目录
- 1 前言
- 2 传输层
- 2.1 端口号
- 2.2 UDP
- 2.3 TCP
- 3 网络层
- 3.1 IP
- 4 数据链路层
- 4.1 以太网
- 4.2 ARP
- 5 DNS
- 6 NAT
1 前言

2 传输层
2.1 端口号
端口号又分为:
- 知名端口:知名程序在启动之后占用的端口号,0-1023。 HTTP, FTP, SSH等这些广为使用的应用层协议, 他们的端口号都是固定的。

- 动态端口号:操作系统动态分配的端口号,1024-65535,最大端口号就是65535。客户端程序的端口号, 就是由操作系统从这个范围分配的。
两个程序能不能使用同一个端口号?不行。
一个程序能不能使用两个端口号?可以。
2.2 UDP
UDP协议数据格式:

16位源端口号:源程序的端口号,根据这个端口号可以定位发送端程序。
16位目的端口号:目标端口号,根据这个端口号可以定位接收端的应用程序。
16位UDP长度:16位长度=UDP头部长度+UDP数据的长度。
16位UDP检验和:检验数据正确性。
检验和执行逻辑:
假设校验和的算法是MD5,MD5(UDP头部长度+UDP数据的长度)。
发送端会将UDP所有内容发送给接收端,此时接收端就有了UDP的校验和和所有的数据,接收端就可以根据(UDP头部长度+UDP数据的长度)进行一个MD5方法,得到一个正确的校验和,然后用这个正确校验和和UDP头部信息中的校验和对比,如果相等则表示数据是正确的;否则数据就是错误的,直接舍弃就行了。
UDP的特点: UDP传输的过程类似于寄信。
- 无连接: 知道对端的IP和端口号就直接进行传输, 不需要建立连接;
- 不可靠: 没有确认机制, 没有重传机制; 如果因为网络故障该段无法发到对方, UDP协议层也不会给应用层返回任何错误信息;
- 面向数据报: 不能够灵活的控制读写数据的次数和数量。
面向数据报:应用层交给UDP多长的报文, UDP原样发送, 既不会拆分, 也不会合并。
用UDP传输100个字节的数据:如果发送端调用一次sendto, 发送100个字节, 那么接收端也必须调用对应的一次recvfrom, 接收100个字节; 而不能循环调用10次recvfrom, 每次接收10个字节。
UDP的缓冲区: UDP只有接收缓冲区,没有发送缓冲区。
- UDP没有真正意义上的 发送缓冲区,调用sendto会直接交给内核, 由内核将数据传给网络层协议进行后续的传输动作。
UDP之所以不需要发送缓冲区,是因为UDP是不需要连接的,也就是不需要等待对方先连接的,所以最快的工作方式就是拿到信息就发。 - UDP具有接收缓冲区,但是这个接收缓冲区不能保证收到的UDP报的顺序和发送UDP报的顺序一致; 如果缓冲区满了, 再到达的UDP数据就会被丢弃。
UDP必须要有接收缓冲区,可以大大提高UDP的工作效率。
TCP既有接收缓冲区,也有发送缓冲区。
全双工和半双工:
- UDP的socket既能读, 也能写, 这个概念叫做 全双工。全双工也就是发送端或者接收端既可以发送消息又可以接收消息。
- 半双工指的是发送端只能发送消息,不能接收消息。
- TCP和UDP都是全双工。
UDP使用注意事项:
因为UDP协议头部中有一个16位的最大长度,也就是说一个UDP能传输的数据最大长度是64K(包含UDP首部)。
然而64K在当今的互联网环境下, 是一个非常小的数字,如果我们需要传输的数据超过64K, 就需要在应用层手动的分包, 多次发送, 并在接收端手动拼装(程序员自己操作);或者以大包的方式去发,在数据链路层进行分包和组包(交给协议自动处理)。
