CircuitBreaker熔断器
1、Hystrix目前也进入维护模式
Hystrix是一个用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
2、分布式系统目前所面临的问题
分布式系统面临的问题
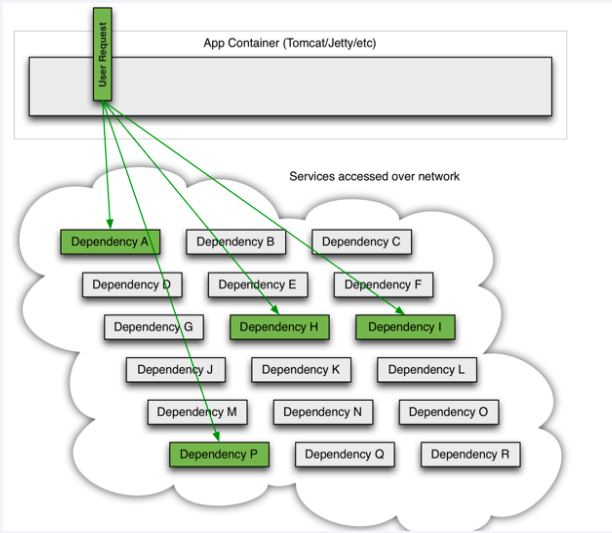
复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免地失败。
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的“扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”.
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
所以,通常当你发现一个模块下的某个实例失败后,这时候这个模块依然还会接收流量,然后这个有问题的模块还调用了其他的模块,这样就会发生级联故障,或者叫雪崩。
**问题是怎么预防服务的雪崩?**
最简单的方法是:有问题的节点,快速熔断,也就是说,快速返回失败处理或者返回默认兜底的数据,也就是服务降级。
“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝),向调用方返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
简单说,就是“保险丝跳闸”,不要影响大局。
如何搞定上述问题,避免整个系统大面积故障
需要解决这些:
- 服务熔断:类比保险丝,保险丝闭合状态(CLOSE)可以正常使用,当达到最大服务访问后,直接拒绝访问跳闸限电(OPEN),此时调用方会接受服务降级的处理并返回友好兜底提示;
- 服务降级:服务器忙,请稍后重试。不让客户端等待并立刻返回友好提示,fallback;
- 服务限流:秒杀高并发操作,严禁一窝蜂的过来拥挤,大家排队,一秒钟N个,有次序;
- 服务限时:错峰访问;
- 服务预热
- 接近实时的监控
- 兜底的处理动作
3、Spring Cloud Circuit Breaker
官网说明:Spring Cloud Circuit Breaker
CircuitBreaker的目的是保护分布式系统免受故障和异常,提高系统的可用性和健壮性。
当一个组件或服务出现故障时,CircuitBreaker会迅速切换到开放OPEN状态(保险丝跳闸断电),阻止请求发送到该组件或服务从而避免更多的请求发送到该组件或服务。这可以减少对该组件或服务的负载,防止该组件或服务进一步崩溃,并使整个系统能够继续正常运行。同时,CircuitBreaker还可以提高系统的可用性和健壮性,因为它可以在分布式系统的各个组件之间自动切换,从而避免单点故障的问题。
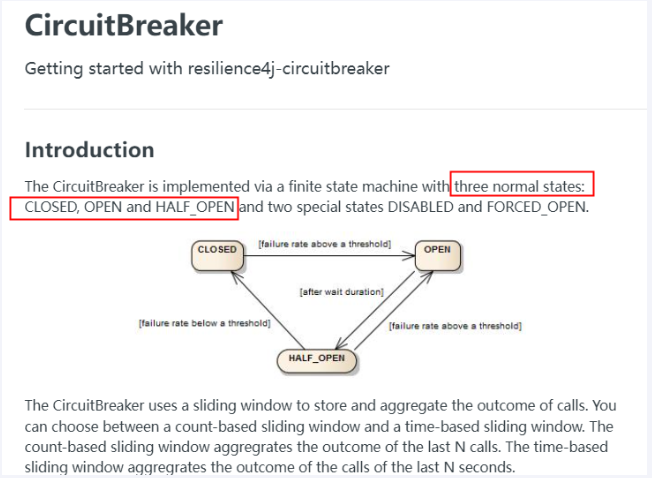
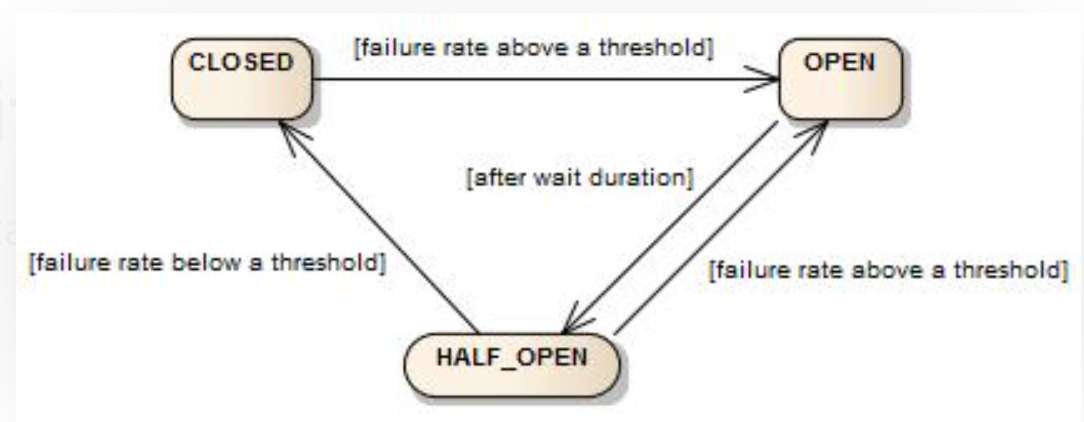
**图解:**当某个服务或组件出现故障,CircuitBreaker就迅速的将当前CLOSED状态切换成OPEN状态,也就是跳闸了。跳闸归跳闸,不能一直断着呀,所以,隔一段时间CircuitBreaker还会尝试发送几次请求看服务或组件是否能用(也就是HALF_OPEN尝试状态),看是否有回应。如果能用就切换成正常的CLOSED状态继续使用,不能用就还回到OPEN状态。
4、Resilience4J
4.1、简介
Github:[GitHub - resilience4j/resilience4j: Resilience4j is a fault tolerance library designed for Java8 and functional programming](https://github.com/resilience4j/resilience4j#1-introduction)
官网:resilience4j (readme.io)
中文手册:Resilience4j-Guides-Chinese/index.md at main · lmhmhl/Resilience4j-Guides-Chinese · GitHub
Resilience4j 是一个轻量级的容错库,专为函数式编程而设计。 Resilience4j 提供高阶函数(装饰器)来增强任何功能接口, 带有断路器、速率限制器、重试或隔板的 lambda 表达式或方法引用。 您可以在任何函数接口、lambda 表达式或方法引用上堆叠多个装饰器。 优点是您可以选择所需的装饰器,而没有别的。Resilience4j 2 需要 Java 17。
4.2、能干嘛?
