正则表达式是一种基于特殊模式符号系统的文本处理系统。简而言之,它为程序员提供了轻松处理和验证字符串的能力。它代表了DRY(Don't Repeat Yourself)原则的实现,在几乎所有支持的语言中,正则表达式模式根本不会改变形式。
在后端和前端应用程序上编写的代码将是相同的,从而为团队实现相同的功能节省了时间。还值得强调的是,该模块非常适合处理大型或复杂的字符串,因此可以简单快速地解决与它们相关的问题。
它发生在厨房里的一杯茶或团队 zoom-call 中,你可以听到正则表达式很难学习、编写和阅读,而且通常它们是由糟糕的人发明的😈。但是吗?让我们弄清楚。
注意:
本文适用于那些认为正则表达式复杂、难以理解的人以及那些认为基本知识完全足以胜任工作的人。
它看起来像什么
以下是用于确定俄罗斯电话号码的 6 种编程语言的示例。

在此示例中,您可以立即注意到 Regex 模块的第一个功能:条件模式将完全相同,您可以轻松地与使用另一种编程语言编写的团队共享您的代码。在不同团队之间快速“摸索”代码库的能力节省了开发和实施功能的时间。
出现的历史
正则表达式最早出现在 20 世纪 50 年代中期关于自动机理论和形式语言理论的科学论文中。Stefan Cole Kleen 被认为是第一个引入正则表达式概念的人。
Ken Thompson 在他的工作中提出的原则和想法得到了实际的实施,并以他轻巧的手融入了 Perl 语言。
根据定义,正则表达式是您的编程语言的一个模块,用于搜索和操作文本。
正则表达式语言不是成熟的编程语言,但与其他语言一样,它有自己的语法和命令。
哪些编程语言支持它们?
列表非常大,这里只是其中的几个:
C
C#
C++
Cobol
Delphi
F#
Go
Groovy
Haskell
Java
JavaScript
Julia
Kotlin
MATLAB
Objective-C
PHP
Perl
Python
R
Ruby
Rust
Scala
Swift
Visual Basic
Visual Basic .NET
...
能力
输入数据的模式匹配。
按模板搜索和更改输入数据。
返回输入字符串的第一个或所有结果。
与一般搜索的结果一起返回,搜索时命名而不是子字符串。
通过后替换输入字符串中的字符、单词、词组。
最重要的是,一次编写,随处使用。
它会用在什么地方?
在 IDE 中按模式搜索和替换代码(VS Code、Rider、CLion、VS)
验证字符串以进行模式匹配(文件扩展名)。
验证前面的字段(电子邮件、电话号码和其他)。
验证请求和响应数据。
验证巨大的字符串,然后在不花费大量时间的情况下获取必要的文本片段。
基本语法
^- 字符串开头(意味着输入字符串必须以其后的下一个字符开头。如果您不知道输入字符串的第一个字符,则不适用)。
$- 字符串结尾(意味着此字符之前的所有条件将是输入字符串的最终结果,之后没有任何进一步的结果。如果您想从输入字符串返回多个结果,则不适合)。
*- 表示给定符号之前的先前条件可能会出现一次或多次或根本不会出现(分别可能会重复)。
+- 表示该符号之前的条件必须出现一次或多次(分别可以重复)。
[a-z]- 枚举输入字符串中的有效字符,即它可以是任何小写拉丁字母(a 或 b 或 c ... 或 x 或 y 或 z)。
[0-9]- 枚举输入字符串中的有效字符,即它可以是任何小写拉丁字母(1 或 2 或 3 ... 或 7 或 8 或 9)。
.- 任何单个字符。
\- 选择任何特殊字符。
|– OR 逻辑运算(必须满足此操作数左侧或右侧的条件)
语法简化
\d≡ [0-9]- 从 0 到 9 的任何字符
\D≡ [^0-9]- 除数字以外的任何字符
\w≡ [a-zA-Z0-9_]- 任何拉丁字符、所有数字和“_”
\W≡ [^a-zA-Z0-9_]- 除拉丁字符、数字和“_”之外的任何字符
\s≡ [ ]- 仅限空格
\S≡ [^ ]- 除空格以外的任何字符
基本语法说明
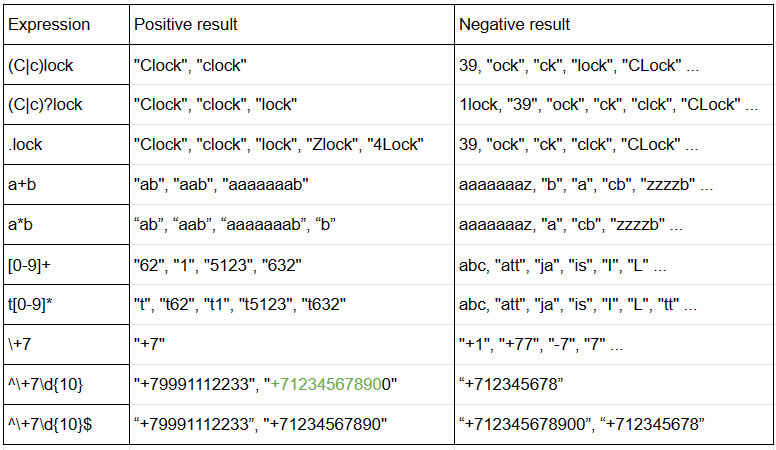
Condition Length
除了验证字符串中的值,我们还可以指定多少个字符应该通过相同的条件。只有三种可能使用长度条件:
{3}– 条件所需的字符数
{3.5}- 最小值。和最大。条件的字符数
{3,}- 强制性最小值。数量和无限最大。数量

注:条件[0-9]可以用缩写代替\d
与小组一起工作(高级)