实际工作中,会采用第一种方式,也就是应用层组包和分包来实现UDP大数据的传递,如果使用了第二种方式,那么任意一个包丢失之后,那么整个数据包也就丢失了,风险极大(网络环境非常复杂),所以不会使用第二种方式。
基于UDP的应用层协议:
- NFS: 网络文件系统。
- TFTP: 简单文件传输协议。
- DHCP: 动态主机配置协议。
- BOOTP: 启动协议(用于无盘设备启动)。
- DNS: 域名解析协议。
- 当然, 也包括你自己写UDP程序时自定义的应用层协议;
2.3 TCP
TCP全称为 “传输控制协议(Transmission Control Protocol”),人如其名,要对数据的传输进行一个详细的控制。
TCP协议数据格式: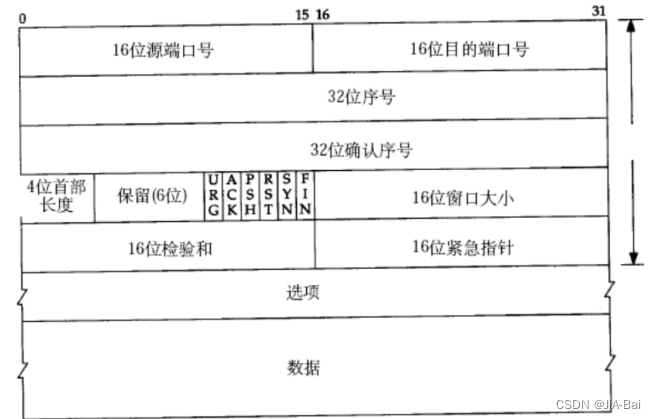
16位源端口号:源程序的端口号,根据这个端口号可以定位发送端程序。
16位目的端口号:目标端口号,根据这个端口号可以定位接收端的应用程序。
(也就是源/目的端口号: 表示数据是从哪个进程来, 到哪个进程去)
32位序号/32位确认号: 可以看作一个身份标识。
4位TCP报头长度: 表示该TCP头部有多少个32位bit(有多少个4字节); 所以TCP头部最大长度是15 * 4 = 60。
6位标志位:
URG: 紧急指针是否有效 ,表示紧急消息。
ACK: 确认号是否有效,确认应答表示。
PSH: 提示接收端应用程序立刻从TCP缓冲区把数据读走 。
RST:对方要求重新建立连接; 我们把携带RST标识的称为复位报文段。
SYN: 请求建立连接; 我们把携带SYN标识的称为同步报文段。
FIN:通知对方, 本端要关闭了, 我们称携带FIN标识的为结束报文段。
16位窗口大小: 不等于滑动窗口的大小,因为滑动窗口的值是固定不变的,因此不需要在信息传输中代入。它是接收缓冲区的窗口大小。
16位校验和: 检验数据正确性。发送端填充, CRC校验,接收端校验不通过, 则认为数据有问题。此处的检验和不光包含TCP首部, 也包含TCP数据部分。
16位紧急指针: 标识哪部分数据是紧急数据。
40字节头部选项: 用来在TCP里面做一些自己的业务时可以在头部里面添加一些自定义的选项,暂时忽略。
TCP的核心思想: 为了保证TCP的稳定性,所以才有了这么多的特性。
TCP的8大特性和一个问题:
- 确认应答(ACK)机制(TCP保证稳定性的核心机制)
- 超时重传(为了解决确认应答的非正常情况)
对于重复发生消息的问题,不用担心,因为系统(内核)会自动帮程序做去重操作。
所以TCP稳定性的核心 = 确认应答 + 超时重传。
超时重发策略1: 使用递增的发送时间。
TCP重发消息设计思路:如果第一次发送失败了,那么大概率第二次发送也会失败,为了节省带宽和程序的开销,那么它会采取递增的方式发送消息。例如:第一次发送失败后,那么会在10分钟之后再发送一次消息;第二次再发送消息的时候就会2 x 10分钟进行发送;第三次再发送消息的时候就会2 x 2 x 10分钟进行发送;
超时重发策略2: 最大尝试失败之后就会“停止”发送。
当经过了一定次数的发送之后,还是没有结果,那么发送端就会认为接收端下线了,就会“停止”发送了。即使已经确认对方下线了,那么还是会以固定的频率发送一个没有内容的检查包,来探测对方是否上线。
TCP为了保证无论在任何环境下都能比较高性能的通信, 因此会动态计算这个最大超时时间:
(1) Linux中(BSD Unix和Windows也是如此), 超时以500ms为一个单位进行控制, 每次判定超时重发的超时时间都是500ms的整数倍。
(2) 如果重发一次之后, 仍然得不到应答, 等待 2 x 500ms 后再进行重传。