Resilience4j 提供了几个核心模块:
- resilience4j-circuitbreaker:熔断(重要)
- resilience4j-ratelimiter:速率限制(重要)
- resilience4j-bulkhead: 舱壁(重要)
- resilience4j-retry:自动重试(同步和异步)
- resilience4j-timelimiter:超时处理
- resilience4j-cache:结果缓存
还有用于指标、Feign、Kotlin、Spring、Ratpack、Vertx、RxJava2 等的附加模块。
5、熔断(CircuitBreaker)(服务熔断+服务降级)
5.1、断路器3大状态
CircuitBreaker 通过有限状态机实现,该状态机具有三种正常状态:CLOSED、OPEN 和 HALF_OPEN 以及两种特殊状态 DISABLED 和 FORCED_OPEN。
CircuitBreaker 使用滑动窗口来存储和聚合调用结果。您可以在基于计数的滑动窗口和基于时间的滑动窗口之间进行选择。基于计数的滑动窗口聚合了最后 N 次调用的结果。基于时间的滑动窗口聚合了最后 N 秒的调用结果。
5.2、断路器3大状态之间的转换

5.3、断路器所有配置参数参考
| Config 属性 | 默认值 | 描述 |
|---|---|---|
| failureRateThreshold | 50 | 以百分比为单位配置故障率阈值。 当故障率等于或大于阈值时,断路器将转换为开路并开始短路呼叫。 |
| slowCallRateThreshold | 100 | 以百分比为单位配置阈值。当呼叫持续时间大于 当慢速呼叫的百分比等于或大于阈值时,CircuitBreaker 将呼叫视为慢速呼叫,CircuitBreaker 将转换为开路并开始短路呼叫。slowCallDurationThreshold |
| slowCallDurationThreshold | 60000 [毫秒] | 配置持续时间阈值,超过该阈值将呼叫视为慢速,并增加慢速呼叫的速率。 |
| 允许NumberOfCalls InHalfOpenState | 10 | 配置断路器半开时允许的呼叫数。 |
| maxWaitDurationInHalfOpenState | 0 [毫秒] | 配置最大等待持续时间,该持续时间控制断路器在切换到打开状态之前可以保持半开状态的最长时间。 值 0 表示断路器将在半开放状态下无限等待,直到所有允许的调用都完成。 |
| slidingWindowType | COUNT_BASED | 配置滑动窗口的类型,该窗口用于在断路器关闭时记录呼叫结果。 滑动窗口可以是基于计数的,也可以是基于时间的。 如果滑动窗口COUNT_BASED,则记录并汇总最后的呼叫。 如果滑动窗口TIME_BASED,则记录并汇总最后几秒的调用。slidingWindowSize``slidingWindowSize |
| slidingWindowSize | 100 | 配置滑动窗口的大小,该窗口用于在断路器关闭时记录呼叫结果。 |
| minimumNumberOfCalls | 100 | 配置在断路器计算错误率或慢速呼叫率之前所需的最小呼叫数(每个滑动窗口周期)。 例如,如果 minimumNumberOfCalls 为 10,则必须至少记录 10 个呼叫,然后才能计算失败率。 如果只记录了 9 个呼叫,即使所有 9 个呼叫都失败,CircuitBreaker 也不会转换为打开。 |
| waitDurationInOpenState | 60000 [毫秒] | 断路器在从开路过渡到半开之前应等待的时间。 |
| automaticTransition FromOpenToHalfOpenEnabled | false | 如果设置为 true,则表示 CircuitBreaker 将自动从开路状态转换为半开状态,并且无需调用即可触发转换。创建一个线程来监视 CircuitBreakers 的所有实例,以便在 waitDurationInOpenState 通过后将它们转换为HALF_OPEN。然而,如果设置为 false,则仅在进行调用时才会转换为 HALF_OPEN,即使在传递 waitDurationInOpenState 之后也是如此。这样做的优点是没有线程监控所有断路器的状态。 |
| recordExceptions | null | 记录为失败并因此增加失败率的异常列表。 任何匹配或从其中一个列表继承的异常都算作失败,除非通过 显式忽略。 如果指定异常列表,则所有其他异常都算作成功,除非 显式忽略这些异常。ignoreExceptions``ignoreExceptions |
| ignoreExceptions | null | 被忽略且既不算作失败也不算成功的异常列表。 任何匹配或继承自某个列表的异常都不会被视为失败或成功,即使异常是 的一部分。recordExceptions |
| recordFailurePre谓词 | throwable -> true :默认情况下,所有异常都作为失败进行重新验证。 | 一个自定义谓词,用于评估是否应将异常记录为失败。 如果异常应计为失败,则谓词必须返回 true。如果异常 应计为成功,则谓词必须返回 false,除非 显式忽略该异常。ignoreExceptions |
| ignoreExceptionPredicate | throwable -> false 默认情况下,不会忽略任何异常。 | 一个自定义谓词,用于评估是否应忽略异常,并且既不计为失败也不计为成功。 如果应忽略异常,则 Predicate 必须返回 true。 如果异常应计为失败,则 Predicate 必须返回 false。 |
这些配置值都在CircuitBreaker.java配置类中,其中我们主要使用以下配置(精简版的):
| failure-rate-threshold | 以百分比配置失败率峰值 |
|---|---|
| sliding-window-type | 断路器的滑动窗口期类型 可以基于“次数”(COUNT_BASED)或者“时间”(TIME_BASED)进行熔断,默认是COUNT_BASED。 |
| sliding-window-size | **若COUNT_BASED,则10次调用中有50%失败(即5次)打开熔断断路器;**若为TIME_BASED则,此时还有额外的两个设置属性,含义为:在N秒内(sliding-window-size)100%(slow-call-rate-threshold)的请求超过N秒(slow-call-duration-threshold)打开断路器。 |
