DDL:创建和管理表
DDL所有的操作都要慎重,尤其是删除,清空等。
创建数据库--->确认字段--->创建数据表---->插入数据
创建数据库
1.创建数据库:推荐使用方式3
#创建数据库
#方式1,使用的是默认字符集
create database mytest1;
show CREATE DATABASE mytest1;#此语句查看数据库信息
#方式2,显示指明字符集
create database mytest2 character set 'gbk';
show CREATE DATABASE mytest2;
#方式3 如果要创建的数据库已经存在,则创建不成功
create database if not exists mytest2 character set 'utf8';#创建失败,字符集仍为gbk
SHOW CREATE DATABASE mytest2;
show databases;2.管理数据库
写的过程中要注意DATABASES 和DATABASE的区别。
查看指定的表,数据库时都用的是DATABASE,罗列数据库或者表是用的是DATABASES和TABLES;
#管理数据库
#查看当前连接的数据库有哪些
show databases;
#切换数据库
use atguigudb;
#查看当前数据库中保存的数据表
show tables;
#查看当前使用的数据库
select database() from dual;
#查看指定数据库下保存的数据表
show tables from atguigudb;
#更改数据库字符集
alter database mytest2 character set 'utf8';
show create database mytest2;
#删除数据库
drop database if exists mytest1;
show databases;
创建表
3.创建表
创建表主要有两种方式,一种是从零开始创建字段,一种是基于现有的表。
方式2可以将各种查询的结果创建为一张新的表。
还要注意DATE日期类型和DATA不要搞混。
查看表结构的语句:
DESC 表名;
SHOW CREATE TABLE 表名;
#2.如何创建数据表
use mytest2;
show create database mytest2;
#方式1:'白手起家'
create table if not exists myemp1(
id int,
emp_name varchar(15),#使用VARCHAR必须指明其长度
hire_date date
);
desc myemp1;#查看表结构
show create table myemp1;
#方式2:基于现有的表创建
use atguigudb;
create table myemp2
as
select employee_id,last_name,salary
from employees;
#复制数据创建表
create table employee_copy
as
select *
from employees;
show tables;
select*
from employee_copy;
#不复制数据只复制字段创建表
create table employee_copy2
as
select *
from employees
limit 0,0;
show create table employee_copy2;
desc employee_copy2;
select *
from employee_copy2;
4.管理表
#管理表
#3修改表 -- >alter table
desc myemp2;
#3.1添加字段
alter table myemp2
add salary double(10,2);
alter table myemp2
add phone_number varchar(20) first;
alter table myemp2
add email varchar(20) after phone_number;
#3.2修改字段
alter table myemp2
modify phone_number varchar(30) default '123456';
desc myemp2;
#3.3重命名字段
alter table myemp2
change salary monthly_salary double(10,2);
desc myemp2;
alter table myemp2
change email my_email Varchar(40);
#3.4删除字段
alter table myemp2
drop column phne_number;
#4.重命名表
rename table myemp2 to myemp22;
show tables;
#删除表
drop table if exists myemp22;
drop table if exists employee_copy2;
#清空表
truncate table employee_copy;DCL中:
COMMIT: 提交数据,永久保存,数据不可以回滚
ROLLBACK:数据可以回滚到最近的一次COMMIT之后
TRUNCATE TABLE 和 DELETE FROM:
相同点:都可以实现对表中所有数据的删除,同时保留表结构
不同点:
TRUNCATE TABLE:一旦执行此操作,表数据清除,数据不可以回滚
DELETE FROM : 一旦执行此操作,表数据可以全部清除。数据可以实现回滚
DDL 和DML的说明:
DDL的操作一旦执行,就不可回滚。
DML的操作默认情况下一旦执行不可回滚。但是在执行DML之前,执行了 set autocommit = false,则执行的DML操作可以实现回滚。
