系列文章目录
MNN createFromBuffer(一)
MNN createRuntime(二)
MNN createSession 之 Schedule(三)
MNN createSession 之创建流水线后端(四)
MNN Session 之维度计算(五)
MNN Session 之几何计算(六)
MNN Session 之 CPU 算子(七)
MNN Session 之 Vulkan 算子(八)
文章目录
- 系列文章目录
- 1、createSession
- 1.1 createMultiPathSession
- 1.1.1 Session::resize
- 1.1.1.1 Pipeline::allocMemory
- 1.1.1.1.1 _createExecutions
- 1.1.1.1.1.1 VulkanBackend::onCreate
- 1.1.1.1.1.1.1 VulkanBackend::Creator::onCreate
- 1.1.1.1.1.1.2 VulkanBasicExecution
- 1.1.1.1.1.1.3 Vulkan 算子执行实例注册
- 添加Vulkan实现
- 添加Metal实现
- 添加OpenCL实现
- 添加OpenGL实现
- 1.1.1.1.1.1.4 VulkanBasicExecutionDirect
- 1.1.1.1.1.1.5 VulkanBasicExecutionDirect::VulkanBasicExecutionDirect
- 1.1.1.1.1.1.6 VulkanBasicExecutionInDirect
- 1.1.1.1.1.2 CPUBackend::onCreate
- 1.1.1.1.2 Backend::onResizeBegin
- 1.1.1.1.3 Execution::onResize
- 1.1.1.1.4 Backend::onResizeEnd
- 1.1.1.1.5 Execution::onExecute
1、createSession

依据 ScheduleConfig 和 RuntimeInfo 创建会话。
// source/core/Interpreter.cpp
Session* Interpreter::createSession(const ScheduleConfig& config, const RuntimeInfo& runtime) {
return createMultiPathSession({config}, runtime);
}
1.1 createMultiPathSession
createMultiPathSession 完整代码
// source/core/Interpreter.cpp
Session* Interpreter::createMultiPathSession(const std::vector<ScheduleConfig>& configs, const RuntimeInfo& runtime) {
// ...
auto result = newSession.get();
auto validForResize = info.validForResize;
if (validForResize && mNet->modes.inputMode == Session_Input_Inside && mNet->modes.resizeMode == Session_Resize_Direct) {
result->resize();
}
// ...
return result;
}
1.1.1 Session::resize
Session::resize 完整代码
// source/core/Session.cpp
ErrorCode Session::resize() {
// ...
if (mNeedMalloc) {
// Set needResize = true for easy for judge in runSession when error
mNeedResize = true;
// Turn Pipeline to Command Buffer and Malloc resource
// TODO: Separate Schedule and Malloc
bool forbidReplace = permitCodegen;
if (mInfo.constReplaceBackend != nullptr) {
forbidReplace = true;
}
for (auto& iter : mPipelines) {
auto error = iter->allocMemory(firstMalloc, forbidReplace);
if (NO_ERROR != error) {
return error;
}
}
// ...
mNeedMalloc = false;
mNeedResize = false;
}
// ...
return NO_ERROR;
}
1.1.1.1 Pipeline::allocMemory
// source/core/Pipeline.cpp
// typedef std::pair<BackendCache, std::vector<OpCacheInfo>> PipelineInfo;
//
// struct BackendCache {
// Backend::Info info;
// BackendConfig config;
// std::pair<std::shared_ptr<Backend>, std::shared_ptr<Backend>> cache;
// bool needComputeShape = true;
// bool needComputeGeometry = true;
// bool reportError = true;
// std::map<Tensor*, TENSORCACHE> inputTensorCopyCache;
// };
//
// /** pipeline info */
// struct OpCacheInfo {
// /** op */
// const Op* op;
// /** input tensors */
// std::vector<Tensor*> inputs;
// /** output tensors */
// std::vector<Tensor*> outputs;
// /** schedule type*/
// Schedule::Type type = Schedule::Type::SEPARATE;
//
// /**Command buffer for cache*/
// CommandBuffer cacheBuffer;
//
// /**Command buffer for execute*/
// CommandBuffer executeBuffer;
//
// std::map<const Op*, std::shared_ptr<Execution>> executionCache;
// };
//
ErrorCode Pipeline::allocMemory(bool firstMalloc, bool forbidReplace) {
// MNN_PRINT("allocMemory mtype:%d, cpubackendType:%d, cpuBackend runtime:%p\n", mBackend->type(), mBackupBackend->type(), mBackupBackend->getRuntime());
if (!firstMalloc) {
// For session setNeedMalloc, if session's output is set as some input, It may cause error
// Dup des to avoid it
for (auto& info : mInfo.second) {
auto& buffer = info.executeBuffer;
for (const auto& infoP : buffer.command) {
auto& info = *infoP;
for (auto t : info.workOutputs) {
if (!TensorUtils::getDescribe(t)->isMutable) {
continue;
}
auto des = TensorUtils::getDescribe(t);
auto usage = des->usage;
if (TensorUtils::getDescribeOrigin(t)->mContent->count() > 1) {
TensorUtils::getDescribeOrigin(t)->mContent = new Tensor::InsideDescribe::NativeInsideDescribe;
auto dstDes = TensorUtils::getDescribe(t);
t->buffer().dim = dstDes->dims;
::memcpy(t->buffer().dim, des->dims, MNN_MAX_TENSOR_DIM * sizeof(halide_dimension_t));
dstDes->dimensionFormat = des->dimensionFormat;
dstDes->usage = usage;
dstDes->regions = des->regions;
dstDes->quantAttr = des->quantAttr;
dstDes->tensorArrayAttr = des->tensorArrayAttr;
}
}
}
}
}
// mInfo 类型为 typedef std::pair<BackendCache, std::vector<OpCacheInfo>> PipelineInfo;
// 开始创建 Execution
/* Create Execution Begin */
// mInfo.first 类型为 BackendCache
// mInfo.first.cache.first 类型为 std::shared_ptr<Backend>,即主动创建的 VulkanBackend
auto& mBackend = mInfo.first.cache.first;
// mInfo.first.cache.second 类型为 std::shared_ptr<Backend>,即后备 CPUBackend
auto& mBackupBackend = mInfo.first.cache.second;
mBackend->onClearBuffer();
mBackupBackend->onClearBuffer();
// Check If we need a lone time for init
if (mBackend->type() != MNN_FORWARD_CPU && mBackend->type() != MNN_FORWARD_CPU_EXTENSION && mTuneAttr.autoSetOpType) {
Runtime::OpInfo dstInfo;
int currentInitCount = 0;
std::vector<Schedule::OpCacheInfo> initInfos;
for (auto& info : mInfo.second) {
auto& buffer = info.executeBuffer;
for (auto& iterP : buffer.command) {
auto& iter = *iterP;
dstInfo.initCostLong = false;
mRuntime->onMeasure(iter.inputs, iter.outputs, iter.op, dstInfo);
if (dstInfo.initCostLong) {
initInfos.emplace_back(info);
currentInitCount++;
break;
}
}
if (currentInitCount >= mTuneAttr.maxTuningNumber) {
break;
}
}
if (currentInitCount > 0) {
MNN_PRINT("Turn back to cpu\n");
// Reset execution
for (auto& info : mInfo.second) {
info.executionCache.clear();
for (auto& iterP : info.executeBuffer.command) {
iterP->execution = nullptr;
iterP->execution = nullptr;
_recycleDynamicMemory(iterP.get());
}
}
if (!mRuntime->hasAsyncWork()) {
_pushTuningTask(std::move(initInfos));
}
mBackend.reset(mCpuRuntime->onCreate(nullptr));
}
}
{
// 创建 Execution
auto code = _createExecutions(mInfo);
if (NO_ERROR != code) {
return code;
}
}
/* Create Execution End */
_SetTensorBackend(mInfo, mAllocInput);
// Insert Wrap If needed
{
auto insertCode = _InsertCopy(mInfo, mCacheConstTensors, mShapeFixConstCache, mAllocInput, forbidReplace);
if (NO_ERROR != insertCode) {
return insertCode;
}
}
/* Insert Wrap End*/
// Compute RefCount Begin
for (auto& info : mInfo.second) {
auto& buffer = info.executeBuffer;
// MNN_PRINT("before resize, mInfo.second size:%lu, command size:%lu,op type:%s, op name:%s\n", mInfo.second.size(), buffer.command.size(), EnumNameOpType(info.op->type()), info.op->name()->c_str());
for (auto& iterP : buffer.command) {
auto& iter = *iterP;
for (auto t : iter.workInputs) {
auto des = TensorUtils::getDescribe(t);
if (des->usage != Tensor::InsideDescribe::CONSTANT) {
des->useCount = 0;
}
}
}
}
for (auto& info : mInfo.second) {
auto& buffer = info.executeBuffer;
for (auto& iterP : buffer.command) {
auto& iter = *iterP;
for (auto t : iter.workInputs) {
auto des = TensorUtils::getDescribe(t);
if (des->usage != Tensor::InsideDescribe::CONSTANT) {
des->useCount += 1;
}
}
}
}
// Compute RefCount End
// Alloc tensor
mBackend->onResizeBegin();
mBackupBackend->onResizeBegin();
for (auto& info : mInfo.second) {
auto& buffer = info.executeBuffer;
for (int cmdIndex=0; cmdIndex < buffer.command.size(); ++cmdIndex) {
auto& iterP = buffer.command[cmdIndex];
auto& iter = *iterP;
#ifdef MNN_PIPELINE_DEBUG
auto memory = const_cast<Runtime*>(mRuntime)->onGetMemoryInMB();
if (nullptr != info.op->name()) {
MNN_PRINT("%f, before Resize: %s - %d\n", memory, info.op->name()->c_str(), cmdIndex);
}
#endif
// MNN_PRINT("before Resize: optype:%s, name:%s, input0:%p, output0:%p, mAllocInput:%d\n", EnumNameOpType(iter.op->type()), iter.info->name().c_str(), iter.inputs[0], iter.outputs[0], mAllocInput);
// Alloc for Tensors
auto curBackend = iter.execution->backend();
if (mAllocInput) {
for (auto t : iter.workInputs) {
auto allocRes = _allocTensor(t, curBackend, mOutputStatic);
if (!allocRes) {
return OUT_OF_MEMORY;
}
}
}
{
for (auto t : iter.workOutputs) {
auto res = _allocTensor(t, curBackend, mOutputStatic);
if (!res) {
return OUT_OF_MEMORY;
}
}
}
#ifdef MNN_PIPELINE_DEBUG
if (iter.info != nullptr) {
MNN_PRINT("before Resize 2, calling: %s - %d \n", iter.info->name().c_str(), cmdIndex);
}
#endif
auto code = iter.execution->onResize(iter.workInputs, iter.workOutputs);
if (NO_ERROR != code) {
#ifdef MNN_PIPELINE_DEBUG
MNN_ERROR("Pipeline Resize error: %d\n", code);
#endif
if (iter.info.get()) {
MNN_ERROR("Resize error for type = %s, name = %s \n", iter.info->type().c_str(), iter.info->name().c_str());
}
return code;
}
// Free mid tensor
for (auto t : iter.workInputs) {
_releaseTensor(t, mAllocInput);
}
}
}
// Recycle All Dynamic Tensor
for (auto& info : mInfo.second) {
auto& buffer = info.executeBuffer;
for (auto& c : buffer.command) {
_recycleDynamicMemory(c.get());
}
}
auto code = mBackend->onResizeEnd();
if (code != NO_ERROR) {
return code;
}
code = mBackupBackend->onResizeEnd();
return code;
}
1.1.1.1.1 _createExecutions
OpCacheInfo 、BackendCache、Command、CommandBuffer
// source/core/Pipeline.cpp
// typedef std::pair<BackendCache, std::vector<OpCacheInfo>> PipelineInfo;
//
// struct BackendCache {
// Backend::Info info;
// BackendConfig config;
// std::pair<std::shared_ptr<Backend>, std::shared_ptr<Backend>> cache;
// bool needComputeShape = true;
// bool needComputeGeometry = true;
// bool reportError = true;
// std::map<Tensor*, TENSORCACHE> inputTensorCopyCache;
// };
//
// /** pipeline info */
// struct OpCacheInfo {
// /** op */
// const Op* op;
// /** input tensors */
// std::vector<Tensor*> inputs;
// /** output tensors */
// std::vector<Tensor*> outputs;
// /** schedule type*/
// Schedule::Type type = Schedule::Type::SEPARATE;
//
// /**Command buffer for cache*/
// CommandBuffer cacheBuffer;
//
// /**Command buffer for execute*/
// CommandBuffer executeBuffer;
//
// std::map<const Op*, std::shared_ptr<Execution>> executionCache;
// };
//
static ErrorCode _createExecutions(Schedule::PipelineInfo& mInfo) {
// mInfo.first 类型为 BackendCache
// mInfo.first.cache.first 类型为 std::shared_ptr<Backend>,即主动创建的 VulkanBackend
auto& mBackend = mInfo.first.cache.first;
// mInfo.first.cache.second 类型为 std::shared_ptr<Backend>,即后备 CPUBackend
auto& mBackupBackend = mInfo.first.cache.second;
// mInfo.second 类型为 std::vector<OpCacheInfo>
for (auto& info : mInfo.second) {
auto& buffer = info.executeBuffer;
// MNN_PRINT("before resize, mInfo.second size:%lu, command size:%lu,op type:%s, op name:%s\n", mInfo.second.size(), buffer.command.size(), EnumNameOpType(info.op->type()), info.op->name()->c_str());
// buffer 类型为 CommandBuffer
// buffer.command 类型为 std::vector<SharedPtr<Command>>
for (auto& iterP : buffer.command) {
auto& iter = *iterP;
// Create exe
// Find Cache
// 先从缓存中找,没有则创建 execution
bool cached = false;
if (nullptr == iter.execution) {
/** Cache origin execution for fast resize*/
auto exeIter = info.executionCache.find(iter.op);
if (exeIter != info.executionCache.end()) {
iter.execution = exeIter->second;
cached = true;
}
}
if (nullptr == iter.execution) {
// 先使用指定的 Backend(如 CPUBackend )创建
// iter 类型为 Command
// iter.execution 类型为 std::shared_ptr<Execution> execution;
iter.execution.reset(mBackend->onCreate(iter.inputs, iter.outputs, iter.op));
}
if (nullptr == iter.execution) {
// Try Backup
// 没创建成功则使用后备 Backend(如 VulkanBackend )创建
iter.execution.reset(mBackupBackend->onCreate(iter.inputs, iter.outputs, iter.op));
if (nullptr == iter.execution) {
if (mInfo.first.reportError) {
MNN_ERROR("Create execution error : %d\n", iter.op->type());
}
return NOT_SUPPORT;
}
}
// invalid means memory alloc failed
if (!iter.execution->valid()) {
iter.execution = nullptr;
iter.execution = nullptr;
return OUT_OF_MEMORY;
}
if ((!cached) && iter.buffer == nullptr && (iter.op->type() != OpType_Raster) && (iter.op->type() != OpType_BinaryOp)) {
// info 类型为 OpCacheInfo
// info.executionCache 类型为 std::map<const Op*, std::shared_ptr<Execution>>
info.executionCache.insert(std::make_pair(iter.op, iter.execution));
}
}
}
return NO_ERROR;
}
1.1.1.1.1.1 VulkanBackend::onCreate
在函数 _createExecutions 中调用 VulkanBackend::onCreate 函数的代码如下:
iter.execution.reset(mBackend->onCreate(iter.inputs, iter.outputs, iter.op));
由于 mBackend 是 VulkanBackend(继承 Backend),所以实际调用的是 VulkanBackend::onCreate,其具体实现代码如下:
// source/backend/vulkan/image/backend/VulkanBackend.cpp
Execution* VulkanBackend::onCreate(const std::vector<Tensor*>& inputs, const std::vector<Tensor*>& outputs,
const MNN::Op* op) {
auto creator = getCreatorMap();
auto iter = creator->find(op->type());
std::string name = "";
if (nullptr != op->name()) {
name = op->name()->str();
}
if (iter == creator->end()) {
#ifdef MNN_OP_SUPPORT_LOG
MNN_PRINT("Vulkan don't support %d, %s: %s\n", op->type(), EnumNameOpType(op->type()),
name.c_str());
#endif
return nullptr;
}
bool valid = true;
for (int i=0; i<inputs.size(); ++i) {
if (!OpCommonUtils::opNeedContent(op, i)) {
continue;
}
auto t = inputs[i];
auto inputDes = TensorUtils::getDescribe(t);
if (inputDes->memoryType == Tensor::InsideDescribe::MEMORY_VIRTUAL) {
for (auto& r : inputDes->regions) {
if (!_supportImageSize(r.origin)) {
valid = false;
break;
}
}
if (!valid) {
break;
}
} else {
if (!_supportImageSize(t)) {
valid = false;
break;
}
}
}
for (auto t : outputs) {
if (!_supportImageSize(t)) {
valid = false;
break;
}
}
if (!valid) {
#ifdef MNN_OP_SUPPORT_LOG
MNN_ERROR("Vulkan don't support for %s, type=%s, Tensor not support\n", name.c_str(), EnumNameOpType(op->type()));
#endif
return nullptr;
}
// iter->second 类型为 MNN::VulkanBackend::Creator *,即调用具体的创建算子计算实现
auto originExecution = (VulkanBasicExecution*)iter->second->onCreate(inputs, outputs, op, this);
if (nullptr == originExecution) {
#ifdef MNN_OP_SUPPORT_LOG
MNN_ERROR("Vulkan don't support for %s, type=%s, Special case\n", name.c_str(), EnumNameOpType(op->type()));
#endif
return nullptr;
}
if (mDirect) {
return new VulkanBasicExecutionDirect(std::shared_ptr<VulkanBasicExecution>(originExecution));
}
return new VulkanBasicExecutionInDirect(std::shared_ptr<VulkanBasicExecution>(originExecution));
}
1.1.1.1.1.1.1 VulkanBackend::Creator::onCreate
在函数 VulkanBackend::onCreate 中调用 VulkanBackend::Creator::onCreate 函数的代码如下:
auto creator = getCreatorMap();
auto iter = creator->find(op->type());
// iter->second 类型为 MNN::VulkanBackend::Creator *,即调用具体的创建算子计算实现
auto originExecution = (VulkanBasicExecution*)iter->second->onCreate(inputs, outputs, op, this);
备注:iter->second->onCreate 调用是个多态,实际运行中根据算子类型 opType ,调用不同的子类。其基类为 VulkanBackend::Creator 。
其中一个实现类为 VulkanConvolutionCreator ,具体实现代码如下:
// source/backend/vulkan/image/execution/VulkanConvolution.cpp
class VulkanConvolutionCreator : public VulkanBackend::Creator {
public:
virtual VulkanBasicExecution* onCreate(const std::vector<Tensor*>& inputs, const std::vector<Tensor*>& outputs, const MNN::Op* op,
Backend* backend) const override {
auto extra = static_cast<VulkanBackend *>(backend);
auto convReal = op->main_as_Convolution2D();
auto common = convReal->common();
auto outputCount = common->outputCount();
const int fh = common->kernelY();
const int fw = common->kernelX();
int srcCount = 0;
const float* source = nullptr;
const float* biasPtr = nullptr;
int weightSize = 0;
std::shared_ptr<ConvolutionCommon::Int8Common> quanWeight;
if (nullptr != op->main_as_Convolution2D()->quanParameter()) {
auto quan = op->main_as_Convolution2D()->quanParameter();
if (1 == quan->type() || 2 == quan->type()) {
if (quan->has_scaleInt()) {
// Don't support IDST-int8 because of error
return nullptr;
}
}
quanWeight = ConvolutionCommon::load(op->main_as_Convolution2D(), backend, true);
srcCount = quanWeight->weightFloat.size() / (outputCount * fh * fw);
source = quanWeight->weightFloat.get();
weightSize = quanWeight->weightFloat.size();
} else {
if (nullptr != convReal->weight()) {
srcCount = convReal->weight()->size() / (outputCount * fh * fw);
source = convReal->weight()->data();
weightSize = convReal->weight()->size();
} else {
srcCount = convReal->common()->inputCount();
}
}
if (nullptr != convReal->bias()) {
biasPtr = convReal->bias()->data();
}
if (op->type() == OpType_Convolution) {
if (inputs.size() > 1) {
return nullptr;
}
auto convCommonParam = op->main_as_Convolution2D()->common();
const int group = convCommonParam->group();
if (1 == group) {
return VulkanConvolutionImpl::create(extra, common, inputs, outputs[0], source,
biasPtr, srcCount, outputCount);
} else {
return nullptr;
}
}
return new VulkanConvolutionDepthwise(source, weightSize, op, backend);
}
};
static bool gResistor = []() {
VulkanBackend::addCreator(OpType_Convolution, new VulkanConvolutionCreator);
VulkanBackend::addCreator(OpType_ConvolutionDepthwise, new VulkanConvolutionCreator);
return true;
}();
1.1.1.1.1.1.2 VulkanBasicExecution
VulkanBasicExecution 为 Vulkan 算子基类,其具体实现如下:
// source/backend/vulkan/image/execution/VulkanBasicExecution.hpp
class VulkanBasicExecution {
public:
VulkanBasicExecution(Backend *bn) : mBackend(bn) {
//Do nothing
}
virtual ~VulkanBasicExecution() = default;
virtual ErrorCode onEncode(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs,
const VulkanCommandPool::Buffer *cmdBuffer) = 0;
Backend* backend() {
return mBackend;
}
private:
Backend* mBackend;
};
1.1.1.1.1.1.3 Vulkan 算子执行实例注册
VulkanBackend::onCreate 函数中有个 gCreator 成员,其缓存了所有的 Vulkan 算子执行创建实例 VulkanBackend::Creator,其初始化分布在各个 VulkanBackend::Creator 实例代码中,采用静态初始化执行的方式进行注册。
// source/backend/vulkan/image/execution/VulkanConvolution.cpp
static bool gResistor = []() {
VulkanBackend::addCreator(OpType_Convolution, new VulkanConvolutionCreator);
VulkanBackend::addCreator(OpType_ConvolutionDepthwise, new VulkanConvolutionCreator);
return true;
}();
VulkanBackend::addCreator 实现如下:
// source/backend/vulkan/image/backend/VulkanBackend.cpp
bool VulkanBackend::addCreator(OpType t, Creator* c) {
auto allKind = getCreatorMap();
allKind->insert(std::make_pair(t, c));
return true;
}
static std::map<OpType, VulkanBackend::Creator*>* gCreator = nullptr;
// Creator
static inline std::map<OpType, VulkanBackend::Creator*>* getCreatorMap() {
if (nullptr == gCreator) {
gCreator = new std::map<OpType, VulkanBackend::Creator*>();
}
return gCreator;
}
添加Vulkan实现
-
添加Shader
在source/backend/vulkan/execution/glsl目录下添加具体的shader(*.comp)。若输入内存布局为NC4HW4,则按image实现,否则采用buffer实现。可以参考目录下已有实现。然后,执行makeshader.py脚本编译Shader。 -
实现类声明
在目录source/backend/vulkan/execution/下添加VulkanMyCustomOp.hpp和VulkanMyCustomOp.cpp:
class VulkanMyCustomOp : public VulkanBasicExecution {
public:
VulkanMyCustomOp(const Op* op, Backend* bn);
virtual ~VulkanMyCustomOp();
ErrorCode onEncode(const std::vector<Tensor*>& inputs,
const std::vector<Tensor*>& outputs,
const VulkanCommandPool::Buffer* cmdBuffer) override;
private:
// GPU Shader所需的参数
std::shared_ptr<VulkanBuffer> mConstBuffer;
// Pipeline
const VulkanPipeline* mPipeline;
// Layout Descriptor Set
std::shared_ptr<VulkanPipeline::DescriptorSet> mDescriptorSet;
};
-
实现
实现函数onEncode,首先需要做内存布局检查:若为NC4HW4,则Shader用image实现,否则用buffer。执行完毕返回NO_ERROR。 -
注册实现类
class VulkanMyCustomOpCreator : public VulkanBackend::Creator {
public:
virtual Execution* onCreate(const std::vector<Tensor*>& inputs,
const MNN::Op* op,
Backend* backend) const override {
return new VulkanMyCustomOp(op, backend);
}
};
static bool gResistor = []() {
VulkanBackend::addCreator(OpType_MyCustomOp, new VulkanMyCustomOpCreator);
return true;
}();
添加Metal实现
-
添加Shader
在source/backend/Metal目录下添加MetalMyCustomOp.metal,并添加进Xcode工程。metal可以参考目录下已有实现。 -
实现类声明
在source/backend/Metal目录下添加MetalMyCustomOp.hpp和MetalMyCustomOp.cpp,并添加进Xcode工程:
class MetalMyCustomOp : public Execution {
public:
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
};
- 实现
onResize和onExecute
不同于CPU Tensor将数据存储在host指针中,Metal数据指针存放在deviceId中,deviceId上存储的是id<MTLBuffer>:
auto buffer = (__bridge id<MTLBuffer>)(void *)tensor->deviceId();
Metal Op的特定参数等可以通过id<MTLBuffer>存储。buffer数据类型可以与tensor不同,buffer甚至可以混合多种数据类型,只需保证创建时指定了正确的长度即可。例如:
auto buffer = [context newDeviceBuffer:2 * sizeof(int) + 2 * sizeof(__fp16) access:CPUWriteOnly];
((__fp16 *)buffer.contents)[0] = mAlpha / mLocalSize; // alpha
((__fp16 *)buffer.contents)[1] = mBeta; // beta
((int *)buffer.contents)[1] = mLocalSize; // local size
((int *)buffer.contents)[2] = inputs[0]->channel(); // channel
在创建buffer时,需要指定访问控制权限。目前共有三种权限:
CPUReadWrite,数据在CPU/GPU间共享存储,一般用于device buffer;CPUWriteOnly,数据通过CPU写入后不再读取,一般用于参数buffer;CPUTransparent,数据只在GPU中,一般用于heap buffer;
MNNMetalContext在创建buffer上,有两套相近的接口,区别只在数据的生命周期上:
- device占用的内存在单次推理过程中都不会被复用;
- 而heap占用的内存,在调用
-[MNNMetalContext releaseHeapBuffer:]之后,可以被其他Op复用;
一般而言,heap只会与CPUTransparent一起使用。heap实际只在iOS 10+上有效,iOS 9-上会回退到device上。
使用Metal时,如非特殊情况,禁止自行创建device和library。加载library、编译function都是耗时行为,MNNMetalContext上做了必要的缓存优化。通过context执行Metal的示例如下:
auto context = (__bridge MNNMetalContext *)backend->context();
auto kernel = /* metal kernel name NSString */;
auto encoder = [context encoder];
auto bandwidth = [context load:kernel encoder:encoder];
/* encoder set buffer(s)/sampler(s) */
[context dispatchEncoder:encoder
threads:{x, y, z}
maxThreadsPerGroup:maxThreadsPerThreadgroup]; // recommended way to dispatch
[encoder endEncoding];
- 注册实现类
class MetalMyCustomOpCreator : public MetalBackend::Creator {
public:
virtual Execution *onCreate(const std::vector<Tensor *> &inputs,
const MNN::Op *op, Backend *backend) const {
return new MetalMyCustomOp(backend);
}
};
REGISTER_METAL_OP_CREATOR(MetalMyCustomOpCreator, OpType_MyCustomOp);
添加注册代码后,重新运行一下 CMake ,自动变更注册文件
添加OpenCL实现
-
添加Kernel
在source/backend/opencl/execution/cl目录添加具体的kernel(*.cl)。目前feature map均使用image2d实现。可以参考目录下已有实现。然后执行opencl_codegen.py来生成kernel映射。 -
实现类声明
在目录source/backend/opencl/execution/下添加MyCustomOp.h和MyCustomOp.cpp:
template <typename T>
class MyCustomOp : public Execution {
public:
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
};
-
实现
实现函数onResize(可选)、onExecute。执行完毕返回NO_ERROR。 -
注册实现类
OpenCLCreatorRegister<TypedCreator<MyCustomOp<cl_data_t>>> __my_custom_op(OpType_MyCustomOp);
添加OpenGL实现
-
添加Shader
在source/backend/opengl/glsl下添加具体的shader(*.glsl),不用加文件头,feature map 均采用image3d表示。可以参考目录下已有实现。而后,在source/backend/opengl目录下执行makeshader.py。 -
添加Executor
在source/backend/opengl/execution/目录下添加GLMyCustomOp.h和GLMyCustomOp.cpp:
class GLMyCustomOp : public Execution {
public:
GLMyCustomOp(const std::vector<Tensor *> &inputs, const Op *op, Backend *bn);
virtual ~GLMyCustomOp();
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs,
const std::vector<Tensor *> &outputs) override;
private:
std::shared_ptr<GLProgram> mProgram;
};
-
实现
实现函数onResize(可选)、onExecute。执行完毕返回NO_ERROR。 -
注册实现类-
GLCreatorRegister<TypedCreator<GLMyCustomOp>> __my_custom_op(OpType_MyCustomOp);
1.1.1.1.1.1.4 VulkanBasicExecutionDirect
// source/backend/vulkan/image/execution/VulkanBasicExecution.hpp
class VulkanBasicExecutionDirect : public Execution {
public:
VulkanBasicExecutionDirect(std::shared_ptr<VulkanBasicExecution> encoder);
virtual ~ VulkanBasicExecutionDirect() = default;
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) override;
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) override;
private:
std::shared_ptr<VulkanBasicExecution> mEncoder;
std::shared_ptr<VulkanCommandPool::Buffer> mCmdBuffer;
};
1.1.1.1.1.1.5 VulkanBasicExecutionDirect::VulkanBasicExecutionDirect
// source/backend/vulkan/image/execution/VulkanBasicExecution.cpp
VulkanBasicExecutionDirect::VulkanBasicExecutionDirect(std::shared_ptr<VulkanBasicExecution> encoder) : Execution(encoder->backend()) {
mEncoder = encoder;
auto extra = static_cast<VulkanBackend *>(encoder->backend());
mCmdBuffer.reset(const_cast<VulkanCommandPool::Buffer *>(extra->getPool().allocBuffer()));
}
1.1.1.1.1.1.6 VulkanBasicExecutionInDirect
// source/backend/vulkan/image/execution/VulkanBasicExecution.hpp
class VulkanBasicExecutionInDirect : public Execution {
public:
VulkanBasicExecutionInDirect(std::shared_ptr<VulkanBasicExecution> encoder);
virtual ~ VulkanBasicExecutionInDirect() = default;
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) override {
return NO_ERROR;
}
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) override;
private:
std::shared_ptr<VulkanBasicExecution> mEncoder;
};
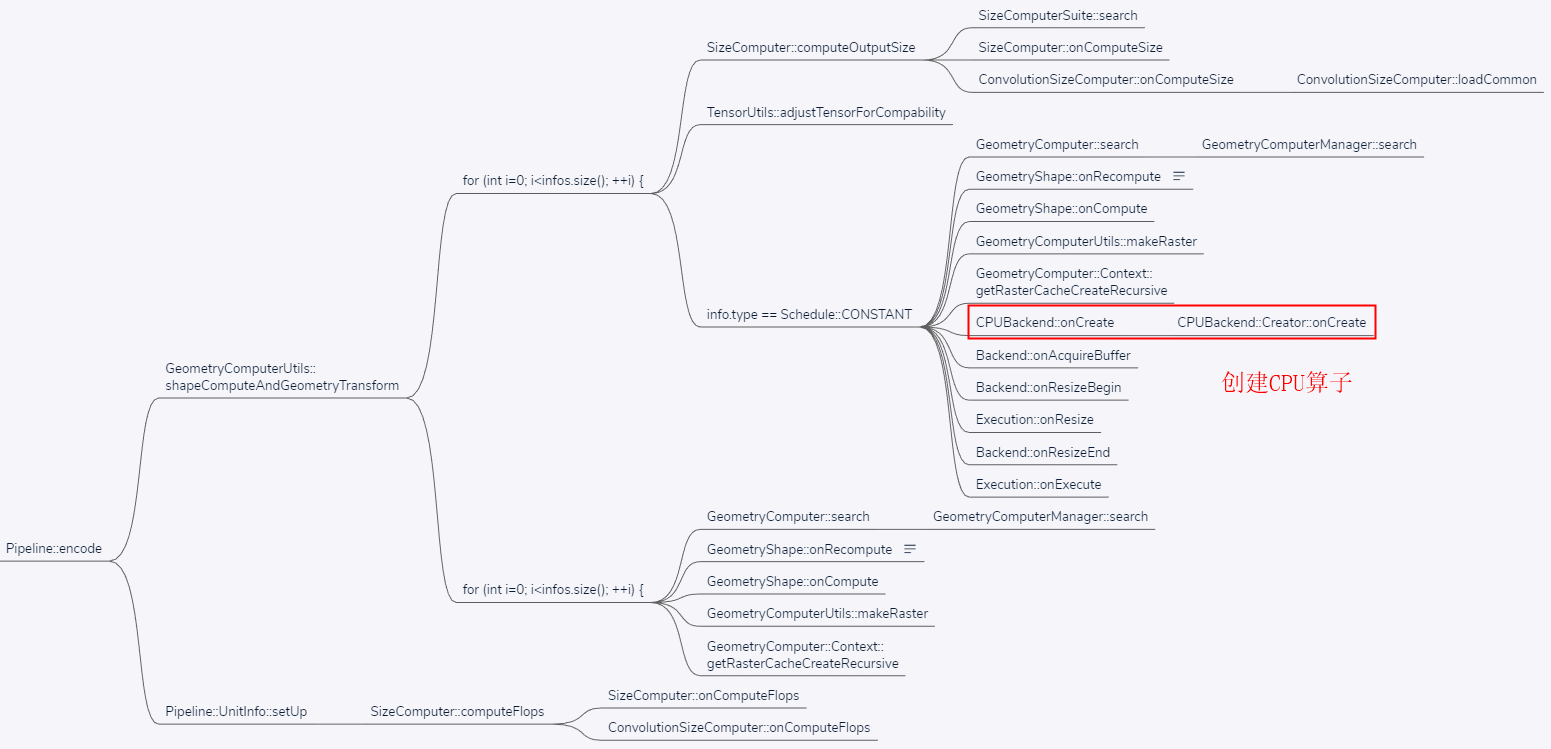
1.1.1.1.1.2 CPUBackend::onCreate
在函数 _createExecutions 中先调用 VulkanBackend::onCreate 创建算子执行器,没创建成功则采用后备 CPUBackend::onCreate 进行创建。
if (nullptr == iter.execution) {
// 先使用指定的 Backend(如 CPUBackend )创建
// iter 类型为 Command
// iter.execution 类型为 std::shared_ptr<Execution> execution;
iter.execution.reset(mBackend->onCreate(iter.inputs, iter.outputs, iter.op));
}
if (nullptr == iter.execution) {
// Try Backup
// 没创建成功则使用后备 Backend(如 VulkanBackend )创建
iter.execution.reset(mBackupBackend->onCreate(iter.inputs, iter.outputs, iter.op));
if (nullptr == iter.execution) {
if (mInfo.first.reportError) {
MNN_ERROR("Create execution error : %d\n", iter.op->type());
}
return NOT_SUPPORT;
}
}
关于 CPUBackend::onCreate 的分析见传送门。
1.1.1.1.2 Backend::onResizeBegin
在函数 Pipeline::allocMemory 中调用 VulkanBackend::onResizeBegin 和 CPUBackend::onResizeBegin 函数的代码如下:
mBackend->onResizeBegin();
mBackupBackend->onResizeBegin();
onResizeBegin 函数是个虚函数,由于 mBackend 是 VulkanBackend(继承 Backend) ,所以实际调用的是 VulkanBackend::onResizeBegin,其具体实现代码如下:
// source/backend/vulkan/image/backend/VulkanBackend.cpp
void VulkanBackend::onResizeBegin() {
mInitBuffer->begin(0);
if (!mDirect) {
mCmdBuffer->begin(0);
}
}
mBackupBackend 是 CPUBackend(继承 Backend),其具体实现见传送门。
1.1.1.1.3 Execution::onResize
在函数 GeometryComputerUtils::shapeComputeAndGeometryTransform 中调用 Execution::onResize 函数的代码如下:
backupBackend->onResizeBegin();
auto code = exe->onResize(c.inputs, c.outputs);
// ...
code = backupBackend->onResizeEnd();
// ...
code = exe->onExecute(c.inputs, c.outputs);
// ...
onResize 函数是个虚函数, exe 创建逻辑见 CPUBackend::onCreate ,exe->onResize 调用是个多态,其基类为 Execution,我们选择一个实例 CPULoop 进行分析,其具体实现代码如下:
// source/backend/cpu/CPURaster.cpp
void VulkanBackend::onResizeBegin() {
mInitBuffer->begin(0);
if (!mDirect) {
mCmdBuffer->begin(0);
}
}
1.1.1.1.4 Backend::onResizeEnd
在函数 Pipeline::allocMemory 中调用 VulkanBackend::onResizeEnd 和 CPUBackend::onResizeEnd 函数的代码如下:
auto code = mBackend->onResizeEnd();
if (code != NO_ERROR) {
return code;
}
code = mBackupBackend->onResizeEnd();
onResizeEnd 函数是个虚函数,由于 mBackend 是 VulkanBackend(继承 Backend) ,所以实际调用的是 VulkanBackend::onResizeEnd,其具体实现代码如下:
// source/backend/vulkan/image/backend/VulkanBackend.cpp
mBackupBackend 是 CPUBackend(继承 Backend),其具体实现见传送门。
1.1.1.1.5 Execution::onExecute
在函数 GeometryComputerUtils::shapeComputeAndGeometryTransform 中调用 Execution::onExecute 函数的代码如下:
backupBackend->onResizeBegin();
auto code = exe->onResize(c.inputs, c.outputs);
// ...
code = backupBackend->onResizeEnd();
// ...
code = exe->onExecute(c.inputs, c.outputs);
// ...
onExecute 函数是个虚函数, exe 创建逻辑见 CPUBackend::onCreate ,exe->onExecute 调用是个多态,其基类为 Execution,我们选择一个实例 CPULoop 进行分析,其具体实现代码如下:
// source/backend/cpu/CPURaster.cpp
class CPULoop : public Execution {
virtual ErrorCode onExecute(const std::vector<Tensor *> &originInputs, const std::vector<Tensor *> &originOutputs) override {
auto cpubackend = static_cast<CPUBackend*>(backend());
auto precision = cpubackend->precisionMode();
auto threadNumber = cpubackend->threadNumber();
if (mLoop->initCommand() != nullptr) {
for (int i=0; i<mLoop->initCommand()->size(); ++i) {
auto cmd = mLoop->initCommand()->GetAs<RegionCommand>(i);
if (cmd->op() == nullptr) {
auto output = mStack[cmd->indexes()->data()[0]];
::memset(output->host<void>(), 0, cpubackend->getTensorSize(output) * cpubackend->functions()->bytes);
} else {
Tensor::InsideDescribe::Region reg;
auto srcView = cmd->view()->GetAs<View>(1);
auto dstView = cmd->view()->GetAs<View>(0);
::memcpy(reg.size, cmd->size()->data(), 3 * sizeof(int32_t));
::memcpy(reg.src.stride, srcView->stride()->data(), 3 * sizeof(int32_t));
::memcpy(reg.dst.stride, dstView->stride()->data(), 3 * sizeof(int32_t));
auto input = mStack[cmd->indexes()->data()[1]];
auto inputSize = input->elementSize();
auto output = mStack[cmd->indexes()->data()[0]];
auto bytes = input->getType().bytes();
if (halide_type_float == input->getType().code) {
bytes = cpubackend->functions()->bytes;
}
_blit(reg, bytes, input->host<uint8_t>(), output->host<uint8_t>());
}
}
}
if (1 == mLoop->commands()->size()) {
auto cmd = mLoop->commands()->GetAs<RegionCommand>(0);
auto op = cmd->op();
if (OpType_UnaryOp == op->type() && nullptr == op->main() && cmd->fuse() < 0) {
// For Gather / Single Unary
auto index0 = cmd->iterIndexes()->data()[0];
auto index1 = cmd->iterIndexes()->data()[1];
int32_t iter = 0;
int32_t* iter0 = &iter;
int32_t* iter1 = &iter;
int32_t iter0Stride = 0;
int32_t iter1Stride = 0;
if (index0 >= 0) {
iter0 = originInputs[index0]->host<int32_t>();
iter0Stride = 1;
}
if (index1 >= 0) {
iter1 = originInputs[index1]->host<int32_t>();
iter1Stride = 1;
}
Tensor::InsideDescribe::Region reg;
auto srcView = cmd->view()->GetAs<View>(1);
auto dstView = cmd->view()->GetAs<View>(0);
::memcpy(reg.size, cmd->size()->data(), 3 * sizeof(int32_t));
::memcpy(reg.src.stride, srcView->stride()->data(), 3 * sizeof(int32_t));
::memcpy(reg.dst.stride, dstView->stride()->data(), 3 * sizeof(int32_t));
auto input = mStack[cmd->indexes()->data()[1]];
auto inputSize = input->elementSize();
auto output = mStack[cmd->indexes()->data()[0]];
auto bytes = input->getType().bytes();
if (halide_type_float == input->getType().code) {
bytes = static_cast<CPUBackend*>(backend())->functions()->bytes;
}
auto step0 = cmd->steps()->data()[0];
auto step1 = cmd->steps()->data()[1];
auto loopNumber = mLoop->loopNumber();
for (; iter<loopNumber; ++iter) {
auto srcIter = *(iter1 + iter1Stride * iter);
auto dstIter = *(iter0 + iter0Stride * iter);
auto srcOffset = srcIter * step1 + srcView->offset();
auto dstOffset = dstIter * step0 + dstView->offset();
if (dstOffset >= 0) {
if (srcOffset >= 0 && srcOffset < inputSize) {
_blit(reg, bytes, input->host<uint8_t>() + bytes * srcOffset, output->host<uint8_t>() + bytes * dstOffset);
} else {
_zero(reg, bytes, output->host<uint8_t>() + bytes * dstOffset);
}
}
}
return NO_ERROR;
}
}
auto bytes = static_cast<CPUBackend*>(backend())->functions()->bytes;
auto func = [&](int iter, int tId) {
int fuseOutputStride[3];
const int32_t* outputStride = nullptr;
auto fuseBuffer = mFuseBuffer + mMaxFuseBufferSize * tId;
for (int index=0; index<mLoop->commands()->size(); ++index) {
auto cmd = mLoop->commands()->GetAs<RegionCommand>(index);
auto blit = _selectUnitProc(bytes, cmd->view()->GetAs<View>(1)->stride()->data()[2], 1);
auto op = cmd->op();
int iterIndexsize = cmd->iterIndexes()->size();
if (cmd->fuse() >= 0) {
outputStride = fuseOutputStride;
auto cmdSize = cmd->size()->data();
fuseOutputStride[0] = cmdSize[1] * cmdSize[2];
fuseOutputStride[1] = cmdSize[2];
fuseOutputStride[2] = 1;
} else {
// Loop Op's command's first index must be output
outputStride = cmd->view()->GetAs<View>(0)->stride()->data();
}
halide_type_t inputType;
for (int v=0; v<iterIndexsize; ++v) {
auto tensorIndex = cmd->indexes()->data()[v];
auto tensor = mStack[tensorIndex];
auto iterIndex = cmd->iterIndexes()->data()[v];
auto offset = iter;
if (1 == v) {
inputType = tensor->getType();
}
if (iterIndex >= 0) {
offset = mStack[iterIndex]->host<int32_t>()[iter];
}
auto view = cmd->view()->GetAs<View>(v);
offset = offset * cmd->steps()->data()[v] + view->offset();
mContainer[tId].stackPtr[tensorIndex] = tensor->host<uint8_t>() + offset * bytes;
MNN_ASSERT(nullptr != tensor->host<uint8_t>());
}
auto dstOrigin = (uint8_t*)mContainer[tId].stackPtr[cmd->indexes()->data()[0]];
auto dst = dstOrigin;
if (cmd->fuse() >= 0) {
dst = fuseBuffer.ptr();
}
do {
if (OpType_UnaryOp == op->type()) {
auto src = (uint8_t*)mContainer[tId].stackPtr[cmd->indexes()->data()[1]];
if (nullptr == op->main()) {
// Copy
Tensor::InsideDescribe::Region reg;
auto srcView = cmd->view()->GetAs<View>(1);
auto dstView = cmd->view()->GetAs<View>(0);
::memcpy(reg.size, cmd->size()->data(), 3 * sizeof(int32_t));
::memcpy(reg.src.stride, srcView->stride()->data(), 3 * sizeof(int32_t));
::memcpy(reg.dst.stride, outputStride, 3 * sizeof(int32_t));
auto step0 = cmd->steps()->data()[0];
auto step1 = cmd->steps()->data()[1];
auto loopNumber = mLoop->loopNumber();
_blit(reg, bytes, (const uint8_t*)src, (uint8_t*)dst);
break;
}
auto proc = static_cast<CPUBackend*>(backend())->functions()->MNNSelectUnaryFunctionForFloat(op->main_as_UnaryOp()->opType(), static_cast<CPUBackend*>(backend())->precisionMode());