(3) 如果仍然得不到应答, 等待 4 x 500ms 进行重传,依次类推, 以指数形式递增。
(4)累计到一定的重传次数, TCP认为网络或者对端主机出现异常, 强制关闭连接。 - 连接管理
连接:3次握手
断开乱接:4次挥手
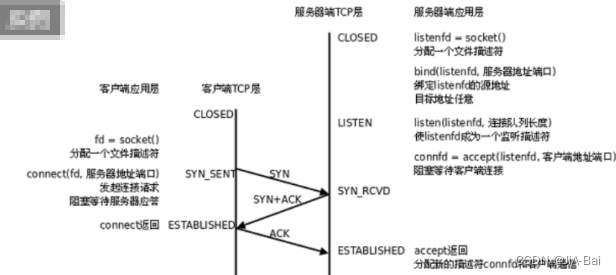
3次握手:
TCP特性:有连接。有连接必须要证明4个能力,这四个能力具备了才能有效进行通讯,即只有具备了以下四个能力之后,才能有效的进行TCP的连接。
能力1:发送方的发送能力。 能力2:发送方的接收能力。
能力3:接收方的发送能力。 能力4:接收方的接收能力。
这也是三次握手的核心指导思想。
三次握手其实也就是3次连接。
TCP的2次握手行不行?不行,因为不能完全验证发送端和接收端的发送和接收的能力。
TCP的4次握手行不行?行,但没有必要。
四次挥手:
四次挥手其实就是进行断开连接的一个过程。
TCP三次挥手行不行?有可能可以,关键看端口连接时,接收缓冲区有没有任务。如果没有任务,那么三次握手是可以的;但如果接收缓冲区有任务,3次挥手就不行了,必须要等到接收缓冲区的所有任务都执行完成之后,才能告诉对方,可以断开连接了。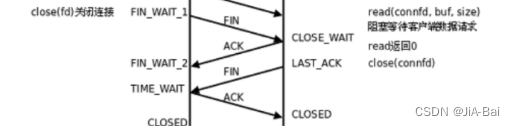 关于CLOSE_WAIT状态的说明:如果有多个CLOSE_WAIT状态,说明你的应用程序有bug,你的程序没有调用close()方法。
关于CLOSE_WAIT状态的说明:如果有多个CLOSE_WAIT状态,说明你的应用程序有bug,你的程序没有调用close()方法。
TIME_WAIT状态转换成CLOSED状态,要经过2MSL(最大生存时间)。因为TIME_WAIT = 等ACK到对方1MSL + FIN最大发送时间MSL。 - 滑动窗口
滑动窗口的目的就是为了保障传输的性能。
那么如果出现了丢包, 如何进行重传? 这里分两种情况讨论:
情况一: 数据包已经抵达, ACK被丢了
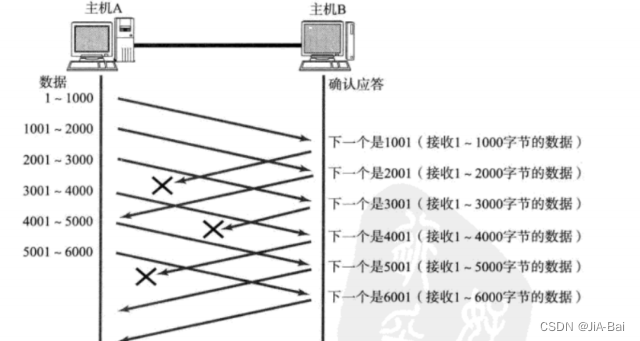
这种情况下, 部分ACK丢了并不要紧, 因为可以通过后续的ACK进行确认。也就是说当返回ACK=6001说明服务器端已经接收到了1-6000的数据了。ACK返回的是接收缓冲区的最大值。
情况二: 数据包就直接丢了
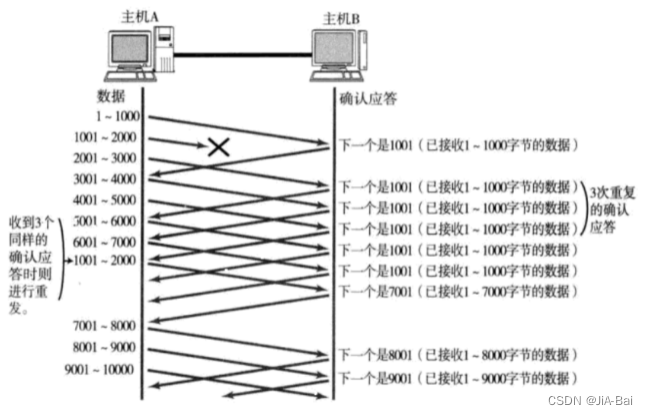
当某一段报文段丢失之后, 发送端会一直收到 1001 这样的ACK, 就像是在提醒发送端 “我想要的是 1001” 一样;如果发送端主机连续三次收到了同样一个 “1001” 这样的应答, 就会将对应的数据 1001 - 2000 重新发送;这个时候接收端收到了 1001 之后, 再次返回的ACK就是7001了(因为2001 - 7000)接收端其实之前就已经收到了, 被放到了接收端操作系统内核的接收缓冲区中;这种机制被称为 “高速重发控制”(也叫 “快重传”)。 - 流量控制
根据接收缓冲区的实际情况,控制发送的速度。
根据结果控制过程。
接收端处理数据的速度是有限的,如果发送端发的太快,导致接收端的缓冲区被打满, 这个时候如果发送端继续发送, 就会造成丢包, 继而引起丢包重传等等一系列连锁反应。因此TCP支持根据接收端的处理能力, 来决定发送端的发送速度, 这个机制就叫做流量控制。
如果TCP协议头的16位窗口大小为0,表示接收缓冲区已经满了,不能再发了。此时发送端就不会进行消息发送了,但发送端会定时发送一个探测包,用来检测接收缓冲区的大小,如果接收缓冲区有值了,那么消息就可以继续发送了。 - 拥塞控制
和你当前网络有关。
