文章目录
- 协程
- 进程和线程
- 进程:
- 进程间通信:
- 线程:
- 区别:
- 协程
- GMP模型
- 调度策略
- 内存管理
- 内存分配
- span:
- cache:
- central:
- heap:
- 垃圾回收
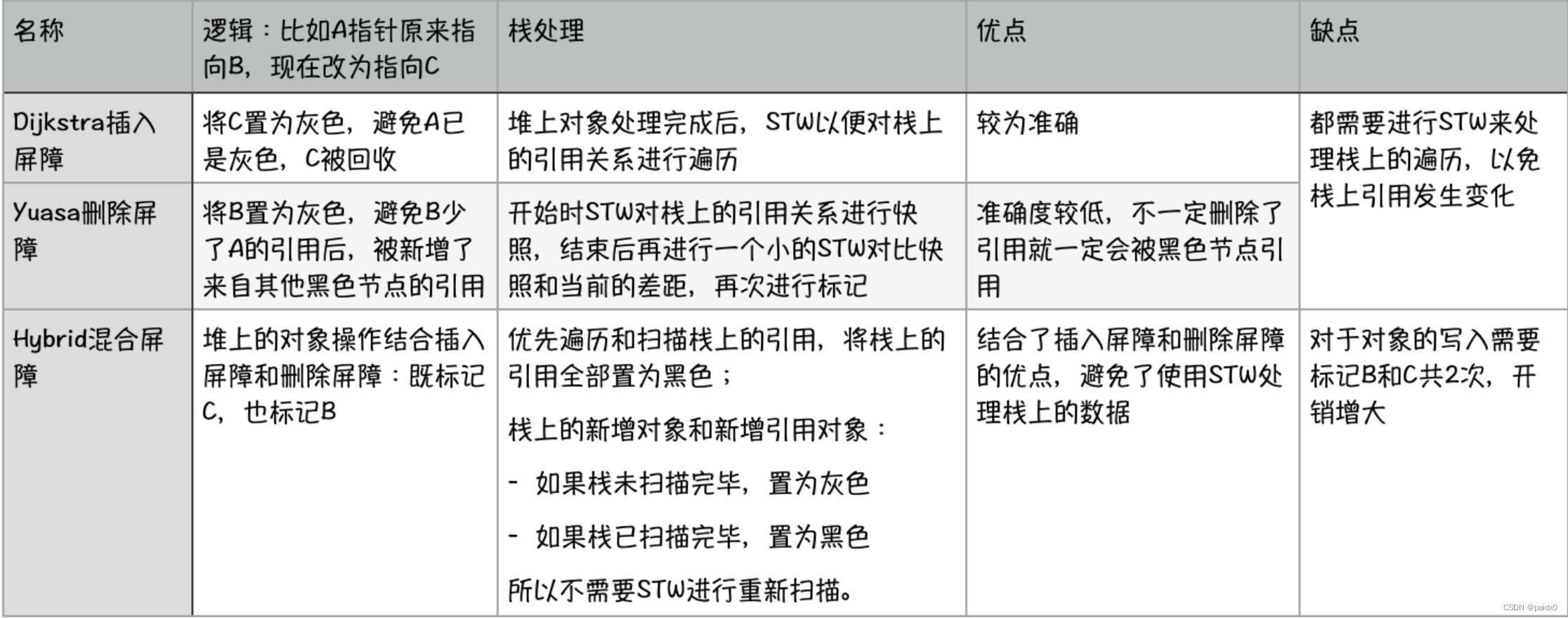
- 常见的垃圾回收算法:
- 三色标记:
- 垃圾回收优化:
- GC流程:
- 逃逸分析:由编译器决定内存分配的位置
- 编译器根据对象是否被函数外部引用来决定是否逃逸:
- 并发控制
- 控制方式
- Channel:
- WaitGroup:
- Add:
- Wait:
- Done:
- context:
- emptyCtx:
- cancelCtx:
- timerCtx:
- valueCtx:
- 锁机制
- Normal模式
- Starving模式
- Woken模式
- 自旋
- 自旋条件:自旋并不是无限制的,只有在不忙的时候才会自旋
- 读写锁
- 写操作如何阻止读操作:
- 读操作如何阻止写操作:
- 写锁定不会饿死吗:
- 反射
- 异常处理
- errors包
- defer
- panic
- recover
- 定时器
- Timer
- Ticker
- timersBucket
- 测试
- 单元测试
- 性能测试
- 示例测试
- 子并发测试
- Main测试
- common
- TB、T、B
首先书很好看,值得去读,其中的原理通俗易懂,配合着源码详略都有,对以前一些较模糊难懂的概念也有了自己的认识和理解
协程
进程和线程
进程:
- 拥有资源分配的基本单位
- 进程是一个独立的单位,有独立的内存空间
进程间通信:
- 管道:父子进程间通信
- 信号:中断机制的一种模拟
- 消息队列:消息链接表,具有写权限进程可以按照一定规则向消息队列中添加新信息;具有读权限进程则可以从消息队列中读取信息
- 共享内存:多个进程可以访问同一块内存空间,可以看到对方共享内存中数据的更新,依靠同步
- 信号量:进程间或同进程间不同线程间的同步和互斥手段
- 套接字:用于网络中不同机器间进程通信
线程:
- 调度和分配的基本单位
- 共享进程资源内存等方式线程间通信
- 线程可以创建和取消另一个线程,进程间线程并发执行
- 易调度,开销少,可并发,创建线程比创建进程开销少,充分利用多处理器的功能
区别:
- 一个 线程只能属于一个进程,而一个进程可以有多个线程,至少一个线程
- 资源分配给进程,同一进程的线程共享资源
- 真正执行处理的是线程,进程内的一个执行单位,可调度实体
- 线程不拥有系统资源,但可以访问隶属于进程的资源
- 分配和回收资源时,进程开销明显大于线程
协程
协程是一种更轻量级的线程,不受操作系统直接调度,而是由用户应用程序提供的协程调度器按照调度策略调度到线程执行
Go协程调度器由runtime包提供,go关键字创建协程,语言层面直接支持协程
高并发应用中频繁创建线程难免造成不必要的开销,所以可以线程池保存一定的线程,新的任务不再是以创建线程执行,而是加入到任务队列。线程池中的线程不断地从任务队列中取出执行,就避免了频繁地创建和销毁线程。
线程池的线程毕竟有限,如果一个线程阻塞一个任务,任务队列中任务就会堆积,可以通过创建线程来缓解这个问题,但是线程过多会造成竞争CPU资源
过多的线程上下文切换开销大,用户态的协程可以减少切换开销,协程调度器可以把可调度的协程给线程执行,同时把阻塞的协程调度出协程,避免线程的频繁切换实现高并发
GMP模型
Go实现的是M:N模型,也就是M个用户线程运行在N个内核线程中,协程上下文切换快,调度算法复杂
- goroutine(G):go关键字创建协程
- machine(M):内核线程,必须有P才能执行,M个数稍大于P
- processor§:协程调度器,默认是CPU核数
M阻塞执行G,其他G等待被调用,全局G队列多个处理器共享
协程G创建的子协程会被加入到本地队列,队列满了则加入到全局,同样的,调度器P除了调度本地队列,也会周期的去调用全局G
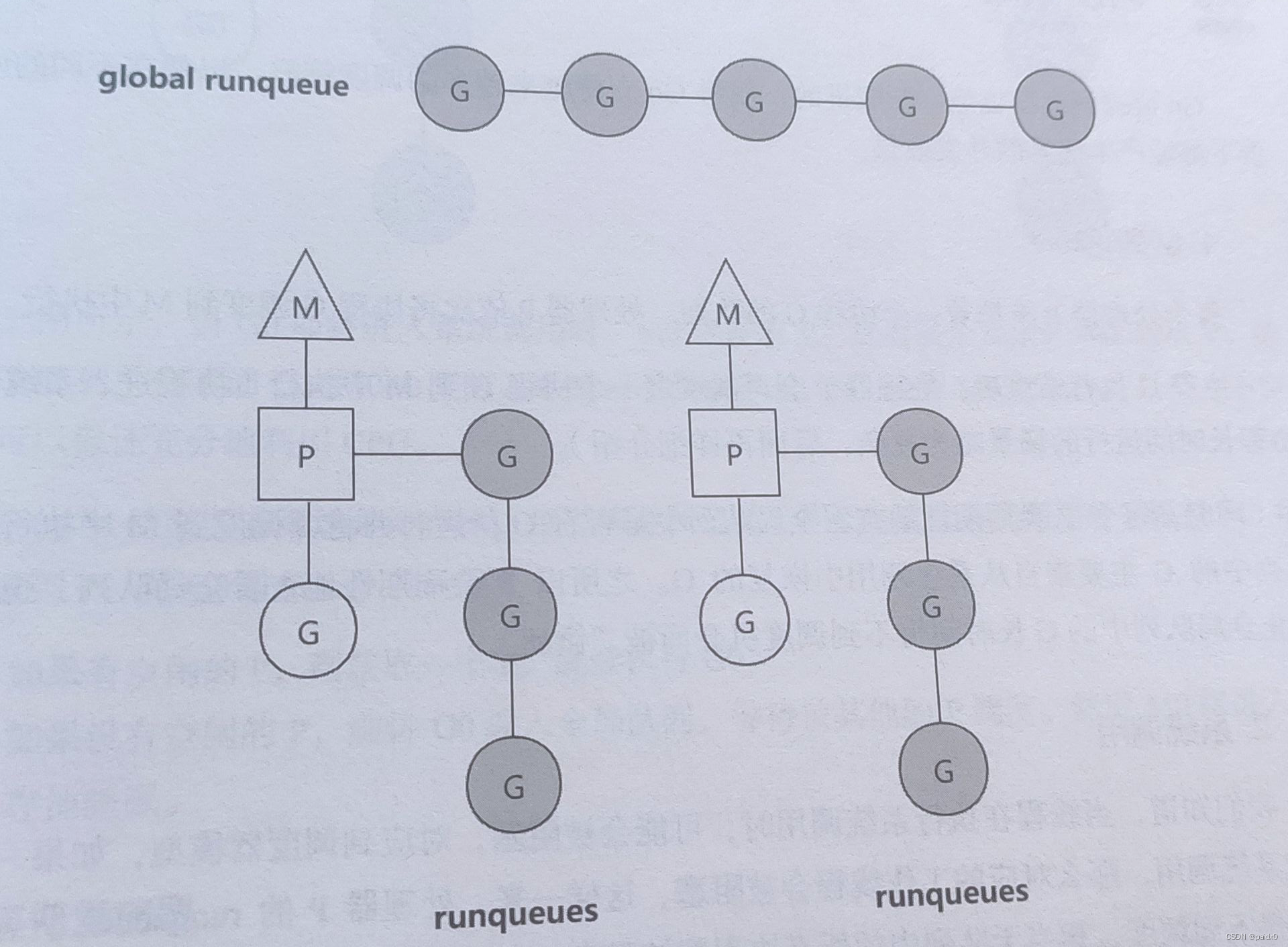
调度策略
- 轮转队列:P从本地G队列中取出到M执行,也会周期的从全局队列中调度G,避免饿死
- 系统调用:前面说了M稍多余P,M和P又需要绑定才能执行,那多余的M就是在系统调用时起作用。比如,M0释放掉P,多余的M1代替M0继续和P工作,从队列中获取协程,M0陷入系统调用继续执行G。G执行完毕如果有空闲的P则M0获取,如果没有M0就休眠
- 工作量窃取:P维护的协程数量是不均衡的,当某个P没有协程时会先检查全局G,没有再从其他P窃取协程过来,每次偷一半
- 抢占式调度:类似时间片轮转,避免某个协程长时间执行
内存管理
内存分配
申请的内存会被划分成三个部分
- arena:即堆区,应用需要的内存也是从这里分配出去的,这个区域会划分成 page页,每个页8KB
- spans:存放span指针的区域,每个指针又对应一个或多个page
- bitmap:和GC标志有关
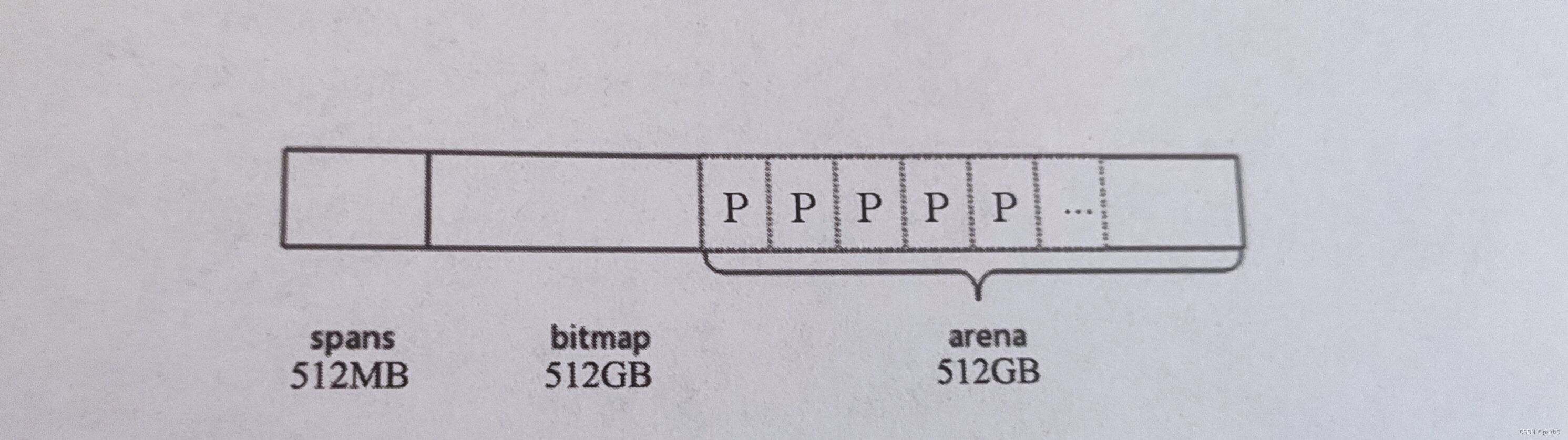
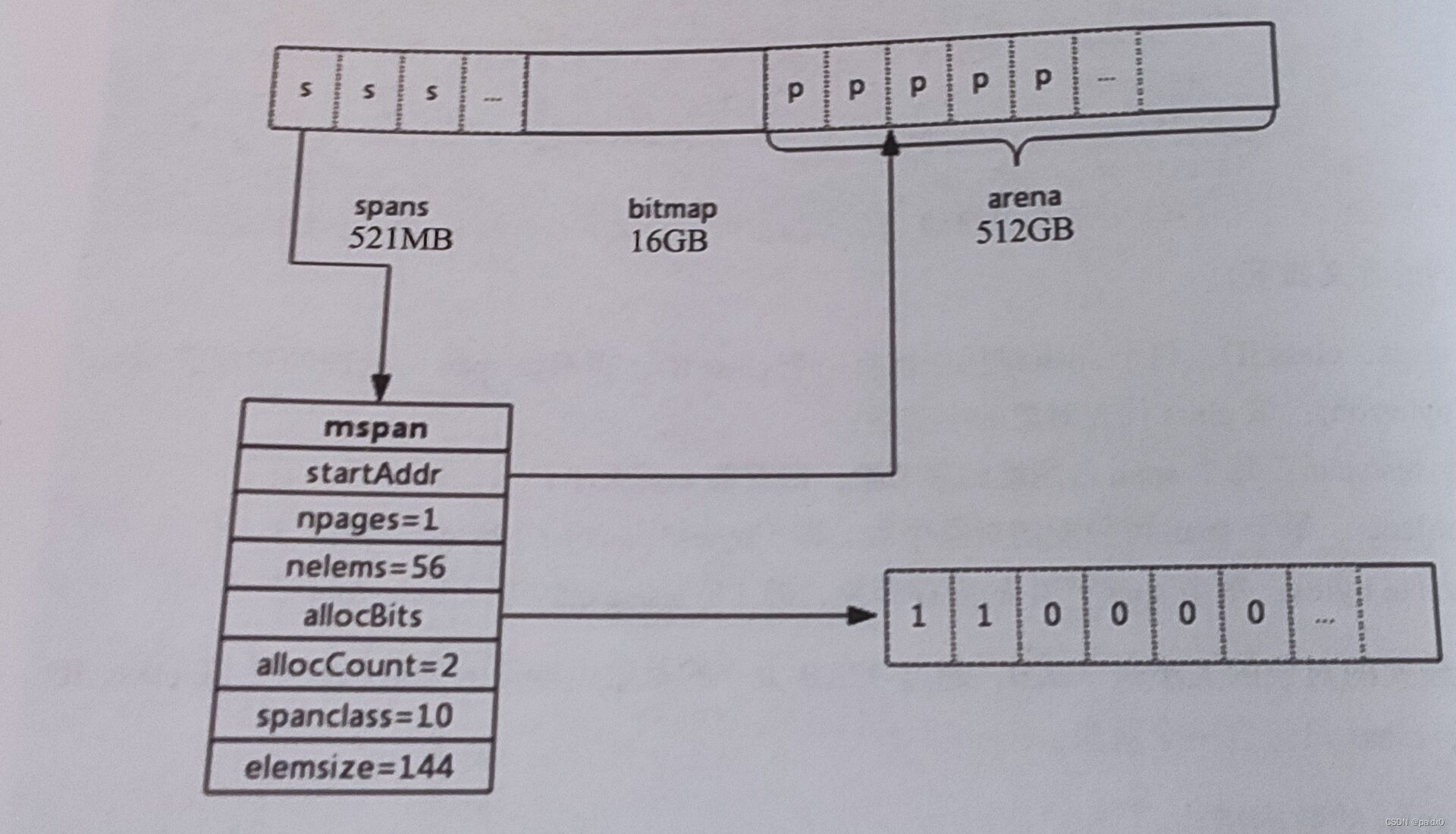
span:
用来管理arena中page页的,包含一个或多个连续页,页又会根据需要划分出更小的粒度class,每个span管理特定的大小的class对象
type mspan struct { next *mspan // 链表前向指针 prev *mspan // 链表后向指针 list *mSpanList // For debugging. TODO: Remove. startAddr uintptr // 管理的页开始地址 npages uintptr // 页数 manualFreeList gclinkptr // list of free objects in mSpanManual spans nelems uintptr // 块个数 allocBits *gcBits // 每一位代表一个块是否被分配 gcmarkBits *gcBits // 每块的gc标记情况 allocCache uint64 sweepgen uint32 allocCount uint16 // 已被分配的块数 spanclass spanClass // size class and noscan (uint8) state mSpanStateBox // needzero uint8 // needs to be zeroed before allocation allocCountBeforeCache uint16 // elemsize uintptr // 块大小 limit uintptr // speciallock mutex // guards specials list specials *special // }
cache:
为了避免多线程申请内存时频繁加锁,为每个线程分配了span的缓存
数组中每个元素代表一种class类型的span列表,列表又有两种,一种包含了指针,一种不包含指针,目的是为了方便GC扫描,没指针对象的就没必要去扫描他
type mcache struct { alloc [numSpanClasses]*mspan // spans to allocate from, indexed by spanClass stackcache [_NumStackOrders]stackfreelist }
central:
用来管理span,这么说吧,cache是为了单个线程提供服务缓存,central则是为了多线程服务
当某个线程内存不足时向central申请,当线程释放又回收到central,cache初始时是没有span的,过程中动态的从central获取并缓存下来
申请span过程:加锁、从空闲表中取span并从链表中删除加入到非空闲链表中,span返回给线程,解锁、线程将span缓存到cache释放span过程:加锁、从非空闲链表删除加到空闲链表,解锁type mcentral struct { spanclass spanClass partial [2]spanSet // 还有空闲块的span列表 full [2]spanSet // 没有空闲块的span列表 }
heap:
知道了central管理的某一种大小的class类型的span,这些central又存放在 heap中,Go也就是通过一个heap管理内存
type mheap struct { lock mutex allspans []*mspan // all spans out there curArena struct { // 当前arena区域的起始和已使用的地址 base, end uintptr } central [numSpanClasses]struct { // 每种类型class对应的central mcentral mcentral pad [cpu.CacheLinePadSize -unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte } }
垃圾回收
常见的垃圾回收算法:
- 引用计数:每个对象维护一个计数,引用该对象的对象被销毁则减1,直到0就回收对象
- 比如:Python、PHP
- 好处就是能够很快的发现并回收,不会等到内存耗尽才回收,缺点是不能很好处理循环引用,实时维护计数也要代价
- 分代收集:按照对象生命周期长短划分不同的代空间,也就是老年代、新生代,不同代有不同的回收算法和频率
- 比如:Java
- 好处就是回收性能好,但是算法复杂
- 标记清除:从根变量开始遍历引用的对象,引用的标记为“被引用”,没有的就会被回收
- 比如:Go三色标记
- 好处是避免了引用计数的循环引用问题,但是需要STW(停止所有协程,专心做垃圾回收)
三色标记:
- 白色:对象未标记(gcmarkBits 对应位 0)
- 灰色:对象在标记队列中等待
- 黑色:对象被标记(gcmarkBits 对应位 1)
垃圾回收优化:
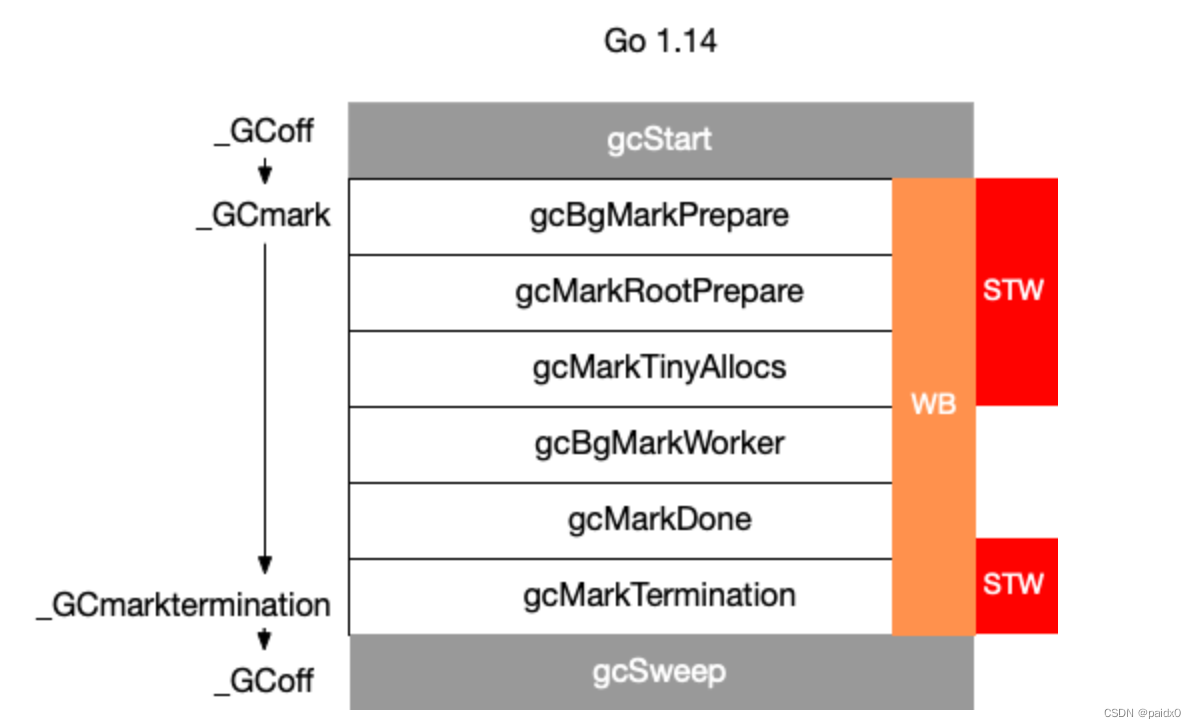
因为STW的存在,STW 的时间长短直接影响了应用的执行,为了缩短STW时间,需要优化垃圾回收
写屏障:允许goroutine与GC同时运行减弱STW,GC过程中新分配的内存会被立即标记,不会在本轮回收
灰色Dijistra插入写屏障(白色先标记为灰色,避免被黑色引用,所有的白色均被灰色引用,重扫就不会有遗漏)
