41、HashMap 的长度为什么是 2 的 N 次方呢?
- 为了能让 HashMap 存数据和取数据的效率高,尽可能地减少 hash 值的碰撞,也就是说尽量把数据能均匀的分配,每个链表或者红黑树长度尽量相等。
- 我们首先可能会想到 % 取模的操作来实现。
- 下面是回答的重点哟:
取余(%)操作中如果除数是 2 的幂次,则等价于 与其除数减一的与(&)操作(也就是说
hash % length == hash &(length - 1) 的前提是 length 是 2 的 n 次方)。
并且,采用二进制位操作 &,相对于 % 能够提高运算效率。
这就是为什么 HashMap 的长度需要 2 的 N 次方了。
42、HashMap 与 ConcurrentHashMap 的异同
- 都是 key-value 形式的存储数据;
- HashMap 是线程不安全的,ConcurrentHashMap 是 JUC 下的线程安全的;
- HashMap 底层数据结构是数组 + 链表(JDK 1.8 之前)。JDK 1.8 之后是数组 + 链表 + 红黑树。当链表中元素个数达到 8 的时候,链表的查询速度不如红黑树快,链表会转为红黑树,红黑树查询速度快;
- HashMap 初始数组大小为 16(默认),当出现扩容的时候,以 0.75 * 数组大小的方式进行扩容;
- ConcurrentHashMap 在 JDK 1.8 之前是采用分段锁来现实的 Segment + HashEntry,Segment 数组大小默认是 16,2 的 n 次方;JDK 1.8 之后,采用 Node + CAS + Synchronized 来保证并发安全进行实现。
43、红黑树有哪几个特征?
紧接上个问题,面试官很有可能会问红黑树,下面把红黑树的几个特征列出来:

44、说说你平时是怎么处理 Java 异常的
- try-catch-finally
- try 块负责监控可能出现异常的代码
- catch 块负责捕获可能出现的异常,并进行处理
- finally 块负责清理各种资源,不管是否出现异常都会执行
- 其中 try 块是必须的,catch 和 finally 至少存在一个标准异常处理流程
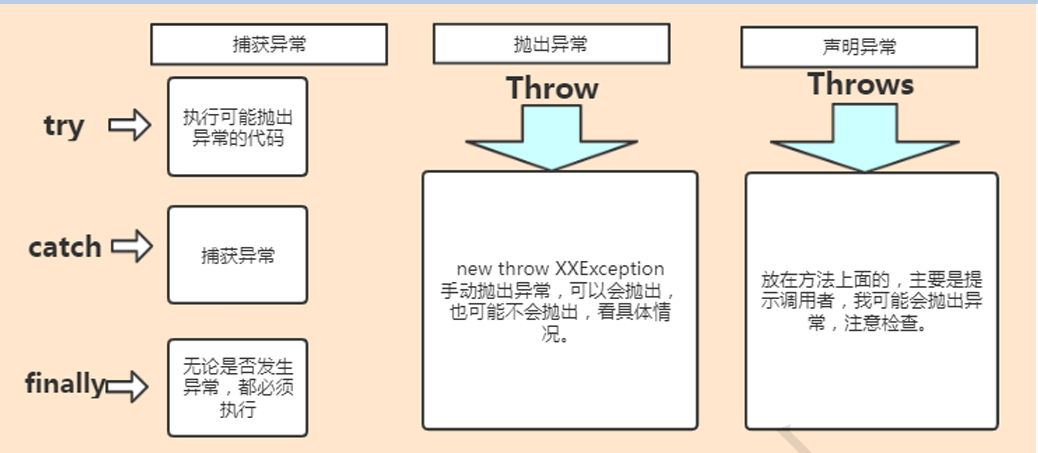
抛出异常→捕获异常→捕获成功(当 catch 的异常类型与抛出的异常类型匹配时,捕获成功) →异常被处理,程序继续运行 抛出异常→捕获异常→捕获失败(当 catch 的异常类型与抛出异 常类型不匹配时,捕获失败)→异常未被处理,程序中断运行
- 在开发过程中会使用到自定义异常,在通常情况下,程序很少会自己抛出异常,因为异常的类名通常也包含了该异常的有用信息,所以在选择抛出异常的时候,应该选择合适的异常类,从而可以明确地描述该异常情况,所以这时候往往都是自定义异常。
- 自定义异常通常是通过继承 java.lang.Exception 类,如果想自定义 Runtime 异常的话,可以继承
java.lang.RuntimeException 类,实现一个无参构造和一个带字符串参数的有参构造方法。 - 在业务代码里,可以针对性的使用自定义异常。比如说:该用户不具备某某权限、余额不足等。
45、说一下 HashMap 的实现原理?