这会有点棘手,所以做好准备吧。
()- 创建一个匿名组(创建一个子字符串并为其分配内存)
(?‘nameGroup’)- (?<nameGroup>)- 创建命名字符串
(\k<nameGroup>)- 用于从重复代码中删除模式,因此,如果您有一个具有某些条件的命名组“nameGroup”,您不能在模式中写入第二个组,但只需将此指令与一个正则表达式一起使用,该正则表达式仅指示之前描述的组的名称。因此,条件将重复出现,您无需再次描述。
(?:)- 在条件的逻辑括号中选择,不命名和创建子字符串
(<=)- 排除括号内的条件并且不将其包含在选择中。
(?!)- 检查括号内的条件,不将其包括在选择中。
现实生活中的例子
有一次,在工作中,我不得不解析打印在支票上的 QR 码数据,当购买/退回各种商品、服务等时。解析器的第一个版本是在 C# 后端编写的。解析器的代码库大约有 150 行代码,它没有考虑到各种财政登记员(打印支票并将数据发送到联邦税务局的设备)的某些功能。要更改此功能,必须仔细查看、检查每一行代码。后来选项太多了,需要在前端用它来验证。因此,决定使用正则表达式重写它以简化解析器并使其轻松快速地移植到另一种编程语言。
目标:
解析输入值以进行模式验证
获取购买日期和金额的必要字段,以便在系统中进一步使用。
检查字段“n”是否始终等于 1(0 - 退货,1 - 购买)
以下是输入数据的示例:
t=20181125T142800&s=850.12&fn=8715000100011785&i=86841&fp=1440325305&n=1
此类数据解析的正则表达式:
^t=(?<Date>[0-9-:T]+)&s=(?<Sum>[0-9]+(?:\.[0-9]{2})?)&fn=[0-9]+&i=[0-9]+&fp=[0-9]+&n=1$
代码示例 (C#):
private static (string date, string sum) parseQRCode(string data)
{
var pattern = new Regex(@"^t=(?<Date>[0-9-:T]+)&s=(?<Sum>[0-9]+(?:\.[0-9]{2})?)&fn=[0-9]+&i=[0-9]+&fp=[0-9]+&n=1$", RegexOptions.ECMAScript);
var matchResult = pattern.Match(data);
if (!matchResult.Success)
throw new ArgumentException("Invalid qrCode");
var dateGroup = matchResult.Groups["Date"];
if(!dateGroup.Success)
throw new ArgumentException("Invalid qrCode, Date group not found");
var sumGroup = matchResult.Groups["Sum"];
if(!sumGroup.Success)
throw new ArgumentException("Invalid qrCode, Sum group not found");
return (dateGroup.Value, sumGroup.Value);
}代码示例(Typescript):
这个选项是通过Exceptions做的,但是可以通过return false或者return null来做。
const parseQRCode = (data:string) : {date: string, sum: string} => {
const pattern = new RegExp("^t=(?<Date>[0-9-:T]+)&s=(?<Sum>[0-9]+(?:\.[0-9]{2})?)&fn=[0-9]+&i=[0-9]+&fp=[0-9]+&n=1$");
const matchResult = pattern.exec(data);
if (!matchResult)
throw "Invalid qrCode";
const dateGroup = matchResult[1];
if(!dateGroup)
throw "Invalid qrCode, Date group not found";
const sumGroup = matchResult[2];
if(!sumGroup)
throw "Invalid qrCode, Sum group not found";
return {date: dateGroup, sum: sumGroup};
};在输出中,我们得到两个值:
日期 - 表示购买日期和时间的字段(它只是解析它并将其转换为日期对象)
Sum - 购买金额
现在让我们更详细地分析该模式:
^- 表示一行的开头
t=(?<Date>[0-9-:T]+)– 所需的字符 t=(以下是任何字符(从 0 到 9 或 - 或 : 或 T)在一个或多个实例中)
&s=(?<Sum>[0-9]+(?:\.[0-9]{2})?)– 必填字符
&s=– 所需的字符序列&和s=
[0-9]+(一个或多个实例中的字符 0 到 9)
(?:\.[0-9]{2})?- 非必需的组从.2 个数字的符号开始
$- 表示行尾
&fn=[0-9]+– 必需的字符&fn=后跟[0-9]+->(在一个或多个实例中是从 0 到 9 的任何数字)
&i=[0-9]+– 必需的字符&i=后跟[0-9]+->(在一个或多个实例中是从 0 到 9 的任何数字)
&fp=[0-9]+– 必需的字符&fp=后跟[0-9]+->(在一个或多个实例中是从 0 到 9 的任何数字)
&n=1– 必填字符&n=1
使用非拉丁字母的问题
当您需要使用整个拉丁字母表时,只需编写[a-zA-Z]. 许多人认为在使用西里尔字母时,编写[а-яА-Я]. 似乎一切都合乎逻辑,一切都很好,但在某些时候你会意识到有时它并不适合你。问题是范围[а-я]不包括字母“ё”,因此,您需要将模式从 更改[а-яА-Я]为[а-яёА-ЯЁ]以便代码考虑字母表中的特定字母。这个问题不仅存在于西里尔字母中,这个问题也与希腊语、土耳其语、中国和许多其他语言有关。编写应使用这些语言的模式时要小心。
JS 正则表达式标志
global (g) - 在找到第一个匹配项后不停止搜索。
多行 (m) - 搜索包含换行符的行(^ 行首,$ 行尾)。
insensitive (i) - 不敏感地搜索 (a ≡ A)
sticky (y) - 除了匹配之外,搜索还返回子选择匹配开头的索引(IE 不支持)
unicode (u) - 搜索包括 unicode 字符(IE 不支持)
单行 (s) - 在此模式下,符号.还包括换行符(Chrome、Opera、Safari 支持)
C#
RegexOptions 中的附加正则表达式设置在 Regex 类的构造函数中公开为附加参数。也可以在 Match、Matches 方法中指定。
无 - 默认设置。
IgnoreCase (\i) - 不区分大小写地检查。
多行 (\m) - 使用包含连字符 \n 的行。
ExplicitCapture (\n) - 仅将命名组添加到结果中。
已编译(仅在静态版本中有用,加速正则表达式,减慢编译速度)。
单行(.符号将匹配除 \n 之外的任何字符,并在搜索时忽略它)
IgnorePatternWhitespace (\x) 。(删除所有空格,构造 []、{} 中的例外)
RightToLeft - 从右到左搜索。
ECMAScript(类似 JS 的版本,但样式分组与 .NET 中的相同)。
CultureInvariant(比较忽略键盘布局)。
良好做法和优化技巧
分组越少,执行速度越快。如果您不需要它们,请尽量避免使用它们。
使用缩写(\d,\w和其他)时,请确保它们与您的搜索词完全匹配。最好检查两次。
如果经常使用正则表达式,全局创建一次,从而减少重复代码量。
几乎所有地方都可以编译正则表达式,这通常可以优化您的表达式并加快它们的执行速度。但是在验证后使用它们,它会加速你的代码。
尝试减少特殊符号选择 ( \) 的数量,此功能会降低许多编程语言的执行速度。
正则表达式支持 UTF 字符代码。在某些时候,这会提高性能,但会降低可读性。如果您决定使用它们,请确保团队会批准您的决定并且这是值得的。
结论
正则表达式只是想看起来很复杂,但实际上,它们提供的功能提供了很多机会,让您可以简化和加快从初级到高级/领导的每个人的工作。
拜托,如果您有任何问题,请随时发表评论,我们可以与您一起讨论。
链接
语言正则表达式基准
在线正则表达式助手,带有所有可用命令的字典并支持多种编程语言
我的 RU 语言原始帖子
PS 不要忘记一条重要规则:“编程很酷。”