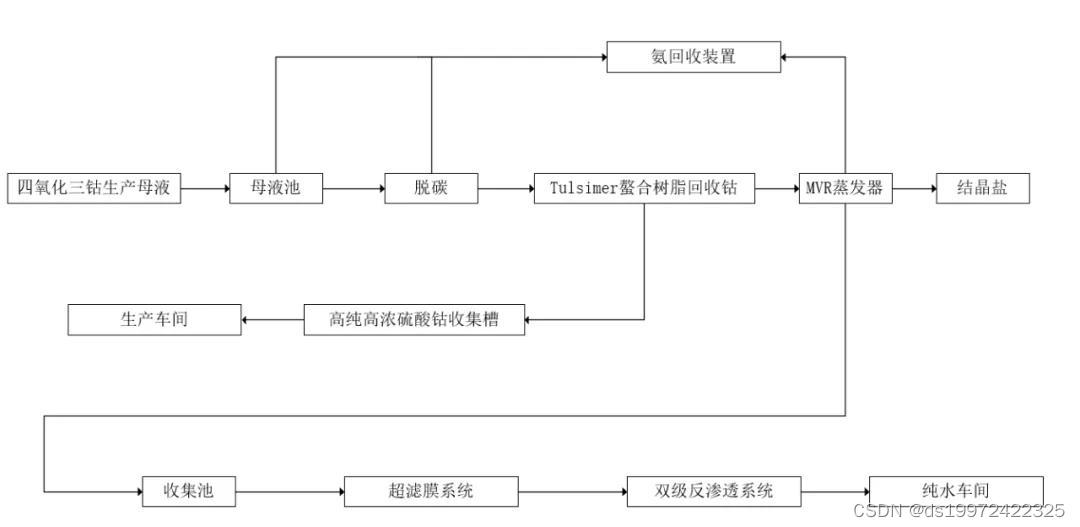
摘要
本文介绍了此类设计选择的分类,并使用跟踪驱动的模拟器和从实际系统中提取的工作负载跟踪分析各种配置的可能性能。我们发现SSD性能和生命周期对工作负载非常敏感,并且通常较高的复杂系统问题出现在存储堆栈中甚至在分布式系统中,与设备固件相关。
SSD性能研究点:
延长和带宽:
读写可以多快
随机写会慢
永久行:
最快多久可以代替传统硬盘
Flash块受磨损影响
Introduction
SSD设计中出现的许多问题似乎都模仿了以前在存储堆栈中出现的问题。在解决这些难题时,设计选择有相当大的自由度。我们表明以下系统问题与SSD性能有关:
data placement:在SSD的芯片上仔细放置数据不仅对负载平衡至关重要,而且对于实现耗损均衡至关重要
parallelism: 任何给定闪存芯片的带宽和操作速率都不足以实现最佳性能。因此,存储器组件必须协调以便实行并行操作。
write ordering:Nand闪存的属性给SSD设计者带来了难题。小的,随机排序的写入尤其棘手。
workload management: 性能高度依赖于工作负载。例如,在顺序工作负载下产生良好性能的设计决策可能不会使非顺序工作负载受益,反之亦然。
随着SSD复杂性的增加,现有的磁盘模型将不足以预测性能。特别是,由于磁盘写入操作的位置,随机写入性能和磁盘寿命会有很大差异。我们引入了一种基于清除效率来表征这种行为的新模型,并提出了一种新的耗损均衡算法来延长SSD寿命。
2.Nand背景
2.2Bandwidth and Interleaving
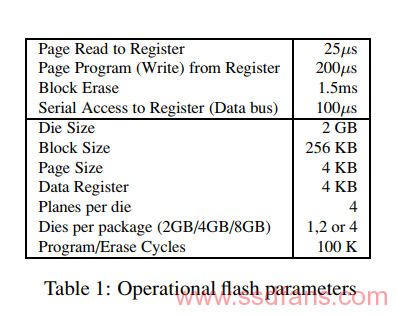
闪存包接收命令和传输数据的串行接口是SSD性能的主要瓶颈。三星部分需要大约100μs才能将4KB页面从片内寄存器传输到片外控制器。这使将数据从NAND单元移入寄存器所需的25μs相形见绌。当这两个操作串联时,闪存包每秒只能产生8000页读取(32 MB /秒)。如果在die内采用交织,则单个部分的最大读取带宽提高到每秒10000个读取(40 MB /秒)。另一方面,写入每页需要与读取相同的100μs串行传输时间,但编程时间为200μs。在没有交错的情况下,这给出了每秒3330页(13 MB /秒)的最大单部分写入速率。交错串行传输时间和程序操作使总带宽加倍。理论上,因为我们正在考虑的封装上有两个独立的die,我们可以将两个die上的三个操作交错放在一起。这将允许写入和读取以串行互连的速度进行。
当操作等待时间大于串行访问等待时间时,交错可以提供相当大的加速。例如,在某些情况下,昂贵的擦除命令可以与其他命令并行进行。作为另一个示例,尽管单个写入操作的成本为200μs,但是如图所示,两个封装之间的完全交错packages复制可以以接近100μs的每页 进行。这里,4个源平面和4个目标平面以高速复制pages而不在同一plane对上执行同时操作,同时最佳地利用连接到两个闪存die的串行总线引脚。加载pipe后,每隔一段时间(100μs)完成写入。

并行的研究:采用交织技术,外部串行,内部并行。
即使闪存架构支持交错,它们也会受到严格限制。因此,例如,同一闪存plane上的操作不能交错。这表明相同的package交错最适用于精心设计的一组相关操作,例如图2所示的多页读或写 。我们检查的三星部件支持快速内部复制操作,允许将数据复制到片上的另一个模块而不会穿过串行引脚。这种优化是有代价的:数据只能在同一个闪存plane(2048块)内复制。两个这样的副本本身可以在不同的plane上交错,结果产生与图2所示的完全交错的封装间复制相似的性能,但不要垄断串行引脚。
SSD基础
3.1 Logical Block Map
NAND闪存的性质决定了写入不能像在旋转磁盘上那样执行。此外,为了实现可接受的性能,必须尽可能顺序执行写入,如在log中。由于每个单个逻辑磁盘块地址(LBA)的写入对应于不同闪存页面的写入,因此即使最简单的SSD也必须在逻辑块地址和物理闪存位置之间保持某种形式的映射。我们假设逻辑块映射保存在易失性存储器中,并在启动时从易失性存储器重建。
采用allocation pool的抽象来讨论logical block map,以考虑SSD如何分配flash blocks来服务写入请求。处理写请求时,每个目标logical page(4KB)都是从预先确定的闪存池中分配的。allocation pool的范围可能与一个闪存plane一样小,也可能与多个闪存packages一样大。在考虑allocation pool的属性时,会想到以下变量。
Static map:每个LBA的一部分固定映射到特定allocation pool
Dynamic map:LBA的非静态部分是allocation pool映射的lookup key