| slowCallRateThreshold | 以百分比的方式配置,断路器把调用时间大于slowCallDurationThreshold的调用视为慢调用,当慢调用比例大于等于峰值时,断路器开启,并进入服务降级。 |
| slowCallDurationThreshold | 配置调用时间的峰值,高于该峰值的视为慢调用。 |
| permitted-number-of-calls-in-half-open-state | 运行断路器在HALF_OPEN状态下时进行N次调用,如果故障或慢速调用仍然高于阈值,断路器再次进入打开状态。 |
| minimum-number-of-calls | 在每个滑动窗口期样本数,配置断路器计算错误率或者慢调用率的最小调用数。比如设置为5意味着,在计算故障率之前,必须至少调用5次。如果只记录了4次,即使4次都失败了,断路器也不会进入到打开状态。 |
| wait-duration-in-open-state | 从OPEN到HALF_OPEN状态需要等待的时间 |
5.4、案例说明
后面要做的需求:
# 6次访问中当执行方法的失败率达到50%时CircuitBreaker将进入开启OPEN状态(保险丝跳闸断电)拒绝所有请求。
# 等待5秒后,CircuitBreaker 将自动从开启OPEN状态过渡到半开HALF_OPEN状态,允许一些请求通过以测试服务是否恢复正常。
# 如还是异常CircuitBreaker 将重新进入开启OPEN状态;如正常将进入关闭CLOSE闭合状态恢复正常处理请求。

5.5、按照COUNT_BASED(计数的滑动窗口)
修改cloud-provider-payment8001,新建PayCircuitController类
@RestController
public class PayCircuitController {
//=========Resilience4j CircuitBreaker 的例子
@GetMapping("/pay/circuit/{id}")
public String myCircuit(@PathVariable("id") Integer id){
if (id == -1) throw new RuntimeException("---------circuit id 不能为负数");
if (id == 9999){
try { TimeUnit.SECONDS.sleep(5); } catch (InterruptedException e) { e.printStackTrace(); }
}
return "Hello, circuit! inputId: "+id+" \t " + IdUtil.simpleUUID();
}
}
到公共API模块中添加对应接口。
//=========Resilience4j CircuitBreaker 的例子
@GetMapping("/pay/circuit/{id}")
public String myCircuit(@PathVariable("id") Integer id);
我们的断路配置要装到消费者那里,因为家里的保险丝就是装家里电闸嘛,下面修改pom导入依赖。
<!--resilience4j-circuitbreaker-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-circuitbreaker-resilience4j</artifactId>
</dependency>
<!-- 由于断路保护等需要AOP实现,所以必须导入AOP包 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
修改一下配置文件application.yml
server:
port: 80
spring:
application:
name: cloud-consumer-openfeign-order
####Spring Cloud Consul for Service Discovery
cloud:
consul:
host: localhost
port: 8500
discovery:
prefer-ip-address: true #优先使用服务ip进行注册
service-name: ${spring.application.name}
openfeign:
client:
config:
# default:
# connectTimeout: 3000 #连接超时时间
# readTimeout: 3000 #读取超时时间
cloud-payment-service:
connectTimeout: 20000
readTimeout: 20000
httpclient:
hc5:
enabled: true
compression:
request:
enabled: true
min-request-size: 2048 #最小触发压缩的大小
mime-types: text/xml,application/xml,application/json #触发压缩数据类型
response:
enabled: true
# 开启circuitbreaker和分组激活 spring.cloud.openfeign.circuitbreaker.enabled
circuitbreaker:
enabled: true
group:
enabled: true #没开分组永远不用分组的配置。精确优先、分组次之(开了分组)、默认最后
# Resilience4j CircuitBreaker 按照次数:COUNT_BASED 的例子
# 6次访问中当执行方法的失败率达到50%时CircuitBreaker将进入开启OPEN状态(保险丝跳闸断电)拒绝所有请求。
# 等待5秒后,CircuitBreaker 将自动从开启OPEN状态过渡到半开HALF_OPEN状态,允许一些请求通过以测试服务是否恢复正常。
# 如还是异常CircuitBreaker 将重新进入开启OPEN状态;如正常将进入关闭CLOSE闭合状态恢复正常处理请求。
resilience4j:
circuitbreaker:
configs:
default:
failureRateThreshold: 50 #设置50%的调用失败时打开断路器,超过失败请求百分⽐CircuitBreaker变为OPEN状态。
slidingWindowType: COUNT_BASED # 滑动窗口的类型
slidingWindowSize: 6 #滑动窗⼝的⼤⼩配置COUNT_BASED表示6个请求,配置TIME_BASED表示6秒