虽然TCP有了滑动窗口这个大杀器, 能够高效可靠的发送大量的数据,但是如果在刚开始阶段就发送大量的数据, 仍然可能引发问题。因为网络上有很多的计算机, 可能当前的网络状态就已经比较拥堵。在不清楚当前网络状态下, 贸然发送大量的数据, 是很有可能引起雪上加霜的。
TCP引入 慢启动 机制, 先发少量的数据, 探探路, 摸清当前的网络拥堵状态, 再决定按照多大的速度传输数据;
规则:发包从1开始,以默认值16为临界值,当小于此值的时候,以指数增加的方式发包,当等于这个临界值的时候就以线性增长的方式发包,一直到有大量丢包的请求(发包已经到当前时间段的极致了);这个时候就会将发包值置为1,然后再将临界值设置为最大发包值的一半,继续重复此过程,一直到发送端的消息发送为止。 - 延迟应答
延迟应答是在流量控制的基础上优化发送效率。
TCP延迟应答策略1:固定一定时间段,发送一个延迟应答包。
TCP延迟应答策略2:接收一定次数的包之后,来一个延迟应答。
注意事项:延迟应答时间不能超过MSL(最大生存时间)。因为如果超过MSL就会触发超时重传,它会以为消息丢失了。 - 捎带应答
用来提高消息传输的性能。
是在延迟应答的基础上继续优化传输效率。 - TCP问题:沾包/半包问题
因为TCP是面向数据流的,没有明确的边界,就像水流一样,就容易出现沾包/半包问题。
解决方法:
(1)给一个固定的边界\n readLine();
(2)每次发送固定大小的数据。(一般不这样操作)。
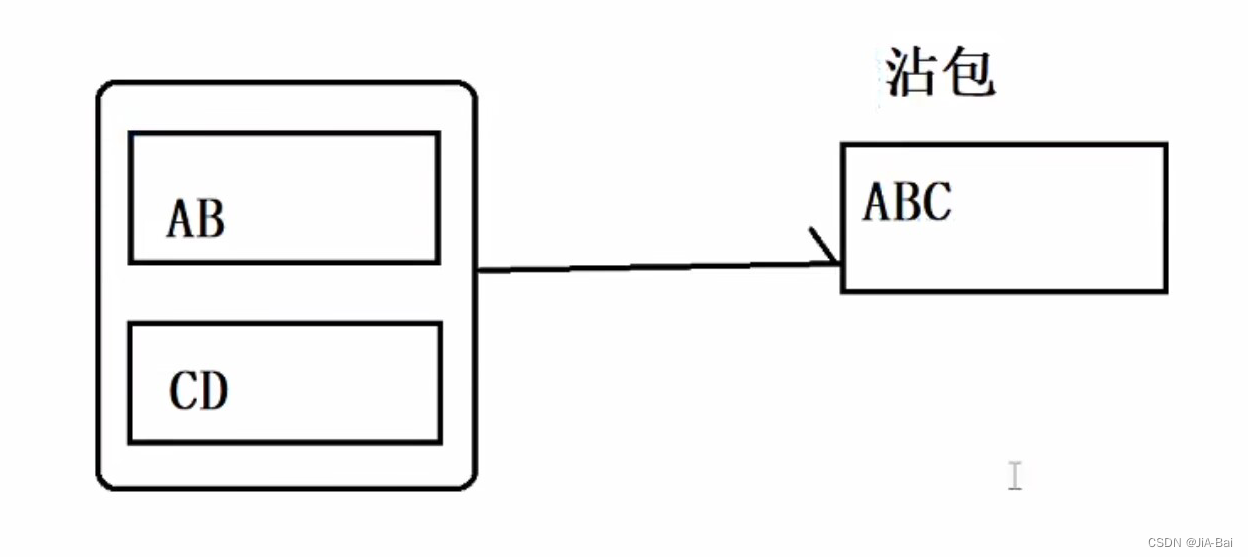
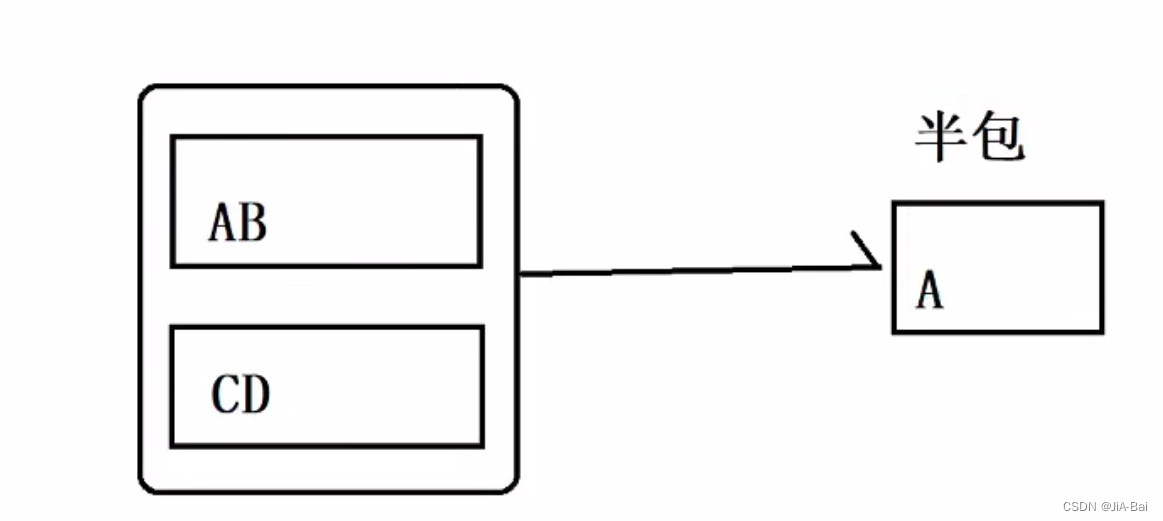
客户端:
package TCP;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.Socket;
/*
* 沾包和半包问题
* */
public class TCPClient2 {
//服务器端IP
private static final String ip = "127.0.0.1";
//服务器端端口号
private static final int port = 9005;
public static void main(String[] args) throws IOException {
//创建客户端,并且链接服务器端
Socket socket = new Socket(ip,port);
//String msg = "Hi,Java~";
String msg = "Hi,Java~\n";
//得到写入对象
try(OutputStream outputStream = socket.getOutputStream()){
for (int i = 0; i < 10; i++) {
//发送数据请求
outputStream.write(msg.getBytes(),0,msg.getBytes().length);
outputStream.flush();
}
}
}
}
服务器端:
package TCP;
import javax.jnlp.FileContents;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
/*
* 沾包和半包问题
* */
public class TCPServer2 {
//端口号
private static final int port = 9005;
//数据传输的最大值
private static final int leng = 1024;