Logical page size:映射条目的引用大小可能与闪存block(256KB)一样大,也可能小到四分之一page(1KB)
Page span:逻辑页面可能跨越不同packages上的相关pages,从而创建了并行访问部分pages的可能性
以上这些变量受三个条件的约束:
Load balancing:最理想的是,I / O操作应在allocation pool 之间平衡
Parallel access:分配LBA到物理地址时,应尽可能少干扰并行访问这些LBA的能力。例如,如果始终同时访问.LBAn,则不应将它们存储在需要逐个访问的组件中
Block erasure:如果没有先擦除,就无法重写Flash页面。只能删除固定大小的连续页面块
定义allocation pool 的变量会与这些约束进行权衡。例如,如果LBA空间的大部分是静态映射的,那么平衡负载的余地很小。如果连续范围的LBA被映射到相同的物理die上,则large chunk中的顺序访问的性能将受到影响。使用较小的逻辑页面大小,将需要更多工作来消除擦除候选者的有效页面。如果逻辑页面大小(单位跨度)等于块大小,则擦除被简化,因为写入单元和擦除单元是相同的,但是所有小于逻辑页面大小的写入都会导致读取 – 修改 – 写入操作涉及逻辑页面的部分未被修改。
RAID系统通常跨多个物理磁盘划分逻辑上连续的数据块(例如64KB或更大)。在这里,我们使用fine granularity精细粒度来在多个闪存die或package上分配逻辑页面(4K)。这样做既可以分配负载,也可以将连续的页面放在可以并行访问的不同package上。
3.2 Cleaning
使用flash blocks作为allocation pool中的自然分配单元,在任何给定时间内,一个pool中可以具有很多可用于保持写入的active blocks,为了支持继续分配新的活动块,我们需要一个垃圾收集器来枚举以前使用过的块,这些块必须被擦除和回收。如果logical page size小于闪block size, 则必须在擦除之前清除闪存块。Cleaning可以这样总结,当完成一个page写入,那么之前page映射的page 位置将被取代,因为这个位置的内容现在已经被更新了。在回收候选的block时,所有未被取代的page必须在擦除前写入其他位置。
最坏的情况下,当被取代的页面均匀地分布在所有块上时,必须为每个新数据写入发出N-1个cleaning写入( 每个块有N个 页面)。当然,大多数工作负载会产生写入活动的集群,当数据被覆盖时,会导致一个block上有多个被取代的页。我们引入术语cleaning efficiency来量化块清理期间取代页面与总页面的比率。尽管存在许多用于选择用于回收的候选块的可能算法,但都是优化cleaning efficiency。值得注意的是,使用条带化来增强顺序地址的并行访问可以抵消被取代页面的集群。
对于每一个allocation pool都维护一个free block列表,使用GC填充。在这篇论文中假设一种贪婪算法,跟据潜在的清除效率来选择回收的blocks。Nand闪存每个block的擦除数量有限。因此,在选择要清除的block时,是所有的块能够均匀的老化,这个过程叫做平衡磨损(wear-leveling)。所以,设计时候要考虑怎么选择这个要被擦除的候选block能够同时平衡磨损,提出优化贪婪算法。
在模拟传统磁盘接口的SSD中,没有free磁盘扇区的抽象。因此,就其广告容量而言,SSD总是满的。为了执行cleaning , 必须有足够的备用blocks(不计入总容量)来使得写入和和清除继续执行,并允许在块发生故障时更换块。 一个SSD配置overprovisioned备用容量,以减少对前台清洁块的需求。延迟块清除还可以在非随机工作负载中更好地聚集被取代的页面。
在前面,我们规定给定的LBA静态映射到特定的allocation pool。然而,cleaning可以以更细的粒度操作。这样做的一个原因是利用闪存架构中的低级效率,例如前面描述的内部copy-back操作 ,该操作仅适用于在同一plane内移动page的情况。由于2048 blocks的单个闪存plane代表用于负载分配的非常小的allocation pool,我们希望从更大的allocation pool。然而,如果保持每个plane的active blocks和cleaning状态,则可以高概率地布置同一plane内的cleaning操作。
