在互联网时代,数据是无处不在的黄金。无论你是寻找小规模的数据采集任务还是大规模的网络爬虫项目,Python提供了丰富的爬虫框架供你选择。对于小型爬虫需求,你可能会喜欢使用requests库和Beautiful Soup(bs4库)这样的基本工具,它们能够满足基本的爬虫任务。
但当你的项目规模逐渐扩大,涉及到异步抓取、内容管理以及未来的扩展需求时,使用成熟的爬虫框架会大有裨益。接下来,我们将探讨7个不同类型的Python爬虫框架,让你了解它们各自的特点和适用场景,以便在编写网络爬虫时选择最合适的工具。
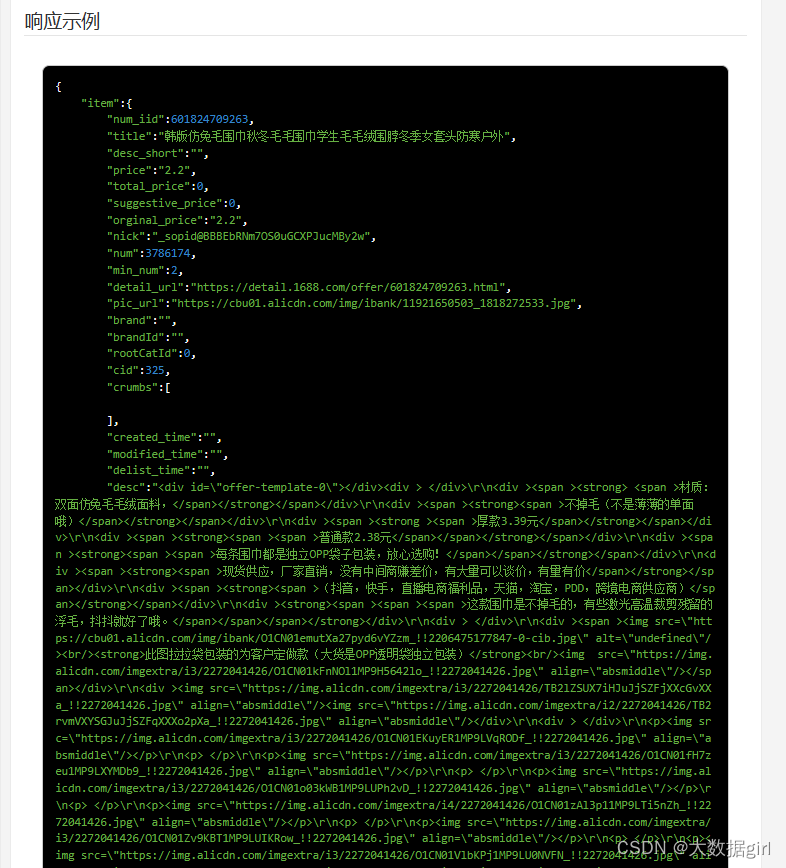
阿里巴巴中国站获得1688商品详情 API 返回值说明
item_get-获得1688商品详情 API测试 注册
1688.item_get
公共参数
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
请求参数
请求参数:num_iid=610947572360
参数说明:num_iid:1688商品ID
sales_data:&sales_data=1 获取近30天成交数据
agent:&agent=1 获取1688分销代发价格数据
响应参数
Version: Date:
| 名称 | 类型 | 必须 | 示例值 | 描述 |
|---|---|---|---|---|
| item | item[] | 0 | 宝贝详情数据 |