public static void main(String[] args) throws IOException {
//创建服务器
ServerSocket serverSocket = new ServerSocket(port);
//得到客户端得连接
Socket client = serverSocket.accept();
// //读取信息
// try(InputStream inputStream = client.getInputStream()){
// while(true){
// byte[] bytes = new byte[leng];
// int result = inputStream.read(bytes,0,leng);
// if(result > 0){
// //表示读取成功
// System.out.println("读取客户端消息:"+new String(bytes));
// }
// }}
//得到读取对象
try(BufferedReader reader = new BufferedReader(
new InputStreamReader(client.getInputStream()))){
while(true){
//按行定义tcp的边界
String msg = reader.readLine();
if(msg!=null && msg.equals("")){
System.out.println("接收到客户端消息"+msg);
}}
}
}
}
TCP异常情况:
- 进程终止: 进程终止会释放文件描述符, 仍然可以发送FIN,和正常关闭没有什么区别。
- 机器重启: 和进程终止的情况相同。
- 机器掉电/网线断开: 接收端认为连接还在, 一旦接收端有写入操作, 接收端发现连接已经不在了, 就会进行reset. 即使没有写入操作, TCP自己也内置了一个保活定时器, 会定期询问对方是否还在. 如果对方不在, 也会把连接释放。
另外, 应用层的某些协议, 也有一些这样的检测机制,例如HTTP长连接中, 也会定期检测对方的状态。例如QQ, 在QQ断线之后, 也会定期尝试重新连接。
TCP小结:
-
TCP保证稳定性:
确认应答
超时重发
连接管理
流量控制(以结果为导向)
拥塞控制(以过程为导向) -
TCP保证高性能:
滑动窗口
延迟应答
捎带应答 -
如何保证UDP发送消息的稳定性?
答:参考TCP的可靠性机制, 在应用层实现类似的逻辑。例如:
引入确认应答, 确保对端收到了数据。
引入超时重传, 如果隔一段时间没有应答, 就重发数据。
… … -
基于TCP应用层协议:
HTTP、HTTPS、SSH、Telnet、FTP、SMTP,当然, 也包括自己写TCP程序时自定义的应用层协议。 -
TCP vs UDP
(1)UDP是无连接的,TCP是有连接的。
(2)UDP是不稳定的,TCP是稳定的。
(3)UDP是面向数据报的,TCP是面向数据流的。
(4)UDP没有发送缓冲区,TCP有发送缓冲区。
(5)UDP是以高效性著称,TCP是以稳定性著称的。
(6)所实现的应用层协议不同,UDP有…,TCP有…。
3 网络层
在复杂的网络环境中确定一个合适的路径。
主机: 配有IP地址, 但是不进行路由控制的设备。
路由器: 即配有IP地址, 又能进行路由控制。
节点: 主机和路由器的统称。
3.1 IP
IP协议数据格式:
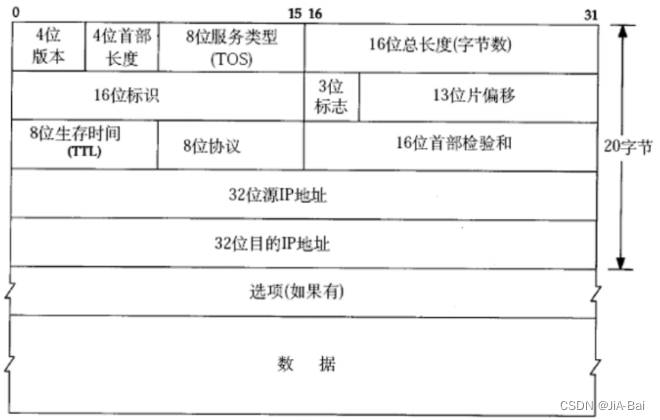
4位版本号(version): 指定IP协议的版本, 对于IPv4来说, 就是4。
4位头部长度(header length): IP头部的长度是多少个32bit, 也就是 length x 4 的字节数,4bit表示最大的数字是15, 因此IP头部最大长度是60字节。
8位服务类型(Type Of Service): 3位优先权字段(已经弃用), 4位TOS字段, 和1位保留字段(必须置为0)。 4位TOS分别表示: 最小延时, 最大吞吐量, 最高可靠性, 最小成本.。这四者相互冲突, 只能选择一个。对于ssh/telnet这样的应用程序, 最小延时比较重要; 对于ftp这样的程序, 最大吞吐量比较重要。
16位总长度(total length): IP数据报整体占多少个字节(整个头部+数据)。
16位标识(id): 唯一的标识主机发送的报文,如果IP报文在数据链路层被分片了, 那么每一个片里面的这个id都是相同的。
3位标志字段: 第一位保留(保留的意思是现在不用, 但是还没想好说不定以后要用到);第二位置为1表示禁止分片, 这时候如果报文长度超过MTU, IP模块就会丢弃报文;第三位表示"更多分片", 如果分片了的话, 最后一个分片置为1, 其他是0. 类似于一个结束标记。
13位分片偏移(framegament offset): 是分片相对于原始IP报文开始处的偏移. 其实就是在表示当前分片在原报文中处在哪个位置,实际偏移的字节数是这个值 * 8 得到的。因此, 除了最后一个报文之外, 其他报文的长度必须是8的整数倍(否则报文就不连续了)。
8位生存时间(Time To Live, TTL): 数据报到达目的地的最大报文跳数,一般是64。每次经过一个路由, TTL -= 1, 一直减到0还没到达, 那么就丢弃了。这个字段主要是用来防止出现路由循环。即它是为了记录路由器转发的次数,默认值是64,每转发一次,次数-1,若这个为0 ,表示此服务器不存在,那么就可以直接舍弃这个包。
8位协议: 表示上层协议的类型。
16位头部校验和: 使用CRC进行校验, 来鉴别头部是否损坏。
源地址和目标地址: 表示发送端和接收端。
选项字段:不定长, 最多40字节。
16位标识、3位标志和13位片偏移这三个是网络层能够实现数据包分发和组装的关键。
IP地址: 网络号+主机号
对于内网来说:网络号相同,主机号不同。
IP分段:
过去曾经提出一种划分网络号和主机号的方案, 把所有IP 地址分为五类,,如下所示:
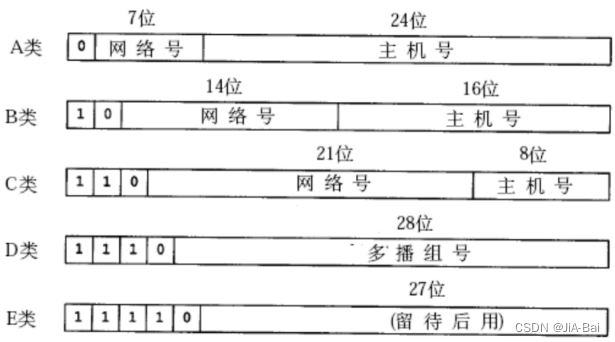
A类 0.0.0.0到127.255.255.255
B类 128.0.0.0到191.255.255.255
C类 192.0.0.0到223.255.255.255
D类 224.0.0.0到239.255.255.255
E类 240.0.0.0到247.255.255.255
随着Internet的飞速发展,这种划分方案的局限性很快显现出来,大多数组织都申请B类网络地址, 导致B类地址很快就分配完了, 而A类却浪费了大量地址。例如, 申请了一个B类地址, 理论上一个子网内能允许6万5千多个主机,A类地址的子网内的主机数更多,然而实际网络架设中, 不会存在一个子网内有这么多的情况,因此大量的IP地址都被浪费掉了。
针对这种情况提出了新的划分方案, 称为CIDR(Classless Interdomain Routing):
- 引入一个额外的子网掩码(subnet mask)来区分网络号和主机号;
- 子网掩码也是一个32位的正整数,通常用一串 “0” 来结尾;
- 将IP地址和子网掩码进行 “按位与” 操作, 得到的结果就是网络号;
- 网络号和主机号的划分与这个IP地址是A类、B类还是C类无关。
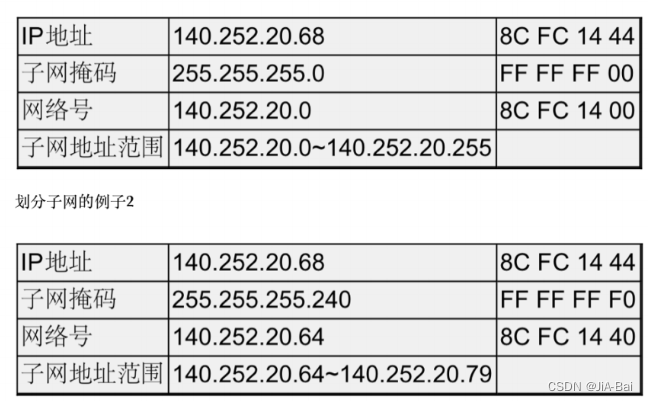