#演示DELETE FROM
COMMIT;
SELECT *
FROM myemp3;
SET autocommit = FALSE;
DELETE FROM myemp3;
SELECT *
FROM myemp3;
ROLLBACK;MySQL8.0新特性—DDL原子化
案例: 假设数据库中只有表book1,在执行DROP TABLE book1,book2的时候显然不成功,此时会执行回滚操作,查看表,book1依然存在。
牵扯到事务的概念。事务是一个整体,要么都做了,要么把已经做的回滚回去。
DML操作
添加数据
添加数据有三种方式,要注意字段顺序和添加顺序一致,以及在第三种方式时要注意查询表的字段大小和新表设置的字段大小容量是否一致合理。
有些未指明字段,添加时是null空值
insert into emp1
values(1,'Tom','2000-2-1',3400.25);
insert into emp1(id,hire_date,salary,`name`)
values(2,'2000-8-21',6700,'Jerry');
insert into emp1(id,salary,`name`)
values(3,9000,'Ellie');
insert into emp1(id,`name`,salary)
values(5,'Jim',5000),(6,'Sam',6700);
insert into emp1(id,`name`,hire_date,salary)
select employee_id,last_name,hire_date,salary
from employees
where department_id in(70,60);更新数据
修改数据可能不成功,可能是由于约束条件限制
UPDATE emp1
SET hire_date=CURDATE()
WHERE id=6;#不添加筛选条件时可以批量修改删除数据
DML操作默认情况下,执行完后都会自动提交数据。
如果希望执行完后不自动提交数据,则需要使用 SET autocommit = false;
COMMIT;
SET autocommit=FALSE;
DELETE FROM emp1
WHERE id<7;
ROLLBACK;
练习
#查询书名达到10个字符,不包含空格
select name
from books
where 10<= CHAR_LENGTH(REPLACE(NAME,' ',''));
#统计每一种note的库存量,并合计总量
select ifnull(note,'合计库存总量') as note,sum(num)
from books
group by note with rollup;
#8. 将userid为Bbiri的user表和my_employees表的记录全部删除
DELETE
FROM my_employees e
JOIN users u
ON e.userid =u.userid
WHERE m.userid ='Bbiri';MySQL数据类型
属性:CHARACTER SET 'utf8';
不仅可以指明数据库的字符集,也可以指明表的字符集,字段的字符集。
不指明时默认向上指明字符集:比如字段名默认用表的字符集,表默认用数据库的,数据库还没指明就默认用MySQL配置文件的字符集(show variables like 'character_%');
CREATE TABLE pet(
`name` VARCHAR(20) character set'utf8',
`owner` VARCHAR(20),
species VARCHAR(20),
sex CHAR(1),
birth YEAR,
death YEAR
)character set'utf8';约束(constraint)
问题1:为什么需要约束
为了保证数据的完整性,需要对表数据进行额外的限制。从以下四个方面考虑:
- 实体完整性。表中不能存在两个完全相同,无法区分的记录
- 域完整性。性别范围"男/女"
- 引用完整性。员工所在部门要能在部门表中找到
- 用户自定义完整性。比如用户名唯一
问题2:约束的分类
- 约束的字段的个数:单列约束 / 多列约束
- 约束的作用范围:列级约束 / 表级约束
- 约束的功能:{
- not null非空约束
- unique 唯一性约束
- primary key 主键约束
- foreign key 外键约束
- check 检查约束
- default默认值约束
- }
添加约束 :在创建表时添加约束;alter table增加约束;alter table时删除约束
查看表中约束:
select * from information_schema.`TABLE_CONSTRAINTS`
where table_name = 'employees';NOT NULL(非空约束)
创建实例:
#方式1
create table test1(
id int not null,
last_name varchar(15) not null,
email varchar(25),
salary decimal(10,2)
);
desc test1;
#方式2
alter table test1
modify email varchar(25) not NULL;效果:可以看到 NULL的id和last_name字段为NO
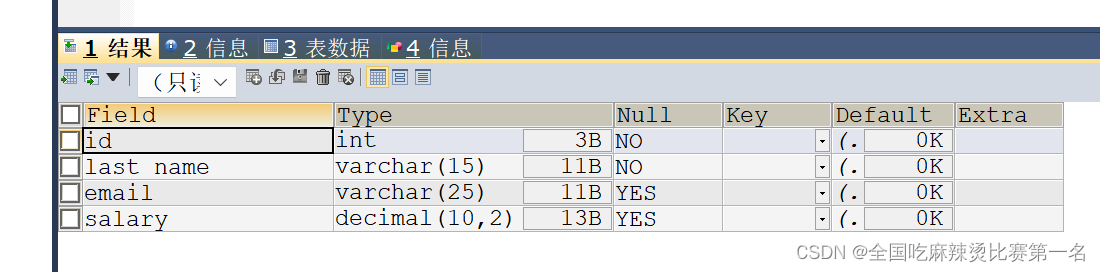 UNIUE(唯一性约束)
UNIUE(唯一性约束)
1)添加唯一性约束:
#方式1
CREATE TABLE test2(
id INT UNIQUE, #UNIQUE列级约束
last_name VARCHAR(15),
email VARCHAR(25),
salary DECIMAL(10,2),
CONSTRAINT uq_test2_email UNIQUE(email)#UNIQUE表级约束
);
#方式2
ALTER TABLE test2
ADD CONSTRAINT uq_test2_salary UNIQUE(salary);
#方式3
ALTER TABLE test2
MODIFY last_name VARCHAR(15) UNIQUE;
#复合的唯一性约束
create table user(
id int,
`name` varchar(15),
`password` varchar(20),
#表级约束
Constraint uq_user_name_pwd UNIQUE(`name`,`password`)
);在创建唯一约束时,如果不给唯一约束命名,就默认和列名相同。
可以向声明在UNIQUE的字段上添加NULL值,而且可以多次添加NUULL值
复合的唯一性是指,两个字段都完全一样是才算做相同,只要其中一个有区别就不算相同并可以添加成功。
2)删除唯一性约束:
添加唯一约束会创建唯一索引;
删除唯一约束只能通过唯一索引;
删除时需要指定唯一索引名,唯一索引名和唯一约束名一样;
如果创建唯一索引时没有指定名称:单列时默认与列名相同;组合列与小括号第一个字段名相同。
ALTER TABLE test2
DROP INDEX email;PRIMARY KEY(主键约束)
主键约束相当于唯一约束+非空约束的组合。
一个表中最多只能有一个逐渐约束,创建表就需要提供一个主键。
联合在一起只要和别的不相同就行,但只要有一个是NULL就添加不成功
创建主键约束:
CREATE TABLE test3(
id INT PRIMARY KEY,#列级约束
last_name VARCHAR(15),
salary DECIMAL,
email VARCHAR(25)
);
CREATE TABLE test3(
id int,
name varchar(15),
password varchar(20),
primary(name,password)#表级约束
);
CREATE TABLE test6(
id INT
);
ALTER TABLE test 6
ADD PRIMARY KEY(id);删除逐渐约束:主键名永远是Primary,实际开发中根本不会做。
ALTER TABLE test6
DROP PRIMARY KEY;AUTO_INCREMENT
特点和要求:
- 只能作用在键列(主键列,唯一键列)
- 一个表只能由一个自增长
#自增长列
CREATE TABLE test7(
id INT PRIMARY KEY AUTO_INCREMENT,
last_name VARCHAR(15)
);
INSERT INTO test7(last_name)
VALUES('Tom');自增变量的持久化
mysql8.0将计数器放入到重做日志当中,每次计数器发生改变都会写入重做日志,如果数据库重启,InnoDB就会根据重做日志中的信息来初始化计数器的内存值。
FOREIGN KEY外键约束
从表(也可以称为子表)中添加的值必须是主表(父表)中已经存在的值。
规则:外键列必须引用主表的主键或唯一约束的列
添加外键约束
#在CREATE TABLE添加
#先创建主表
create table dept1(
dept_id int primary key,
dept_name varchar(15)
);
#再创建从表
create table emp1(
id int primary key auto_increment,
emp_name varchar(15),
department_id int,
constraint fk_emp1_dept_id foreign key(department_id) references dept1(dept_id)
);使用外键实例:
添加数据:先添加父表,后添加子表
删除数据:先删除子表。后删除父表。
#主表添加数据
insert into dept1
value(1,'IT');
#子表添加数据
insert into emp1
values(1001,'Tom',1);
#删除数据
DELETE FROM emp1
WHERE id=1001;
DELETE FROM dept1
WHERE dept_id=1;约束等级
Cascade方式:删除/修改父表,同步删除/修改子表记录
Set null方式:删除/修改父表,子表匹配记录列设为null
No action方式:子表中有记录,父表不允许任何操作
Restrict:同 No action
对于外键约束 最好采用" on update cascade on delete restrict ".
删除外键约束:
ALTER TABLE emp1
DROP FOREIGN KEY fk_emp1_dept_id;
#再手动删除外键约束对应的普通索引(按照外键约束名去删)
SHOW INDEX FROM emp1;
ALTER TABLE emp1
DROP INDEX fk_emp1_dept_id;CHECK约束
代码实例:
CREATE TABLE test10(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) CHECK(salary>2000)
);DEFAULT默认值
CREATE TABLE test10(
id INT,
last_name VARCHAR(15),
salary DECIMAL(10,2) DEFAULT 2000
);