黑色Yuasa删除写屏障(标记为灰色,创造灰色到灰色或灰色到白色的路径)
混合Hybrid写屏障(Go1.8以后简化GC流程,减少标记重扫的成本,对正在被覆盖的对象着色,且如果当前栈未扫描完成,则同样对指针着色)
强三色不变性:黑色不允许引用白色
弱三色不变性:黑色可以引用白色,但白色有其他灰色间接引用
GC流程:

逃逸分析:由编译器决定内存分配的位置
- 如果分配在栈中,函数执行结束自动内存回收
- 如果分配在堆中,函数执行结束可交给GC处理
编译器根据对象是否被函数外部引用来决定是否逃逸:
- 没被引用,优先放入栈中
- 被引用,一定是放到堆中
还有当内存过大超过栈存储能力时,也会放到堆中
- 动态类型逃逸
func main(){ s := "test" fmt.Println(s) // Println(a...interface{}),编译期间很难确定参数具体类型,也会产生逃逸 }
- 闭包引用
func fibonaci() func() int { a,b := 0,0 return func() int { a,b = b,a+b return a } // 闭包引用了局部变量a、b,所以被放入到堆中 }所以有时候函数指针传递不一定就比值传递好,虽然可以提高效率但是会发生逃逸,加剧了GC的负担
并发控制
控制方式
实际中经常遇到这种场景,协程A创造出多个子协程,然后就需要等待协程退出,Go也有三种方式解决这个问题
- channel 实现简单
- waitgroup 协程个数可以动态调整
- context 可以很好的操作派生出来的子孙协程
Channel:
有优点有缺点,优点就是实现简单,缺点是当需要大量创建协程时需要同样数量的Channel,而且对子孙协程不好控制
func main() { channels := make([]chan int, 10) for i := 0; i < 10; i++ { channels[i] = make(chan int) go process(channels[i]) } for i, ch := range channels { <-ch fmt.Println("子协程", i, "退出") } } func process(ch chan int) { time.Sleep(time.Second) ch <- 1 }
WaitGroup:
通过信号量的方式控制子协程,信号量 >0 资源可用,获取后自动减1,信号量 = 0 资源不可用,线程睡眠
缺点是子协程派生新的协程时,goroutine数量不太好确定,但WaitGroup Add方法需要提前预知
type WaitGroup struct { noCopy noCopy // 锁 state1 uint64 // 两个计数器,counter当前还未执行结束的goroutine计数器,waiter等待goroutine结束的goroutine数量 state2 uint32 // 信号量 }提供了三个接口函数 Add、Wait、Done
Add:
func (wg *WaitGroup) Add(delta int) { statep, semap := wg.state() // 获取到 state1 和 state2 指针 if race.Enabled { _ = *statep // trigger nil deref early if delta < 0 { race.ReleaseMerge(unsafe.Pointer(wg)) } race.Disable() defer race.Enable() } state := atomic.AddUint64(statep, uint64(delta)<<32) // 左移32位加到 counter上 v := int32(state >> 32) // counter w := uint32(state) // waiter if race.Enabled && delta > 0 && v == int32(delta) { race.Read(unsafe.Pointer(semap)) } if v < 0 { // counter 是可正可负的,Done就是加了个 -1 panic("sync: negative WaitGroup counter") } // Wait 先于 Add 被调用就会 panic,Add设置的值必须和实际等待的 goroutine个数相同 if w != 0 && delta > 0 && v == int32(delta) { panic("sync: WaitGroup misuse: Add called concurrently with Wait") } // counter > 0 说明不需要释放信号量,waiter = 0 说明没有等待者,也不用释放信号量 if v > 0 || w == 0 { return } if *statep != state { panic("sync: WaitGroup misuse: Add called concurrently with Wait") } // Reset waiters count to 0. *statep = 0 for ; w != 0; w-- { runtime_Semrelease(semap, false, 0) // 释放信号量,唤醒等待者 } }Wait:
func (wg *WaitGroup) Wait() { statep, semap := wg.state() if race.Enabled { _ = *statep // trigger nil deref early race.Disable() } for { state := atomic.LoadUint64(statep) v := int32(state >> 32) // counter w := uint32(state) // waiter if v == 0 { // counter = 0 说明所有的 goroutine都退出了,不用等待了 if race.Enabled { race.Enable() race.Acquire(unsafe.Pointer(wg)) } return } // 累加 waiter if atomic.CompareAndSwapUint64(statep, state, state+1) { if race.Enabled && w == 0 { race.Write(unsafe.Pointer(semap)) } runtime_Semacquire(semap) // 等待信号量唤醒 if *statep != 0 { panic("sync: WaitGroup is reused before previous Wait has returned") } return } } }Done:
func (wg *WaitGroup) Done() { wg.Add(-1) }
context:
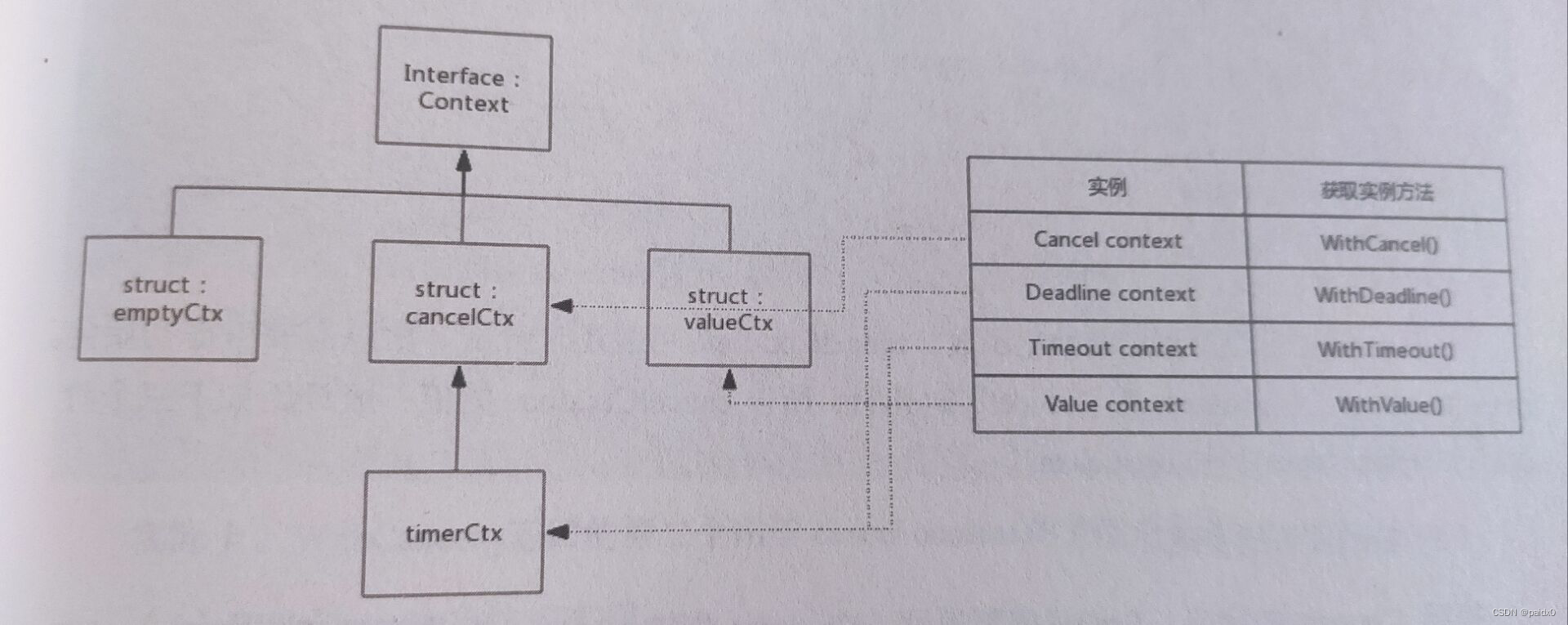
对派生的子孙节点有很好的控制能力,呈现的是一种goroutine树状结构,每个goroutine 拥有相同的 ctx
type Context interface { Deadline() (deadline time.Time, ok bool) Done() <-chan struct{} Err() error Value(key any) any }实现Context接口的有四个
- emptyCtx 这个就是我们熟知的 ctx.background
- cancelCtx 可以cancel掉ctx派生的子cancel
- timerCtx 在cancelCtx 基础上加了计时器,超时自动cancel
- valueCtx 可以用于子协程读取到父协程key-value
可以互为父节点,根据特点可以组合多种形式
emptyCtx:
其他类型的Ctx 方法如果没有父Context,需要传入background作为父节点
type emptyCtx int func (*emptyCtx) Deadline() (deadline time.Time, ok bool) { return } func (*emptyCtx) Done() <-chan struct{} { return nil } func (*emptyCtx) Err() error { return nil } func (*emptyCtx) Value(key any) any { return nil } func (e *emptyCtx) String() string { switch e { case background: return "context.Background" case todo: return "context.TODO" } return "unknown empty Context" }
cancelCtx:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) { if parent == nil { panic("cannot create context from nil parent") } c := newCancelCtx(parent) propagateCancel(parent, &c) // 自身节点加到父节点上 return &c, func() { c.cancel(true, Canceled) } } type cancelCtx struct { Context mu sync.Mutex done atomic.Value children map[canceler]struct{} // 派生子协程 err error } func (c *cancelCtx) cancel(removeFromParent bool, err error) { if err == nil { panic("context: internal error: missing cancel error") } c.mu.Lock() if c.err != nil { c.mu.Unlock() return // already canceled } c.err = err d, _ := c.done.Load().(chan struct{}) if d == nil { c.done.Store(closedchan) } else { // 关闭 chancel 并通知派生 Context close(d) } // 遍历 子Context 调用cancel for child := range c.children { child.cancel(false, err) } c.children = nil c.mu.Unlock() // 再将自己从父节点下移除 if removeFromParent { removeChild(c.Context, c) } }