可见,IP地址与子网掩码做与运算可以得到网络号, 主机号从全0到全1就是子网的地址范围。IP地址和子网掩码还有一种更简洁的表示方法,例如140.252.20.68/24,表示IP地址为140.252.20.68, 子网掩码的高24位是1,也就是255.255.255.0。
特殊的IP地址:
- 将IP地址中的主机地址全部设为0, 就成为了网络号, 代表这个局域网;
- 将IP地址中的主机地址全部设为1, 就成为了广播地址, 用于给同一个链路中相互连接的所有主机发送数据包;
- 127.*的IP地址用于本机环回(loop back)测试,通常是127.0.0.1
私有IP地址和公网IP地址:
如果一个组织内部组建局域网,IP地址只用于局域网内的通信,而不直接连到Internet上,理论上 使用任意的IP地址都可以,但是RFC 1918规定了用于组建局域网的私有IP地址:
- 10.*,前8位是网络号,共16,777,216个地址
- 172.16.到172.31.,前12位是网络号,共1,048,576个地址
- 192.168.*,前16位是网络号,共65,536个地址
包含在这个范围中的, 都成为私有IP, 其余的则称为全局IP(或公网IP);
4 数据链路层
4.1 以太网
“以太网” 不是一种具体的网络, 而是一种技术标准; 既包含了数据链路层的内容, 也包含了一些物理层的内容。 例如: 规定了网络拓扑结构, 访问控制方式, 传输速率等。
例如以太网中的网线必须使用双绞线; 传输速率有10M, 100M, 1000M等。
以太网是当前应用最广泛的局域网技术; 和以太网并列的还有令牌环网, 无线LAN等;
以太网帧格式:
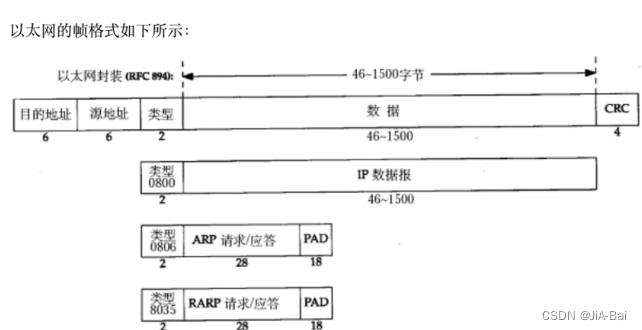
源地址和目的地址是指网卡的硬件地址(也叫MAC地址), 长度是48位,是在网卡出厂时固化的。
帧协议类型字段有三种值,分别对应IP、ARP、RARP。
帧末尾是CRC校验码。
MTU(最大长度): 1500字节。
MTU对于UDP来说: 实际传输的最大值1500字节 - 传输层8字节 - 网络层20字节 = 1472字节。
- 一旦UDP携带的数据超过1472(1500 - 20(IP首部) - 8(UDP首部)), 那么就会在网络层分成多个IP数据报。
- 这多个IP数据报有任意一个丢失, 都会引起接收端网络层重组失败。那么这就意味着, 如果UDP数据报在网络层被分片, 整个数据被丢失的概率就大大增加了。
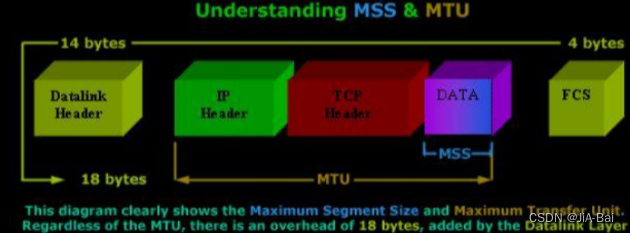
MTU对TCP来说:
- TCP的一个数据报也不能无限大, 还是受制于MTU。TCP的单个数据报的最大消息长度, 称为MSS(Max Segment Size)。
- TCP在建立连接的过程中, 通信双方会进行MSS协商。
- 最理想的情况下, MSS的值正好是在IP不会被分片处理的最大长度(这个长度仍然是受制于数据链路层的MTU)。
- 双方在发送SYN的时候会在TCP头部写入自己能支持的MSS值。
- 然后双方得知对方的MSS值之后, 选择较小的作为最终MSS。
- MSS的值就是在TCP首部的40字节变长选项中(kind=2)。
MSS(最大帧大小) 发送方和接收方连接会进行协商,带上彼此支持的MSS,最终以最小的MSS作为最终的MSS。
MSS和MTU的关系:
4.2 ARP
ARP协议它严格意义上来说,它不属于数据链路层,它是基于网络层数据链路层之间的一个协议。
ARP可以实现IP到MAC映射。
- 在网络通讯时,源主机的应用程序知道目的主机的IP地址和端口号,却不知道目的主机的硬件地址;