minimumNumberOfCalls: 6 #断路器计算失败率或慢调用率之前所需的最小样本(每个滑动窗口周期)。如果minimumNumberOfCalls为10,则必须最少记录10个样本,然后才能计算失败率。如果只记录了9次调用,即使所有9次调用都失败,断路器也不会开启。
automaticTransitionFromOpenToHalfOpenEnabled: true # 是否启用自动从开启状态过渡到半开状态,默认值为true。如果启用,CircuitBreaker将自动从开启状态过渡到半开状态,并允许一些请求通过以测试服务是否恢复正常
waitDurationInOpenState: 5s #从OPEN到HALF_OPEN状态需要等待的时间
permittedNumberOfCallsInHalfOpenState: 2 #半开状态允许的最大请求数,默认值为10。在半开状态下,CircuitBreaker将允许最多permittedNumberOfCallsInHalfOpenState个请求通过,如果其中有任何一个请求失败,CircuitBreaker将重新进入开启状态。
recordExceptions:
- java.lang.Exception
instances:
cloud-payment-service:
baseConfig: default
# feign日志以什么级别监控哪个接口
#logging:
# level:
# com:
# zm:
# cloud:
# apis:
# PayFeignApi: debug
新建OrderCircuitController
package com.zm.cloud.controller;
import com.zm.cloud.apis.PayFeignApi;
import io.github.resilience4j.circuitbreaker.annotation.CircuitBreaker;
import jakarta.annotation.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class OrderCircuitController {
@Resource
private PayFeignApi payFeignApi;
@GetMapping("/feign/pay/circuit/{id}")
@CircuitBreaker(name = "cloud-payment-service",fallbackMethod = "myCircuitFallback")
public String myCircuitBreaker(@PathVariable("id") Integer id){
return payFeignApi.myCircuit(id);
}
//myCircuitFallback就是服务降级后的兜底处理方法
public String myCircuitFallback(Integer id,Throwable t) {
// 这里是容错处理逻辑,返回备用结果
return "myCircuitFallback,温馨提醒:系统繁忙,请稍后再试-----/(ㄒoㄒ)/~~";
}
}
启动服务,我们在浏览器中一次输入正确的一次输入错误的,交替请求看会发生什么。
正常情况下,访问正确的出来正确的,访问错误的就到友好界面了,但我们交替着访问当错误数达到3次后再访问正确的,正确的地址就会也到友好界面了,这个时候还在OPEN状态断路,过5秒就到半开状态并继续正常访问,慢慢切换回CLOSED状态,就能正常访问。
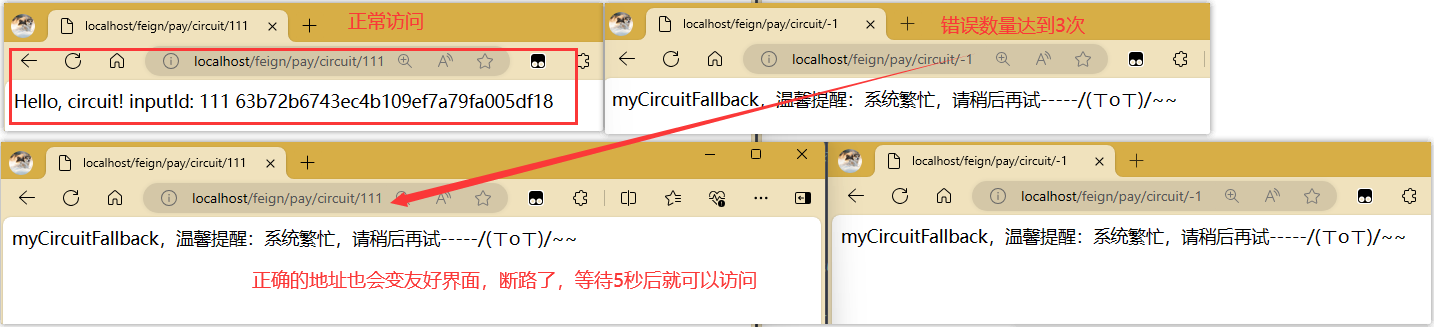
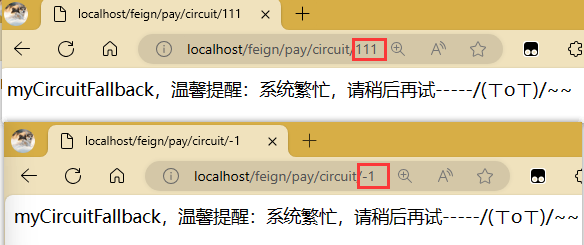
还有就是我们直接开始就一直访问错误的,这个时候你再访问正确的地址就会直接fallback。
5.6、按照TIME_BASED(基于时间的滑动窗口)
再次修改配置文件
resilience4j:
timelimiter:
configs:
default:
timeout-duration: 10s #神坑的位置,timelimiter 默认限制远程1s,超于1s就超时异常,配置了降级,直接就走降级逻辑了不会看到后面的配置效果
circuitbreaker:
configs:
default:
failureRateThreshold: 50 #设置50%的调用失败时打开断路器,超过失败请求百分⽐CircuitBreaker变为OPEN状态。
slowCallDurationThreshold: 2s #慢调用时间阈值,高于这个阈值的视为慢调用并增加慢调用比例。
slowCallRateThreshold: 30 #慢调用百分比峰值,断路器把调用时间⼤于slowCallDurationThreshold,视为慢调用,当慢调用比例高于阈值,断路器打开,并开启服务降级
slidingWindowType: TIME_BASED # 滑动窗口的类型
slidingWindowSize: 2 #滑动窗口的大小配置,配置TIME_BASED表示2秒
minimumNumberOfCalls: 2 #断路器计算失败率或慢调用率之前所需的最小样本(每个滑动窗口周期)。
permittedNumberOfCallsInHalfOpenState: 2 #半开状态允许的最大请求数,默认值为10。
waitDurationInOpenState: 5s #从OPEN到HALF_OPEN状态需要等待的时间
recordExceptions:
- java.lang.Exception
instances:
cloud-payment-service:
baseConfig: default
把原来我们配置的超时重试给注释掉,不要在后台报错,然后重启80测试。
测试:一个正常访问的,一个慢调用的。
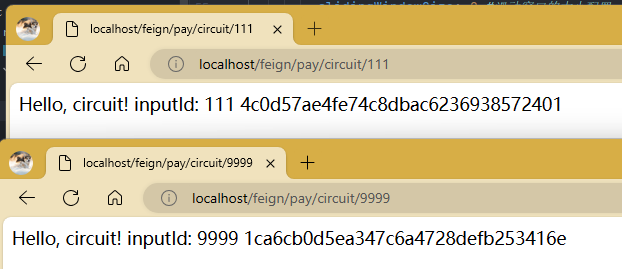
现在是正常访问没问题,还没有触发熔断。我再开三个慢调用标签页然后同时开始。

会发现这几个页面全是fallback友好界面了,正常的那个也是,不过过一会就可以正常访问了。
5.7、总结
断路器开启或者关闭的条件
- 当满足一定的峰值和失败率达到一定条件后,断路器将会进入OPEN状态(断路)服务熔断;
- 当OPEN的时候,所有请求都不会调用主业务逻辑方法,而是直接中fallback方法兜底,服务降级;
- 当一段时间过后,这个时候断路器会从OPEN状态进入HALF_OPEN半开状态,会放过几个请求过去探一下路,如果成功,断路器会恢复到CLOSE状态就可以正常访问了,如果失败还继续,这几个探路的请求都失败就没办法了回到OPEN状态过一会再试;
- TIME_BASED和COUNT_BASED不要混用,比较建议使用count;
6、隔离(BulkHead)
6.1、BulkHead是什么?
Resilience4j提供了两种隔离的实现方式,可以限制并发执行的数量。
SemaphoreBulkhead使用了信号量;FixedThreadPoolBulkhead使用了有界队列和固定大小线程池;
SemaphoreBulkhead可以在各种线程和I/O模型上正常工作。与Hystrix不同,它不提供基于shadow的thread选项。由客户端来确保正确的线程池大小与隔离配置一致。
它就是限制并发的,依赖隔离和负载保护:用来限制对于下游服务的最大并发数量的限制。
你可以提供一个自定义的全局BulkheadConfig,你可以使用BulkheadConfig建造者模式来创建自定义的全局BulkheadConfig,可以使用builder来配置下面的属性。
| 配置属性 | 默认值 | 描述 |
|---|---|---|
| maxConcurrentCalls | 25 | 隔离允许线程并发执行的最大数量 |
| maxWaitDuration | 0 | 当达到并发调用数量时,新的线程执行时将被阻塞,这个属性表示最长的等待时间。 |
6.2、实现SemaphoreBulkhead(信号量舱壁)
基本上就是我们JUC信号灯内容的同样思想
信号量舱壁(SemaphoreBulkhead)原理:当信号量有空闲时,进入系统的请求会直接获取信号量并开始业务处理。
当信号量全被占用时,接下来的请求将会进入阻塞状态,SemaphoreBulkhead提供了一个阻塞计时器,如果阻塞状态的请求在阻塞计时内无法获取到信号量则系统会拒绝这些请求。
若请求在阻塞计时内获取到了信号量,那将直接获取信号量并执行相应的业务处理。
其实SemaphoreBulkhead的低子还是JUC中的Semaphore类。
修改8001微服务的PayCircuitController,添加这次测试的controller
//=========Resilience4j bulkhead 的例子
@GetMapping(value = "/pay/bulkhead/{id}")
public String myBulkhead(@PathVariable("id") Integer id)
{
if(id == -4) throw new RuntimeException("----bulkhead id 不能-4");
if(id == 9999)
{
try { TimeUnit.SECONDS.sleep(5); } catch (InterruptedException e) { e.printStackTrace(); }
}
return "Hello, bulkhead! inputId: "+id+" \t " + IdUtil.simpleUUID();
}
修改PayFeignApi接口新增舱壁的方法。
//=========Resilience4j bulkhead 的例子
@GetMapping(value = "/pay/bulkhead/{id}")
public String myBulkhead(@PathVariable("id") Integer id);
在80中添加舱壁依赖。
<!--resilience4j-bulkhead-->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-bulkhead</artifactId>
</dependency>
修改配置文件,添加舱壁配置,先把原来的熔断配置暂时注释掉。
####resilience4j bulkhead 的例子
resilience4j:
bulkhead:
configs:
default:
maxConcurrentCalls: 2 # 隔离允许并发线程执行的最大数量
maxWaitDuration: 1s # 当达到并发调用数量时,新的线程的阻塞时间,我只愿意等待1秒,过时不候进舱壁兜底fallback
instances:
cloud-payment-service:
baseConfig: default
timelimiter:
configs:
default:
timeout-duration: 20s
业务类OrderCircuitController
//舱壁隔离
@GetMapping("/feign/pay/bulkhead/{id}")
@Bulkhead(name = "cloud-payment-service",fallbackMethod = "myBulkheadFallback",type = Bulkhead.Type.SEMAPHORE)
public String myBulkhead(@PathVariable("id") Integer id)
{
return payFeignApi.myBulkhead(id);
}
public String myBulkheadFallback(Throwable t)
{