timerCtx:
type timerCtx struct { cancelCtx timer *time.Timer deadline time.Time } // 超时时间 func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) { return WithDeadline(parent, time.Now().Add(timeout)) } // 截止时间 func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) { if parent == nil { panic("cannot create context from nil parent") } if cur, ok := parent.Deadline(); ok && cur.Before(d) { return WithCancel(parent) } c := &timerCtx{ cancelCtx: newCancelCtx(parent), deadline: d, } propagateCancel(parent, c) dur := time.Until(d) if dur <= 0 { c.cancel(true, DeadlineExceeded) return c, func() { c.cancel(false, Canceled) } } c.mu.Lock() defer c.mu.Unlock() if c.err == nil { c.timer = time.AfterFunc(dur, func() { c.cancel(true, DeadlineExceeded) }) } return c, func() { c.cancel(true, Canceled) } }
valueCtx:
type valueCtx struct { Context key, val any } func (c *valueCtx) Value(key any) any { if c.key == key { return c.val } // 当前节点找不到就会去父节点找,没有找到最终返回 interface{} return value(c.Context, key) } func value(c Context, key any) any { for { switch ctx := c.(type) { case *valueCtx: if key == ctx.key { return ctx.val } c = ctx.Context case *cancelCtx: if key == &cancelCtxKey { return c } c = ctx.Context case *timerCtx: if key == &cancelCtxKey { return &ctx.cancelCtx } c = ctx.Context case *emptyCtx: return nil default: return c.Value(key) } } }
锁机制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-03WImqHf-1673361883713)(go%E4%B8%93%E5%AE%B6%E7%BC%96%E7%A8%8B.assets/76599410260b73898db7637b68d2e07c.jpg)]](https://img-blog.csdnimg.cn/165387a11a084b2595ba4546ae84e3d6.png)
type Mutex struct {
state int32 // 锁状态
sema uint32 // 信号量
}
// 四种状态
const (
mutexLocked = 1 << iota // 是否已被锁
mutexWoken // 是否有协程已被唤醒
mutexStarving // 是否处于饥饿状态
mutexWaiterShift = iota // 阻塞等待锁的协程个数
}
Normal模式
默认下,如果加锁不成功不会立即进入阻塞状态,而是先判断是否满足自旋条件,满足自旋条件就尝试抢锁
Starving模式
自旋能抢到锁,那么一定有协程释放了锁,有阻塞的协程被唤醒,但是唤醒后发现锁已被抢走只能继续阻塞,这次阻塞会与上次阻塞时间比较,超过1Ms则标记为饥饿,饥饿状态下不会自旋,下一次一定获得锁
Woken模式
同一时刻两个协程一个加锁一个解锁,加锁的在自旋检查,woken标记为1,通知解锁的协程不需要释放信号量,加锁的协程马上就拿到了
自旋
自旋很好理解,类似CPU空转sleep,时间很短,过程会持续检查Locked标记是否为0
自旋条件:自旋并不是无限制的,只有在不忙的时候才会自旋
- 自旋次数足够少,最多4次
- CPU多核
- 协程调度中P的数量大于1
- 协程可调度队列必须为空,否则延迟协程调度
自旋更充分利用CPU,尽量避免协程切换,短时间自旋可以获得锁就不需要进入阻塞
读写锁
type RWMutex struct { w Mutex writerSem uint32 // 写阻塞信号量 readerSem uint32 // 读阻塞信号量 readerCount int32 // 读者个数 readerWait int32 // 写阻塞时的读者个数 } const rwmutexMaxReaders = 1 << 30写操作如何阻止读操作:
代码大概是这个意思,readerCount - 2^30 就变成负数对吧,读锁来到时检查 readerCount < 0 就代表已经有了写锁,阻塞等待,要返回加回2^30 就行。
读操作如何阻止写操作:
读锁就简单了,readerCount +1,写锁来到时发现读者数量不等于0,阻塞等待所有读者退出
写锁定不会饿死吗:
写锁到来时要等待所有读者退出对吧,但是这个时候又有新的读者加入,readerCount +1 写锁会不会饿死呢,其实写锁到来时会把readerCount 复制给 readerWait 一份,读者退出他们两个都 -1,直到 readerWait = 0,也就说明写锁前的读者全部退出,readerCount中是写锁后的读者
反射

异常处理
errors包
errors包比较简单,简单提一下
- New 自定义错误
- Unwrap 获取原始的error
- Is 检查error链中是否包含特定的error值
- As 断言检查error是否是指定类型
defer
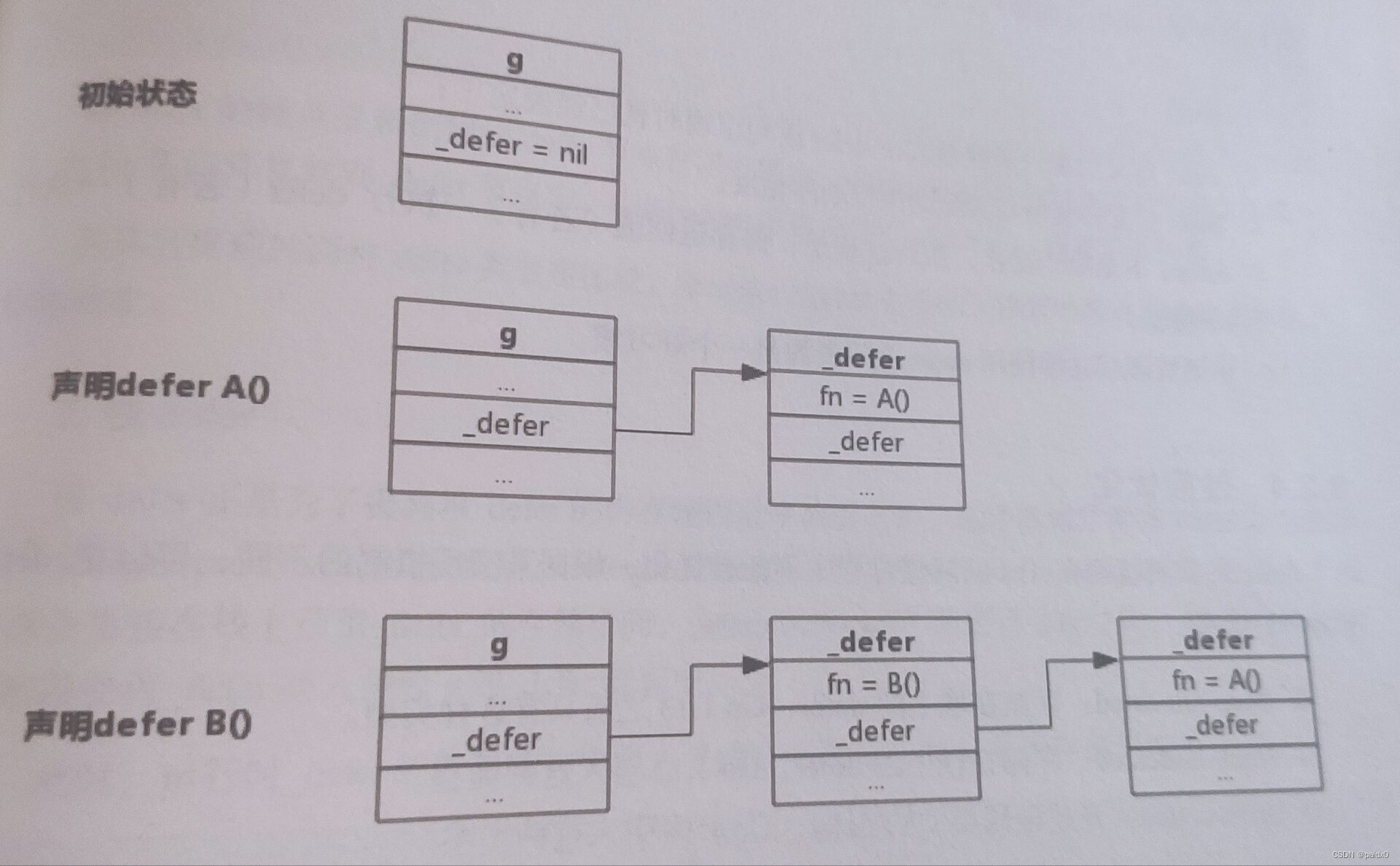
只要记住一个先进后出规则进行了,defer延迟函数会在return返回之前执行,return转成汇编其实就是RET
确定返回值 -> 执行defer -> RET跳转
type _defer struct {
started bool
heap bool
openDefer bool
sp uintptr // 函数栈指针
pc uintptr // 程序计数器
fn func() // 调用函数
_panic *_panic //
link *_defer // defer链
fd unsafe.Pointer
varp uintptr
framepc uintptr
}
type g struct {
stack stack //
stackguard0 uintptr //
stackguard1 uintptr //
_panic *_panic
_defer *_defer
............
}
panic
type _panic struct {
argp unsafe.Pointer
arg any
link *_panic
pc uintptr
sp unsafe.Pointer
recovered bool
aborted bool
goexit bool
}
recover
func gorecover(argp uintptr) any {
gp := getg()
p := gp._panic
// 触发panic时,recover必须被defer直接调用
if p != nil && !p.goexit && !p.recovered && argp == uintptr(p.argp) {
p.recovered = true
return p.arg
}
return nil
}
定时器
Timer
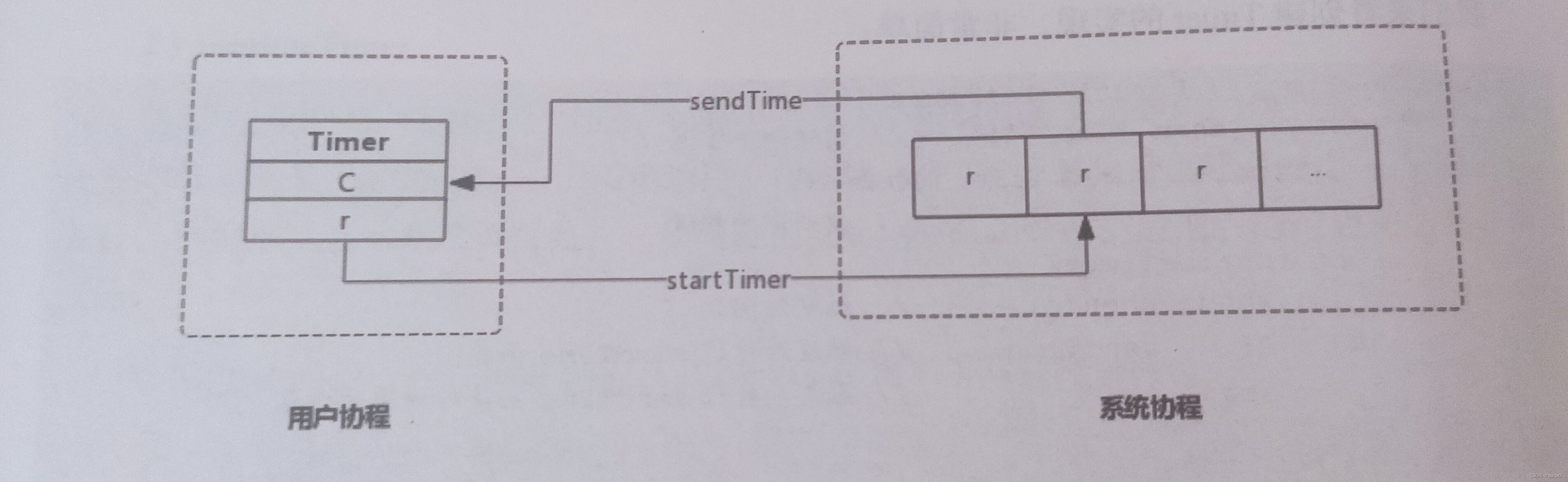
单一事件的定时器,也就是说只执行一次就结束
// 新的Timer交给系统协程监控 func startTimer(*runtimeTimer) // 系统协程删除指定的Timer func stopTimer(*runtimeTimer) bool // 系统协程删除指定Timer再添加一个新的 func resetTimer(*runtimeTimer, int64) bool type Timer struct { C <-chan Time // r runtimeTimer // 定时器 } // 会把一个定时任务交给专门的协程给到系统管理监控 type runtimeTimer struct { pp uintptr // 系统底层中定时器的存储数组地址 when int64 // 触发时间 period int64 // 周期触发间隔 f func(any, uintptr) // 触发时回调函数 arg any // 回调函数的参数一 seq uintptr // 回调函数的参数二 nextwhen int64 status uint32 } func NewTimer(d Duration) *Timer { c := make(chan Time, 1) t := &Timer{ C: c, r: runtimeTimer{ when: when(d), f: sendTime, arg: c, }, } startTimer(&t.r) return t } // 向管道写入当前时间 func sendTime(c any, seq uintptr) { select { case c.(chan Time) <- Now(): default: } } // 自定义执行方法 func AfterFunc(d Duration, f func()) *Timer { t := &Timer{ r: runtimeTimer{ when: when(d), f: goFunc, arg: f, }, } startTimer(&t.r) return t }
Ticker
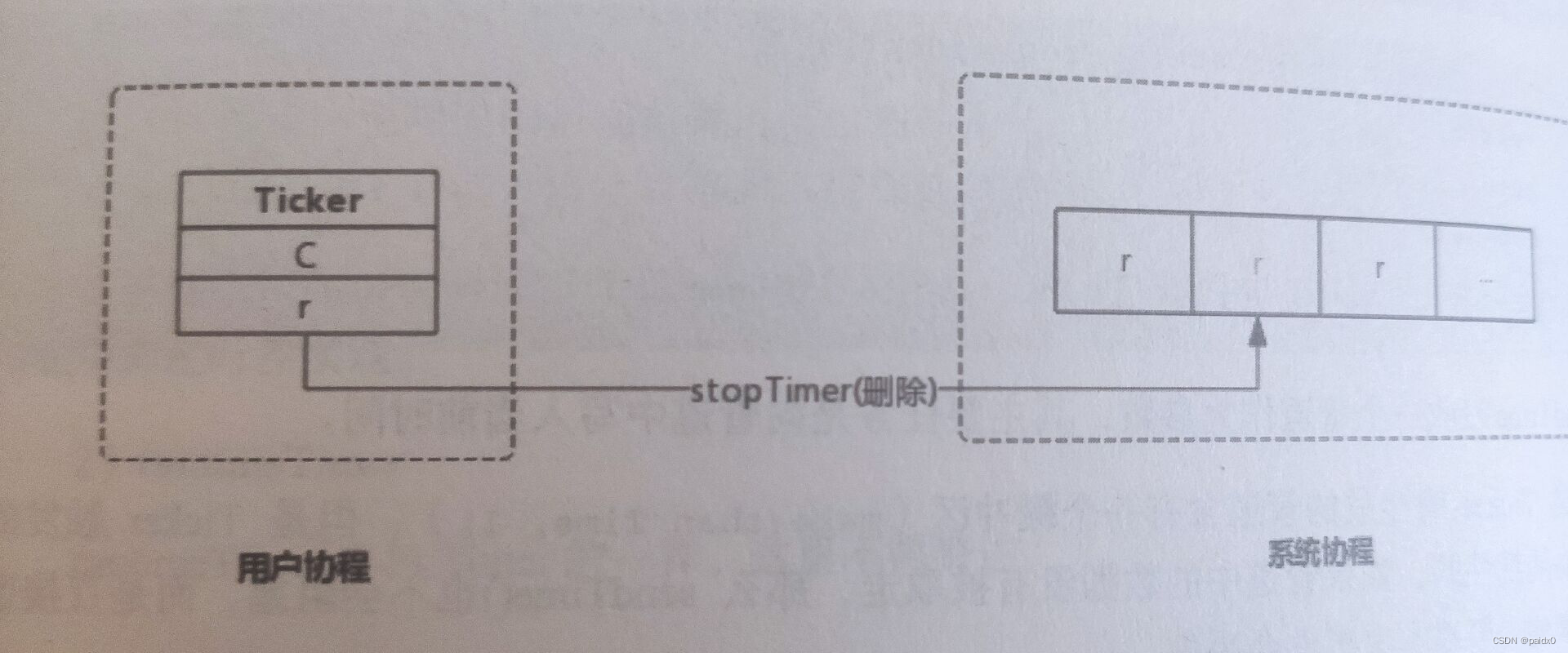
周期计时器,和Timer用法差不多,但有一点就是执行完必须有 Stop(),而Timer可以不用,执行结束会自动退出系统计时器监控,Ticker没有退出会一直占用CPU资源
type Ticker struct { C <-chan Time r runtimeTimer } func NewTicker(d Duration) *Ticker { if d <= 0 { panic(errors.New("non-positive interval for NewTicker")) } c := make(chan Time, 1) t := &Ticker{ C: c, r: runtimeTimer{ when: when(d), period: int64(d), // 执行周期 f: sendTime, arg: c, }, } startTimer(&t.r) return t }
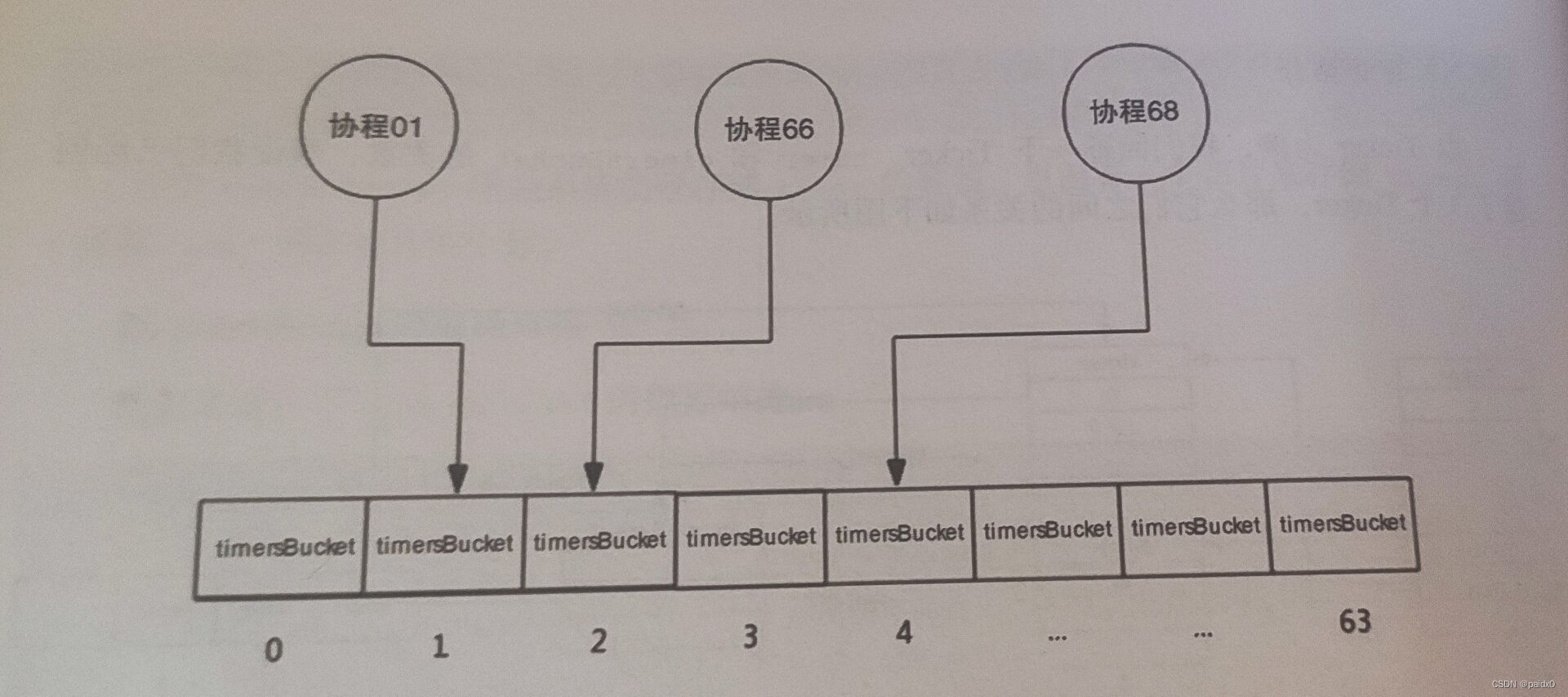
timersBucket
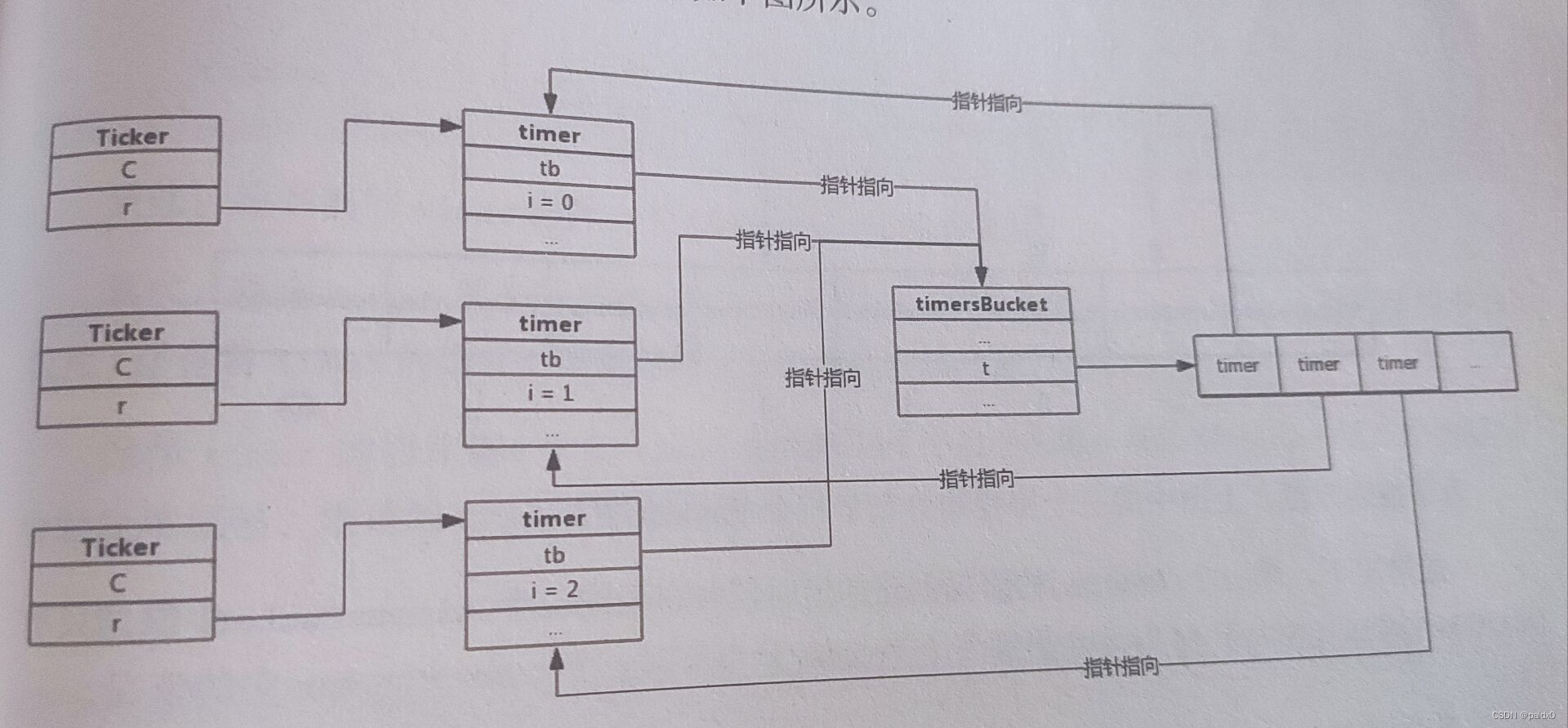
在Go1.14之前有 timer桶数组的概念,1.14以后优化掉了
type timersBucket struct { lock mutex gp *g // 处理堆中事件的协程 created bool // 添加首个定时器后为true sleeping bool // gp 是否休眠 rescheduling bool // gp 是否已暂停 sleepUntil int64 // 事件处理协程睡眠事件 waitnote note // 唤醒协程 t []*timer // 定时器 }
Go在实现时预留了64个timer桶,当协程创建定时器时,使用协程所属的ProcessID%64来存入桶
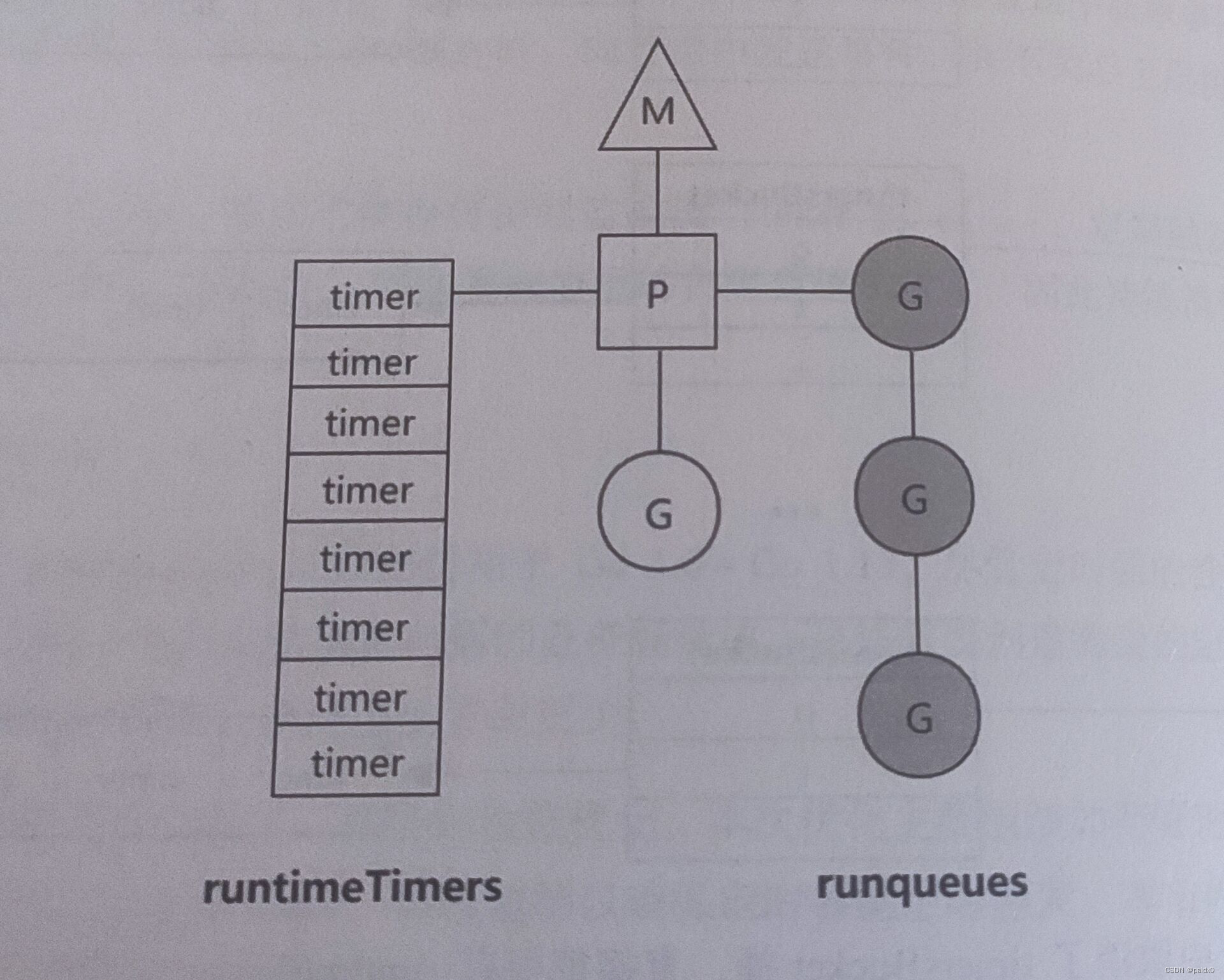
1.14中取消桶,直接把保存timer的堆放到P中,P除了包含协程队列,还直接包含timer
1.14前定时器和其他协程一样也要竞争P调度1.14后每次调度协程都会检查定时器需不需要处理,避免产生频繁的上下文切换
测试
单元测试
- testing.T
- 文件命名 xxx_test.go
- 函数命名 TestXxx
- 执行测试 go test
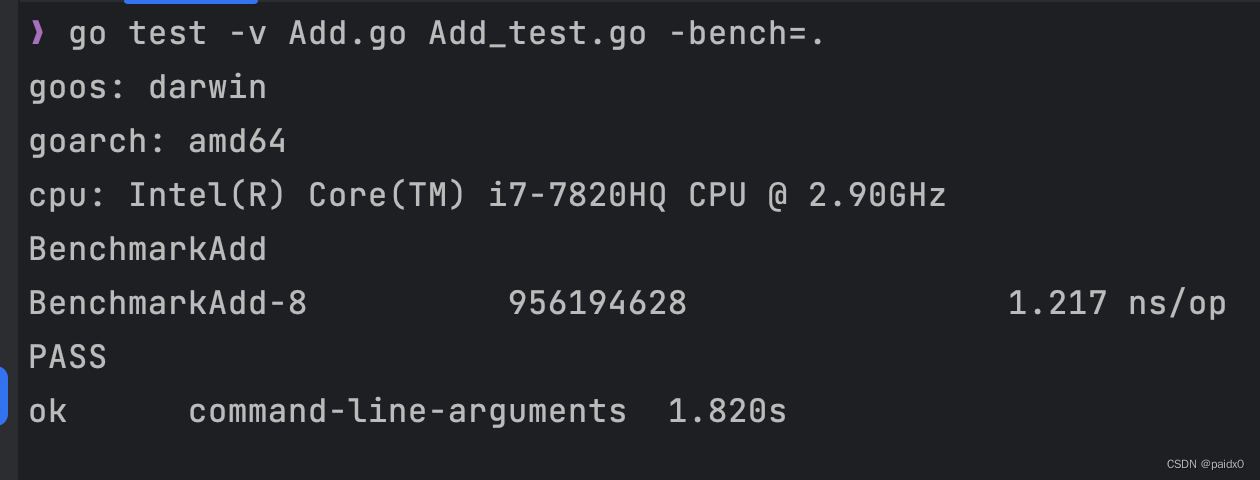
性能测试
- testing.B
- 函数命名 BenchmarkXxx
- 执行测试 go test -bench= [Add/test] 正则匹配符合的性能函数
func BenchmarkAdd(b *testing.B) { for i := 0; i < b.N; i++ { AAA() } } func AAA() func(t testing.T) { return func(t testing.T) { t.Run("test1", add1) t.Run("test2", add2) t.Run("demo3", add3) } }
示例测试
- 不需要引testing包
- 函数命名 ExampleXxx
- 执行测试 go test
测试函数中没有output标识,代表测试函数没有被执行
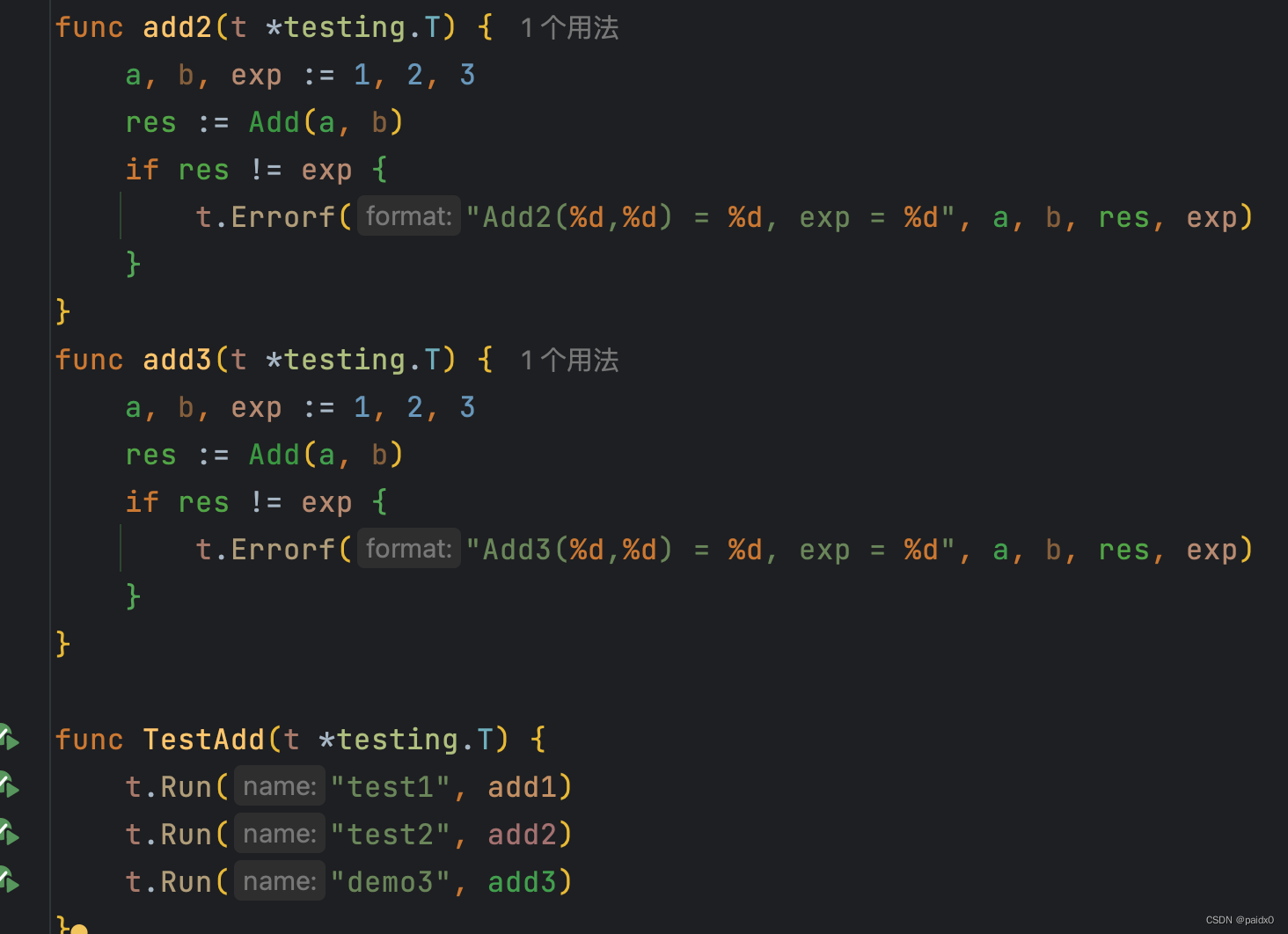
子并发测试
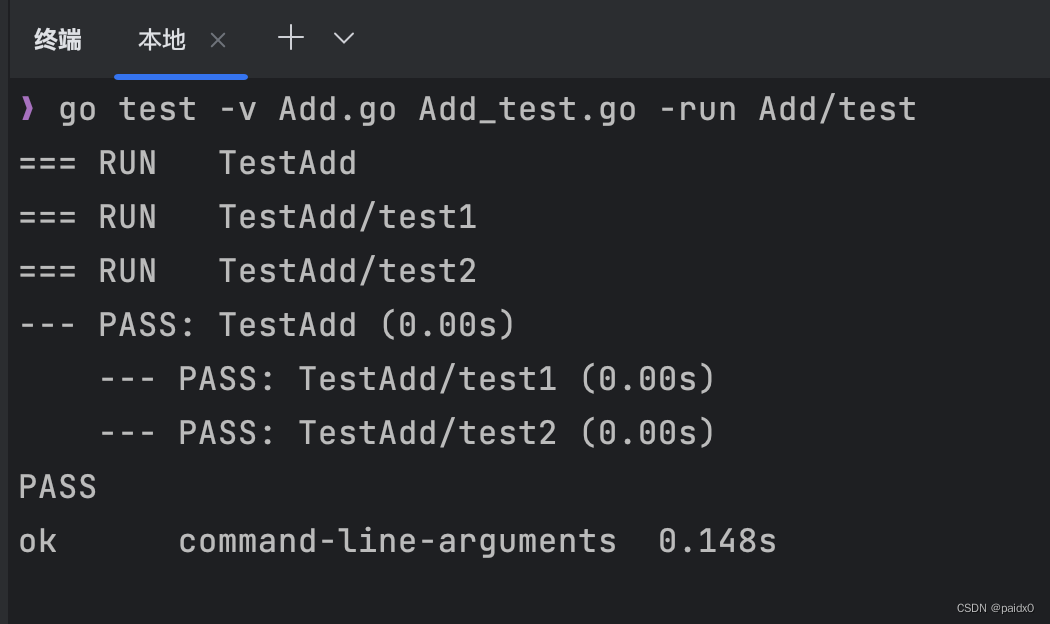
- go test -v Add.go Add_test.go 相关函数变量引用了的文件一起编译
- 函数命名 TestXxx
- 执行测试 go test -v Add.go Add_test.go -run Xxx[/test] 包含匹配,比如命名包含test的就会被执行
包含test的被执行,demo的没执行
Main测试
- testing.M
- 函数命名 TestMain
func TestMain(m *testing.M) { // 执行单元测试、性能测试、示例测试 // 返回 0 全部通过,返回 1 有失败 code := m.Run() os.Exit(code) }type M struct { deps testDeps tests []InternalTest // 单元测试 benchmarks []InternalBenchmark // 性能测试 fuzzTargets []InternalFuzzTarget // examples []InternalExample // 示例测试 timer *time.Timer // 超时时间 afterOnce sync.Once numRun int exitCode int }
