通过之前作业中完成的所有组件,使用高性能的网络结构来解决一些问题。首先会增加一些新的算子(使用CPU/CUDA后端),然后完成卷积、以及用一个卷积神经网络来在CIFAR-10图像数据集上训练一个分类器。接着需要完成循环神经网络(带LSTM),并在Penn Treebank数据集上完成字符级的预测
实现功能
- 在
python/needle/ops.py中添加三个新算子:Tanh、Stack、Split - 实现CIFAR-10数据集的Dataset以及在此基础上训练自己实现的卷积神经网络(本篇暂只关注下面的循环神经网络,这个先跳过)
- 实现循环神经网络
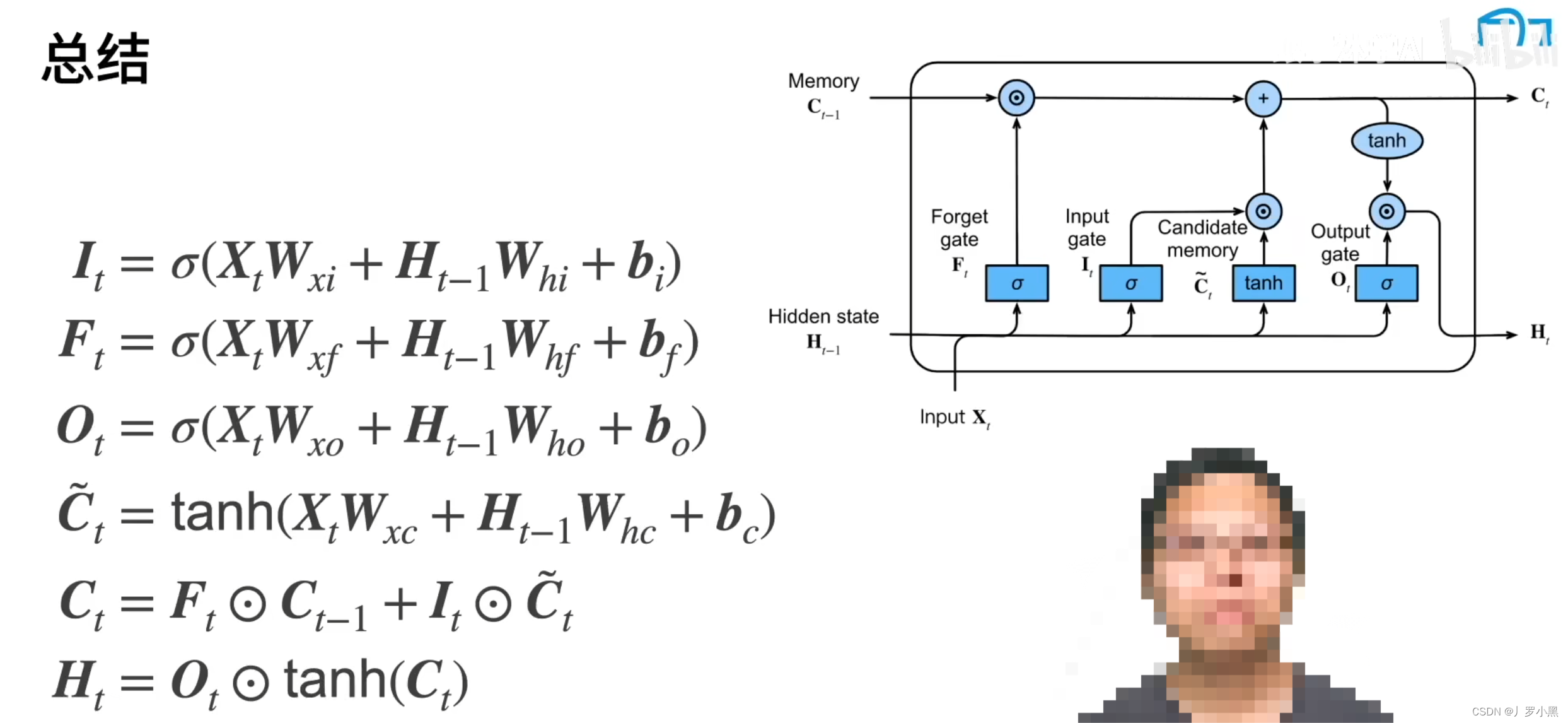
先实现单个RNN cell(class RNNCell),然后将多个RNNcell叠加起来,形成更复杂的网络结构(class RNN),如下图所示,图1为单个RNNcell,图二为多个RNNcell组成的RNN
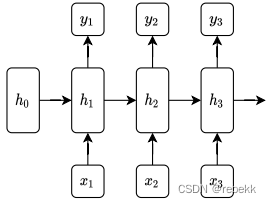
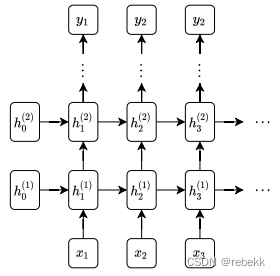
- 实现单个RNN cell(
class RNNCell(Module)):\_\_init__()初始化函数:进行一系列参数初始化,用均匀分布初始化参数矩阵,并选用激活函数(Tanh或ReLU)forward(X,h)函数:即实现 h t = tanh ( x t W i h + b i h + h ( t − 1 ) W h h + b h h ) h_t=\tanh(x_tW_{ih}+b_{ih}+h_{(t-1)}W_{hh}+b_{hh}) ht=tanh(xtWih+bih+h(t−1)Whh+bhh)(其中tanh也可换为relu),代码如下:def forward(self, X, h=None): batch_size, _ = X.shape if h is None: h = init.zeros(batch_size, self.hidden_size, device=self.device, dtype=self.dtype) if self.bias: return self.nonlinearity(X @ self.W_ih + self.bias_ih.reshape((1, self.hidden_size)).broadcast_to((batch_size, self.hidden_size)) \ + h @ self.W_hh + self.bias_hh.reshape((1, self.hidden_size)).broadcast_to((batch_size, self.hidden_size))) else: return self.nonlinearity(X @ self.W_ih + h @ self.W_hh)
- 实现多层RNN(