return "myBulkheadFallback,隔板超出最大数量限制,系统繁忙,请稍后再试-----/(ㄒoㄒ)/~~";
}
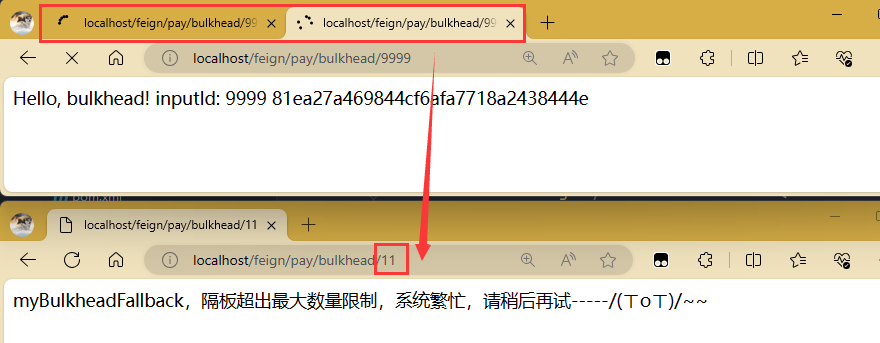
浏览器新打开2个窗口,各点一次,分别点击http://localhost/feign/pay/bulkhead/9999,每个请求调用需要耗时5秒,2个线程瞬间达到配置过的最大并发数2,此时第3个请求正常的请求访问,http://localhost/feign/pay/bulkhead/3,直接被舱壁限制隔离了,碰不到8001。
等到那俩时间长的其中一个到时间了,并发数小于2了,就能访问了
过一会就正常
6.3、实现FixedThreadPoolBulkhead(固定线程池舱壁)
基本上就是我们JUC-线程池内容的同样思想,低子就是JUC里面的线程池ThreadPoolExecutor。


submit进程池返回CompletableFuture
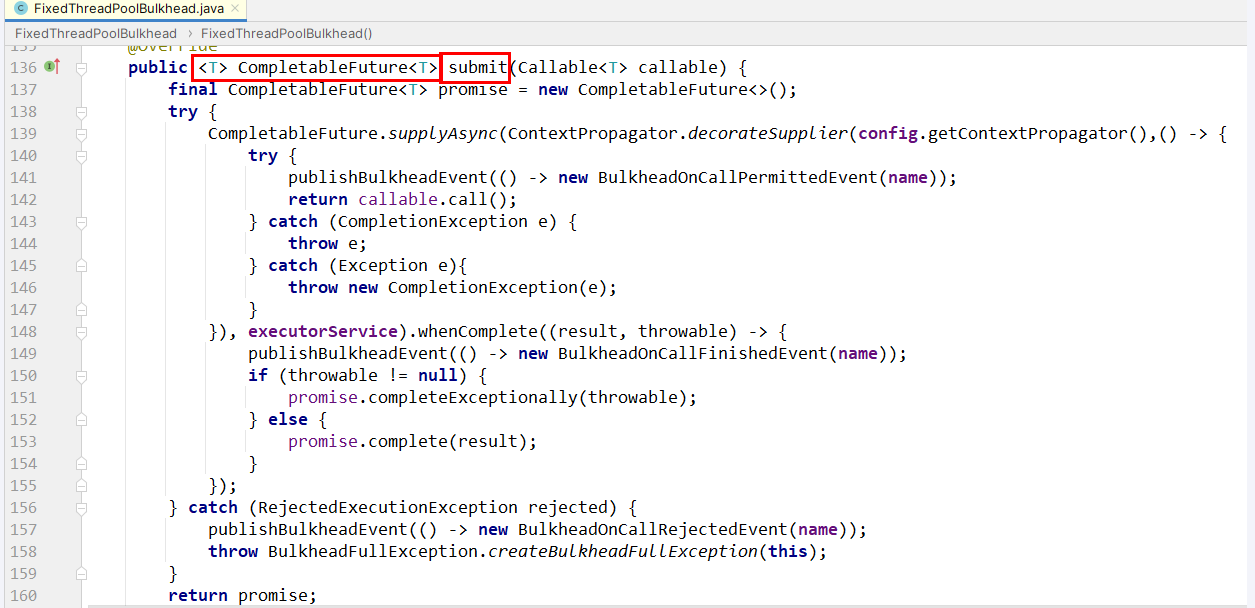
固定线程池舱壁(FixedThreadPoolBulkhead)FixedThreadPoolBulkhead的功能与SemaphoreBulkhead一样也是用于限制并发执行的次数的,但是二者的实现原理存在差别而且表现效果也存在细微的差别。FixedThreadPoolBulkhead使用一个固定线程池和一个等待队列来实现舱壁。
当线程池中存在空闲时,则此时进入系统的请求将直接进入线程池开启新线程或使用空闲线程来处理请求。当线程池中无空闲时时,接下来的请求将进入等待队列,若等待队列仍然无剩余空间时接下来的请求将直接被拒绝,在队列中的请求等待线程池出现空闲时,将进入线程池进行业务处理。
另外:ThreadPoolBulkhead只对CompletableFuture方法有效,所以我们必创建返回CompletableFuture类型的方法
线程池底层工作原理:

配置80微服务配置文件修改。
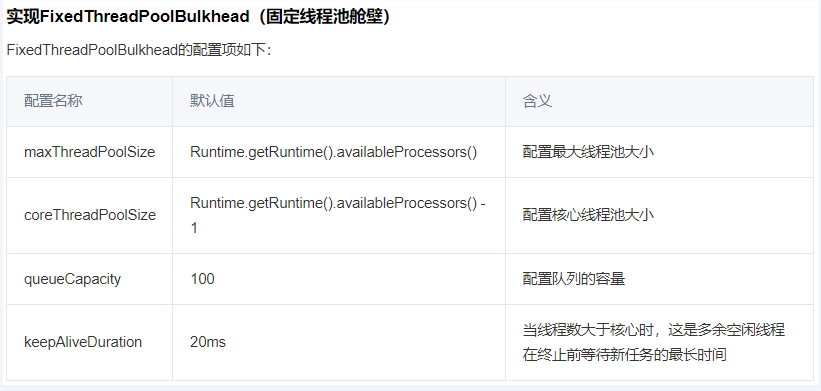
配置文件cloud-consumer-feign-order80的application.yml配置
resilience4j:
timelimiter:
configs:
default:
timeout-duration: 20s
# bulkhead:
# configs:
# default:
# maxConcurrentCalls: 2 # 隔离允许并发线程执行的最大数量
# maxWaitDuration: 1s # 当达到并发调用数量时,新的线程的阻塞时间,我只愿意等待1秒,过时不候进舱壁兜底fallback
thread-pool-bulkhead:
configs:
default:
core-thread-pool-size: 1 #核心线程池大小
max-thread-pool-size: 1 #最大线程池大小max-thread-pool-size中包含了core-thread-pool-size,加上队列里的1个所以只能同时有2个线程,第三个就要阻塞报错callback
queue-capacity: 1 #队列的容量
instances:
cloud-payment-service:
baseConfig: default
cloud-consumer-feign-order80的controller新增舱壁线程池测试内容
//舱壁线程池
@GetMapping("/feign/pay/poolBulkhead/{id}")
@Bulkhead(name = "cloud-payment-service",fallbackMethod = "myPoolBulkheadFallback",type = Bulkhead.Type.THREADPOOL)
public CompletableFuture<String> poolBulkhead(@PathVariable("id") Integer id)
{
System.out.println(Thread.currentThread().getName()+"\t"+"enter the method!!!");
try { TimeUnit.SECONDS.sleep(3); } catch (InterruptedException e) { e.printStackTrace(); }
System.out.println(Thread.currentThread().getName()+"\t"+"enter the method!!!");
return CompletableFuture.supplyAsync(() -> payFeignApi.myBulkhead(id) +"\t"+"Bulkhead.Type.THREADPOOL");
}