- 数据包首先是被网卡接收到再去处理上层协议的,如果接收到的数据包的硬件地址与本机不符,则直接丢弃;
- 因此在通讯前必须获得目的主机的硬件地址。
ARP协议的工作流程:

- 源主机发出ARP请求,询问“IP地址是192.168.0.1的主机的硬件地址是多少”, 并将这个请求广播到本地网段(以太网帧首部的硬件地址填FF:FF:FF:FF:FF:FF表示广播);
- 目的主机接收到广播的ARP请求,发现其中的IP地址与本机相符,则发送一个ARP应答数据包给源主机,将自己的硬件地址填写在应答包中;
- 每台主机都维护一个ARP缓存表,可以用arp -a命令查看。缓存表中的表项有过期时间(一般为20分钟),如果20分钟内没有再次使用某个表项,则该表项失效,下次还要发ARP请求来获得目的主机的硬件地址。
5 DNS
DNS是一整套从域名映射到IP的系统,它是应用层的重要协议。
TCP/IP中使用IP地址和端口号来确定网络上的一台主机的一个程序,但是IP地址不方便记忆。于是人们发明了一种叫主机名的东西, 是一个字符串, 并且使用hosts文件来描述主机名和IP地址的关系。
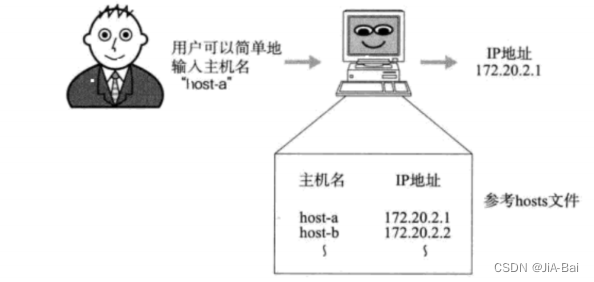
DNS是应用层协议
DNS底层使用UDP进行解析
浏览器会缓存DNS结果
经典题目: 当在浏览器中输入url后, 会发生什么事情?
- 浏览器会判断当前输入的URL是否合规,也是判断当前url是否正确。
- 浏览器会判断当前的URL有没有缓存。
- DNS服务器(域名——>IP)。
- TCP连接(3次握手)
- 以http协议的数据格式发送数据给客户端。
- ACK返回给客户端,告诉客户端我已经收到消息了。
- 服务器业务代码处理并且把结果返回给浏览器。
- 浏览器拿到服务器返回的信息,执行渲染。
- 4次挥手正常断开连接。
6 NAT
缓解IPV4地址不够用的解决方案:
- IPV6(128位) [弊端:需要更换网络设备来支持IPV6]
- NAT
优点:缓解IPV4不够用的问题。
缺点:(a)NAT服务是有开销;(b)如果NAT服务器挂了,那么整个都会挂掉。
也就是:(a)无法从NAT外部向内部服务器建立连接;(b)装换表的生成和销毁都需要额外开销;©通信过程中一旦NAT设备异常, 即使存在热备, 所有的TCP连接也都会断开。
NAT技术当前解决IP地址不够用的主要手段, 是路由器的一个重要功能;
NAT能够将私有IP对外通信时转为全局IP,也就是就是一种将私有IP和全局IP相互转化的技术方法。
很多学校, 家庭, 公司内部采用每个终端设置私有IP, 而在路由器或必要的服务器上设置全局IP;全局IP要求唯一, 但是私有IP不需要; 在不同的局域网中出现相同的私有IP是完全不影响的。
NAT IP转换过程:
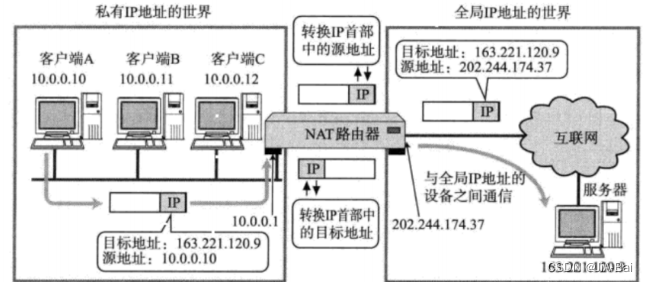
- NAT路由器将源地址从10.0.0.10替换成全局的IP 202.244.174.37;
- NAT路由器收到外部的数据时, 又会把目标IP从202.244.174.37替换回10.0.0.10;
- 在NAT路由器内部, 有一张自动生成的, 用于地址转换的表;
- 当 10.0.0.10 第一次向 163.221.120.9 发送数据时就会生成表中的映射关系]
NAT vs 代理服务器:
- 所在层级不一样:代理服务器一般运行在应用层;NAT是运行在数据链路层。
- 代理服务器通常是安装在电脑或手机上的,而NAT服务器通常安装在防火墙上。
- 解决问题不同:NAT是解决IP不够用的问题,代理服务器是为了解决访问延迟或者访问不了的问题。