auto lastS = cmd->size()->data()[2];
if (lastS == 1 || cmd->view()->GetAs<View>(1)->stride()->data()[2] == 1) {
for (int z=0; z<cmd->size()->data()[0]; ++z) {
auto srcZ = src + z * cmd->view()->GetAs<View>(1)->stride()->data()[0] * bytes;
auto dstZ = dst + z * outputStride[0] * bytes;
for (int y=0; y<cmd->size()->data()[1]; ++y) {
auto srcY = srcZ + y * cmd->view()->GetAs<View>(1)->stride()->data()[1] * bytes;
auto dstY = dstZ + y * outputStride[1] * bytes;
proc(dstY, srcY, lastS);
}
}
} else {
// Blit to cache
auto srcCache = mCacheBuffer.ptr() + mMaxCacheSize * tId;
for (int z=0; z<cmd->size()->data()[0]; ++z) {
auto srcZ = src + z * cmd->view()->GetAs<View>(1)->stride()->data()[0] * bytes;
auto dstZ = dst + z * outputStride[0] * bytes;
for (int y=0; y<cmd->size()->data()[1]; ++y) {
auto srcY = srcZ + y * cmd->view()->GetAs<View>(1)->stride()->data()[1] * bytes;
auto dstY = dstZ + y * outputStride[1] * bytes;
blit(srcCache, srcY, lastS, cmd->view()->GetAs<View>(1)->stride()->data()[2], 1);
proc(dstY, srcCache, lastS);
}
}
}
continue;
}
if (OpType_MatMul == op->type()) {
// TODO: Don't support fuse for matmul currently
const float* APtr = nullptr;
const float* BPtr = nullptr;
const float* BiasPtr = nullptr;
float* CPtr = (float*)dst;
auto exe = static_cast<CPUMatMul*>(mContainer[tId].exe[index].get());
APtr = (const float*)mContainer[tId].stackPtr[cmd->indexes()->data()[1]];
BPtr = (const float*)mContainer[tId].stackPtr[cmd->indexes()->data()[2]];
if (iterIndexsize > 3) {
BiasPtr = (const float*)mContainer[tId].stackPtr[cmd->indexes()->data()[3]];
}
exe->execute(APtr, BPtr, CPtr, BiasPtr);
break;
}
if (OpType_BinaryOp == op->type()) {
auto src0 = mContainer[tId].stackPtr[cmd->indexes()->data()[1]];
MNNBinaryExecute proc;
if (inputType.code == halide_type_float) {
proc = static_cast<CPUBackend*>(backend())->functions()->MNNSelectBinaryFunctionForFloat(op->main_as_BinaryOp()->opType());
} else {
MNN_ASSERT(inputType.code == halide_type_int);
proc = CPUBinary::selectForInt(op->main_as_BinaryOp()->opType());
}
auto lastS = cmd->size()->data()[2];
auto stride0 = outputStride;
auto stride1 = cmd->view()->GetAs<View>(1)->stride()->data();
MNN_ASSERT(stride0[2] == 1);
auto src1 = mContainer[tId].stackPtr[cmd->indexes()->data()[2]];
auto stride2 = cmd->view()->GetAs<View>(2)->stride()->data();
auto blit1 = _selectUnitProc(bytes, stride1[2], 1);
auto blit2 = _selectUnitProc(bytes, stride2[2], 1);
if (cmd->size()->data()[2] == 1 || (stride1[2] == 1 && stride2[2] == 1)) {
for (int z=0; z<cmd->size()->data()[0]; ++z) {
auto src0Z = src0 + z * stride1[0] * bytes;
auto src1Z = src1 + z * stride2[0] * bytes;
auto dstZ = dst + z * stride0[0] * bytes;
for (int y=0; y<cmd->size()->data()[1]; ++y) {
auto src0Y = src0Z + y * stride1[1] * bytes;
auto src1Y = src1Z + y * stride2[1] * bytes;
auto dstY = dstZ + y * stride0[1] * bytes;
proc(dstY, src0Y, src1Y, cmd->size()->data()[2], -1);
}
}
} else {
auto cache0 = mCacheBuffer.ptr() + mMaxCacheSize * tId;
auto cache1 = cache0 + cmd->size()->data()[2] * bytes;
for (int z=0; z<cmd->size()->data()[0]; ++z) {
auto src0Z = src0 + z * stride1[0] * bytes;
auto src1Z = src1 + z * stride2[0] * bytes;
auto dstZ = dst + z * stride0[0] * bytes;
for (int y=0; y<cmd->size()->data()[1]; ++y) {
auto src0Y = src0Z + y * stride1[1] * bytes;
auto src1Y = src1Z + y * stride2[1] * bytes;
auto dstY = dstZ + y * stride0[1] * bytes;
blit1(cache0, src0Y, cmd->size()->data()[2], stride1[2], 1);
blit2(cache1, src1Y, cmd->size()->data()[2], stride2[2], 1);
proc(dstY, cache0, cache1, cmd->size()->data()[2], -1);
}
}
}
break;
}
} while(false);
if (dst != dstOrigin) {
MNN_ASSERT(bytes == 4);
// Currently only support add and float32
auto dstStride = cmd->view()->GetAs<View>(0)->stride()->data();
auto srcF = (const float*)dst;
auto dstF = (float*)dstOrigin;
int sizeZ = cmd->size()->data()[0];
int sizeY = cmd->size()->data()[1];
int sizeX = cmd->size()->data()[2];
if (cmd->op()->type() == OpType_MatMul) {
auto proc = static_cast<CPUBackend*>(backend())->functions()->MNNSelectBinaryFunctionForFloat(cmd->fuse());
proc(dstF, dstF, srcF, sizeZ * sizeX, -1);
continue;
}
switch (cmd->fuse()) {
case BinaryOpOperation_ADD:
for (int z=0; z<sizeZ; ++z) {
auto srcZ = srcF + z * outputStride[0];
auto dstZ = dstF + z * dstStride[0];
for (int y=0; y<sizeY; ++y) {
auto srcY = srcZ + y * outputStride[1];
auto dstY = dstZ + y * dstStride[1];
for (int x=0; x<sizeX; ++x) {
auto dstOffset = x * dstStride[2];
dstY[dstOffset] = dstY[dstOffset] + srcY[x];
}
}
}
break;
case BinaryOpOperation_MUL:
for (int z=0; z<sizeZ; ++z) {
auto srcZ = srcF + z * dstStride[0];
auto dstZ = dstF + z * outputStride[0];
for (int y=0; y<sizeY; ++y) {
auto srcY = srcZ + z * dstStride[1];
auto dstY = dstZ + z * outputStride[1];
for (int x=0; x<sizeX; ++x) {
auto dstOffset = x * dstStride[2];
dstY[dstOffset] = dstY[dstOffset] * srcY[x];
}
}
}
break;
case BinaryOpOperation_SUB:
for (int z=0; z<sizeZ; ++z) {
auto srcZ = srcF + z * dstStride[0];
auto dstZ = dstF + z * outputStride[0];
for (int y=0; y<sizeY; ++y) {
auto srcY = srcZ + z * dstStride[1];
auto dstY = dstZ + z * outputStride[1];
for (int x=0; x<sizeX; ++x) {
auto dstOffset = x * dstStride[2];
auto D = dstY[dstOffset];
auto S = srcY[x];
dstY[dstOffset] = D - S;
}
}
}
break;
default:
break;
}
}
}
};
if (mLoop->parallel()) {
MNN_CONCURRENCY_BEGIN(tId, threadNumber) {
for (int iter=tId; iter < mLoop->loopNumber(); iter+=threadNumber) {
func(iter, tId);
}
}
MNN_CONCURRENCY_END();
} else {
for (int iter=0; iter < mLoop->loopNumber(); ++iter) {
func(iter, 0);
}
}
return NO_ERROR;
}
}
☆