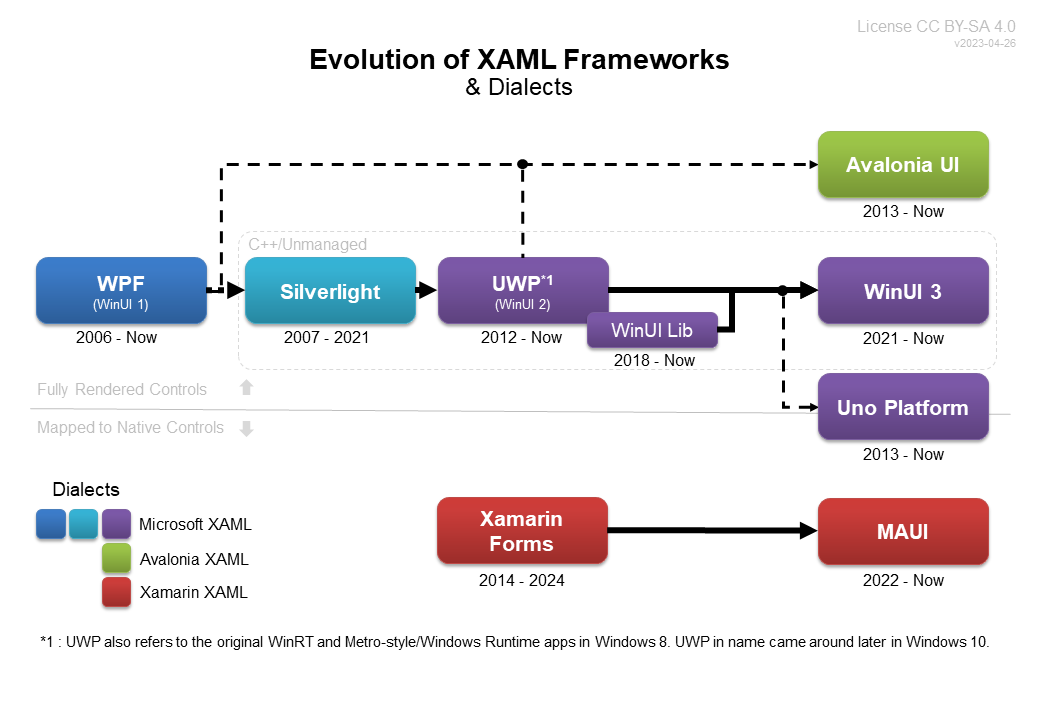
BPG(basic path group)和PG(path group)的异同
INVS默认使用了BPG,但是基于SDC理论下PG(path group)也是天然存在,两者在数据库里边有各自存在的方式,也可以共融共生中,通过其中的异同,看到INVS的一些有趣的处理。

BPG (basic path group)timeDesign报告简析
如果用户没有在SDC里边使用任何的group_path命令,INVS默认就会是使用BGP进行分组(PS:这点和S家的有区别)。
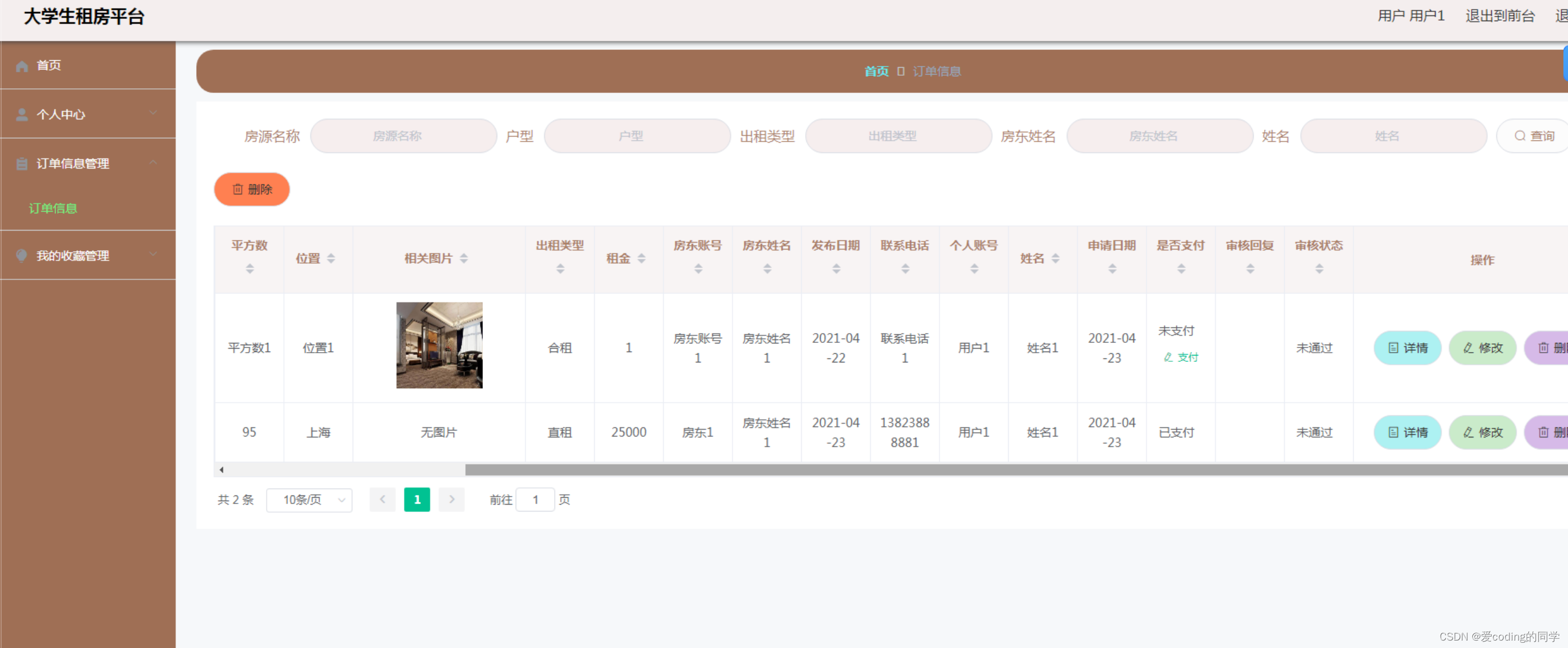
用户在导入数据库后,通过timeDesign就可以看到类似下面的分组关系:

(default – reg2reg – reg2cgate) - all = (125024+787+479) - 125882 = 408。
所有BGP的path总量竟然要比all 要多!
这个是因为:all 是基于EP的path核算,一个EP点就对应1,如果某个EP有路径展开,譬如: FF1 -> FF0 和 INPUT -> FF0 ,这样在default里边就会再出现以FF0为EP的path。这里称为:EP展开
为了验证这个理论,尝试做一下IO的set_false_path操作,然后再用timeDesign


这里的default=0说明所有的EP都没有二次展开,可以明确的看到:
reg2reg + reg2cgate = 125024 + 787 = all = 125811
PS:无论用户是否通过group_path调整分组,timeDesign的all的值是不会发生变化的。可以利用这个信息,查看用户EP展开路径的数量:
EP展开路径 = all – [user_group_path_count_sum | BGP_path_count_sum]
BPG和PG(path group)的兼容
虽然INVS拥有自己独创的BGP,但是在兼容传统SDC的大前提下,INVS当然也支持了用户自定义的path group。
通过下图理解BPG和PG的关系:

可以看到,通过group_path命令定义PG的优先级是大于BPG的,任何时候用户使用了group_path 命令,那么原始的BGP就会被完全替代,(PS:两个系统只能居其一,不能同时存在)。无论用户的group path定义是否完备,都可以让INVS从BPG进入到PG系统:
譬如下例:这里用户只使用了group_path 定义了一个组

可以看到,由于用户定义的组没有timing path,所以整个系统的path都归集为了default,此时,系统已经切换到PG了。
尽管如此,用户依然可以通过all path数量来评估自己的EP展开问题,这个和BPG是一样的,无论是在那个系统,all的信息是一致的,INVS的底层逻辑其实并没有发生改变。
但是,如果用户定义的分组很多,这个在做place_opt_design的时候,INVS采用了更多的iteration进行收敛,这个和INVS基于BGP EP 的优化方式是类似的不同,只不过分组变多会直接导致iteration变多。也会简介导致时序收敛的问题。

工具会把所有的HEPG (high effort path group)在这里描述一下TNS/WNS,同时,后续的正常修复也是集中在HEPG组的(如Active Path Group行所示),所以HEPG越多,工具的考虑就会越多。
PS:这里注意,default带了一个*,其实他也是一个high effort组,
report_timing对BPG和 PG 的支持
由于BPG是系统默认的分组方式,INVS把BPG设定为为隐性的(implicit),而把用户使用group_path的分组定义为显性的(explicit)。无论是那个系统,data path optimization的工作方式是没有区别的,甚至在timeDesign的时候也是看不出来区别的。
但是对于report_timing命令系统,INVS处理还是略有不同:
BGP下的report_timing 命令使用
report_timing 后面跟的-group选项,需要制定的是显性组(explicit),如果这里用户使用了BPG的隐性组(implicit),工具返回错误:

那这里问题来了,数据库里的group都去哪里了。
INVS使用了BPG和PG里边都有的一个公共组:default 巧妙的处理了这个问题:

可以看到,在BPG下,所有的path对应于report_timing的path_group都回归到了default。可以视为对隐性组的一个简单管理方法。
但是,这里还有一个点需要探究:
INVS用户都知道,一个timing path里边会有很多属性,如果在BPG下,report_timing借用了default组,那么这个属性何去何从呢?
- 如果是使用
-path_group指定 default组,这个会返回设计里边所有的timing path - 如果用户去query这个某个path的
path_group_name属性,这个会立刻现实类似S家的策略:所有的EP都是基于clock domain的,同时你也可以看到S家里边熟悉的异步和clock gating 组,譬如下面的统计结果

所以这个时候,用户又可以用上述的path_group进行report_timing 报告了,尽管你在get_path_group得不到上述的组。INVS这里有一次巧妙地利用了implicit的语境。
report_timing -path_group CLK_1
这个可以被是为BPG的隐形福利,这种处理方式较为方便用户在使用BPG的时候查验数据。
PG下的report_timing 命令使用
PG下,由于用户都是使用了SDC标准的group_path命令,这个时候所有定义的组,在data path optimization和report_timing下都是完全统一的,这里就不做过多的赘述了。
BPG对实现人员的启发
INVS的BPG对于multi-clock per FF给出了比较好的解决方法。相较而言,后端工具更善于对单纯的数据进行分析和优化,过于复杂的环境处理的结果,经测试明显会变差不少,并且runtime 和area都变得更差一点。
譬如下面的示例:

FF0-> FF1/2/3 三条路径都比较critical,直接的感官印象就是到FF1/2/3的timing 很差,如果只是简单的基于FF1/2/3 三个EP分别做组,其实是不利于优化的
因为INVS每一次对HEPG的优化都会把common path和local path推进一次,但是这两类path是会互相牵制的。所以,简单的单分组,并不能很好的解决这类问题。
用户还是需要顺应工具的特点进行约束规划,从而得到自己期望的结果。
BPG和PG的融合使用
BPG符合INVS原生策略。但是由于INVS兼顾了SDC里的group_path的一些设定,所以会对用户的report_timing系统带来一些困惑,知识星球会提供一个具体脚本,使用一个脚本,可以在使用BPG的便利性的同时,也可以在兼顾report_timing报告的使用便利性
【敲黑板划重点】

BPG可以视为INVS的data path optimization的一个基础起点,在大部分情况下会更好的体现INVS的优势,用户需要理解其中的奥秘,灵活使用/切换BPG和PG系统,找到适合自己设计的方式/流程。
参考资料
Synopsys Design Compiler® User Guide
Cadence Innovus User Guide