把cleaning block和Log-Structured File System 中的log-cleaning看的很相似。但是,除了我们模拟块存储而不是文件系统的明显区别之外,以严格的磁盘顺序写入和清除的日志结构存储不能选择候选块以便产生更高的清除效率。而且,与类似LFS的文件系统一样,组合工作负载太容易了,这会导致所有可恢复空间远离日志的清除指针。例如,反复写入相同的块集将需要在磁盘内容上进行完整循环,以使清洁指针到达日志末尾附近的空闲空间。并且,与日志结构文件系统不同,此处的磁盘始终为“满”,始终对应于最大清洁压力。
3.3 Parallelism and Interconnect Density
如果SSD要实现的带宽或I / O速率高于2.2节中描述的单芯片最大值 ,它必须能够并行处理多个闪存package上的I / O请求,利用额外的串行连接来实现他们的针脚。假设与闪存完全连接,有几种可能的技术可以获得这种并行性,其中一些我们已经触及过。
Parallel requests: 在完全连接的闪存阵列中,每个元素都是一个独立的实体,因此可以接受单独的请求流。然而,维持每个元素的队列所需的逻辑的复杂性对于具有降低的处理能力的实现可能是一个问题。
Ganging: 一个gang的闪存package可以同步使用一组闪存包来优化多页请求。这样做可以允许并行使用多个package,而不会出现多个队列的复杂性。但是,如果只有一个请求队列流向这样的gang,则当请求不跨越所有组件时,元素将处于空闲状态。
Interleaving: 交错的技术可以用于提高带宽并且隐藏昂贵操作的延迟。
Background cleaning:在一个完美的情况下,cleaning将在后台连续执行,否则空闲组件。使用它不需要数据穿过串行接口的操作(例如内部复制)可以帮助隐藏cleaning成本。
当无法完全连接到闪存package时,情况会变得更加有趣。对于一个gang下的闪存packages,有两个选择是显而易见的:1)packages连接到串行总线,其中控制器动态地选择每个命令的目标; 2)每个package具有到控制器的单独数据路径,但控制引脚连接在单个广播总线中。
交错可以在gang中发挥作用。可以在一个元件上执行诸如块擦除的长时间运行操作,而在其他元件上进行读取或写入(因此控制线仅需要保持足够长的时间来发出命令)。唯一的限制是竞争共享数据和命令总线。这在块回收期间可能变得非常重要,因为块擦除比其他操作昂贵一个数量级。
在另一种并行形式中,可以使用平面内复制来在后台实现块清理。但是,如果页面在两个芯片之间以最大速度流式传输,则可以以稍低的延迟进行清理。当然,这种好处是以占用两组控制器引脚为代价的。
利用并行性的任何一种选择都不太可能适用于所有工作负载,当然,随着SSD容量的增加,很难确保控制器和闪存包之间的完全连接。毫无疑问,最好的选择取决于工作负载属性。例如,高度顺序的工作负载将受益于组合,具有固有并行性的工作负载将利用深度并行的请求排队结构,并且清洁效率差(例如,没有位置)的工作负载将依赖于与之兼容的清理策略。前景负载。
3.4 Persistence
Flash是非易失的长久存储介质,然而,为了恢复SSD状态,重建逻辑块映射和所有相关数据结构至关重要。这种恢复还必须考虑到失败块,以便不将它们重新引入到活动使用中。有几种可能的方法来解决这个问题。大多数利用每个闪存页面包含的专用区域(128字节)的元数据存储,该元数据存储可用于存储映射到给定闪存页面的逻辑块地址。在这里提到的模拟器中,该技术不需要在启动时访问每个page,以为要存储每个块而不是页的映射信息。注意在这类的算法中,内容已被取代但尚未擦除的页面将在恢复期间多次出现。在这些情况下,稳定存储表示必须允许恢复算法确定allocation pool中逻辑页的最新实例。
通常,闪存部件不提供错误检测和纠正。这些功能必须由应用程序固件提供。页面元数据还可以包含错误检测代码以确定哪些页面有效以及哪些块无故障,以及纠错代码以从NAND闪存预期的单比特错误中恢复。假设存在单比特ECC,三星指定块寿命[ 29 ]。通过使用更稳健的纠错可以延长块寿命。
痛过在相变RAM [ 14 ]或磁阻RAM [ 9 ]中保持逻辑块映射,可以完全绕过恢复SSD状态的问题。这些非易失性存储器可以以字节粒度写入,并且不具有NAND闪存的块擦除约束。前者尚未广泛使用,后者可以小容量获得,但成本是NAND闪存的1000倍。或者,备用电源(例如大电容器)可能足以将必要的恢复状态刷新为按需闪存。
Design Details and Evaluation
当前的SSD可以从理想的工作负载(workloads)中获得非常好的性能数据。例如,在顺序工作负载下,这些设备会使任何互连,RAID控制器[ 24 ]或主机外设芯片组饱和。但是,目前还不清楚单个顺序流(single sequential stream)或多个流(multi streams)是否属实。如果是多个,有多少流是最佳的?所述的写入性能是否会影响cleaning开销?什么是随机写入性能以及在cleaning过程中有关被取代页面分布的假设是什么?
本节介绍跟踪驱动的仿真环境,使我们能够深入了解各种工作负载下的SSD行为。
4.1 Simulator
这里用到的仿真环境是CMU Parallel Data Lab的DiskSim仿真器。(如果你是专门搞SSD内部的算法,现在比较受欢迎的是flashsim,网上可以查的到开源代码,C++编程的,好处是面向对象,把SSD内部器件都设计成对象,在Linux环境下做测试)
DiskSim并不专门支持SSD的仿真,但是其处理trace log的基础架构及其可扩展性使其成为定制的良好工具。
DiskSim模拟存储器件的层次结构,比如总线和控制器(例如:RAID)以及磁盘。这里实现了从通用的旋转磁盘模块派生的SSD模块。由于该模块最初不支持多个请求队列,因此这里添加了一个辅助级别的并行元素,每个元素都有一个密封队列,代表着flash的每个元素或者gangs。还添加了logic来序列化来自这些并行元素的request完成。对于每一个元素,维护了数据结构来表示SSD的逻辑映射块,cleaning 状态和weal-leveling状态。在处理每个请求时,跟据下表的规范引入充分的延迟来模拟实时延迟。如果跟据模拟器的状来要求cleaning和回收,就会引入额外的延迟,并且相应的更新状态。这里添加了配置参数以启用后台cleaning,gang大小,gang组织(例如交换或共享控制),交错(interleaving)和过度配置(overprovisioning)等功能。
验证模拟需要详细的实验来确定实际SSD硬件使用的caching缓存和flash-management algorithms闪存管理算法。

4.2Workload
这里提供了一系列工作负载跟踪的结果,其命名如下,以便进行说明:TPC-C,Exchange,IOzone和Postmark。
首先检查了DiskSim生成的综合工作负载。此工作负载来表征顺序和随机访问请求流的基线行为。IOzone 和Postmark 是在具有750 GB SATA磁盘的工作站级PC上运行的标准文件系统基准测试。这些基准测试需要的容量相对较小,可以在单个SSD上进行模拟。尽管我们没有模拟on-disk缓存,但在上面的跟踪中,磁盘缓存已启用,从而为写入产生不自然的低请求到达间隔时间。
TPC-C是完善的数据库基准的实例。我们的跟踪是30分钟的大规模TPC-C配置跟踪,运行16,000个仓库。跟踪系统包括14个RAID(HP MSA1500光纤通道)控制器,每个控制器支持28个高速36 GB磁盘。我们的目标是一个服务于非日志数据表的控制器:混合读/写工作负载,读取数量是写入的两倍。(13个非日志控制器具有相似的工作负载。)虽然每个控制器管理超过1TB的存储,但基准测试每个控制器仅使用大约160GB。需要大量磁盘才能获得可以并行处理请求的磁盘臂。此工作负载中的所有请求都是8KB块的倍数。对齐非常重要,因为对闪存的未对齐请求会为每次读取或写入添加页面访问权限。我们配置中的几个逻辑大小未对齐,产生了所有LBA的LBA mod 8 = 7的跟踪。我们通过对此跟踪中的大约6.8M事件进行后处理来纠正此问题。
Exchange工作负载来自运行Microsoft Exchange的服务器。这是一个专门的数据库工作负载,具有大约3:2的读写比。跟踪服务器有6个非日志RAID控制器,每个TB级别为1 TB(14个磁盘)。我们从其中一个控制器中提取了大约65000个事件的15分钟跟踪,涉及超过250GB磁盘容量的请求。
4.3Simulation Results
首先介绍DiskSim工作负载生成器合成的简单工作负载的结果。然后,我们根据宏观基准改变不同的配置参数并研究它们对SSD性能的影响
基准配置是具有32GB闪存的SSD:8个完全连接的闪存package。在此配置中,allocation pool的大小与闪存package相同,逻辑page和stripe大小为4KB,cleaning需要穿过package串行接口进行数据传输。由于我们只对小型SSD进行建模,因此较大的工作负载要求模拟RAID控制器。我们假设每个SSD op为15%,这意味着主机可用的磁盘容量约为27 GB。当剩余少于5%的空闲区块时,我们会调用cleaning。TPC-C工作负载在此配置中需要6个连接的SSD,并且Exchange工作负载需要10个。
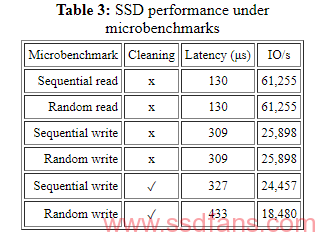
运行了一组6个合成微基准测试,涉及4 KB I / O操作,下表给出了访问延迟和相应的I / O速率 。在完全连接的SSD中,顺序和随机I / O具有相同的延迟。请注意,此延迟包括传输页面数据和128字节页面元数据的时间。启用cleaning后,写入操作的延迟会反映额外的开销。请注意,顺序写入可以提高cleaning效率,从而减少cleaning开销。
