海量数据存储面临的问题
- 海量数据存储面临的问题
- 成本高
- 性能低
- 可扩展性差
- 如何实现分布式文件存储
- 如何支撑高效率的计算分析
- 如何解决海量数据存储的问题
- 如何解决海量数据文件查询便捷问题
- 如何解决大文件传输效率慢的问题
- 如何解决硬件故障数据丢失问题
- 如何解决用户查询视角统一规整问题
- 分布式存储应具备的特征
海量数据存储面临的问题
成本高
传统存储硬件通用性差,设备投资加上后期维护,升级扩容的成本非常高。
例如:盘位满了,要换更多盘位的机器。3
性能低
单节点I/O性能瓶颈无法逾越,难以支撑海量数据的高并发高吞吐场景。
可扩展性差
无法实现快速部署和弹性扩展,动态扩容、缩容成本高,技术实现难度大。
如何实现分布式文件存储
如何支撑高效率的计算分析

传统存储方式意味着数据存储是存储,计算是计算,当需要处理数据的时候把数据移动过来(存储不动,数据移动)。
程序和数据存储是属于不同的技术厂商实现无法有机统一整合在一起。
如何解决海量数据存储的问题
传统做法是单机存储,随着数据变多,会遇到存储瓶颈。
-
单机纵向扩展:
内存不够加内存,磁盘不够加磁盘,有上限限制,不能无限制加下去。 -
多机横向扩展:
采用多台机器存储,一台不够就加机器。理论上可以无限。
多台机器存储也意味着迈入了分布式存储。
如何解决海量数据文件查询便捷问题
当文件被分布式存储在多台机器之后,后续获取文件的时候如何能快速找到文件位于哪台机器上呢?
一台一台查询过来是不靠谱的。因此可以借助于元数据记录来解决这个问题。把文件和其存储的机器的位置信息记录下来,类似于图书馆查阅图书系统,这样就可以快速定位文件存储在哪一台机器上了。
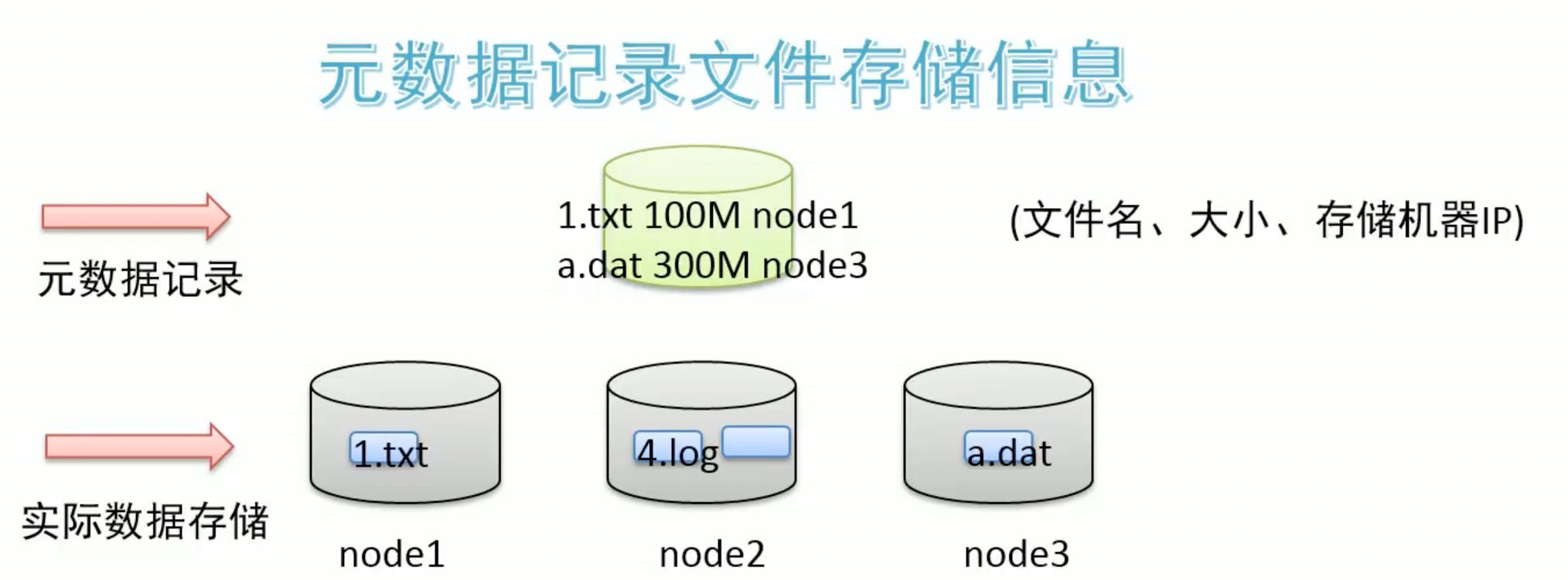
如何解决大文件传输效率慢的问题
大数据使用场景下,GB、TP级别的大文件是常见的。当单个文件过大的时候,如何提高传输效率?
通常的做法是分块存储:
把大文件拆分成若干个小块(block简写blk),分别存储在不同机器上,并行操作提高效率。
此外分块存储还可以解决数据存储负载均衡问题。此时元数据记录信息也应该更加详细:文件分了几块,分别位于哪些机器上。
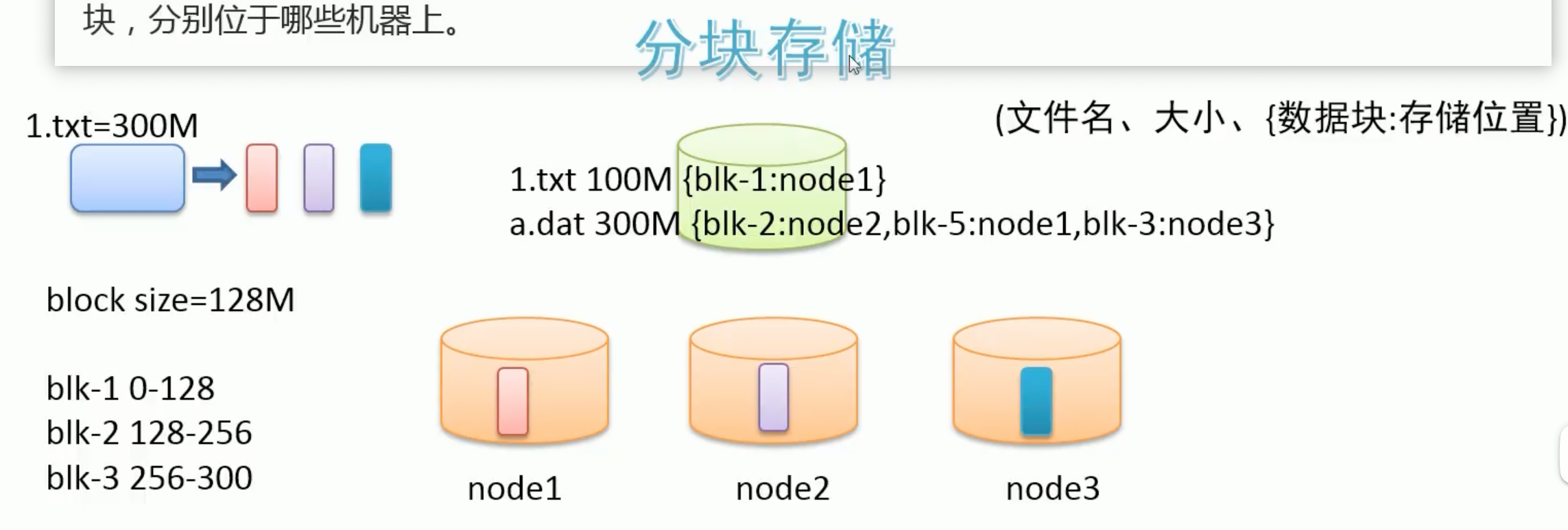
如何解决硬件故障数据丢失问题

如何解决用户查询视角统一规整问题
namespace也可以理解为文件夹的目录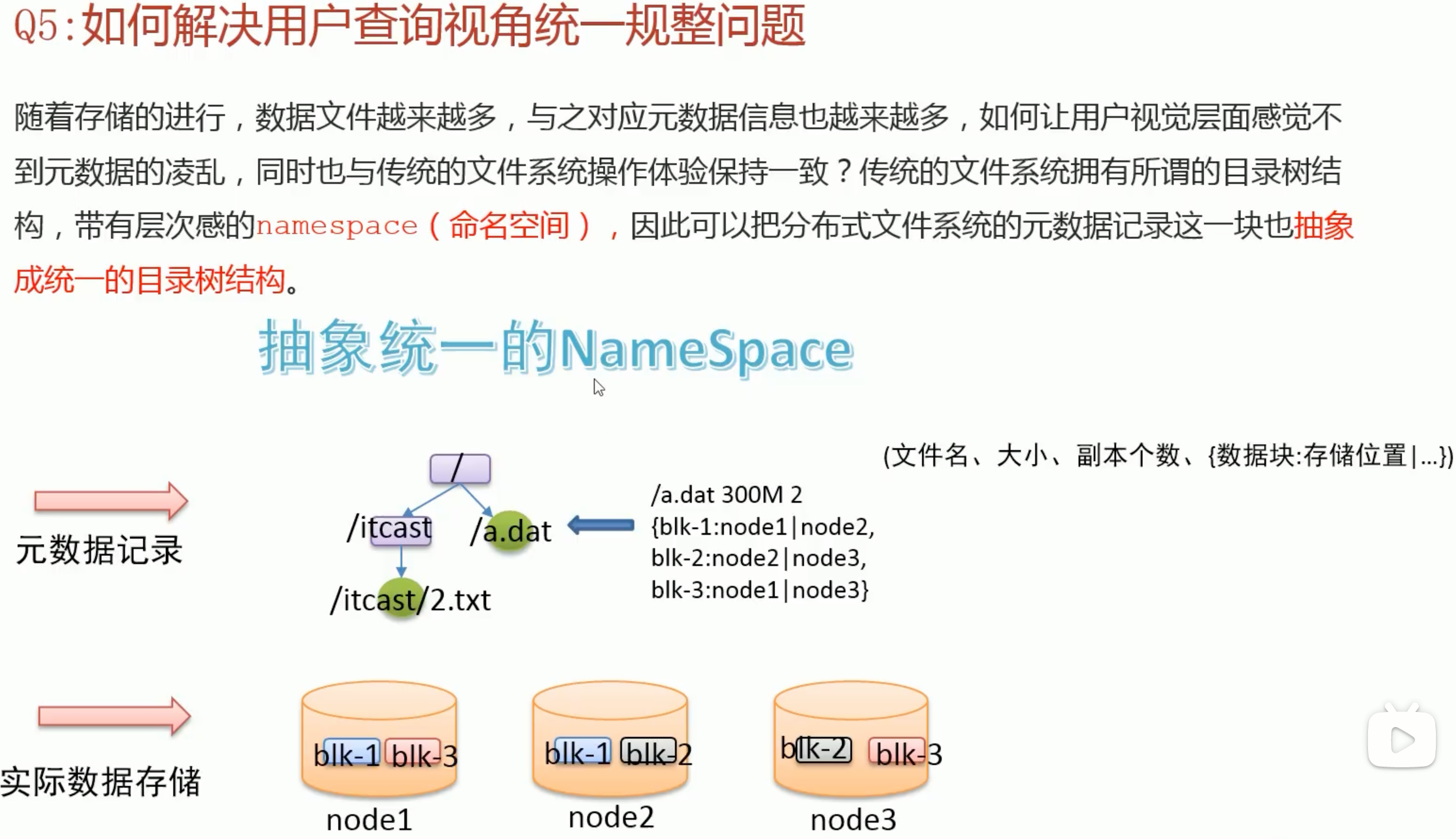
分布式存储应具备的特征