class RNN(Module))\_\_init__()初始化函数:forward(X,h0)函数:将X(seq_len, bs, input_size)分割成seq_len个X(bs, input_size),将每个分割部分分别输入每个RNN cells,得到num_layers个hiddens和seq_len个out。最终将out组装到一起、将hiddens组装到一起,返回out和hsdef forward(self, X, h0=None): _, batch_size, _ = X.shape if h0 is None: h0 = [init.zeros(batch_size, self.hidden_size, device=self.device, dtype=self.dtype) for _ in range(self.num_layers)] else: h0 = tuple(ops.split(h0, 0)) h_n = [] inputs = list(tuple(ops.split(X, 0))) for num_layer in range(self.num_layers): h = h0[num_layer] for t, input in enumerate(inputs): h = self.rnn_cells[num_layer](input, h) inputs[t] = h h_n.append(h) return ops.stack(inputs, 0), ops.stack(h_n, 0)
- 实现单个RNN cell(
- 实现LSTM网络(在此学习使用numpy一步步实现lstm的流程))
- 实现
Sigmoid - 实现单个LSTMCell
__init__()函数:初始化forward()函数:def forward(self, X, h=None): batch_size, _ = X.shape # X:(batch_size, feature_size) if h is None: h0, c0 = init.zeros(batch_size, self.hidden_size, device=self.device, dtype=self.dtype), \ init.zeros(batch_size, self.hidden_size, device=self.device, dtype=self.dtype) else: h0, c0 = h if self.bias: gates_all = X @ self.W_ih + self.bias_ih.reshape((1, 4 * self.hidden_size)).broadcast_to((batch_size, 4 * self.hidden_size)) \ + h0 @ self.W_hh + self.bias_hh.reshape((1, 4 * self.hidden_size)).broadcast_to((batch_size, 4 * self.hidden_size)) else: gates_all = X @ self.W_ih + h0 @ self.W_hh gates_all_split = tuple(ops.split(gates_all, axis = 1)) gates = [] for i in range(4): gates.append
- 实现