1. 使用缓存的好处:减少数据库的访问频率,提高用户获取数据的速度。
2. 什么样的数据适合存储到缓存中?
①及时性、数据一致性要求不高的数据,例如物流信息、商品类目信息
②访问量大更新频率不高的数据(读多、写少)
3. 读模式中缓存使用流程

一、本地缓存
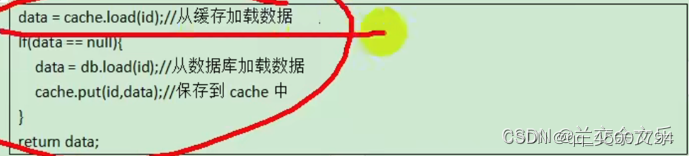
通过cache将数据库的数据缓存在本地内存中,java中最常用的就是将数据库数据缓存在HashMap中。
使用本地缓存存在的问题:
问题1:
分布式架构中,相同的一个微服务部署将在多个服务器中,如果使用本地缓存,每一个服务器都要建立一个缓存区,这样在访问不同的服务器中的微服务时,需要重复将数据加入到缓存区中。

问题2:
如果在写模式情况下,不同服务器中的微服务缓存中的数据同时得到修改,那么将缓存中的数据写回数据库时将会发生写操作的不一致性。
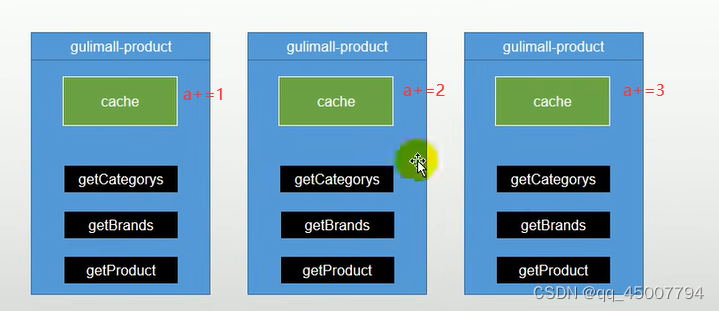
解决办法:使用分布式缓存方式
二、分布式缓存

可以通过redis作为这个缓存中间件。
首先利用序列化操作将java对象转换为跨语言、跨平台兼容的JSON字符串,这个过程可以方便将java对象以JSON字符串的方式保存在redis中。
其次可以利用反序列化操作将JSON字符串转换为java对象,这个过程可以将redis保存的JSON字符串转为java。
高并发环境下的缓存穿透问题:(主要就是DB受到过多访问)
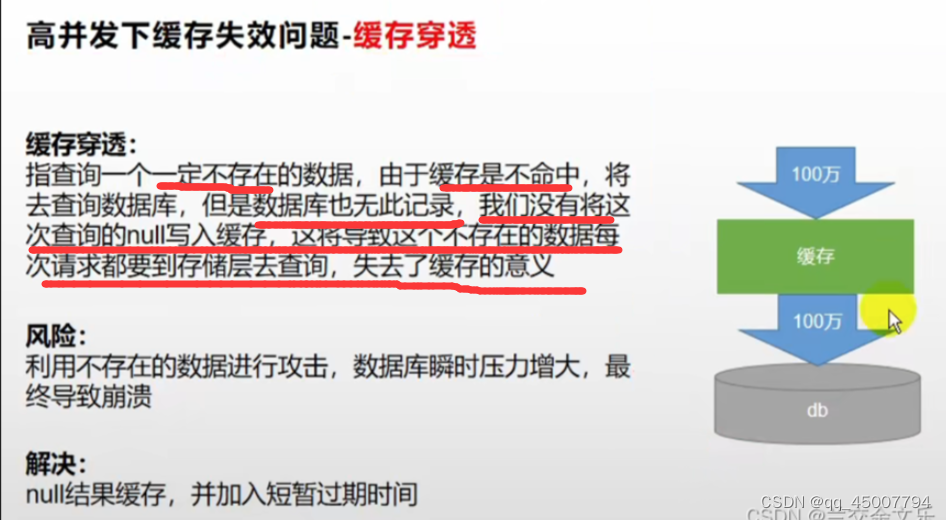
1. 缓存穿透
问题描述:如下图。
解决方法:将空值也进行缓存,但设置较短过期时间。
2. 缓存雪崩(缓存值大面积失效)
问题描述:所有缓存数据设置的过期时间相同,从而导致在同一时间失效,恰好这个时间有大量访问,这些访问就需要同时去访问数据库,导致数据库压力过大崩溃。
解决方法:对于每一个缓存值在固定过期时间基础上设置一个随机值。

3. 缓存击穿(访问频率高的缓存值失效)
问题描述:如果缓存中一个访问频率高的值过期,此时有大量访问访问这个值,导致DB压力过大。
解决办法:加锁。大量并发时,先让一个人去查,其他人等着。这样剩下人就可在缓存直接获取值。

但是加锁,又引发了需要分布式锁的问题:
如果使用本地锁,由于相同的微服务部署在不同的服务器中,假设服务器数量为N,这样依然还是放进来N个DB访问请求(其实问题也不大)。但如果只想放行一个DB访问请求,就必须要分布式锁。

