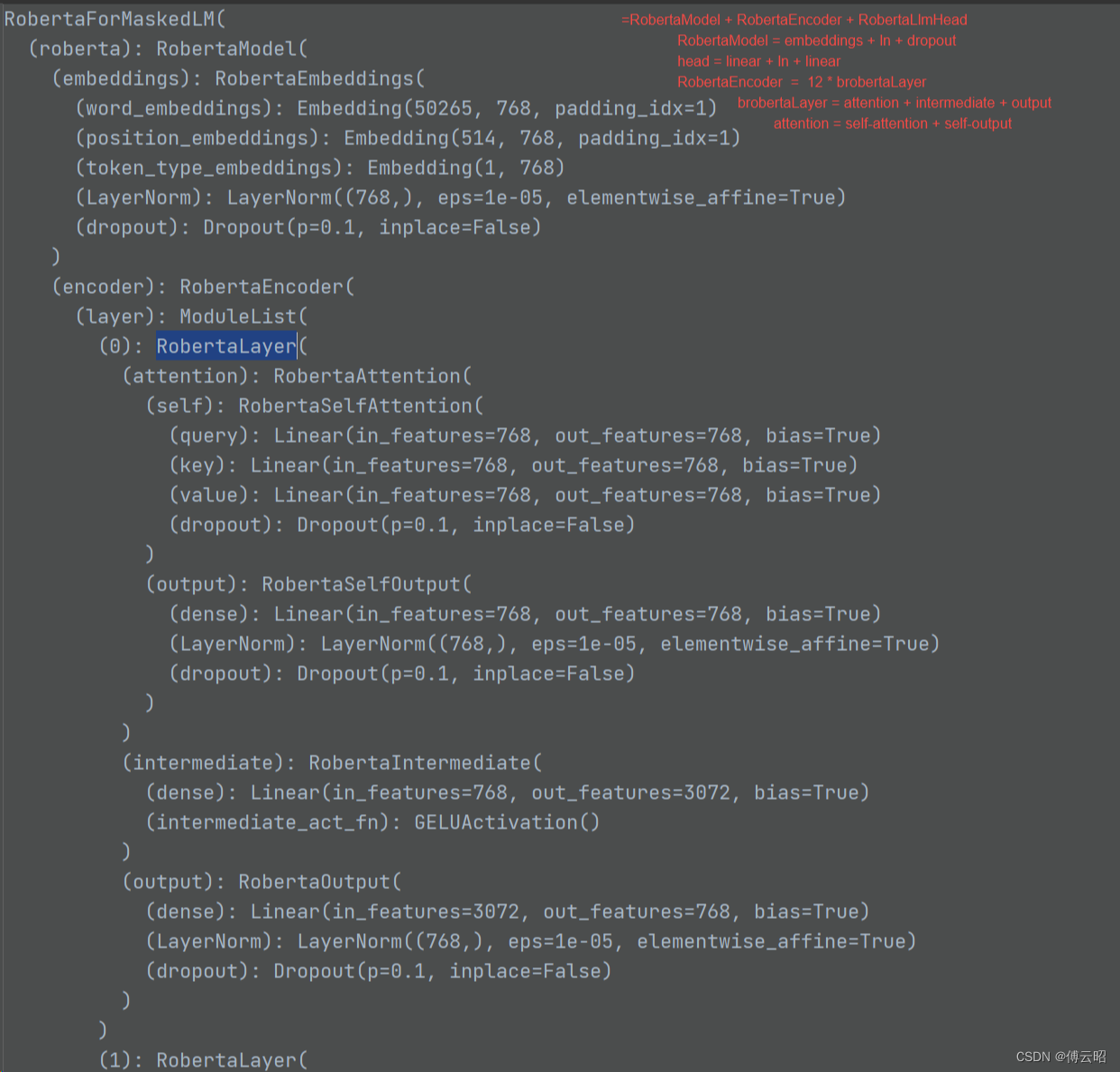
总结:
RobertaForMaskedLM = RobertaModel + RobertaLMHead
RobertaModel = RobertaEmbeddings + RobertaEncoder + RobertaPooler
RobertaEmbeddings = nn.Embedding(word,position,token_type) + nn.LayerNorm + nn.Dropout
RobertaEncoder = nn.ModuleList([RobertaLayer(config))
RobertaLayer = RobertaAttention + RobertaIntermediate + RobertaOutput * 12
RobertaAttention = RobertaSelfAttention + RobertaSelfOutput
RobertaIntermediate = Fc + activate
RobertaOutput = Linear + dropout + layernorm
RobertaPooler = Linear + 激活函数Tanh
RobertaLMHead = Linear + gelu + layernorm +linear



![每日一题 --- 209. 长度最小的子数组[力扣][Go]](https://img-blog.csdnimg.cn/direct/cf7ba345cbee450f860f0ae86cf678cd.png)