common
T 和 B 是在 common上做扩展
type common struct { mu sync.RWMutex // 读写锁 output []byte // 测试日志 w io.Writer // 子测试通过 w传递给父测试中 ran bool // 是否被执行过 failed bool // 当前测试失败,则 true skipped bool // 是否已跳过当前测试 done bool // 当前测试及子测试已结束 helperPCs map[uintptr]struct{} // helperNames map[string]struct{} // cleanups []func() // cleanupName string // cleanupPc []uintptr // finished bool // 当前测试结束,则 true inFuzzFn bool // chatty *chattyPrinter // 对应 -v,打印更详细日志 bench bool // hasSub int32 // 当前测试是否包含子测试 raceErrors int // 竞态检测错误数 runner string // 当前测试函数名 parent *common // 父测试指针 level int // 测试嵌套层数 creator []uintptr // 测试函数调用栈 name string // 记录每个测试函数名 start time.Time // 记录测试开始时间 duration time.Duration // 记录花费时间 barrier chan bool // 控制父测试和子测试执行的channel signal chan bool // 通知当前测试结束 sub []*T // 子测试列表 tempDirMu sync.Mutex // tempDir string // tempDirErr error // tempDirSeq int32 // }
TB、T、B
type TB interface { Cleanup(func()) Error(args ...any) Errorf(format string, args ...any) Fail() FailNow() Failed() bool Fatal(args ...any) Fatalf(format string, args ...any) Helper() Log(args ...any) Logf(format string, args ...any) Name() string Setenv(key, value string) Skip(args ...any) SkipNow() Skipf(format string, args ...any) Skipped() bool TempDir() string // 私有接口用于控制接口唯一性 // 即使用户代码实现了这些方法,但是无法实现这个私有接口,也就无法实现 TB接口 private() } type T struct { common isParallel bool // 当前测试是否需要并发 isEnvSet bool context *testContext // 控制测试并发调度 } type B struct { common importPath string context *benchContext N int // 目标代码执行次数,会自行调整 previousN int previousDuration time.Duration benchFunc func(b *B) // 性能测试函数 benchTime durationOrCountFlag // 测试函数最少执行时间,默认1s bytes int64 // 每次迭代处理的字节数 missingBytes bool timerOn bool // 是否开始计时 showAllocResult bool result BenchmarkResult // 测试结果 parallelism int startAllocs uint64 // 开始时堆中分配的对象总数 startBytes uint64 // 开始时堆中分配的字节总数 netAllocs uint64 // 结束时时堆中分配的对象总数 netBytes uint64 // 结束时堆中分配的对象总数 extra map[string]float64 // }
- -timeout 超时时间
- -args 参数列表
- -json 测试结果转换成JSON格式
- -o 生成测试二进制程序
- -benchtime s 每个性能测试时间,默认1s
- -count n 每个测试执行次数,默认1次
- -parallel n 设置最大并发数
- -timeout xs|xm|xh 超时时间,默认超过10分钟退出
- -benchmem 性能测试同时打印每个操作分配的字节数和对象数