public CompletableFuture<String> myPoolBulkheadFallback(Integer id,Throwable t)
{
return CompletableFuture.supplyAsync(() -> "Bulkhead.Type.THREADPOOL,系统繁忙,请稍后再试-----/(ㄒoㄒ)/~~");
}
测试,同时发起两个请求然后再开一个,看第三个就是被拒绝了。
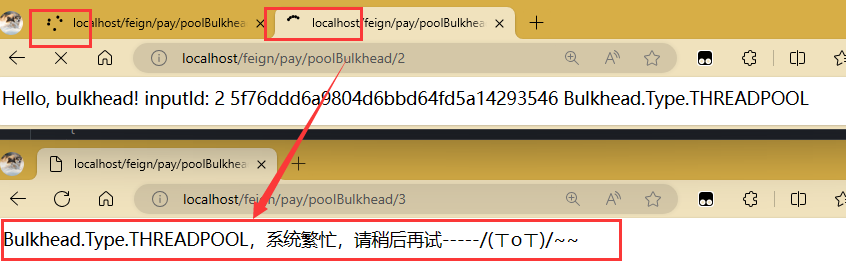
等其中有位置了就能继续正常访问了。
7、限流(RateLimiter)
7.1、概述
限流是一种必不可少的技术,可以帮助您的API进行扩展,并建立服务的高可用性和可靠性。但是,这项技术还附带了一堆不同的选项,比如如何处理检测到的多余流量,或者您希望限制什么类型的请求。您可以简单地拒绝这个超限请求,或者构建一个队列以稍后执行它们,或者以某种方式组合这两种方法。
Resilience4j提供了一个限流器,它将从epoch开始的所有纳秒划分为多个周期。每个周期的持续时间RateLimiterConfig.limitRefreshPeriod。在每个周期开始时,限流器将活动权限数设置为RateLimiterConfig.limitForPeriod。期间, 对于限流器的调用者,它看起来确实是这样的,但是对于AtomicRateLimiter实现,如果RateLimiter未被经常使用,则会在后台进行一些优化,这些优化将跳过此刷新。
限流器的默认实现是AtomicRateLimiter,它通过原子引用管理其状态。这个AtomicRateLimiter状态完全不可变,并且具有以下字段:
- activeCycle -上次调用的周期号
- activePermissions -在上次调用结束后,可用的活跃权限数。如果保留了某些权限,则可以为负。
- nanosToWait - 最后一次调用要等待的纳秒数
还有一个使用信号量的SemaphoreBasedRateLimiter和一个调度程序,它将在每个RateLimiterConfig#limitRefreshPeriod之后刷新活动权限数。
所谓限流,就是通过对并发访问/请求进行限速,或者对一个时间窗口内的请求进行限速,以保护应用系统,一旦达到限制速率则可以拒绝服务、排队或等待、降级等处理。
7.2、常见限流算法
7.2.1、漏洞算法(Leaky Bucket)
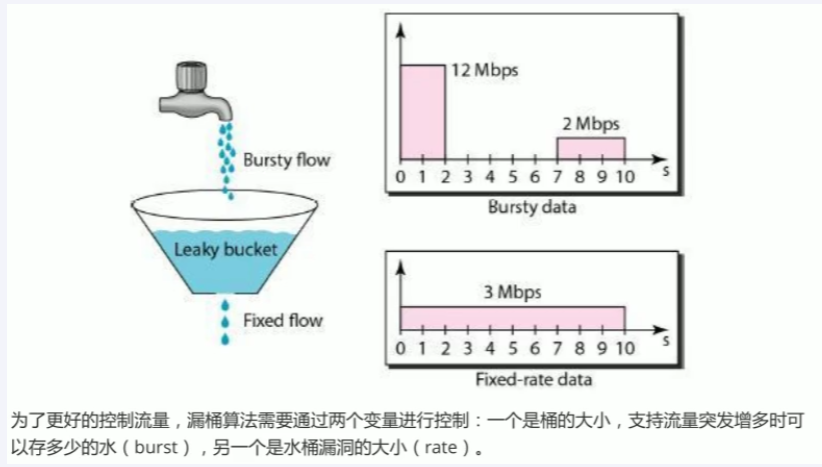
一个固定容量的漏桶,按照设定常量固定速率流出水滴,类似医院打吊针,不管你源头流量多大,我设定匀速流出。 如果流入水滴超出了桶的容量,则流入的水滴将会溢出了(被丢弃),而漏桶容量是不变的。
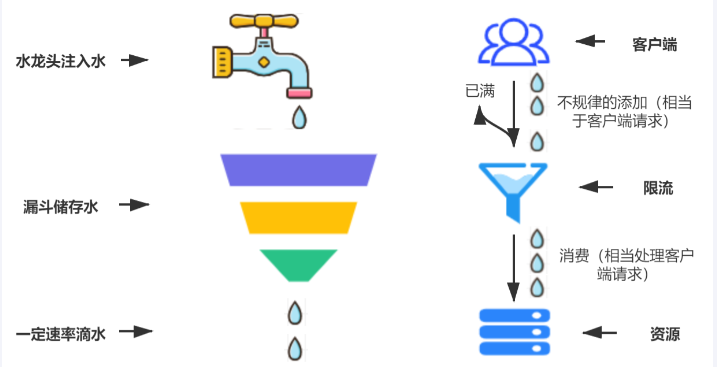
**缺点:**这里有两个变量,一个是桶的大小,支持流量突发增多时可以存多少的水(burst),另一个是水桶漏洞的大小(rate)。因为漏桶的漏出速率是固定的参数,所以,即使网络中不存在资源冲突(没有发生拥塞),漏桶算法也不能使流突发(burst)到端口速率。因此,漏桶算法对于存在突发特性的流量来说缺乏效率。
7.2.2、令牌算法(Token Bucket)
令牌算法是SpringCloud默认使用的,其核心思想是维护一个固定容量的令牌桶,并以固定的速率生成令牌。每当有请求到来时,必须从令牌桶中取走一个令牌,只有取到令牌的请求才能被处理。
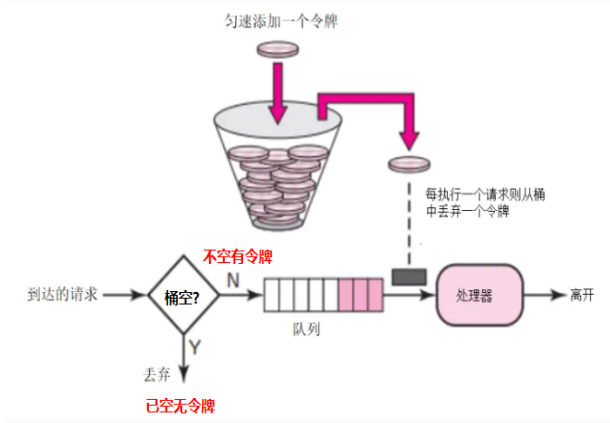
令牌算法具有以下特点:
- 稳定的速率控制:通过控制令牌的生成速率,可以实现对请求处理速率的稳定控制。
- 允许短时突发请求:由于令牌桶有一定的容量,因此可以缓存一定数量的令牌,以应对短时内的突发请求。
在令牌算法中,有几个重要的参数:
- 桶的容量:决定了可以缓存的令牌数量,从而影响了算法应对突发请求的能力。
- 令牌的生成速率:决定了请求处理的平均速率。这个速率通常根据实际需求进行配置。
- Burst size(Bc):一次性加进令牌桶的令牌数量。它决定了在令牌桶未满时,每次添加令牌的数量。
- Time interval(Tc):表示多久往桶里加一次令牌。这个时间间隔通常由令牌生成速率和Burst size共同决定。
令牌算法的实现方式相对简单,通常包括以下步骤:
- 每秒生成一定数量的令牌,并将它们放入令牌桶中。
- 当请求到达时,尝试从令牌桶中取走一个令牌。
- 如果令牌桶中有足够的令牌,则处理该请求;否则,请求被拒绝或进入队列等待。
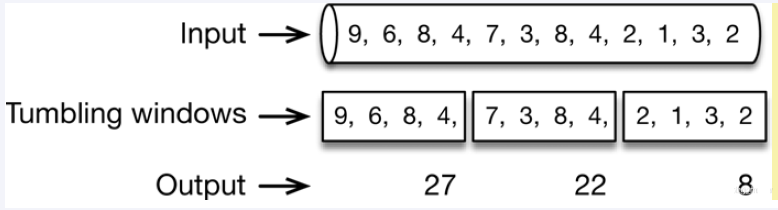
7.2.3、滚动时间窗(tumbling time window)
允许固定数量的请求进入(比如1秒取4个数据相加,超过25值就over)超过数量就拒绝或者排队,等下一个时间段进入。