分布式锁的原理如下:
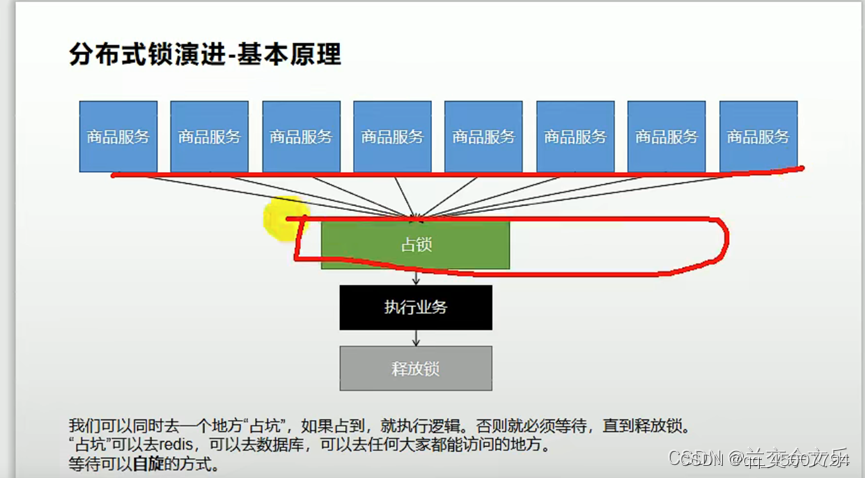
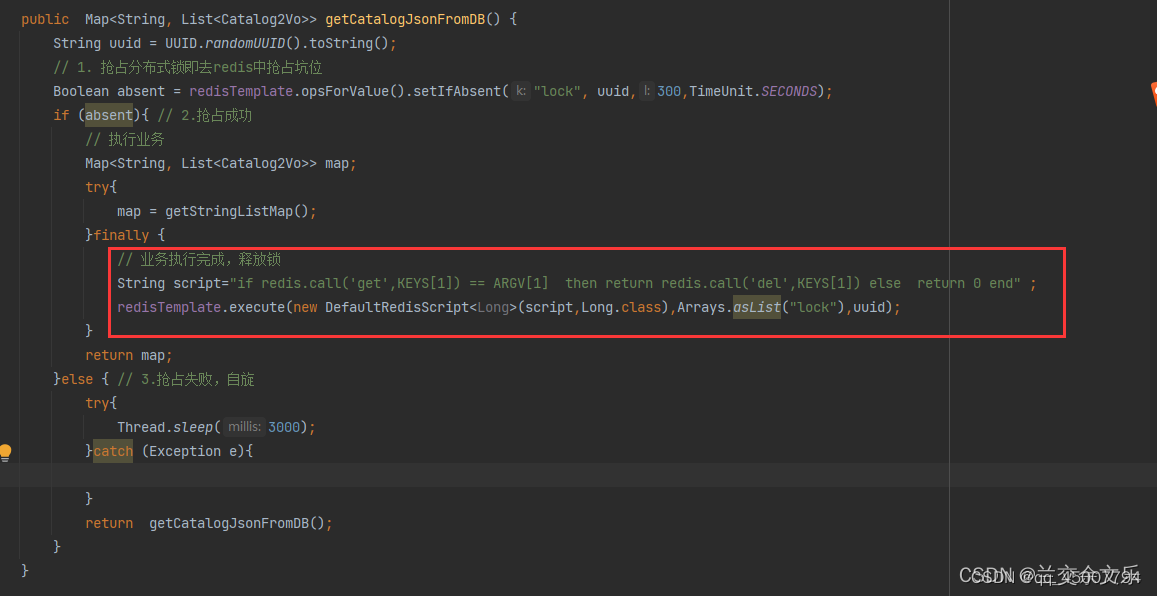
可以向redis中存储一个map,其中key为lock,value可以是任意值。由这个map充当我们分布式锁。使用setIfAbsent()方法抢占分布式锁,这个方法实际上就是set nx 或者 setnx,表示只有当key不存在时才能插入:
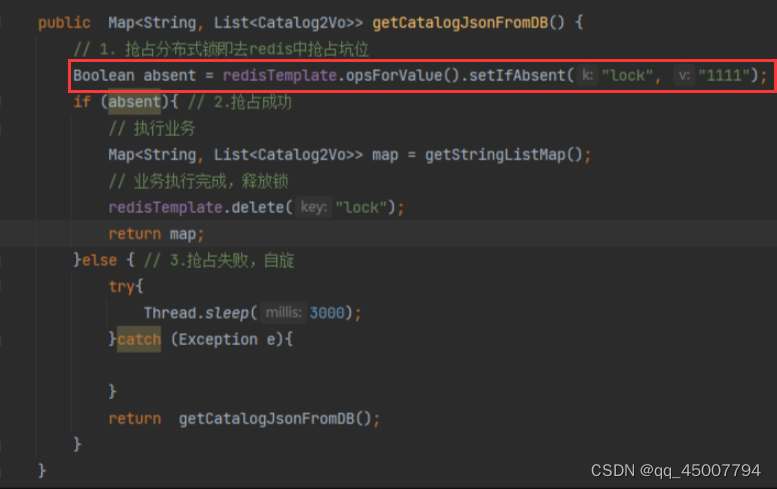
1. 但是这个时候,在业务执行过程中出现异常或者服务器宕机则没有执行删除锁的操作,永远无法释放锁,出现死锁问题。相应解决办法:设置过期时间,即使没有删除,会自动删除。代码如下:
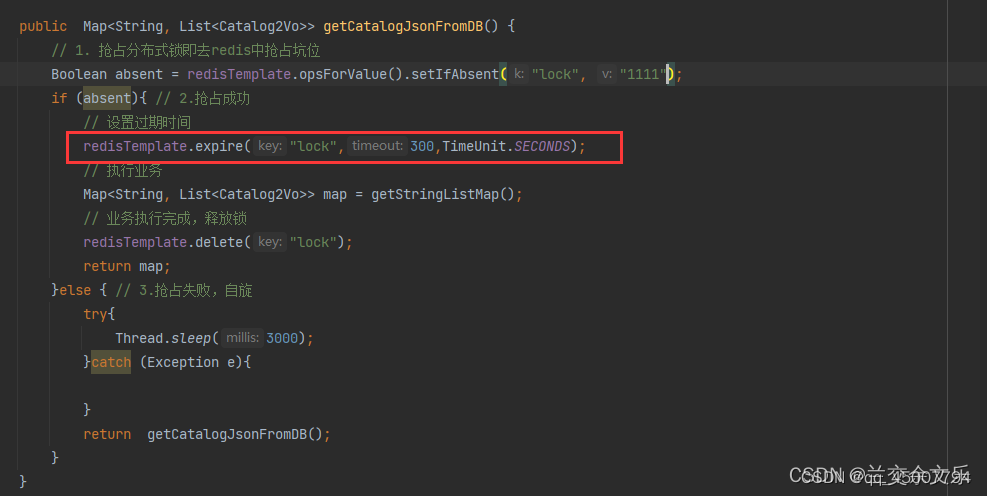
2. 但如果上锁与设置过期时间分开进行,会出现当我们要去设置过期时间时,出现异常或者宕机导致无法设置过期时间。解决办法:抢占锁和设置过期时间必须是原子操作。代码如下:

3. 但是由于我们业务执行时间很长,锁已经过期了,此时别的服务器上的微服务创建了一个锁,当该业务执行完后,会将别的微服务的锁删除(因为我们锁的值为1,此时无法分别这是不是我们业务上的锁,还是其他微服务业务上的锁)。解决办法:给锁赋值上uuid,删除锁之前查询是否是同一把锁。代码如下:
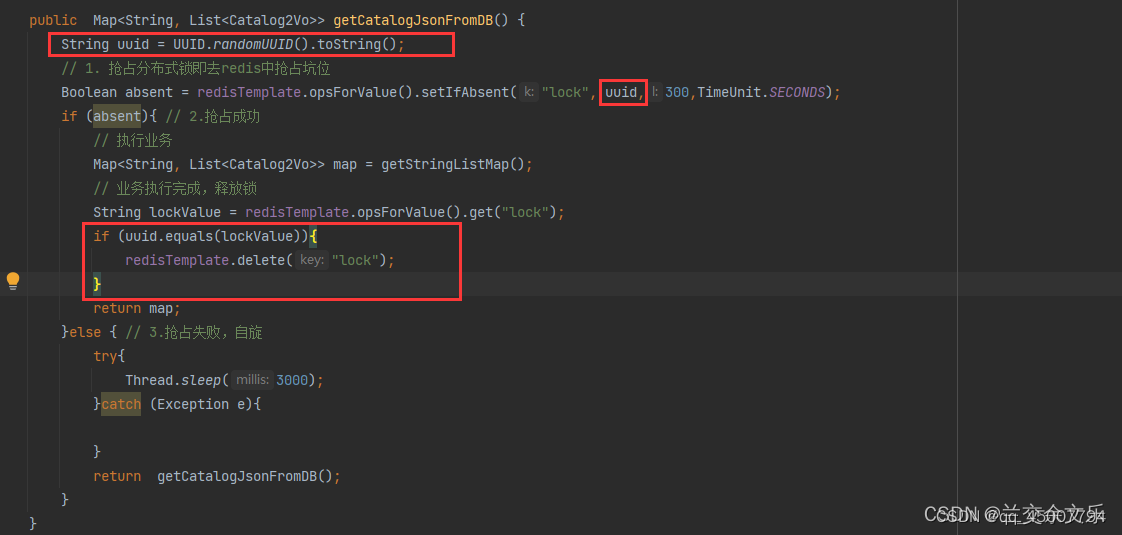
4. 但是上述操作又有新的问题:如果我们在校验锁是否是本业务上的时候,锁正好过期,其他微服务就会重新上锁,如果之前的校验结果为真,则本业务会将其他微服务上的锁删除。解决办法:是查询lock的值和删除lock的值需要原子操作。可以使用lua脚本,将查询与删除合并为一个原子操作。代码如下: