概述
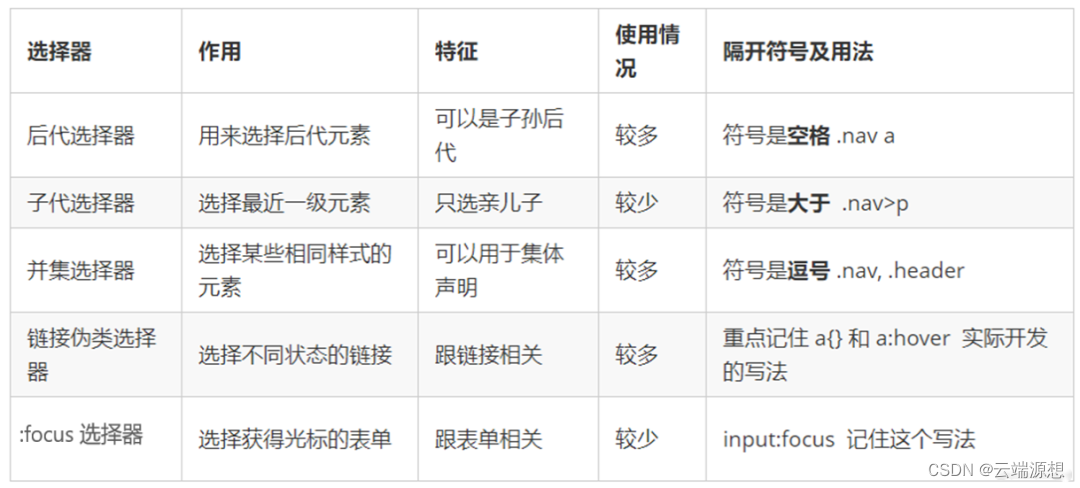
“下推”是数据库管理系统优化查询性能的一种思路,集中式数据库支持谓词下推和投影下推,通过将Filter(过滤)和Project(映射)算子在算子数中向下移动,提前对行/列进行裁剪,减少后续计算处理的数据量。
分布式数据库中,条件涉及字段可能比较多,或者索引字段上使用了函数,导致无法直接使用索引,这时介入端会向远程服务发送全表扫描查询,将数据全表拉回本地执行,这种执行方式是非常低效的,大量数据的网络传输占用带宽,又带来了大量数据的本地拷贝、格式转换等代价。
数据库AntDB-M,将继续沿用集中式数据库的执行思路,将条件下推到远端服务,在远端过滤(Filter)和映射(Project)数据,减少网络I/O和本地格式转换的代价,解决跨节点访问数据的开销。
条件下推
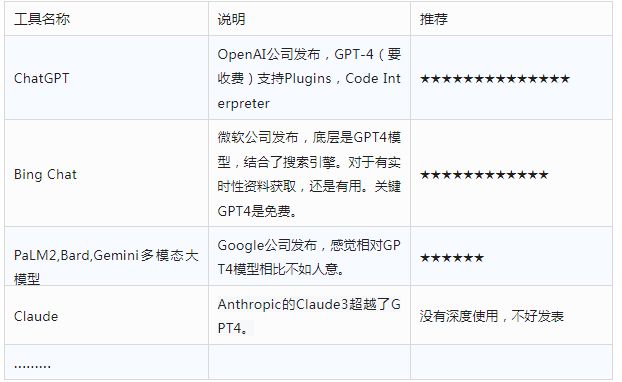
分布式数据库与集中式不同,分布式数据库的数据在不同的数据节点,需要避免过多复杂的算子下推,导致查询性能下降。比如:Hash Join、FileSort、涉及临时表、Agg Merge等。为此,我们简单对其进行分类:
图表1 条件分类
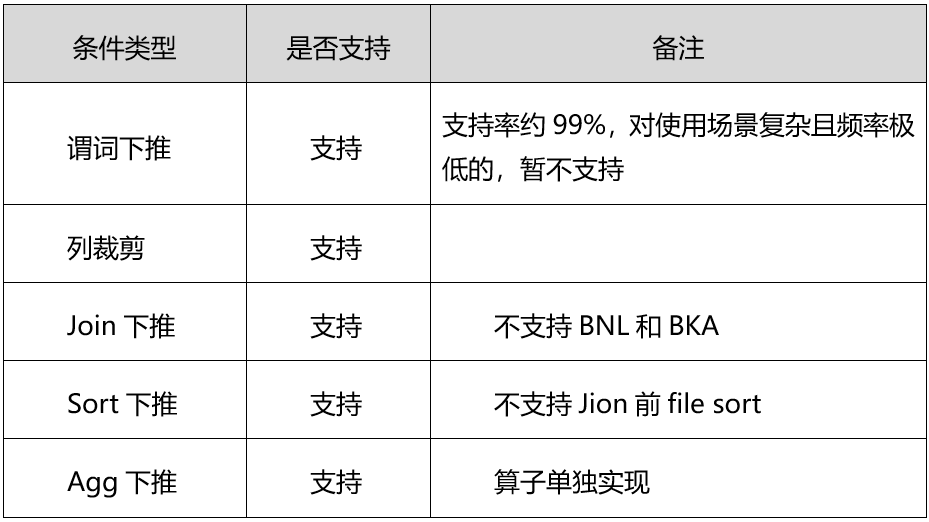
实现方式
分布式数据库条件下推时,在接入端序列化条件树,数据节点(服务端)反序列化条件树,在服务端行记录返回前,执行条件树判断当前行是否满足条件。
图表2 下推示意图
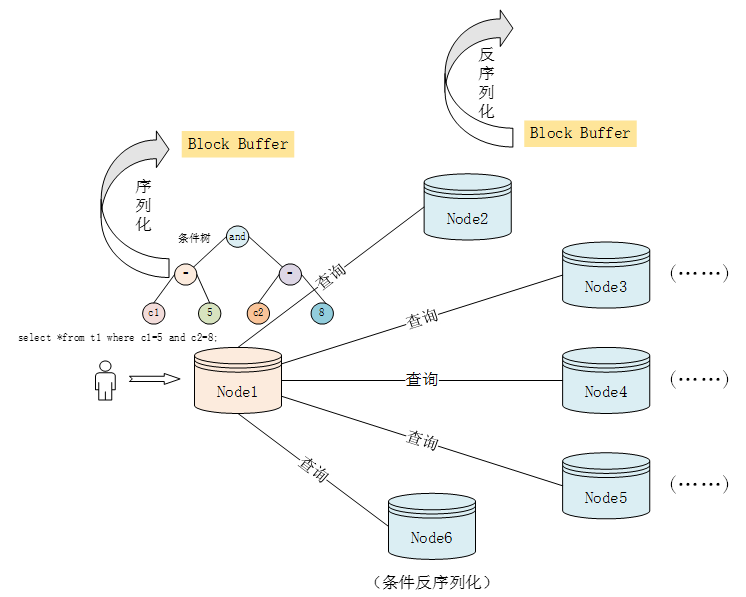
(1)条件树序列化
条件树的序列化过程,就是将内存中的树型条件链表,转化为可识别的标记型xml语言,然后打包写入到上行包。
图表3 序列话

(2)条件树反序列化
服务端节点接收到数据包,将Block Buffer转化为标记型xml语言,并重构树型条件链表。为减少重复发送,客户端只在首次访问时发送条件树。
图表 4 反序列化

(3)驱动算子
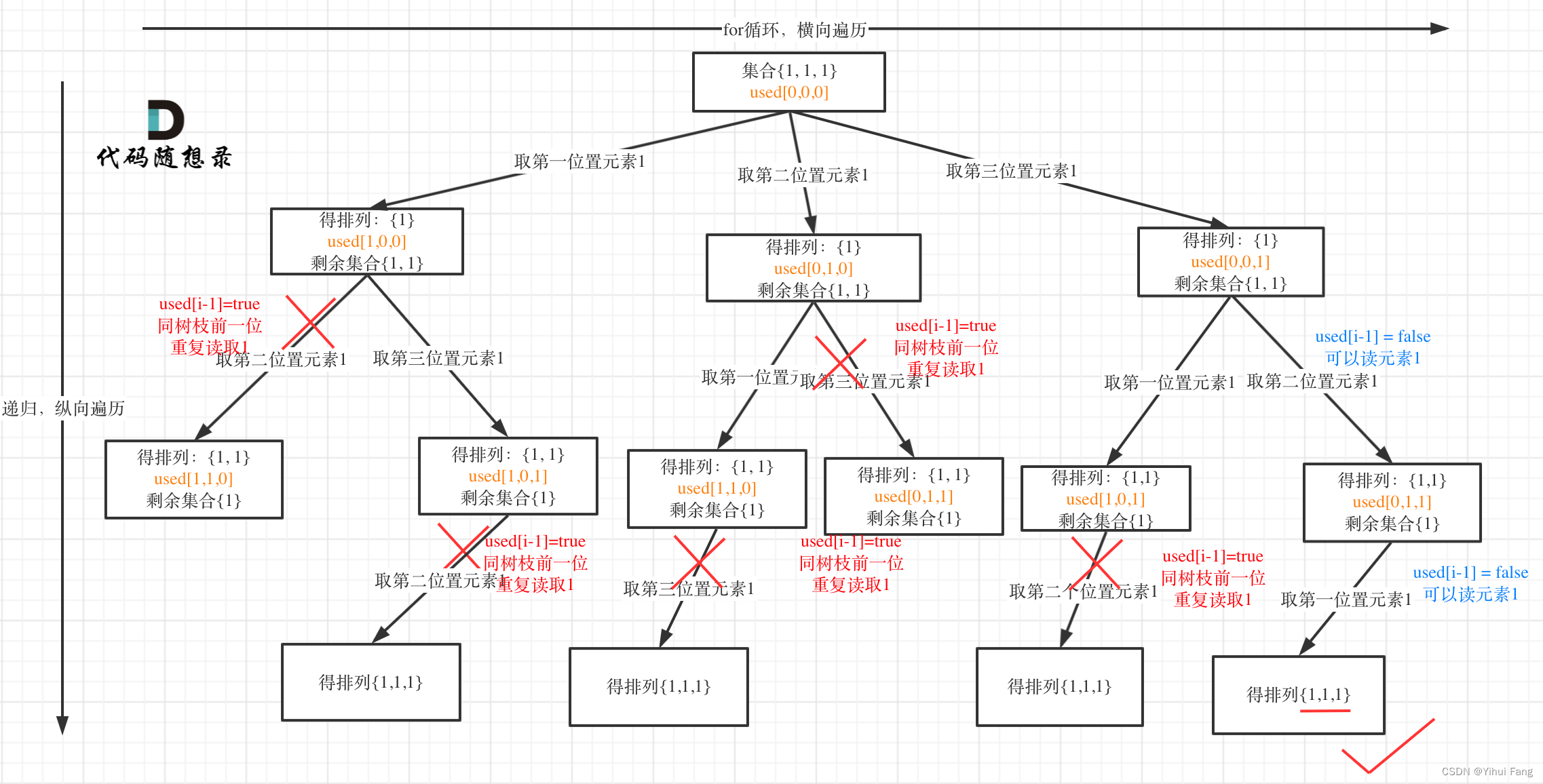
多张表关联查询时,执行Nest Loop算法,SQL优化为由小表驱动大表的嵌套循环操作。这里涉及到驱动表和被驱动表,被驱动表执行时,需要检测驱动表记录是否发生切换。

执行tb2查询时,驱动表tb1字段(id)在条件树中称之为“驱动算子”。根据tb1行唯一标识(Row_id)的值,判断记录是否切换。
若驱动算子的值发生变化,需要将驱动算子的值重新推到远端节点。远端节点,接收到新的驱动算子,需要将其回写到驱动表行记录中,这个回写的过程称之为“回表”。保证所有节点的上下文一致。
测试验证
本例使用包含1千万条数据的sysbench表来模拟不同选择率条件下,条件下推带来的性能收益,远程和本地机器配置均为4 Core 32G,single表的定义为:
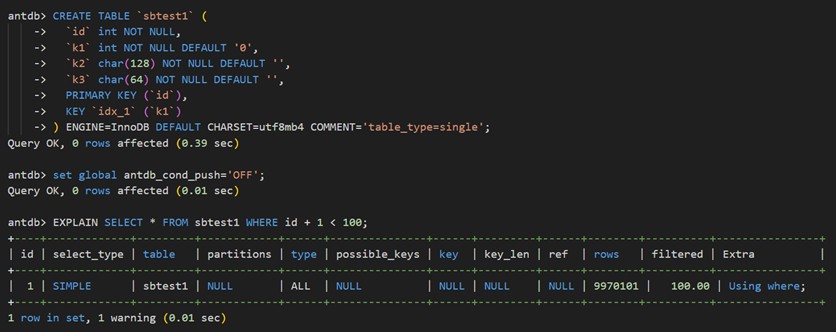
查询条件中使用包含主键的函数与常量进行比较,最优执行计划使用的是全表扫描方式。差别在于是否将条件下推到远程执行,通过改变常量值,构造不同的选择率条件,测试性能得到:
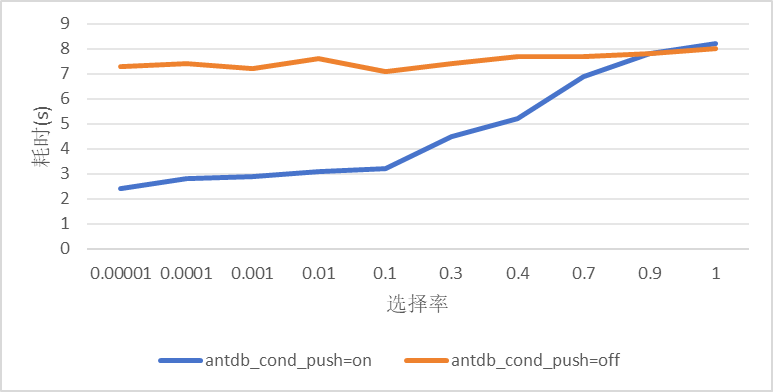
从测试数据可以看出,当条件选择率较低(小于0.1)时,约有近两倍的提升。
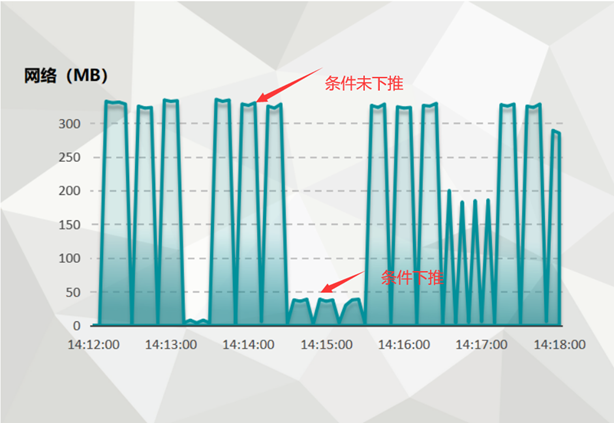