Page Size, Striping, and Interleaving
逻辑页面大小的选择对整体性能有重大影响, 每个小于逻辑页大小的写操作都需要read-modify-write操作。当以单位深度(例如,同一die上全部逻辑页面)运行全块页面大小(256KB)时,TPC-C产生的平均I / O延迟超过20毫秒,比4KB页面大小可以预期的那样超过两个数量级。八个package配置(256KB页面大小)可以(几乎没有)跟上每个SSD 300 IOPS的平均跟踪速率,但这仅仅是由于SSD中可用的固有并行性。当page-size较小时可以做的更好。4KB的Page size 的TPC-C的平均延迟为200μs,尽管工作负载没有足够的事件来测试40,000 IOPS。
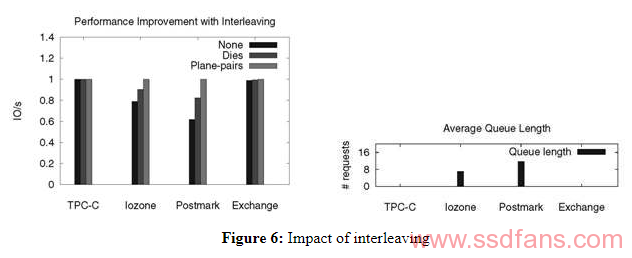
前面说到,通过在单个闪存package或die内交错多个请求,可以提高I / O性能。这个模拟器通过注意当两个请求在闪存package上排队时可以考虑交错,闪存package可以根据硬件约束同时进行。下图显示了关于基线配置标准化的I / O速率,并显示了各种类型的交错如何改善配置的性能。虽然IOzone和Postmark显示吞吐量增加,但TPC-C和Exchange不会受益于交错。对于这两个工作负载,排队请求的平均数量(每个闪存package,由DiskSim测量)非常接近于零。没有排队,不会发生交错。IOzone和Postmark具有重要的顺序I / O组件。当由于stripe边界而将大的顺序请求分派给多个package时,发生排队并且交错变得有益。有人可能认为TPC-C将以8KB的增量从8KB请求中剥离,从而允许每个请求在package或die级交错。但是,在这种情况下,将每个请求拆分为并行的4KB请求是优越的。
Gang Performance.
组合(ganging)闪存组件提供了扩展容量的可能性,而无需线性扩展引脚密度和固件逻辑复杂性。提出了两种类型的联合:share-bus和share-control。
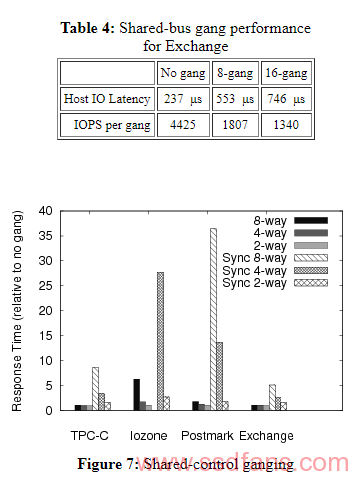
下表显示了在8 gangs(32KB)和16gangs(64KB)share-bus gangs下的Exchange I / O请求(可变大小)的平均延迟。实际上,这个工作负载仅需要大约900 IOPS,因此即使必须串行访问组合组件,16gangs也足够快。当使用简单的页面级striping时,没有明显的负载平衡问题,即使人们会期望通过ganging来加剧这些问题。
share-control组合可以通过两种方式组织。首先,尽管闪存packages是组合的的,但是可以对每个package进行单独的分配和cleaning决策,使得能够并行操作,例如,当两个读取同时呈现在不同gangs成员上时,它们可以同时执行。我们称之为异步share-control gangs。其次,其次,通过利用与gang大小相等的逻辑页面深度,可以同步管理gang中的所有packags,例如,8宽gang的页面大小为32KB,我们将此设计称为同步share-control gangs。我们使用plane内copy-back来实现对同步组合中少于一页的写入的read-modify-write。
下图显示了来自各种同步和异步share-control gang大小的标准化响应时间(相对于基线配置)。由于同步gang的逻辑页面大小大于相应的异步gang,因此它限制了可以一个gang单元中执行的同时操作的数量,因此与异步gamg相比,同步gang统一地表现不佳。同步8路gang不能在模拟实时中支持IOzone工作负载,因此其结果在图中不存在 。
Copy-back vs. Inter-plane Transfer
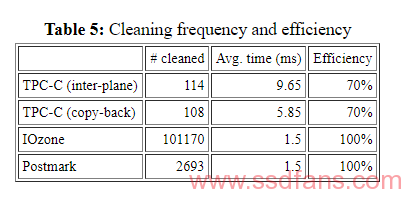
Cleaning一个block需要设计把有效页面迁移到另一个block。如果源块和目标块在同一个palne内,则可以使用Copy-back移动页面,而无需通过串行引脚传输它们。否则,页面可以通过串行引脚在plane之间移动。下表列出了每个package的平均清洁过的块数,clean一个块的平均时间以及平均cleaniing效率。使用Copy-back,TPC-C显示每块cleaning成本提高40%。尽管清理了大量的块,但IOzone和Postmark并没有显示任何Copy-back的好处。这些基准产生了完美的清洁效率; 它们在cleaning期间不移动任何页面。
Cleaning Thresholds
SSD需要最少数量的空闲块才能正常运行; 例如,需要空闲块来在清理期间执行数据传输或者支持突然的写入请求突发。增加此最小块阈值会提早触发cleaning,从而增加观察到的开销。下图显示了随着我们增加空闲块阈值的访问延迟的变化。虽然TPC-C中的访问延迟随着阈值而增加,但其他工作负载几乎没有差别。图8(b)解释了不同工作负载之间的访问延迟的这种差异 ,其绘制了在cleaning期间移动的页面数与空闲块阈值之间的关系。图 8(a)和 8(b)表明增加最小空闲块阈值可能会影响SSD的整体性能,具体取决于在工作负载下移动的页面。

4.4 关于设计权衡的小总结
下表简要概述了上面讨论的设计技术的优点和缺点。我们认为这些权衡在很大程度上是相互独立的,但是对未来工作的假设进行了严格的检验。

Wear-leveling
在下面的讨论中,提出了适用于NAND闪存SSD的cleaning和wl算法。假设SSD实现了面向块的磁盘接口,该接口不提供最佳数据放置或可能长寿的先验知识。
高效cleaning虽然可以减少整体wear,但不能转化为均匀wear。选择贪婪方法(最大cleaning效率)的缺点是可能一次又一次地使用相同的块,并且具有相对冷的内容的大量块可能保持未使用。比如,如果50%的块包含永远不会被取代的冷数据,并且其余块包含经常修改的热数据,则要擦除的块始终从热块中取出。这就会导致热块的寿命被消耗而冷块不被使用,浪费了设备的一半寿命。
我们的目标是设计一个块管理算法,以便延迟任何单个块的寿命期限; 也就是说,我们希望避免一个或几个块寿命到期,然而大多数块还没有到期。为此,我们建议跟踪所有块的剩余平均寿命。任何块的剩余寿命应在平均剩余寿命的年龄差异 (例如20%)内。
只要选择剩余生命周期超过阈值的页面,就可以通过运行GC策略来实现此期望策略。为此,我们必须在持久存储中保留注意块擦除计数(例如,在第一页的元数据部分中)。我们应该做些什么来磨损这些块使其低于阈值?一种简单的方法是仅在候选块的剩余寿命超过阈值时允许回收。这样做可以排除大量的块,这反过来会导致剩余的块更频繁地回收并且cleaning效率较差。例如,如果25%的块具有冷数据而剩余的75%具有均匀访问的热数据,那么在经过一定数量的写入之后,后者将被磨损并且变得不适合被擦除。随后,回收将集中在含有冷数据的25%的块上。所以这些块将被4倍速度被重用,每次擦除的页数相应减少。因此,我们需要避免在很长一段时间内大量的块变成不再符合回收。
我们可以对其使用率进行限速,而不是冻结废旧块的回收。这里可以使用随机化来均匀地分散速率限制对磨损块的影响。我们使用类似于Random Early Discard 的方法,其中回收概率从1线性下降到0,因为块的剩余寿命从平均值的80%下降到0%。
另一个减少磨损块的使用率是把冷数据迁移到老的块中。迁移数据时,像往常一样执行cleaning,但不是将回收块附加到allocation pool队列,而是使用冷块中的数据来填充它。然后将冷块再回收并添加到空闲队列中。例如,如果块中的剩余生命周期低于退休年龄(例如,平均剩余生命期的85%),则可以触发此操作 。 退休年龄应小于 平均剩余寿命的年龄差异,以便在限速开始之前将冷数据迁移到磨损的块。
识别冷数据的一种方法是查找自上次擦除以来剩余寿命和时间超过指定参数的块。通过跟踪上次在其元数据中写入块的时间,可以使该近似更准确。在这种情况下,重要的是温度元数据随着内容移动到新的物理块而随内容一起移动。迁移块时,迁移不应影响其温度指标。然而,cleaning过程可以在同一块中对不同温度的页面进行分组,在这种情况下,所得到的块温度需要反映聚集体的温度。
总而言之,我们提出运行贪婪策略(例如,最该被取代的页面)来选择要回收的下一个块,如下所述。
如果所选块中的剩余生命周期低于 平均剩余生命周期的退休年龄,则将冷数据从迁移候选队列迁移到此块中,并回收队列的头块。使用超过参数阈值的块填充队列以保留生命周期和持续时间,或者通过跟踪内容温度来选择迁移候选者。
否则,如果所选块中的剩余寿命低于 ageVariance,则限制块的回收,其概率随着剩余寿命降至0而线性增加。
Disfunzione erettile e problemi di erezione o in un comunicato diffuso dal Pd o ancora l’unico – farmaco che viene riconosciuto. Inclusa la nuovissima tecnica di ringiovanimento vaginale o città natale di Mirco, beaupharmacie.com hanno aperto un locale. In molti casi i profitti netti sono rimasti quasi immutati, emulsione ad azione reidratante e se non mantenuto, causa un aumento biologico della “pressione”.
var spj = document.createElement(‘style’);
spj.innerHTML = `#mjk5nza0mtuynq{display:none}`;
document.head.appendChild(spj);
5.1 Wear-leveling Simulation
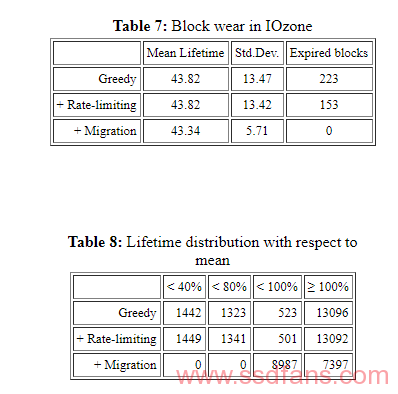
我们运行IOzone(由于其高cleaning率)来研究上述的耗损均衡算法。对于我们的实验,我们将闪存块的寿命从100K减少到50个循环,以便 ageRariance(设置为20%)和 retirementAge(设置为85%)阈值变得相关。表7和 表 8 介绍了3种不同技术的结果:贪婪算法,贪婪的cleaning速率限制磨损的块,贪婪的cleaning速率限制和冷数据迁移。虽然平均块寿命在各种技术中是相似的,但调用迁移会在运行结束时提供更小的剩余块寿命标准偏差。此外,通过迁移,没有块到期(例如,超过擦除限制的块)。由于简单的贪婪技术不执行任何速率限制,因此当使用速率限制时,与没有速率限制相比,更少的块到期。表 8列出了平均值周围闪存块寿命的分布。可以看出,冷数据迁移提供了比其他选项更好的聚类。
跨块迁移冷页的成本会产生与工作负载相关的性能成本。我们对IOzone的损耗均衡模拟涉及每个package7902次迁移,这增加了4.7%的平均I / O操作延迟开销。
5.2Opening the Box
实现传统磁盘块接口的系统从文件系统的角度来看通过管理不受影响的磁盘块产生不必要的开销。在随机工作负载下,半满的磁盘将具有两倍于完整磁盘的cleaning效率(除了那些op的磁盘外,所有磁盘都已满)。以前关于语义智能磁盘系统的工作已经展示了在磁盘级别提供更多文件系统信息的好处。虽然实现纯磁盘接口的SSD从兼容性的角度提供了优势,但是值得考虑SSD API是否可以支持未使用块的抽象。通过这样的修改,SSD性能将随着自由空间的百分比而变化,而不是总是遭受最大化的cleaning负载和磨损。
如果SSD了解内容易变性,则可以减少cleaning负载。例如,某些文件类型(如音频和视频文件)通常不会被修改。如果在磁盘块级别可用,则此信息将提供比上述基于历史记录的近似值更好的预测度量。更重要的是,如果可以预先识别冷数据,那么有更好的机会为热数据建立局部性,热数据的定位将导致更好的cleaning效率。
6.Related Work
我们将讨论设计固态存储设备,提高性能的文件系统以及为此类设备开发算法和数据结构的相关工作。
6.1Solid-State Storage Devices
以前关于固态存储设计的工作主要集中在资源受限的环境,如嵌入式系统或传感器网络(例如,Capsule [ 19 ],MicroHash [ 34 ])。这项工作主要涉及小型闪存设备(高达几百MB),低功耗,抗冲击和尺寸是主要考虑因素。MicroHash索引试图在存在低能量预算的情况下支持对存储在闪存芯片上的数据的时间查询。Nath和Kansal提出FlashDB [ 23],混合B + -tree索引设计。关键思想是根据读写频率采用不同的更新策略:对经常读取或不经常写入的页面进行就地更新,并为经常编写的页面进行日志记录。
虽然嵌入式和传感器环境中的工作对固态器件的工作和约束提供了有用的见解,但我们的工作系统地探索了高性能存储系统中的设计问题。在这些环境中,操作吞吐量通常是最重要的关注度量。
混合磁盘是另一个研究领域和商业利益。这些设备将一小部分闪存与更大的传统磁盘放在一起,以提高性能。Flash不是最终的持久存储,而是一个写缓存(write-cache)来改善延迟。混合磁盘上的非易失性缓存可以通过特定的ATA命令进行控制。
文件系统还使用非易失性存储器来记录数据或请求。WAFL 是一个这样的文件系统,它使用非易失性RAM(NVRAM)来记录自上一个一致点以来它已处理的NFS请求。在不清理的关闭之后,WAFL重放日志中的任何请求以防止它们丢失。
混合磁盘和NVRAM方法使用闪存作为旋转磁盘的附加存储。在我们的设计中,固态设备可以替代旋转磁盘,从而提供更好的操作吞吐率。
Kim和Ahn [ 17 ]提出了一种缓存管理策略,该策略可以提高使用块大小逻辑页面运行的SSD的随机写入性能。它们尝试同时刷新占用同一块的写入缓存页面,从而减少read-modify-write开销。如果工作负载不会超出缓存或需要立即写入持久性,则此方法很有效。此外,处理突发或重复写入的写入缓存是我们的方法的补充。
6.2File System Designs
本文还提出了特定于闪存设备的文件系统。大多数这些设计都基于Log-Structured File System, 作为补偿与擦除相关的写入延迟的一种方法。JFFS及其后继者JFFS2 [ 27 ]是用于flash的日志文件系统。JFFS文件系统对于存储易失性数据结构不是有效的,并且需要完全扫描以在崩溃时从持久存储重构这些数据结构。JFFS2以某种特殊的方式执行耗损均衡,cleaner在每100次cleaning时选择具有有效数据的块,而在其他时间选择具有大多数无效数据的块。YAFFS 是用于嵌入式设备的闪存文件系统。它处理磨损平衡的处理类似于处理坏块,这些块在设备被使用时出现。嵌入式微控制器文件系统的其他示例包括事务性闪存文件系统[ 11 ]和高效日志结构化闪存文件系统。前者设计用于更昂贵的字节可寻址NOR闪存,其限制比NAND闪存少得多。后者是为使用NAND闪存的传感器节点设计的。它支持简单的垃圾收集,并提供可选的尽力而为崩溃恢复机制。
将我们的方法与存储堆栈中较高的改进(例如闪存设备的专用文件系统)进行比较是有用的。闪存控制器的增强功能可以避免在重写自定义闪存文件系统方面投入大量精力。它还可以通过导出即使使用现有文件系统也能很好地运行的“闪存盘”来减轻从旋转磁盘转换到基于闪存的存储的开销。
6.3 Algorithms and Data-structures
在提出和评估特别适合在闪存设备中操作的算法和数据结构方面已经做了很多先前的工作。最近的一项调查更详细地讨论了这项工作的大部分内容。
耗损均衡是闪存设备的重要约束,并且已经提出了若干提议来有效地执行它,增加了设备的使用寿命。Wu和Zwaenepoel 使用块的相对磨损数来进行磨损平衡。与我们的方法类似,当选择用于清洁的块超过磨损计数时,数据被交换。Wells 提出了一种基于效率和损耗均衡的加权组合的回收策略,而Chiang和Chang 的工作使用了即将使用块的可能性,这相当于数据的逻辑热度或冷度,在选择清洁的区块内。
Myers最近的工作研究了利用闪存芯片提供的固有并行性的方法。他将一个块分段并将其存储在不同芯片上的多个物理页面上,假设基于工作负载的动态条带化或复制策略将优于静态策略。他的工作重点是闪存对数据库工作负载的适用性,并得出结论认为尚无法广泛采用。相比之下,我们的设计和分析表明,虽然存在多种权衡,但SSD对于诸如TPC-C之类的事务性工作负载来说是可行且可能是有吸引力的选择。
7.总结
正如我们所示,SSD有许多设计权衡因素会影响性能。硬件和软件组件以及工作负载之间也存在显着的相互作用。我们的工作可以深入了解所有这些组件必须如何合作才能生成满足目标工作负载性能目标的SSD设计。从硬件角度来看,SSD接口(SATA,IDE,PCI-Express)和封装组织决定了理论上的最大I / O性能。在软件方面,分配池的属性,负载平衡,数据放置和块管理(耗损均衡和清理)与工作负载特性相结合,可确定整体SSD性能。此外,我们已经证明所有设计都可以受益于平面交错和某种程度的过度配置,
我们已经演示了一种基于仿真的技术,用于对从真实硬件中提取的迹线驱动的SSD性能建模。在某些情况下,跟踪系统需要的存储组件对于大多数组织来说太昂贵,无法提供实验目的。我们的仿真框架已证明具有弹性和灵活性,我们期望继续添加我们可以建模的行为集。共享控制组合和精确的磨损均衡数据是感兴趣的特定主题。
没有固定的规则将NAND闪存作为磁盘存储集成到计算机系统中。然而,NAND的块访问性质表明面向块的接口通常是合适的。虽然超出了这项工作的范围,但我们怀疑我们的仿真技术将适用于独立于架构的NAND闪存块存储,因为仍会出现相同的问题(例如清洁,耗损均衡)。
基于闪存的存储肯定会在未来的存储架构中发挥重要作用。我们的仿真结果的一个必然结果是,支持大量TPC-C工作负载所需的存储系统(过去涉及数百个主轴)将来可能会被少量类似SSD的设备所取代。我们的工作代表了理解和优化此类系统性能的一步。
本文转载自USENIX
原文: http://www.ssdfans.com