由于是在一个时间间隔内进行限制,如果用户在上个时间间隔结束前请求(但没有超过限制),同时在当前时间间隔刚开始请求(同样没超过限制),在各自的时间间隔内,这些请求都是正常的。
缺点:间隔临界的一段时间内的请求就会超过系统限制,可能导致系统被压垮
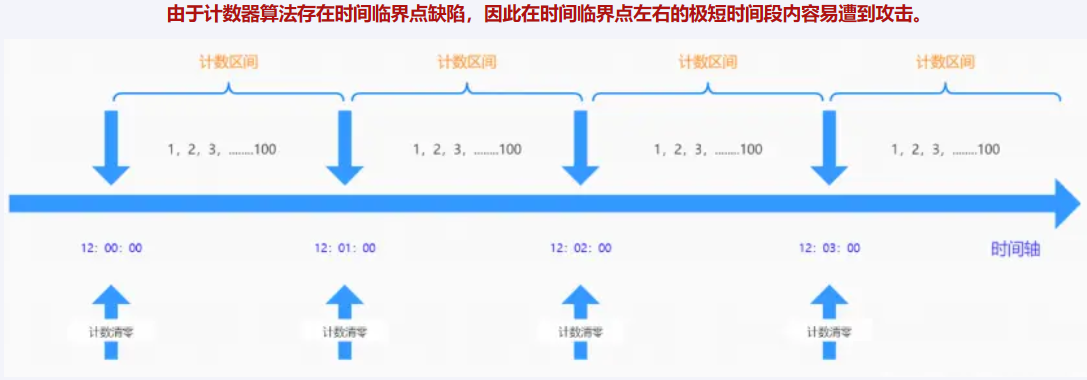
假如设定1分钟最多可以请求100次某个接口,如12:00:00-12:00:59时间段内没有数据请求但12:00:59-12:01:00时间段内突然并发100次请求,紧接着瞬间跨入下一个计数周期计数器清零;在12:01:00-12:01:01内又有100次请求。那么也就是说在时间临界点左右可能同时有2倍的峰值进行请求,从而造成后台处理请求加倍过载的bug,导致系统运营能力不足,甚至导致系统崩溃…
7.2.4、滑动时间窗口(sliding time window)(重要)
顾名思义,该时间窗口是滑动的。所以,从概念上讲,这里有两个方面的概念需要理解:
- 窗口:需要定义窗口的大小
- 滑动:需要定义在窗口中滑动的大小,但理论上讲滑动的大小不能超过窗口大小
滑动窗口算法是把固定时间片进行划分并且随着时间移动,移动方式为开始时间点变为时间列表中的第2个时间点,结束时间点增加一个时间点,不断重复,通过这种方式可以巧妙的避开计数器的临界点的问题。下图统计了5次
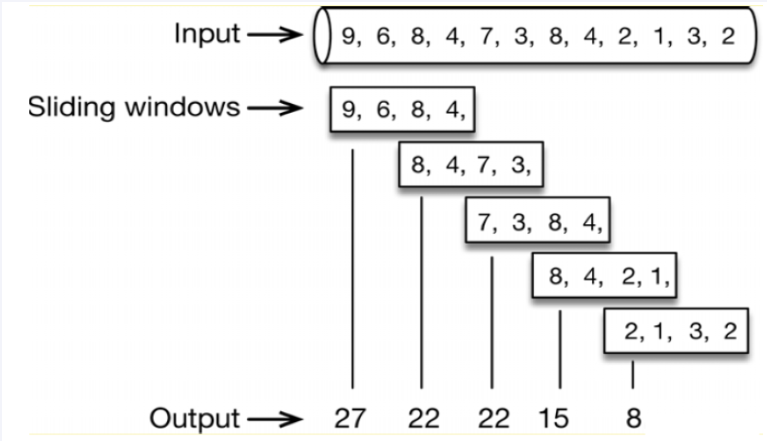
7.3、演示
cloud-provider-payment8001支付微服务修改PayCircuitcontroller新增myRatelimit方法
//=========Resilience4j ratelimit 的例子
@GetMapping(value = "/pay/ratelimit/{id}")
public String myRatelimit(@PathVariable("id") Integer id)
{
return "Hello, myRatelimit欢迎到来 inputId: "+id+" \t " + IdUtil.simpleUUID();
}
PayFeignApi接口新增限流api方法
//=========Resilience4j ratelimit 的例子
@GetMapping(value = "/pay/ratelimit/{id}")
public String myRatelimit(@PathVariable("id") Integer id)
修改cloud-consumer-feign-order80,增加ratelimiter依赖
<!--resilience4j-ratelimiter-->
<dependency>
<groupId>io.github.resilience4j</groupId>
<artifactId>resilience4j-ratelimiter</artifactId>
</dependency>
写配置文件增加限流的配置。
####resilience4j ratelimiter 限流的例子
resilience4j:
ratelimiter:
configs:
default:
limitForPeriod: 2 #在一次刷新周期内,允许执行的最大请求数
limitRefreshPeriod: 1s # 限流器每隔limitRefreshPeriod刷新一次,将允许处理的最大请求数量重置为limitForPeriod
timeout-duration: 1 # 线程等待权限的默认等待时间
instances:
cloud-payment-service:
baseConfig: default
order的controller
@GetMapping(value = "/feign/pay/ratelimit/{id}")
@RateLimiter(name = "cloud-payment-service",fallbackMethod = "myRatelimitFallback")
public String myBulkhead(@PathVariable("id") Integer id)
{
return payFeignApi.myRatelimit(id);
}
public String myRatelimitFallback(Integer id,Throwable t)
{
return "你被限流了,禁止访问/(ㄒoㄒ)/~~";
}
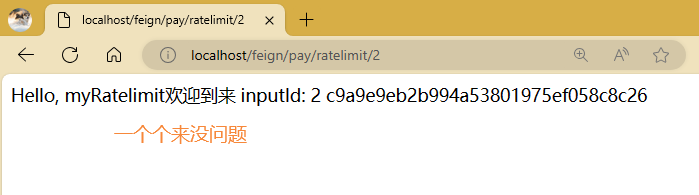
测试的时候,我们一个一个慢慢的访问是没有问题的,但是你疯狂刷新的话就会被限流。
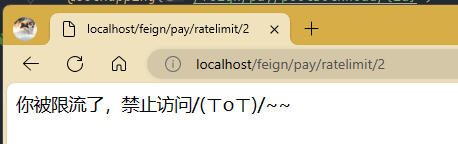
疯狂刷新就被限流。

![每日一题 --- 27. 移除元素 - 力扣 [Go]](https://img-blog.csdnimg.cn/direct/edb3655aca7349ed941562b162820103.png)