通过监控看出测试期间对网络带宽的占用情况,测试过程中,条件下推与不下推查询交替进行,可以看到:
-
条件不下推时,对网络带宽占用很高,且在不同选择率条件下都相同;
-
条件下推且选择率较低(小于0.1)时,对网络的流量非常小,随着选择率的增大逐渐增多,与条件不下推的网络I/O相比有明显区别。
新增的列裁剪、行数据压缩打包、Agg函数下推、批量行记录阈值,配合条件下推功能,进一步减少网络访问次数、网络传输数据量。
总结
分布式数据库支持谓词下推和投影(列裁剪)下推,优化产生的副作用极小。关联Join通过驱动表回表等操作,实现下推功能。为进一步降低网络开销,定义规则表,将Agg算子整体下推,并在接入端Merge。批量查询/更新、服务端自动提交、延迟发送等优化技术,能够合理的计算下推大幅降低网络开销,提升查询性能。
关于亚信安慧AntDB数据库
AntDB数据库始于2008年,在运营商的核心系统上,服务国内24个省市自治区的数亿用户,具备高性能、弹性扩展、高可靠等产品特性,峰值每秒可处理百万笔通信核心交易,保障系统持续稳定运行超十年,并在通信、金融、交通、能源、物联网等行业成功商用落地。