HashMap 基于 Hash 算法实现的,我们通过 put(key,value)存储,get(key)来获取。当传入 key 时,HashMap 会根据 key. hashCode() 计算出 hash 值,根据 hash 值将 value 保存在 bucket 里。当计算出的 hash 值相同时,我们称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value。当 hash 冲突的个数比较少时,使用链表否则使用红黑树。
46、说一下 HashSet 的实现原理?
HashSet 是基于 HashMap 实现的,HashSet 底层使用 HashMap来保存所有元素,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,HashSet 不允许重复的值。
47、String、StringBuffer 和 StringBuilder 的区别是什么?
- String是只读字符串,它并不是基本数据类型,而是一个对象。从底层源码来看是一个final类型的字符数组,所引用的字符串不能被改变,一经定义,无法再增删改。每次对String的操作都会生成新的String对象。
private final char value[];
-
String 的 每次+操作 : 隐式在堆上new了一个跟原字符串相同的StringBuilder对象,再调用append方法 拼接+后面的字符。
-
StringBuffer和StringBuilder他们两都继承了AbstractStringBuilder抽象类,从
AbstractStringBuilder抽象类中我们可以看到
/**
* The value is used for character storage.
*/
char[] value;
- StringBuffer和StringBuilder它们的底层都是可变的字符数组,所以在进行频繁的字符串操作时,建议使用StringBuffer和StringBuilder来进行操作。
- 另外StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。
- StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
48、 String str="i"与 String str=new String(“i”)一样吗?
不一样,因为内存的分配方式不一样。String str="i"的方式,Java 虚拟机会将其分配到常量池中;而 String str=new String(“i”) 则会被分到堆内存中。
49、Java中是值传递还是引用传递?
- 在Java中,参数传递是按值传递(Pass-by-Value)进行的。
- 无论是基本数据类型还是对象类型,实际参数的值都会被复制一份传递给方法中的形式参数。对于基本数据类型,传递的是值本身;对于对象类型,传递的是对象的引用(地址)。
- 当将一个基本数据类型作为参数传递给方法时,方法中对形式参数的修改不会影响到原始值,因为基本数据类型的值存储在栈内存中,每次传递都是将值复制一份。
- 当将一个对象作为参数传递给方法时,方法中对形式参数的修改会影响到原始对象,因为传递的是对象的引用(地址),指向的是同一个对象。
- 虽然在对象类型中传递的是对象的引用,看起来类似引用传递,但实际上仍然是值传递。这是因为对于对象的引用,传递的是引用的副本,而不是引用本身。对形式参数的修改只会影响到引用副本所指向的对象,但不会改变原始引用的指向。
- 总结:Java中的参数传递是值传递的,无论是基本数据类型还是对象类型。这种值传递的方式使得方法中对参数的修改不会影响到原始值(对于基本数据类型)或原始对象的引用(对于对象类型)。
50、简述一下面向对象的六大原则?
-
单一职责原则(Single Responsibility Principle,SRP):一个类应该只有一个引起它变化的原因。换句话说,一个类应该只有一个职责,这样可以使类更加聚焦,降低耦合性,并提高代码的可维护性
-
开放封闭原则(Open-Closed Principle,OCP):软件实体(类、模块、函数等)应该对扩展开放,对修改关闭。意思是当需求发生变化时,应该通过扩展现有代码来适应新的需求,而不是修改已有的代码。这样可以保持代码的稳定性和可维护性
-
里氏替换原则(Liskov Substitution Principle,LSP):子类对象可以替换父类对象,而程序的行为不受影响。子类应该能够完全替代父类,并且在任何使用父类的地方都不会引起错误或异常
-
接口隔离原则(Interface Segregation Principle,ISP):应该为客户端提供尽可能小、精确的接口,而不应该提供大而全的接口。避免客户端依赖它们不需要的接口,这样可以降低耦合性,并提高系统的灵活性和可维护性
-
依赖倒置原则(Dependency Inversion Principle,DIP):高层模块不应该依赖于低层模块,它们都应该依赖于抽象。抽象不应该依赖于具体实现,而具体实现应该依赖于抽象。这样可以降低模块之间的直接依赖关系,提高代码的可扩展性和可维护性
-
迪米特法则(Law of Demeter,LoD):一个对象应该尽量少地与其他对象发生相互作用。一个对象应该只与其直接的朋友进行通信,而不应该暴露太多的内部细节给外部。这样可以降低对象之间的耦合性,提高系统的可维护性和灵活性